用Python实现卷积神经网络(一)
用代码创建CNNs
从前面传统神经网络的情况,我们看到传统神经网络不工作当像素向左平移一单位时。实践中,我们可以考虑卷积作为识别模式而池化步骤作为平移不变种。
N 个池化步骤导致最后N单元平移不变。考虑下面的例子,我们在卷积后用一个池化步(代码见 ):
1.导入和变形数据以拟合 CNN:
(X_train, y_train), (X_test, y_test) = mnist.load_data() X_train = X_train.reshape(X_train.shape[0],X_train.shape[1], X_train.shape[1],1 ).astype('float32')
X_test = X_test.reshape(X_test.shape[0],X_test.shape[1],X_test. shape[1],1).astype('float32')
X_train = X_train / 255 X_test = X_test / 255
y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) num_classes = y_test.shape[1]
Step 2: Build a model model = Sequential()
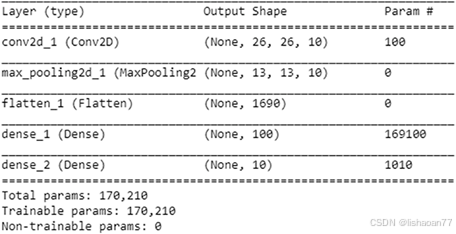
model.add(Conv2D(10, (3,3), input_shape=(28, 28,1), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten())
model.add(Dense(1000, activation='relu')) model.add(Dense(num_classes, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
2.拟合模型:
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=5, batch_size=1024, verbose=1)

对于前面的卷积,一个卷积接着一个池化层,输出预测工作得很好如果像素向左或向右平移一个单元,但是当像素平移大于1单元时不工作 (图 9-7):
pic=np.zeros((28,28)) pic2=np.copy(pic)
for i in range(X_train1.shape[0]): pic2=X_train1[i,:,:] pic=pic+pic2
pic=(pic/X_train1.shape[0]) for i in range(pic.shape[0]):
if i<20: pic[:,i]=pic[:,i+1]
plt.imshow(pic)
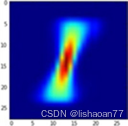
图 9-7.平均 1图像像素向左平移1单元
我们继续并预测图 9-7的标签:
model.predict(pic.reshape(1,28,28,1))
![]()
我们看到准确的预测1作为输出。
在下一个情况 (图 9-8),我们向左移动2个像素:
pic=np.zeros((28,28)) pic2=np.copy(pic)
for i in range(X_train1.shape[0]): pic2=X_train1[i,:,:] pic=pic+pic2
pic=(pic/X_train1.shape[0]) for i in range(pic.shape[0]):
if i<20: pic[:,i]=pic[:,i+2]
plt.imshow(pic)

图 9-8.平均1的图像向右平移2个像素
我们来预测图 9-8的标签用我们构建的 CNN 模型:
model.predict(pic.reshape(1,28,28,1))
![]()
注意当卷积池化层的数量与图像平移数量一样时,预测是准确的。但是如果平移的数量大于卷积和池化层的数量时预测很可能是不准确的。