基于Python flask的常用AI工具功能数据分析与可视化系统设计与实现,技术包括LSTM、SVM、朴素贝叶斯三种算法,echart可视化
摘 要
本系统基于Flask框架设计与实现,主要功能包括用户登录注册、数据展示、情感分析和可视化。首先,通过网络爬虫从应用宝网站抓取约4000条AI工具评论数据,并将其存储于MySQL数据库中。系统提供用户注册和登录功能,注册时通过POST请求接收用户输入的用户名、密码等信息,登录通过Session验证用户身份,保障安全性和流畅的用户体验。
数据展示功能通过Flask模板引擎和Bootstrap框架实现,页面集成DataTables插件,支持分页、搜索和排序。数据通过Jinja2动态渲染,确保前端与后端数据无缝对接。数据可视化部分采用ECharts展示情感分布图和主题聚类图,支持动态更新,用户可以选择不同的AI工具进行情感分析,分析结果通过AJAX异步请求进行刷新。
在情感预测功能方面,用户可以选择不同的机器学习模型(如LSTM、SVM、朴素贝叶斯)进行情感分析。通过POST方法提交数据,系统返回情感分类结果,支持实时更新和无刷新交互。整个系统的前端设计响应式,兼容各种设备,界面简洁易用,提供了良好的用户体验。
该系统有效地结合了数据爬取、情感分析和可视化展示,具备高效的数据处理能力和良好的用户交互体验,为情感分析领域提供了一个综合性的解决方案。
目 录
1 绪论
1.1 研究背景
1.2 研究目的与意义
1.2.1 研究目的
1.2.2 研究意义
1.3 研究现状
1.3.1 国内研究现状
1.3.2 国外研究现状
1.3.3 现有研究分析和局限性
1.4研究的主要内容
1.5本章小节
2.1系统技术简介
2.1.1 Flask框架技术
2.1.2 Request爬虫技术
2.1.3 Mysql技术
2.2LSTM模型
2.3本章小结
3 系统需求分析
3.1功能需求分析
3.2非功能性需求
3.3系统业务流程分析
3.4可行性分析
3.4.1技术可行性
3.4.2经济可行性分析
3.5本章小结
4 系统设计
4.1系统架构设计
4.2功能详细设计
4.2.1数据采集功能
4.2.2注册登录功能设计
4.2.3数据处理功能
4.2.4数据可视化功能
4.2.5情感预测功能
4.3数据库设计
4.3.1数据库逻辑设计
4.3.2数据库物理设计
4.4本章小结
5 基于Lstm算法设计与实现
5.1数据采集实现
5.2数据清洗与预处理
5.3LSTM模型算法实现与评估
5.4本章小结
6 系统实现
6.1用户登录注册功能实现
6.2数据展示功能实现
6.3数据可视化功能实现
6.4评论聚类分析功能实现
6.5情感预测功能实现
6.6本章小结
7 各个AI工具结果分析
7.1 AI工具结果分析
7.1.1评论时间分布特点
7.1.2评论评分分布
7.1.3情感分布
7.1.4文本主题聚类分析
7.2 结论
参考文献
1 绪论
1.1 研究背景
近年来,AI相关开源框架工具不断增加,极大降低了AI开发的门槛,但也面临着如何选择适合工具的问题,因为市场上AI相关的开源开发框架工具种类繁多,在功能差异、性能差异、使用场景中,究竟如何为不同人群、不同需求的企业选择相应的AI开发框架、工具?究竟要怎样选择才能解决目前面对的纷繁复杂的信息碎片化?究竟要考虑哪些信息的因素才能帮工具选择者做出正确判断?目前还未出现系统性的关于AI工具功能数据的有效报告,各部分工具的更新迭代、数据分析、版本迭代对决策者带来极大困扰。
1.2 研究目的与意义
1.2.1 研究目的
一是建立AI工具功能数据仓库,整合AI主流工具的功用特点、性能、社区活跃度等数据;二是建立数据分析模型,运用Python进行多维度(功能覆盖范围、可用性、性能、生态支持等)的量化分析;三是建立可视化交互平台,运用动态图表、分析比对界面等方式,直观呈现工具优劣势;四是做到动态化更新与预测:运用时间序列方法,预测AI工具发展方向。
1.2.2 研究意义
(一)理论意义
理论上可以弥补AI工具功能数据化分析空白,构建多维度评价指标体系;探索数据可视技术在工具生态研究中的方法模式,从分析Python库的依赖关系(如PyPI数据)、功能演化路径两个方面探索工具生态协作规,为开源社区治理的理论参考;丰富相关方法论。
(二)实践意义
实践意义上,能够帮助开发者快速匹配适合的工具,提升开发效率,同时为工具开发者提供功能优化方向,通过交互式可视化界面,降低非技术人员理解AI工具的门槛,推动AI技术在教育、医疗等领域的落地,推动技术生态良性发展,也可以为企业技术选型提供数据支持,降低试错成本。
1.3 研究现状
1.3.1 国内研究现状
在国内,随着近年来人工智能技术的飞速进步,AI工具在国内的研究也从算法的研究逐步转变为对于AI工具生态进行分析的范畴,而对于AI工具功能数据分析和可视化的研究仍处于刚刚起步阶段。具体研究情况为对AI工具功能分析方法的初次研究、Python工具生态的局部研究、对数据可视化技术的应用。
1.3.2 国外研究现状
国外AI工具功能分析与可视化的研究时间较长,已涌现出较为成熟的研究方向与方法,但也面临技术障碍和应用制约。
1.3.3 现有研究分析和局限性
国内外现有研究尚未构建良好的系统性框架,获得的结果大多是点式研究成果,并未构建“获取数据→特征数据处理→设计模型→结果可视化”的整体系统体系;其次是缺少动态的适配性,针对AI开发人员每周数以千计次的代码提交(以TensorFlow日均50次为基准),现有研究难以“识变”;再者是缺乏用户参与度,现有的多数研究都属于单向的信息呈现,未能通过用户反馈形成动态的持续改进。
1.4研究的主要内容
研究内容主要划分为以下几个部分:
(1)数据采集模块:开发数据采集模块,采集豌豆荚、应用宝等平台中的AI工具功能介绍、性能参数、用户评论等相关数据信息。
2.数据处理模块:搭建与实现数据处理模块,用于对采集到的数据做清洗、整理、分析。数据处理的内容:文本清洗、文本分词、特征提取、数据转换。
3.数据分析模块:设计实现数据处理后进行统计分析、聚类分析、情感分析等数据分析模块。数据分析包括:描述性统计、聚类分析、情感分析。
4.可视化部件:设计、开发可视化部件,将分析结论用直观的方式展现。可视化包括:表格;分布饼图;AI之间关系图;交互界面:允许用户查询与对比的自定义。
5.系统集成测试:集成基于Flask框架和Boostrap前端的各部分组成完整的系统,测试并进行系统化优化。
2 相关技术简介
2.1系统技术简介
2.1.1 Flask框架技术
Flask是以Werkzeug工具包和Jinja2模板引擎作为基础的轻量级PythonWeb框架。微框架就是功能模块不臃肿、尽量保持简单的开发模式,并且能够通过扩展机制增添新功能,以实现尽可能大的灵活性。Flask秉承清晰胜于巧妙的设计理念,使程序员对项目组织形式有更大控制权。
2.1.2 Request爬虫技术
AI工具评论分析系统的设计与实现中,通过request库对豌豆荚、应用宝进行发起一个请求,从而获取网页内容和数据,在利用特定的网页解析技术提取出我们想要的内容。
2.1.3 Mysql技术
系统的设计与实现使用了多个开发工具,其中包括:
MySQL:能存储和管理数据,对web系统中实现数据的增删改查,并为可视化提供数据支持,起到数据引擎的作用。
2.2LSTM模型
LSTM(LongShortTermMemoryNetwork)是在循环神经网络(RNN)的基础上,为了克服RNN长时程依赖性而提出的一种改进版本,LSTM相对于传统的RNN的突出优势在于通过一组门将内部记忆单元更新到最大。
3 系统需求分析
3.1功能需求分析
系统以Flask为后端、Bootstrap为前端框架,结合使用LSTM情感模型和Echarts,将AI工具评论进行分析展示,对系统的功能需求如下。
身份管理、数据获取及处理、检索、情感分析、多视角可视化、对比分析。
3.2非功能性需求
系统性能要求:在系统中,性能要求是非常关键的。系统要求能够良好运行在大量用户并发访问的基础上,在此期间,可以快速响应系统中的各种预测过程以及数据查询等操作,保证系统的响应性。
3.3系统业务流程分析
本次系统的业务流程分为四个部分。首先是数据分析收集部分,采用自定义爬虫程序自动采集一些主流的网站平台AI工具评论的文本数据,将商品名称、功能分类、评分及评论文本进行结构化存储形成原始数据表。实现业务流程如图3.2所示。

图3.2 系统业务流程图
3.4可行性分析
4 系统设计
4.1系统架构设计
系统基于分层架构,分为表现、业务逻辑和访问三层。系统框架图如下图4.1:
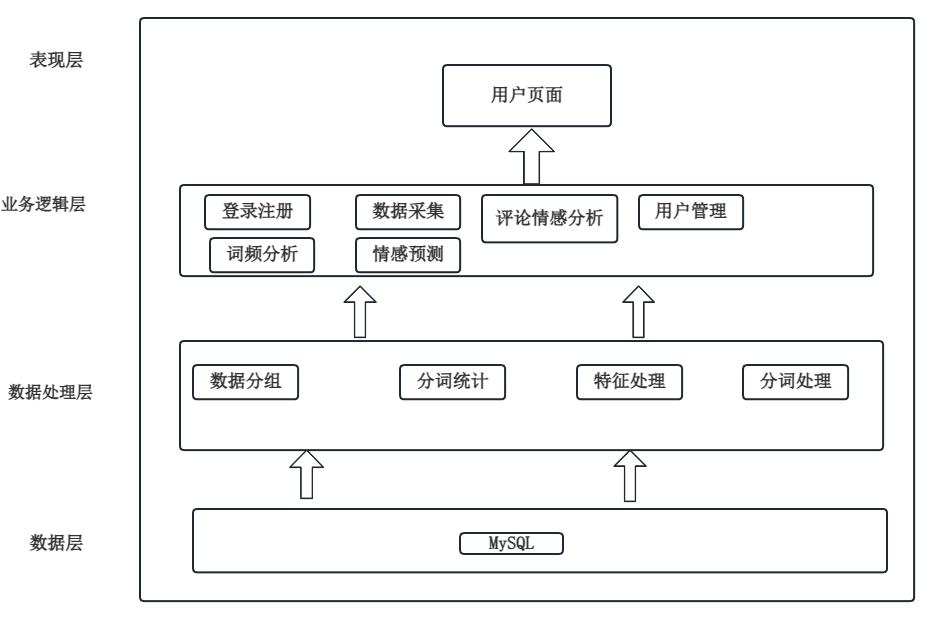
图4.1系统架构图
本系统对照功能实现,用户模块也就是系统使用者拥有登录注册、数据采集、数据可视化、情感预测等功能。
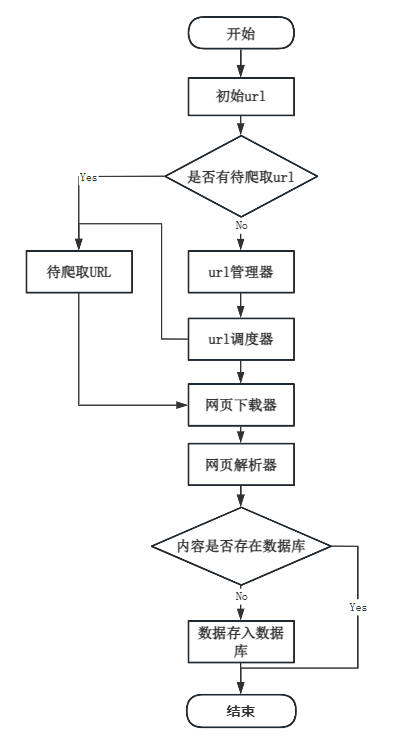
从常用应用商店豌豆荚、应用宝等下载平台抓取AI工具的结构化数据和文本数据:利用request框架实现爬虫多线程异步抓取,使用第三方代理(快代理)更换爬虫IP,以避免被APP厂商服务器封IP。数据采集的流程如图4.2所示。
4.2.2注册登录功能设计
登录用户信息的输入是在注册页面用户输入用户名、登录密码、E-mail,点击提交按钮时,前端将表单内容传给后端,后端对传回的数据进行校验,验证是否有效,若有问题,将显示提示信息;若有效,则将其存储在数据库中,并创建登录成功界面。图4.3为注册与登录的流程图。
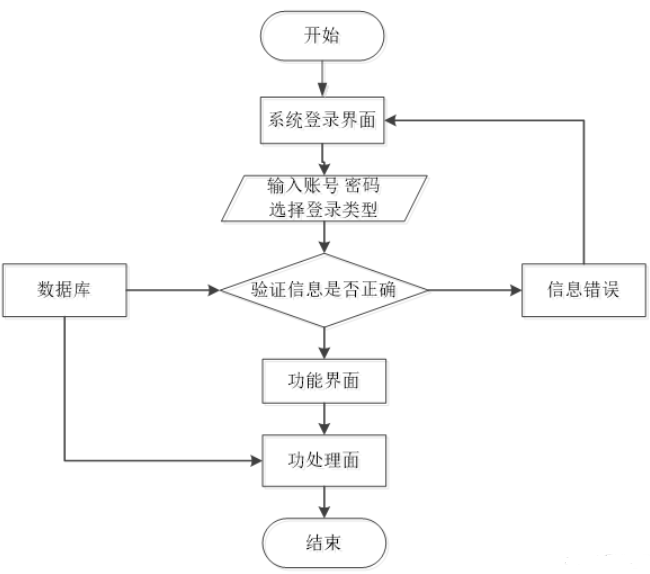
图4.3 注册登录流程图
4.2.3数据处理功能
清洗原始数据并提取有效特征,为模型训练提供高质量输入。数据处理流程如图如图4.4所示。

图4.4 数据处理流程图
4.2.4数据可视化功能
数据可视化功能部分,设置多种用户交互分析架构,以用户决策过程为逻辑主线构建三项交互功能模块:数据动态交互设计,在数据预处理构建的基础上,将数据中的特征进行动态图形绘制展示,分析用户评论的情感比例、发帖时间分布等内容。数据可视化的过程如图4.5所示。
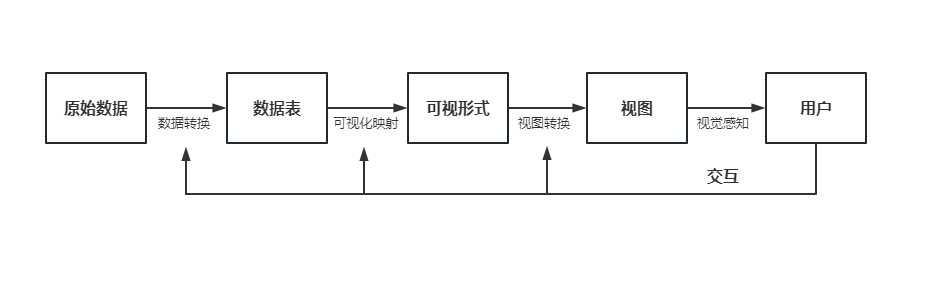
图4.5 数据可视化流程
4.2.5情感预测功能
情感预测模块的执行步骤共包含三个环节:第一环节进行数据预处理。第二环节进行情感预测模型建立。第三环节将存储在数据库中的情感预测模型加载到计算机服务器中,通过情感预测模型计算用户提出问题情感倾向的可能性。情感预测模块执行流程见如图4.6所示。
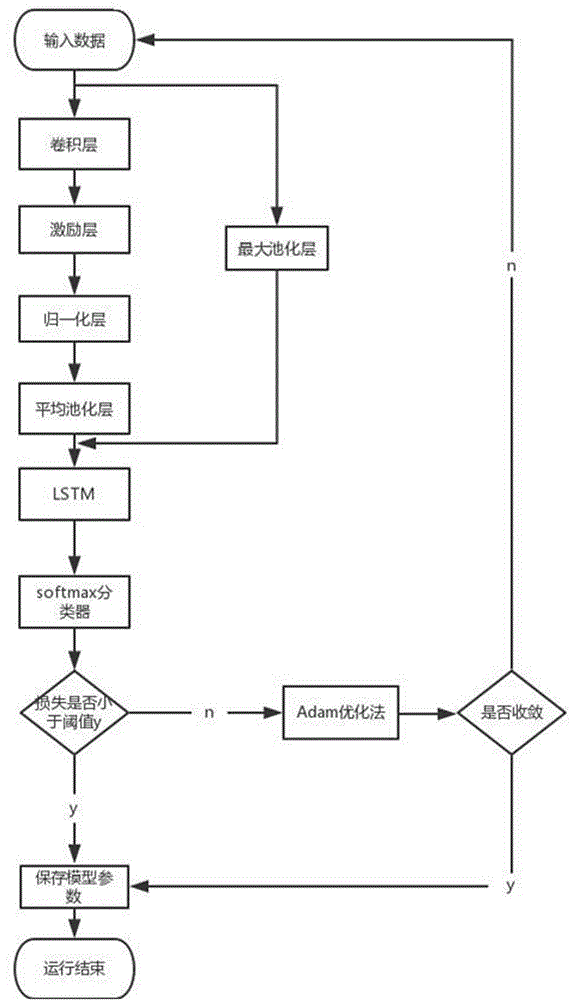
图4.6 情感预测流程图
4.3数据库设计
4.3.1数据库逻辑设计
系统数据库设计聚焦用户与评论两类核心数据实体。用户信息实体属性图如图4.6所示。
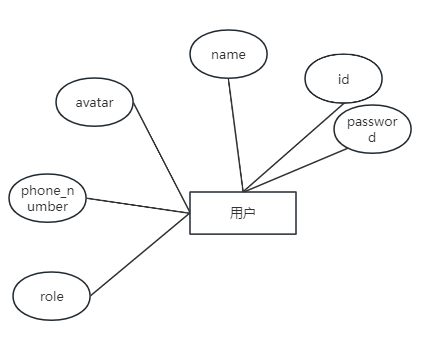
图4.6 用户信息实体属性图
4.3.2数据库物理设计
表1是用户基本信息表,ID为主键用于唯一标识,用户名、邮箱、手机号、地址和介绍非空不为空、用户名唯一。
表4.1 用户表
| 字段名 | 类型 | 长度 | 说明 |
| id | int | 0 | 用户编号(主键、自增) |
| username | varchar | 255 | 用户名 |
| password | varchar | 255 | 密码 |
| | text | 0 | 邮箱 |
| content | text | 0 | 简介 |
| address | text | 0 | 地址 |
| phone | text | 0 | 手机号 |
| Role | text | 0 |
评论信息如表4.2所示,评论信息表存储了评论的相关信息,包括id、评论、时间、是否推荐、评分、AI工具等信息。其中ID为主键。
表4.2 评论信息表
| 字段名 | 类型 | 长度 | 说明 |
| 用户名 | TEXT | 255 | 不为空 |
| 评论 | TEXT | 255 | 不为空 |
| 时间 | TEXT | 255 | 不为空 |
| 评分 | integer | 255 | 不为空 |
| 是否推荐 | TEXT | 255 | 不为空 |
| AI工具 | TEXT | 255 | 不为空 |
| id | INTEGER | 0 | (主键、自增) |
5 基于Lstm算法设计与实现
5.1数据采集实现
本文数据来源于应用宝。为了提高数据获取的效率,本文采取的是网络爬虫的方式来获取应用宝网站的AI工具评论信息数据。共爬取了4000条数据。部分数据如下图5.2所示:
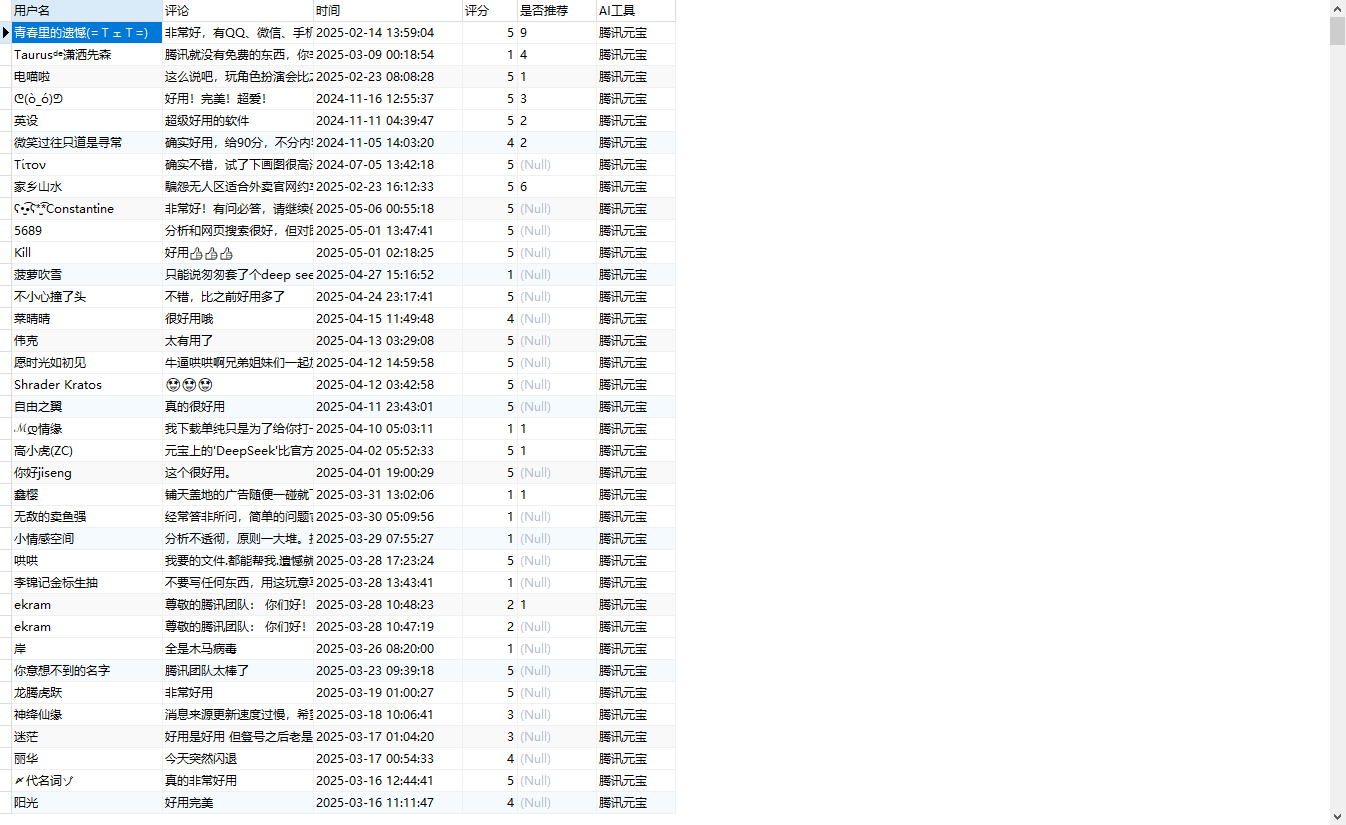
图5.1 数据采集结果
5.2数据清洗与预处理
基于文本数据将本文任务分为情感分类任务,情感倾向即负面/中性/正面,采用基于LSTM(长短时记忆网络)的模型实现该任务。
5.3LSTM模型算法实现与评估
对情感分类任务而言,主要使用LSTM模型进行文本分类。LSTM是最常见的递归神经网络(RNN),它能有效处理如文本之类的序列型数据。LSTM可以有效地抓取文本中所体现出的长距离依赖关系,这是情感分析一个很重要的特点,因为情感表达经常会考虑上下文的信息,如图5-2混淆矩阵,图5-3 Roc曲线:
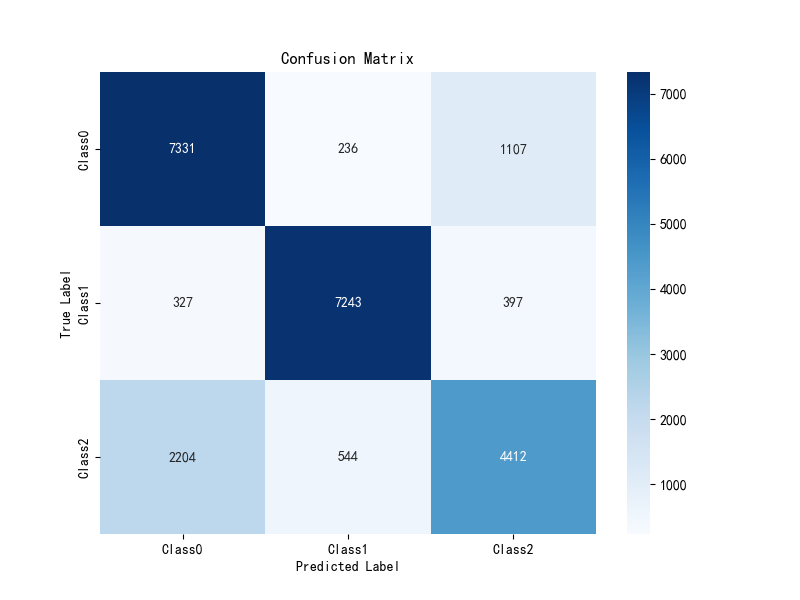
图5.2 混淆矩阵
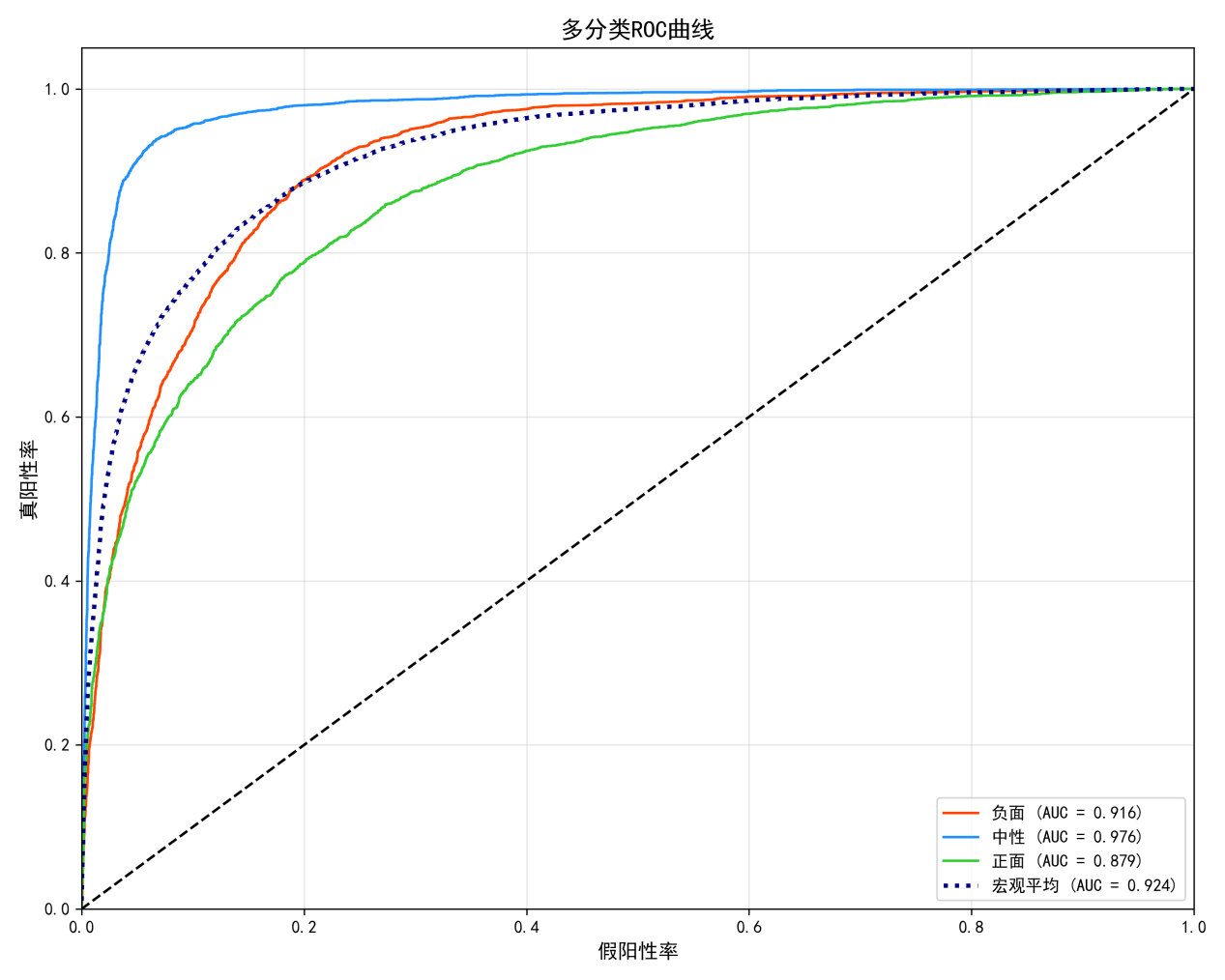
图5.3 Roc曲线
6 系统实现
6.1用户登录注册功能实现
该系统实现的登录注册功能利用后端Flask框架实现,当用户访问系统时可以进行系统登录使用账号注册系统,也可以进行系统注册使用用户名,注册采用GET请求渲染注册页面,当用户提交注册信息时,发送POST请求,系统接收用户提交的用户名和密码以及确认密码。如图6.2所示:

图6.1注册界面

图6.2登录界面
6.2数据展示功能实现
下面展示数据展示页面,首先通过Flask模板引擎,利用Bootstrap框架构建响应式的响应式页面,其结构从基础模板index.html继承,主要内容放在一个占据页面完整宽度的容器里,并在一个卡片组件中。数据展示结果如下图6.3所示:
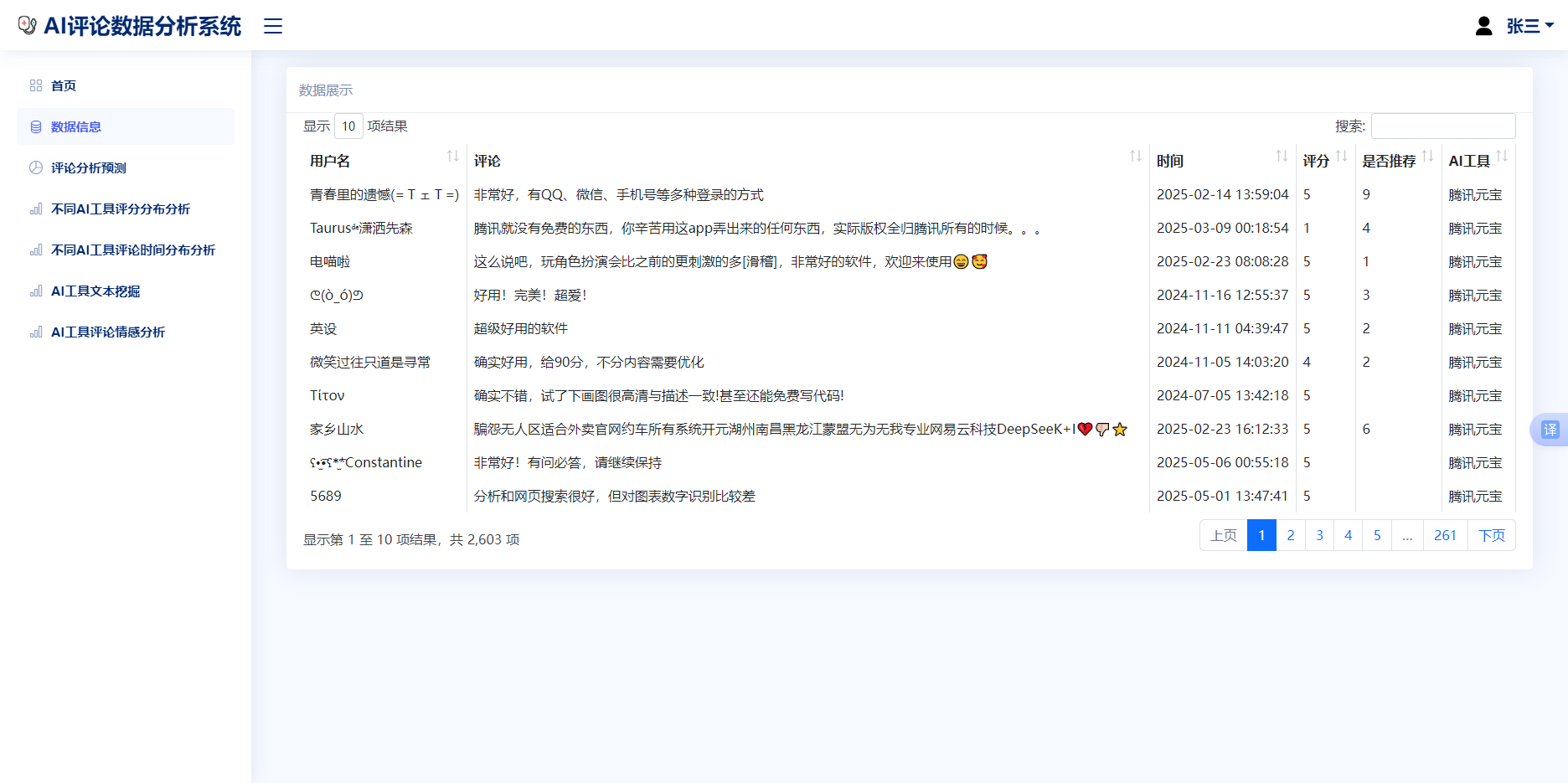
图6.3数据展示界面
6.3数据可视化功能实现
本可视化示例使用Flask继承模板继承渲染的模版继承风格,依照Bootstrap的栅格布局,将模版分为左右两个部分,左边占用了9个格,嵌套的Echarts饼图占满了所有格,嵌套使用json传入后端获得的data变量,渲染初始情感比例,圆环设置半径大小为40%-70%,将标签设置在圆的中心位置,并将百分比值显示在圆形标签上,将标签颜色设置为红色,状态色显示时放大字体至40px以突出显示圆环图的圆环标签位置。数据可视化界面交互后的效果见图6.4:
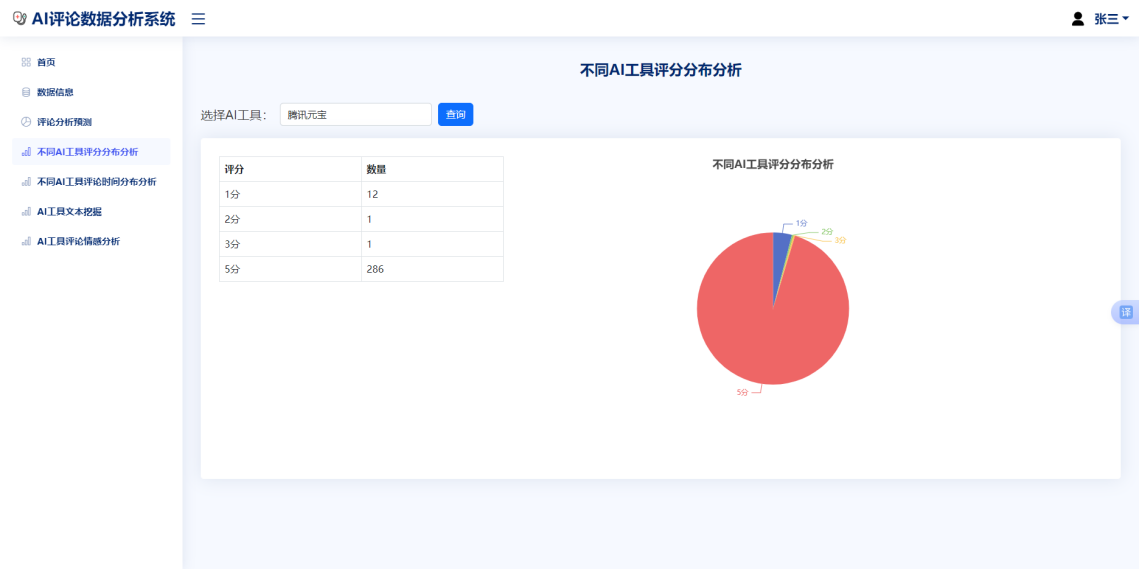
图6.4评分分布界面
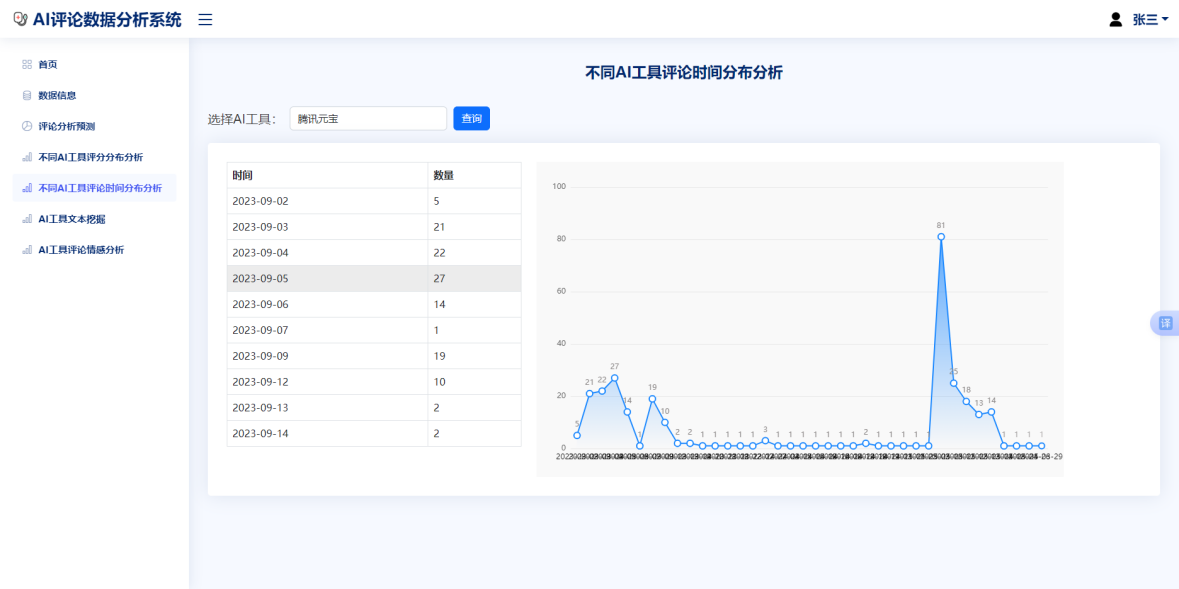
图6.5评论实际分布界面
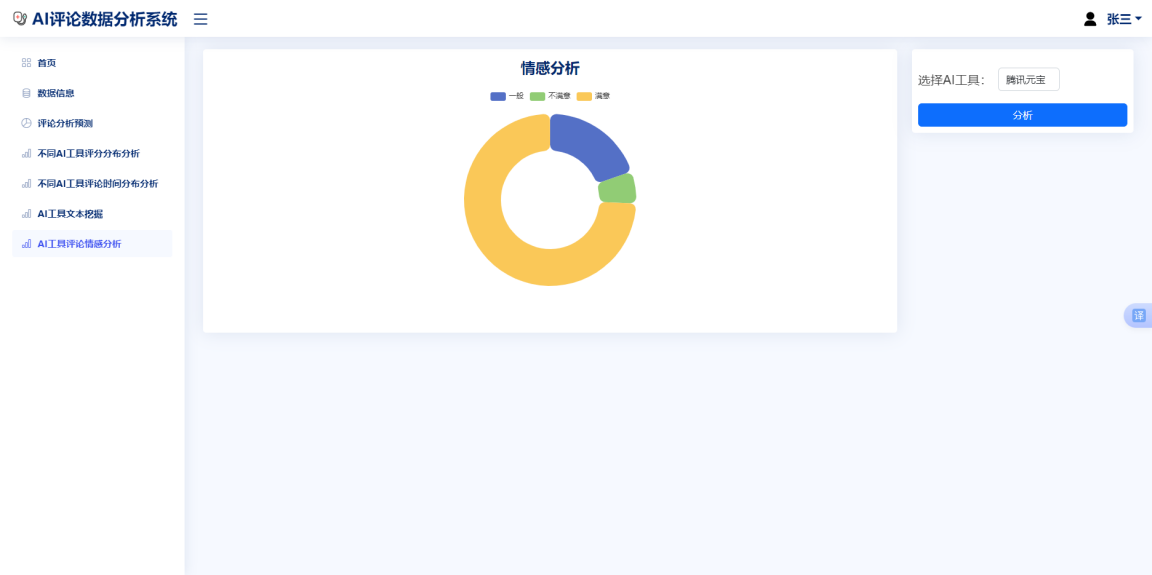
图6.5评论情感分析界面
Python Flask模板继承创建该数据聚类网页的界面,引入bootstrap栅格布局使两个图表均水平排列在屏幕上。该交互面板是HTML文件的上部分,运用静态下拉按钮,静态文本为八种AI工具名称,作为<option>的选项,绑定的ID为player的值,在交互区域单击查询按钮即触发jQueryAjax请求,方法为GET,端点为/kme,发送的内容为所选的AI工具名。:
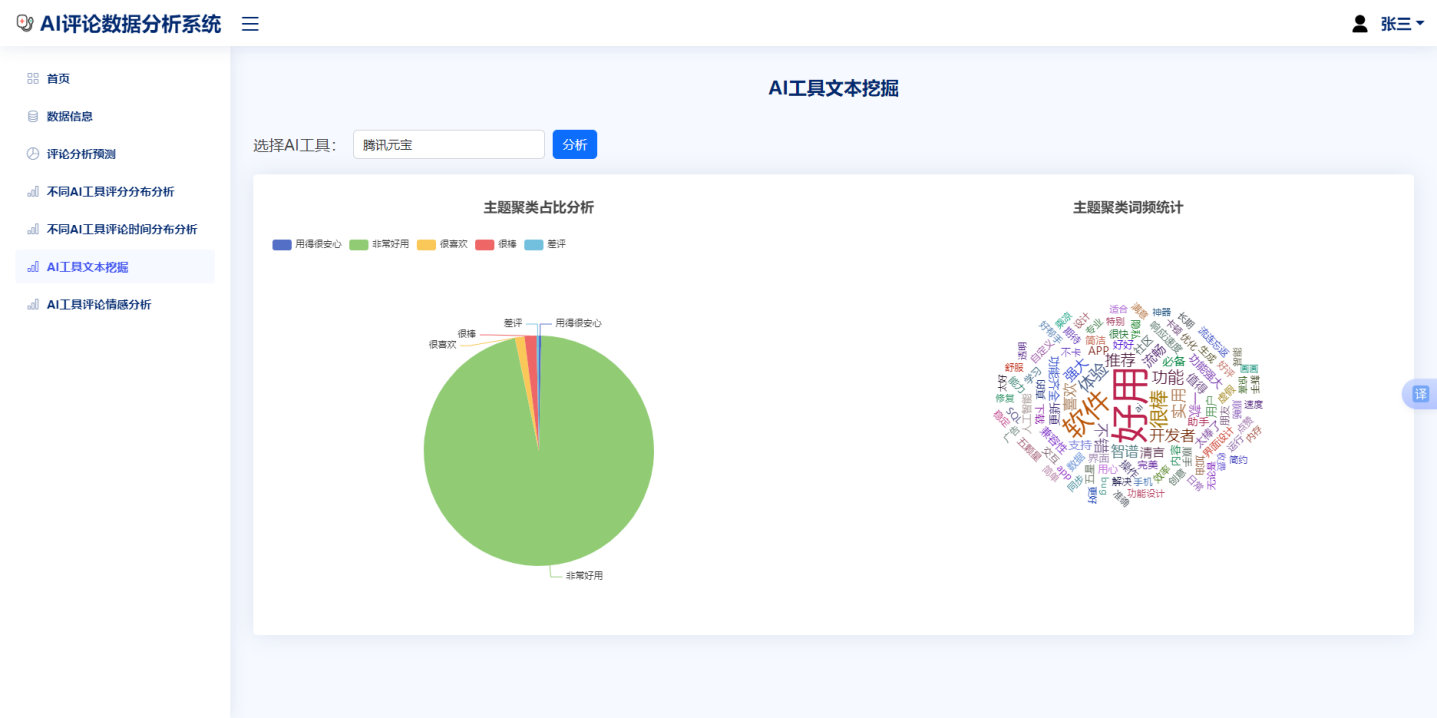
图6.6评论聚类分析界面
6.5情感预测功能实现
首先使用Flask模板继承在视图中创建了一个表单类实例,利用Bootstrap的card组件将页面分为上下两个部分,上部分使用Bootstrap的Form组件布局表单输入样式,并且使用form-row将参数输入框和下拉选项箱并排放置,使用class定义边框,同时定义输入框的名称为slope,form-group用于进行响应式布局,required属性用于下拉选项检查是否被点击确认,因此可以发现除了第一个选项为选择项外,其他三个选项被设置为选择项。最终,效果见图6.7:
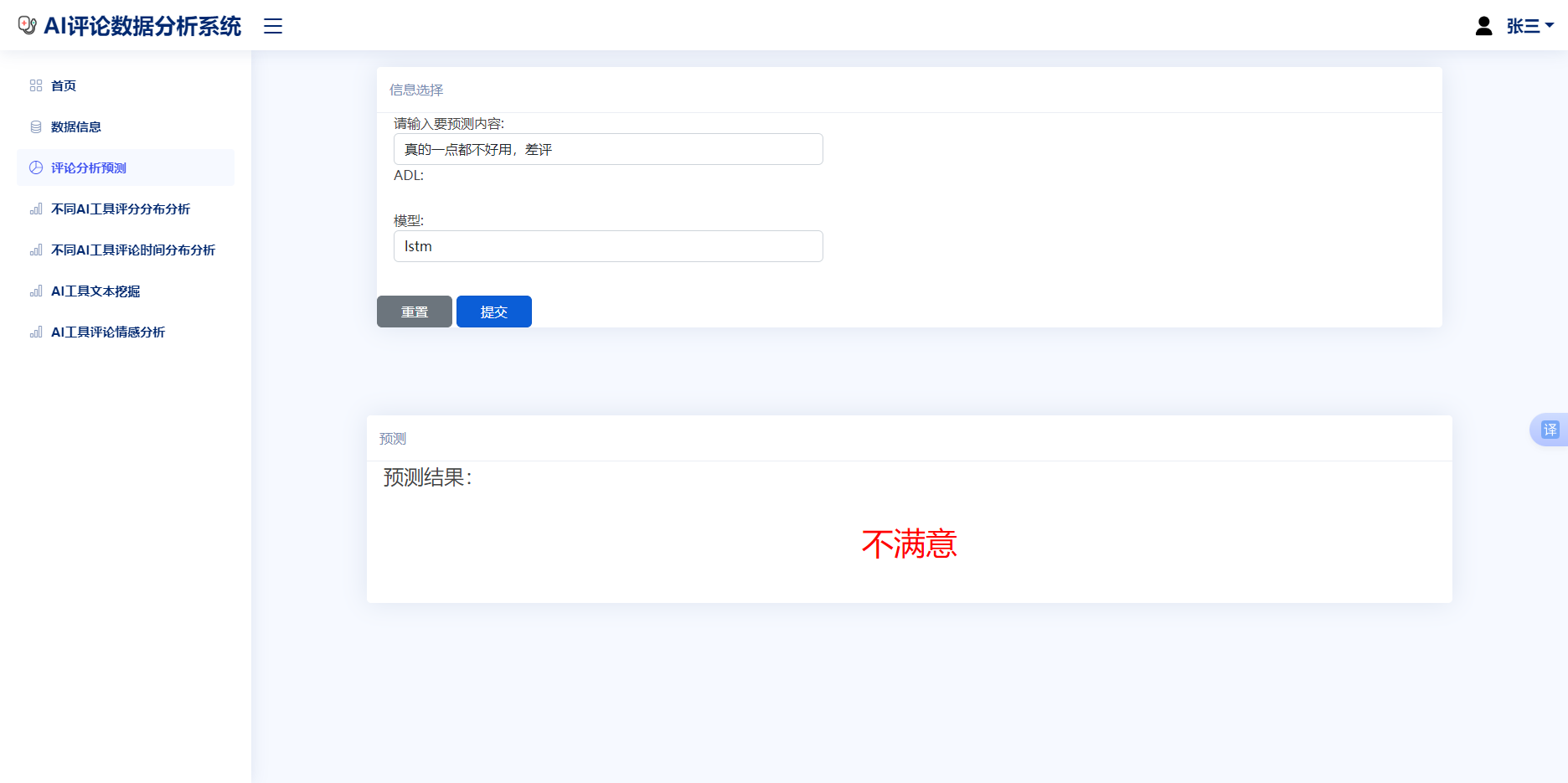
图6.7评论情感预测界面