Elasticsearch服务器开发(第2版) - 读书笔记 第一章 Elasticsearch集群入门
第一章 Elasticsearch集群入门
1.1 全文检索
1.1.1 Lucene词汇表和架构
文档(document): 索引和搜索时使用的主要数据载体,包含一个或多个存在数据的字段
字段(field): 文档的一部分,包含名称和值两部分
词(term): 一个搜索单元,表示文件中的一个词
标记/词元(token): 表示在字段文本中出现的词,由这个词的文本、开始和结束偏移量以及类型组成.
倒排索引
索引额外文件包含了词向量(term vector)、文档值(doc value).
每个索引分为多个"写一次、读多次(write once and read many time)"的段(segment).建立索引时,一个段写入磁盘后就不能再更新.因此被删除的文档信息存储在一个单独的文件中, 单该段自身不能被更新.
然而多个段可以通过**段合并(segment merge)**合并在一起.当强制段合并或者Lucene决定合并时,这些小段就会由Lucene合并成更大的一些段.合并需要I/O.在合并时,不在需要的信息会被删除(例如,被删除的文档).除此之外,检索大段必检索存在相同数据的多个小段的速度更快.在一般情况下,搜索只需要将查询词与那些编入索引的词相匹配.通过多个小段寻找和合并结果,显然会比让一个大段直接提供结果慢的多.
1.1.2 输入数据分析
输入的文档和查询的文本都要转换成可以被搜索的词.这个转换过程称为分析.这个过程我们一般需求会要经过语言分析处理,使得car和cars在索引中被视为是一个,另外以往一些字段只用空格或者小写进行划分.
分析的工作有分析器完成,它由零到多个字符过滤器(Char Filters)加上一个分词器(Tokenizer)和零到多个标记过滤器(Token Filters)组成.
原始文本 -> 字符过滤器(Char Filters) -> 分词器(Tokenizer) -> 标记过滤器(Token Filters) -> 标记流(Token Stream)
常见的过滤器
- 小写过滤器(lowercase filter): 将所有输入的词转换为小写.
- 同义词过滤器(synonyms filter): 基于基本的同义词规则,把一个标记换成另外一个同义的标记.
- 多语言词干提取过滤器(multiple language stemming filter):减小标记(实际上是标记中的文本部分),得到词根或者基本形式,即词干.
过滤器是一个接一个处理的的,所以我们通过使用多个过滤器,可以拓展分析的可能性.
索引和查询
建立索引时,Lucene会使用你选择的分析器来处理你的文档内容.不同的字段可以使用不同的分析器,所以文档的名称字段可以和汇总字段做不通的分析.也可以不分析字段.
查询时,查询将被分析.但是也可以选择不分析.例如前缀和词查询不被分析,匹配查询被分析.可以在被分析和查询和不被分析查询两者中选择非常有用.例如我么查询LightRed这个词,标准分析器分析这个查询后,会去查询light和red,如果我们使用不经分析的查询类型,则会明确的查询LightRed这个词.
在索引和查询分析中,索引应该和查询次匹配.如果不匹配,Lucene不会返回所需的文档.例如在建立索引的时候使用了词干提取和小写,那你应该保证查询中的词也必须是词干和小写、否则,Lucene将不会返回任何结果…重要的是在索引和查询分析时,对所用的标记过滤器保持相同的顺序,这样分析出来的词也是一样的.
1.1.3 评分和查询相关性
评分(scoring),是根据文档和查询的匹配度用计分工时计算的结果.默认情况下Lucene使用TF/IDF(term frequency/inverse document frequency, 词频/逆向文档频率)评分机制.也会有其他评分办法. 评分越高,文档越相关.
1.2 ElasticSearch基础
1.2.1 数据架构的主要概念
1. 索引
索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以他可以分为更小的部分.可以把索引 看成关系数据库中的表.但是索引中的结果是为了快速有效的全文索引准备的,它不存储原始值[注意:原书描述是错误的].(默认_source是开启的,存储的是原始值,但是可以关闭)
关闭_source影响
- 不能使用_reindex写入新索引
- 不能使用_update和script update
- 不能使用 _get 或 fields: _source 获取完整文档
- 不能支持高亮(highlight)默认行为
- 无法使用 _source 过滤返回字段
- 不能使用 painless 脚本引用 ctx._source
2. 文档
存储在Elasticsearch中的主要实体叫文档(document) 。类比与关系数据库中的一行记录,在Elasticsearch中,相同的字段必须是相同的类型,否则会报错.
如果我们不指定字段的类型,那么这个值第一次来的时候会进行推断,作为这个字段的类型,如果后续数据跟当前的不一致的会报错.
如果之前没有某个字段,后续插入的时候新出现了字段,默认情况下是会自动推断类型并且不报错的,但是我们关闭了 动态映射关闭(dynamic: false)就会报错
一种比较好的习惯是我们主动定义mapping,对于不确定的字段可以使用text或keyword 或者使用dynamic_templates
文档由多个字段组成,每个字段可能多次出现在一个文档中,这样的字段叫多值字段(multivalued).每个字段都有类型,如文本、数值、日期.也可以是复杂类型,
3. 文档类型 已经废弃
4. 映射
主要是描述输入文本的内容格式, 定义了Elasticsearch怎么处理这些字段
1.2.2 Elasticsearch 主要概念
-
节点和集群
Elasticsearch可以作为单个节点运行,也可以运行多个相互协作的服务器上。这些服务器称为集群(cluster),形成集群的每个服务器称为节点(node) -
分片
当有大量文档的时候,由于内存的限制、硬盘的能力、处理能力的不足、无法足够快的响应客户端请求。这种情况下,数据可以分为比较小的分片(shard)的部分(每个分片都是一个独立的 apache Lucene索引)。每个分片可以存放在不同的服务器上,因此数据可以在集群中的节点传播。当查询的数据分布在不同的节点上,Elasticsearch会把查询发送给每个相关的分片,并将结果合并到一起,而应用程序不知道分片的存在。此外多个分片可以加快索引。 -
副本
为了提高查询的吞吐量或实现高可用,可以使用分片副本。副本(replica)只是一个分片的精确复制,每个分片可以有零个或多个副本。elasticsearch会有很多相同的分片,其中的一个被选择为主分片(primary shard),复制更改索引操作,其余的为副本分片(replica shard)。在主分片丢失时,,例如所在的服务器不可用的时候,集群将副本提升为新的主分片。
1.2.3 索引的建立和搜索
elasticsearch会帮我们找到对应的索引处理请求
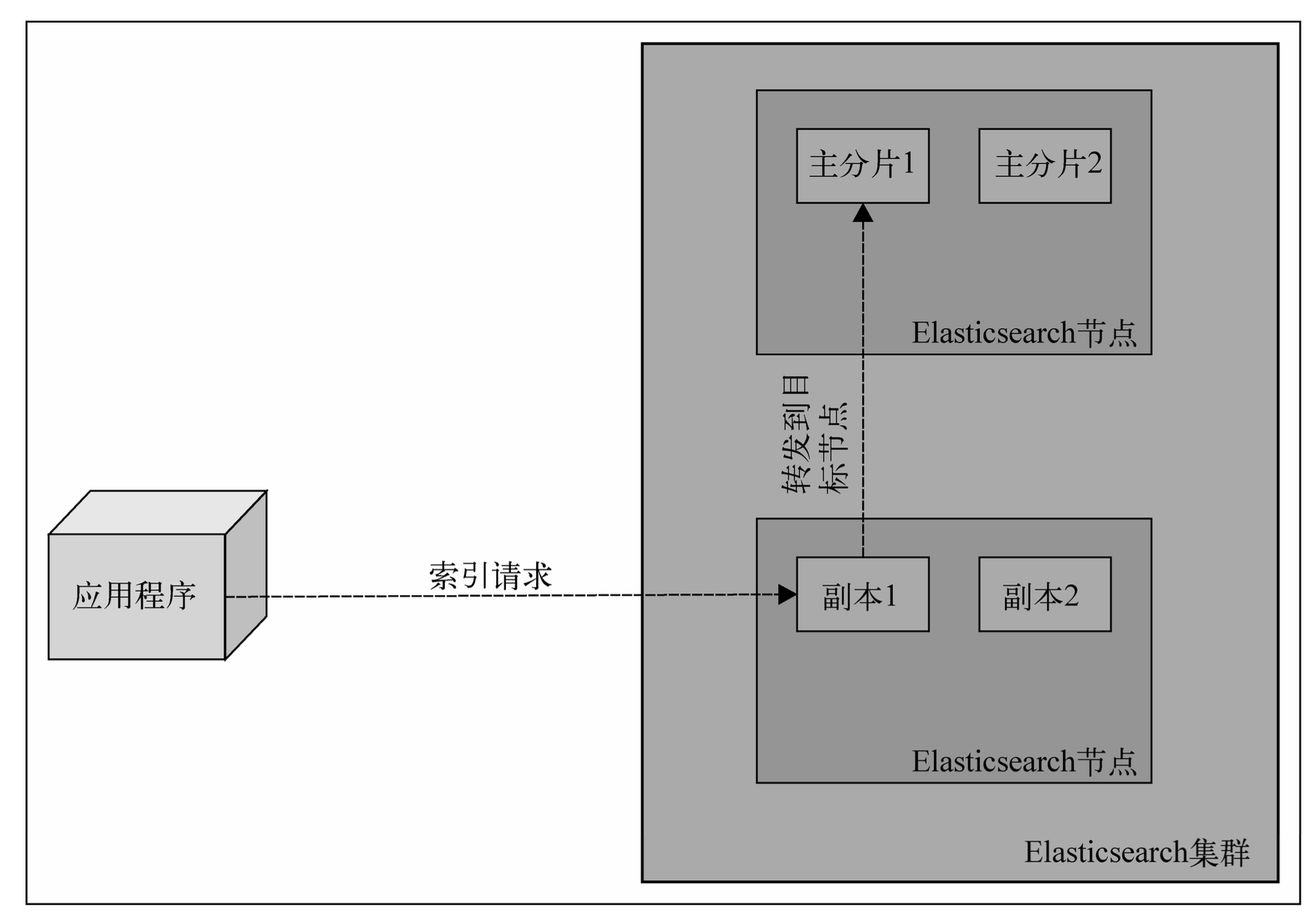
发送一个新文档给集群的时候,你指定一个目标索引并发送他给任意一个节点。这个节点知道目标索引有多少个分片,并且知道那个分片用来存储你的文档。
Elasticsearch使用文档的唯一标识符,来计算文档应该放到哪一个分片中。索引请求发送到一个节点后,该节点会转发文档到持有相关分片的目标节点中。
elasticsearch执行搜索请求
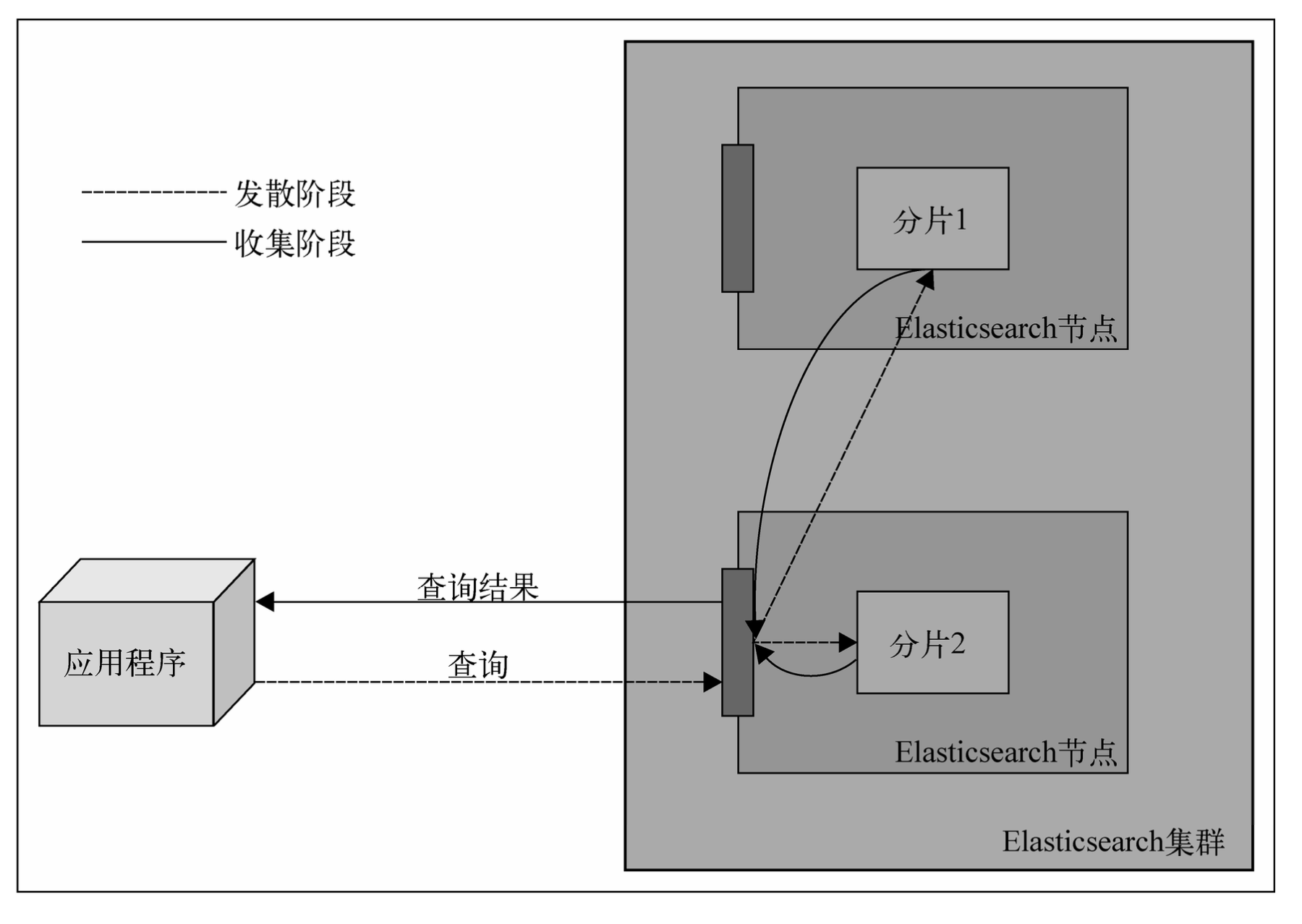
尝试使用文档标识获取文档时,发送查询到一个节点,该节点使用同样的路由算法来决定持有文档的节点和分片,然后转发查询,获取结果,并把结果转发给你。
查询的过程更为复杂。除非使用了路由,查询将直接转发到单个分片,否则,收到查询请求的节点会把查询转发给保存了属于给定索引分片的所有节点,并要求与查询匹配的文档的最少信息(默认情况下时标识符和得分)。这个阶段称为发散阶段(scatter phase)。收到这些信息后,该聚合节点(收到客户端请求的节点)对结果进行排序,并发送第二个请求来获取结果列表的所需的文档(除标识符和得分以外其他的全部信息)。这个阶段称为收集阶段(gather phase)。这个阶段完成后,把数据返回给客户端。
1.3 安装并配置集群
不再赘述
目录作用说明
| 目录 | 描述 |
|---|---|
| bin | 运行elasticsearch实例和插件管理所需要的脚本 |
| config | 配置目录 |
| lib | Elasticsearch 使用的库 |
| data | 数据存储目录 |
| logs | 事件和错误记录的目录 |
| plugins | 存储安装插件的目录 |
| work | 临时文件路径 |
1.4.3 新建文档
使用kibana 请求
PUT /blog/_doc/1
{"title": "New version of Elasticsearch released!","content": "Version 1.0 released today!","tags": ["announce","elasticsearch","release"]
}
返回结果
{
"_index": "blog",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
说明: _id 文档唯一标识
_version 文档版本,递增
使用 curl请求
curl -XPUT http://localhost:9200/blog/_doc/1 -d '{"title": "New version of Elasticsearch released!", "content": "Version 1.0 released today!", "tags": ["announce",
"elasticsearch", "release"] }'
其中 1 是文档标识符,是我们指定的,也可以自动生成,其中PUT请求必须指定标识符,自动生成的使用POST请求,重复请求内容会生成多个文档
eg:自动创建标识符
POST /blog/_doc
{"title": "New version of Elasticsearch released!","content": "Version 1.0 released today!","tags": ["announce","elasticsearch","release"]
}
返回结果
{
"_index": "blog",
"_id": "SoXdL5gBB4N0GQW8y-Wx",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
1.4.4 检索文档
GET /blog/_doc/1
返回结果
{"_index": "blog","_id": "1","_version": 2,"_seq_no": 1,"_primary_term": 1,"found": true,"_source": {"title": "New version of Elasticsearch released!","content": "Version 1.0 released today!","tags": ["announce","elasticsearch","release"]}
}
会发现有新的字段
_source 存储了原始的数据
found : true 表示文档存在
如果查找的文档不存在,结果如下
{"_index": "blog","_id": "2","found": false
}
1.4.5 更新文档
更新索引内部的文档比较复杂.首先Elasticsearch必须先获取文档,从_source属性获取数据,删除旧的文件,更改_sources属性,然后把它作为新的文档来索引.因为信息一旦在Lucene的倒排索引中存储就不能修改.Elasticsearch通过一个带_update参数的脚本来实现.这样就可以做比较简单的修改字段
修改content字
POST /blog/_update/1
{
"script": "ctx._source.content = \"new content\""
}
返回结果
{"_index": "blog","_id": "1","_version": 3,"result": "updated","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 3,"_primary_term": 1
}
修改的时候不需要发送整个文档,但是当我们使用更新功能的时候需要使用_source字段.
当我们更新文档的时候,可以设置一个值用来处理文档中没有该字段的情况.例如,想增加文档中的counter字段,而该字段不存在,可以使用upsert来提供字段的默认值.
POST /blog/_update/1
{"script": {"source": "ctx._source.counter = (ctx._source.counter != null ? ctx._source.counter + 1 : 1)"},"upsert": {"counter": 0}
}
注意如果不判空的时候会报错,upsert 是处理 文档不存在的时候
1.4.6 删除文档
删除文档
DELETE /blog/_doc/1
返回结果
{"_index": "blog","_id": "1","_version": 3,"result": "deleted","_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 9,"_primary_term": 1
}
1.4.7 版本控制
“_version” : 1 这个字段的值是版本号,这个版本号是递增的.默认情况下,在Elasticsearch中添加、修改或者删除的时候都会递增版本号.除了能够记录更该的次数,还能够实现乐观锁(optimistic locking).
例如:
DELETE /blog/_doc/1?version=1&version_type=external
说明: version 参数指定了当前文档的版本号,如果文档的版本号和参数指定的版本号不一致,则返回409错误.
version_type 参数指定了版本号类型,可选值有external,internal,external_gt,external_gte. 默认值是internal[内部]
返回结果
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, current version [2] is higher or equal to the one provided [1]",
"index_uuid": "zh9XTX6hTLqvrl2ZG-CKow",
"shard": "0",
"index": "blog"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, current version [2] is higher or equal to the one provided [1]",
"index_uuid": "zh9XTX6hTLqvrl2ZG-CKow",
"shard": "0",
"index": "blog"
},
"status": 409
}
其他说明:
如果使用下面的
DELETE /blog/_doc/1?version=1
会报错
{
"error": {
"root_cause": [
{
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use if_seq_no and if_primary_term instead;"
}
],
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use if_seq_no and if_primary_term instead;"
},
"status": 400
}
但是在7.x之后的版本使用if_seq_no 和 if_primary_term 实现乐观并发控制
如果需要创建的时候制定版本号
PUT /blog/_doc/1?version=999&version_type=external
{
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"tags": [
"announce",
"elasticsearch",
"release"
]
}
即使文档被移除后,短时间内Elasticsearch仍然可以检查版本号,Elasticsearch保留了删除文档的版本信息.默认情况下,这个信息在60s可用.可以通过修改
index.gc_deletes配置修改这个值
1.5 使用URI请求查询检索
1.5.1 示例数据
POST /books/_doc/1
{"category": "es","title": "Elasticsearch Server","published": 2023
}POST /books/_doc/2
{"category": "es","title": "Mastering Elasticsearch","published": 2023
}POST /books/_doc/3
{"category": "solr","title": "Mastering Elasticsearch","published": 2025
}
ES从8.x彻底取消type,可以使用字段进行区分,或者使用不同的索引,可以减少mapping冲突
查询索引的mapping映射
GET /books/_mapping?pretty
返回结果
{"books": {"mappings": {"properties": {"category": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"published": {"type": "long"},"title": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
}
1.5.2 URI 请求
Elasticsearch的所有查询都会发送到_search端点.可以搜索单个或多个索引
GET /books/_search?pretty
也可以对多个索引执行一个查询
GET /books,blog/_search?pretty
也可以使用通配符来进行索引名称匹配
GET /b*/_search?pretty
也可以不指定索引,匹配所有索引
GET /_search?pretty
- Elasticsearch查询响应
假如在books索引中title字段中包含elasticsearch一词中的所有文档
GET /books/_search?pretty&q=title:elasticsearch
返回结果
{"took": 15,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 3,"relation": "eq"},"max_score": 0.13353139,"hits": [{"_index": "books","_id": "1","_score": 0.13353139,"_source": {"category": "es","title": "Elasticsearch Server","published": 2023}},{"_index": "books","_id": "2","_score": 0.13353139,"_source": {"category": "es","title": "Mastering Elasticsearch","published": 2023}},{"_index": "books","_id": "3","_score": 0.13353139,"_source": {"category": "solr","title": "Mastering Elasticsearch","published": 2025}}]}
}
响应的第一部分展示了请求花费多少时间(took属性,单位是毫秒),有没有超时属性(timed_out属性),执行请求时查询的分片信息,包括查询的分片的数量(_shards对象的total属性)、成功返回结果的分片数量(_shards对象的successful属性)、失败的分片数量(_shards.failed属性)、忽略的分片数量(_shards.skipped属性,执行 跨索引或者跨分片查询时,有多少个 shard 被跳过(未参与搜索))。
可以使用timeout参数来指定查询的最大执行时间,失败的分片可能是分片出问题或者执行搜索时不可用.
hits里面包含我们使用的结果.查询返回的文档总数(total属性)和计算所得订单最高分(max_score属性),还有包含返回文档的hits数组.每个返回的文档包含索引(_index属性)、标识符(_id属性)、分数(_score属性)以及_source字段.
- 查询分析
上面的例子中,使用"Elasticsearch"建立索引,然后使用"elasticsearch"来执行查询,虽然大小写不同,但是还能找到相关文档,原因是查询分析.在建立索引时,底层的Lucene库会根据Elasticsearch配置文件分析文档并建立索引数据.默认情况下,Elasticsearch会告诉Lucene对基于字符串的数据和数字都做索引和分析.查询结果也一样,URI的查询会映射到query_string查询,Elasticsearch会分析它.
使用索引分析API(indices analyze API)可以查看分析过程是什么样的,建立索引时发生了什么,在查询阶段又发生了什么.
GET /books/_analyze
{"text": "Elasticsearch Server"
}
返回结果
{"tokens": [{"token": "elasticsearch","start_offset": 0,"end_offset": 13,"type": "<ALPHANUM>","position": 0},{"token": "server","start_offset": 14,"end_offset": 20,"type": "<ALPHANUM>","position": 1}]
}
可以看到Elasticsearch把文本划分为两个词,第一个标记值(token value)为elasticsearch,第二个标记值为server.
下面看看查询文本是如何被分析的
GET /books/_analyze?pretty
{"text": "elasticsearch"
}
返回结果
{"tokens": [{"token": "elasticsearch","start_offset": 0,"end_offset": 13,"type": "<ALPHANUM>","position": 0}]
}
可以看到,这个词和传到查询的原始值是一样的. 分析之后的索引词和分析之后查询词是一样的,因此该文档与查询匹配并作为结果返回.
- URI查询中的字符参数
查询参数间使用&作为分割符
- 查询 参数q用来指定希望文件匹配的查询条件,eg q=title:elasticsearch
- 默认查询字段 参数df用来指定默认查询字段,默认是_all字段,eg df=title
- 分析器 参数analyzer用来指定查询分析器名称.默认情况下,索引阶段对字段内容做分析的分析器将用来分析我们的查询
- 默认操作符 参数default_operator用来指定查询中的默认操作符可以是OR或AND,用来指定查询的默认布尔运算符.默认是OR,只要有一个条件匹配就返回文档.
- 查询解释 如果将explain参数设置为true,Elasticsearch会返回查询的详细解释信息,如文档是在哪个分片上获取的、计算得分的详细信息.但是不要在正常的查询上设置explain会影响性能
GET /books/_search?pretty&q=title:elasticsearch&df=title&analyzer=standard&default_operator=AND&explain=true
返回结果
{"took": 7,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 3,"relation": "eq"},"max_score": 0.13353139,"hits": [{"_shard": "[books][0]","_node": "_TQP_g3ORGu4qozsEApJbw","_index": "books","_id": "1","_score": 0.13353139,"_source": {"category": "es","title": "Elasticsearch Server","published": 2023},"_explanation": {"value": 0.13353139,"description": "weight(title:elasticsearch in 0) [PerFieldSimilarity], result of:","details": [{"value": 0.13353139,"description": "score(freq=1.0), computed as boost * idf * tf from:","details": [{"value": 2.2,"description": "boost","details": []},{"value": 0.13353139,"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details": [{"value": 3,"description": "n, number of documents containing term","details": []},{"value": 3,"description": "N, total number of documents with field","details": []}]},{"value": 0.45454544,"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details": [{"value": 1,"description": "freq, occurrences of term within document","details": []},{"value": 1.2,"description": "k1, term saturation parameter","details": []},{"value": 0.75,"description": "b, length normalization parameter","details": []},{"value": 2,"description": "dl, length of field","details": []},{"value": 2,"description": "avgdl, average length of field","details": []}]}]}]}},{"_shard": "[books][0]","_node": "_TQP_g3ORGu4qozsEApJbw","_index": "books","_id": "2","_score": 0.13353139,"_source": {"category": "es","title": "Mastering Elasticsearch","published": 2023},"_explanation": {"value": 0.13353139,"description": "weight(title:elasticsearch in 0) [PerFieldSimilarity], result of:","details": [{"value": 0.13353139,"description": "score(freq=1.0), computed as boost * idf * tf from:","details": [{"value": 2.2,"description": "boost","details": []},{"value": 0.13353139,"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details": [{"value": 3,"description": "n, number of documents containing term","details": []},{"value": 3,"description": "N, total number of documents with field","details": []}]},{"value": 0.45454544,"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details": [{"value": 1,"description": "freq, occurrences of term within document","details": []},{"value": 1.2,"description": "k1, term saturation parameter","details": []},{"value": 0.75,"description": "b, length normalization parameter","details": []},{"value": 2,"description": "dl, length of field","details": []},{"value": 2,"description": "avgdl, average length of field","details": []}]}]}]}},{"_shard": "[books][0]","_node": "_TQP_g3ORGu4qozsEApJbw","_index": "books","_id": "3","_score": 0.13353139,"_source": {"category": "solr","title": "Mastering Elasticsearch","published": 2025},"_explanation": {"value": 0.13353139,"description": "weight(title:elasticsearch in 0) [PerFieldSimilarity], result of:","details": [{"value": 0.13353139,"description": "score(freq=1.0), computed as boost * idf * tf from:","details": [{"value": 2.2,"description": "boost","details": []},{"value": 0.13353139,"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details": [{"value": 3,"description": "n, number of documents containing term","details": []},{"value": 3,"description": "N, total number of documents with field","details": []}]},{"value": 0.45454544,"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details": [{"value": 1,"description": "freq, occurrences of term within document","details": []},{"value": 1.2,"description": "k1, term saturation parameter","details": []},{"value": 0.75,"description": "b, length normalization parameter","details": []},{"value": 2,"description": "dl, length of field","details": []},{"value": 2,"description": "avgdl, average length of field","details": []}]}]}]}}]}
}
- 返回字段 默认情况下,返回每个文档中, Elasticsearch将包含索引名称、文档标识符、得分和_source字段. 可以通过添加field参数并指定一个逗号分割的字段名称列表.这些字段将在存储字段或内部的_source字段中检索.默认参数值是_source.举例: field=title
- 结果排序 通过sort参数,可以自定义排序. 默认是按照得分降序排列.例如: sort=published:desc,如果自定义排序,Elasticsearch将省略计算文档的_score字段.如果既要排序,又要计算文档的_score字段,可以通过设置track_scores参数为true.
- 搜索超时 默认情况下没有查询超时.按时我们可以通过timeout参数设置查询超时.例如: timeout=5s
- 查询结果窗口 通过from和size参数,可以指定查询结果窗口.例如: from=0,size=10,可以完成分页功能
- 搜索类型 通过search_type参数,可以指定搜索类型.默认是query_then_fetch[查询后获取]. dfs_query_then_fetch.其他的基本弃用了.
| 搜索类型 | 是否执行 DFS(全局词频统计) | 排序准确性 | 描述 |
|---|---|---|---|
| query_then_fetch | 否 | 中 | 默认搜索类型,默认高效搜索,先执行查询,再获取结果 |
| dfs_query_then_fetch | 是 | 高 | 对 score 极度敏感时用(如广告推荐) |
- 小写扩展词 一些查询使用的查询扩展,比如前缀查询(prefix query),可以使用lowercase_expanded_terms属性来定义扩展词是否应该转换为小写.默认是true.
- 分析通配符和前缀 默认情况下,通配符查询和前缀查询不会被分析.如果要更改,可以吧analyze_wildcard属性设置为true.
1.5.3 Lucene查询语法
完整语法地址:https://lucene.apache.org/core/10_2_2/queryparser/org/apache/lucene/queryparser/classic/package-summary.html
传入Lucene的查询被查询解析器分为词(term)和操作符(operator).词可以有两种类型:单词和短语.eg: title:book 短语 title:“elasticsearch book”
Lucene查询语法支持操作符. 操作符+告诉Lucene给定部分必须在文档中匹配.操作符-相反,这一部分不能出现在文档中.即没有+也没有-的话是可以匹配、但是非强制性
的查询.所以想找titl字段包含book但是description字段不包含cat的文档可以 +title:book -description:cat. 也可以使用括号来组合多个词 title:(crime punishment)
还可以使用^操作符接上一个值来助推(boost)一个词,如 title:book^4 来加强这个词的相关性
其他说明
内容和图书可以见,持续更新中
Elasticsearch读书笔记
如果需要部署可以参考
docker compose搭建elk 8.6.2
或者直接下载,单机版的开箱即用