SQL基础④ | 多表查询篇
0 序言
本文将系统讲解多表查询的概念、类型、实现方法及相关语法,
包括笛卡尔积的处理、各类连接、SQL99语法规范及UNION的使用。
通过学习能初步掌握多表查询的逻辑与操作,解决复杂数据关联查询问题。
1 多表查询基础
多表查询,或者叫关联查询。
指通过关联字段将两个或多个表联合查询,前提是表之间存在如一对一、一对多这些关系,且有共同的关联字段。
1.1 案例引出的多表连接问题
需从employees(员工表)、departments(部门表)、locations(位置表)中联合获取数据,如员工姓名及所属部门名称。
当直接查询两个表时,若未加连接条件,会产生笛卡尔积(交叉连接),
即两表所有行的组合,结果行数为两表行数的乘积
加入有107行员工表跟27行部门表,那么此时行数就为两者乘积2889行,数据无意义。
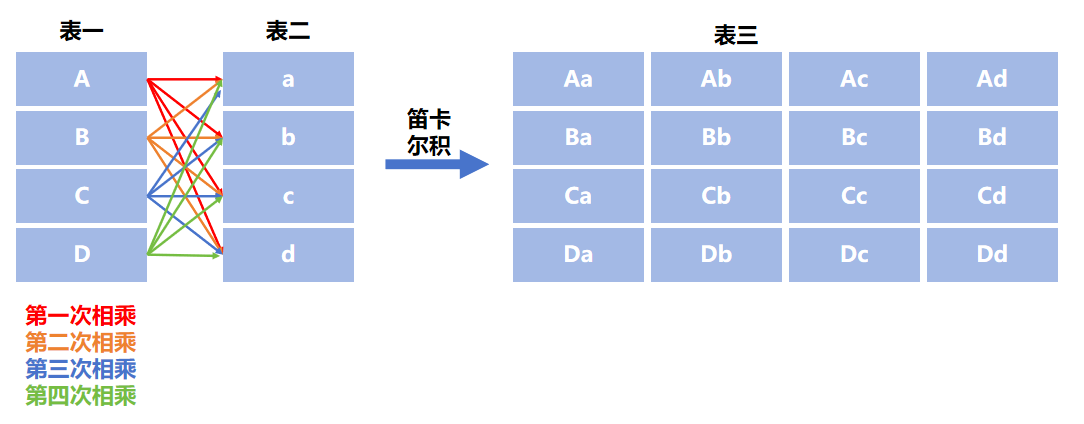
1.2 笛卡尔积的理解与解决
1.2.1 笛卡尔积概念
数学上指两个集合所有可能的组合,
在SQL中若多表查询未加有效连接条件,会返回两表所有行的交叉组合,属于无效结果!!!
具体的运算的过程如下:
1.2.2 产生原因
- 省略表的连接条件;
- 连接条件无效;
- 所有表的行无差别连接。
1.2.3 解决方法
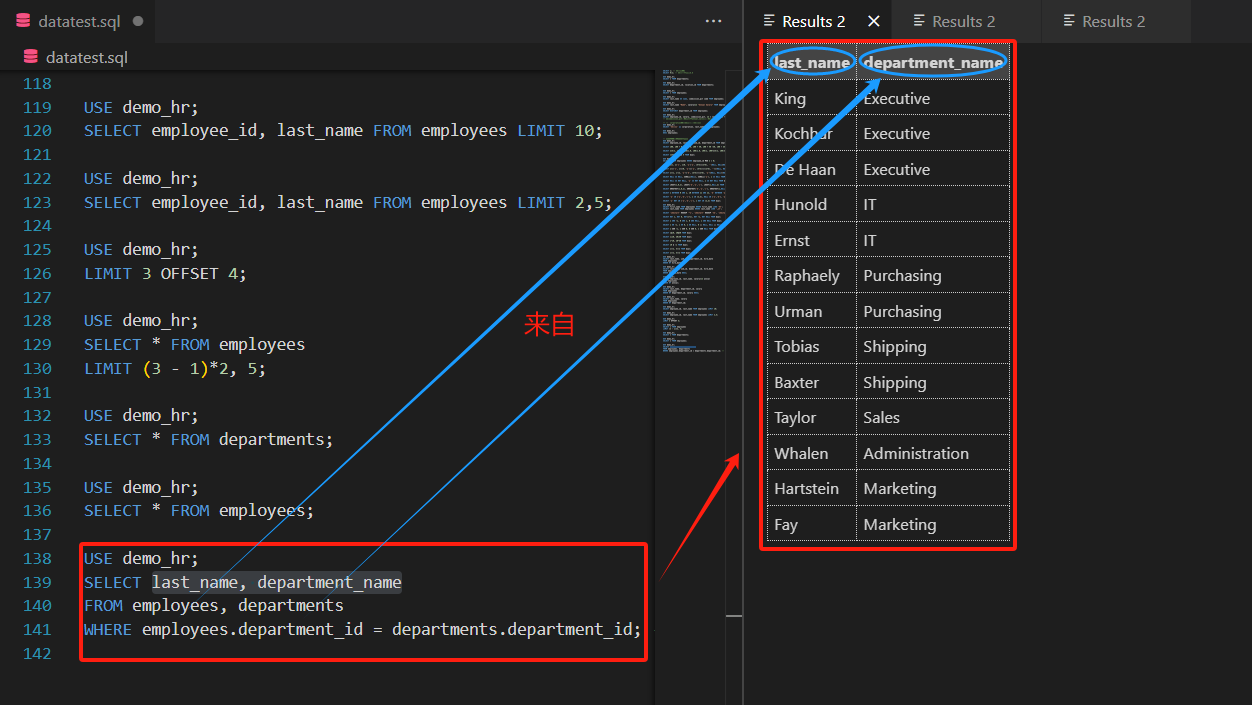
在WHERE子句中添加有效的连接条件,过滤掉无效组合。例如查询员工姓名和部门名称:
SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id; -- 关联条件:部门ID相等
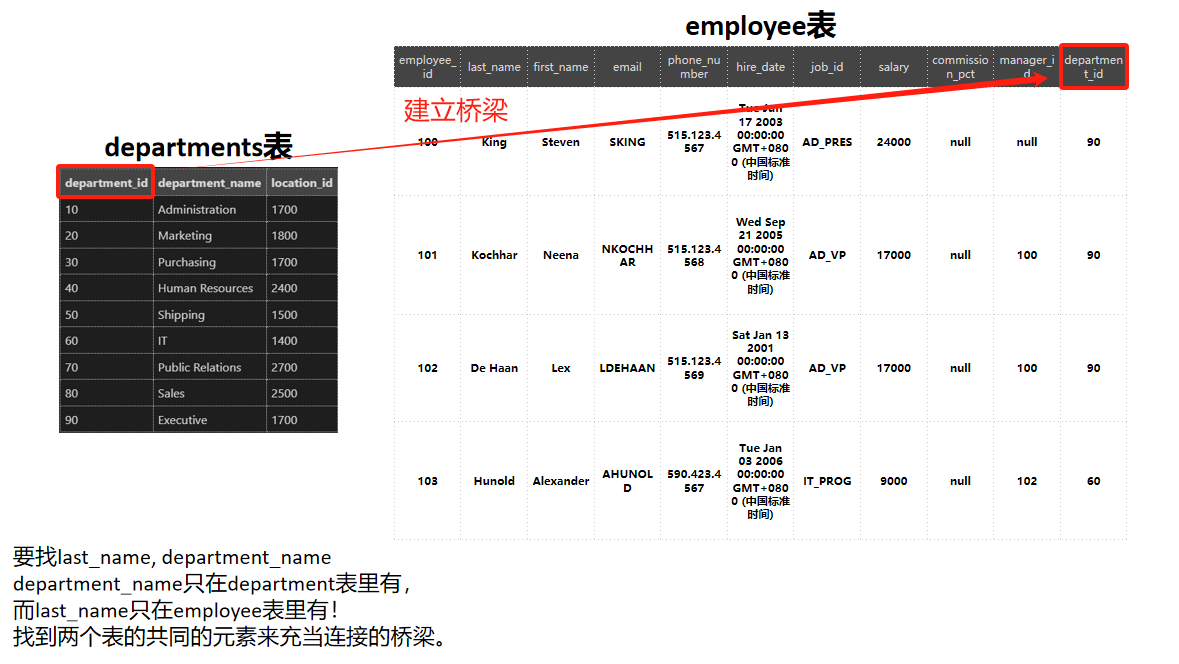
所以通过这种方式来建立两个表之间的联系。
2 多表查询分类
2.1 等值连接 vs 非等值连接
2.1.1 等值连接
- 定义:通过两表中相等的关联字段进行连接,
如员工表和部门表的department_id,上面刚刚给的例子就是等值连接。 - 操作要点:
- 多表有相同列时,需用表名或别名前缀区分(如
e.department_id); - 可使用表别名简化查询(如
employees e、departments d); - 连接
n个表需至少n-1个连接条件。
- 多表有相同列时,需用表名或别名前缀区分(如
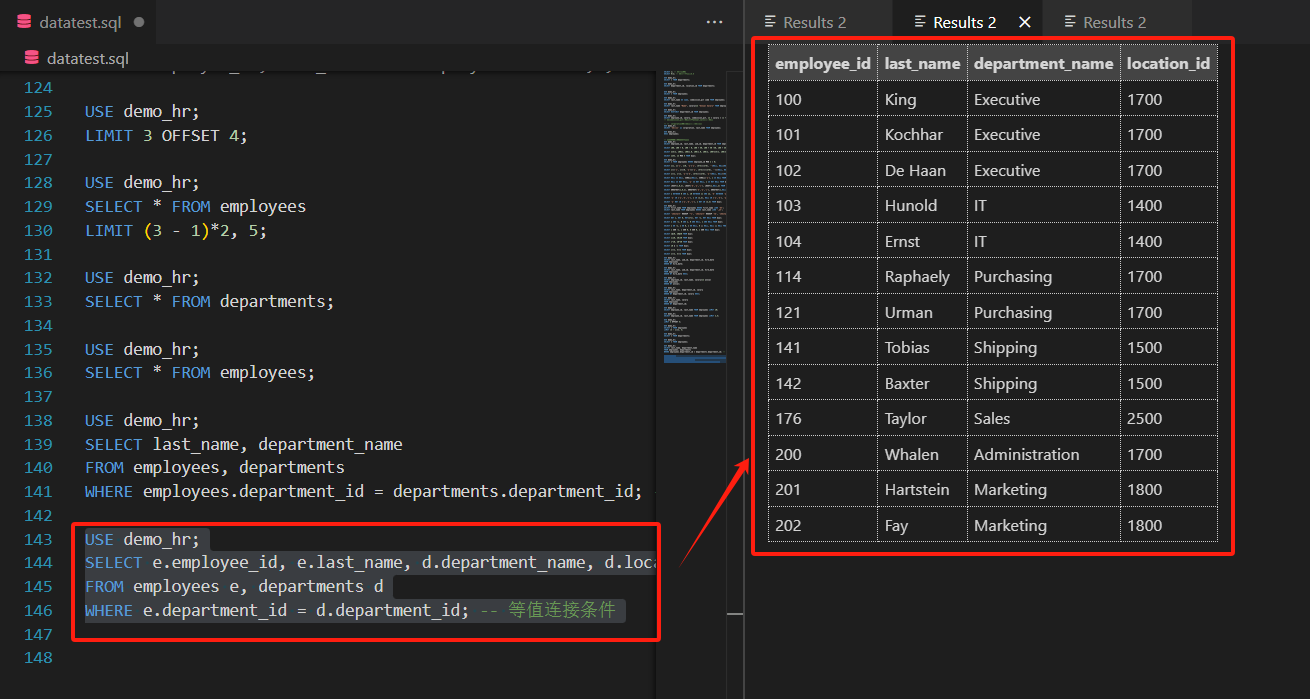
- 示例:查询员工ID、姓名、部门名称及位置ID
SELECT e.employee_id, e.last_name, d.department_name, d.location_id
FROM employees e, departments d
WHERE e.department_id = d.department_id; -- 等值连接条件
这个跟刚刚的例子是一样的。
2.1.2 非等值连接
- 定义:连接条件为范围或不等式,而非字段相等(如员工工资与工资等级表的范围匹配)。
- 示例:查询员工姓名、工资及对应的工资等级(
job_grades表含lowest_sal和highest_sal)
SELECT e.last_name, e.salary, j.grade
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal; -- 非等值条件(范围匹配)
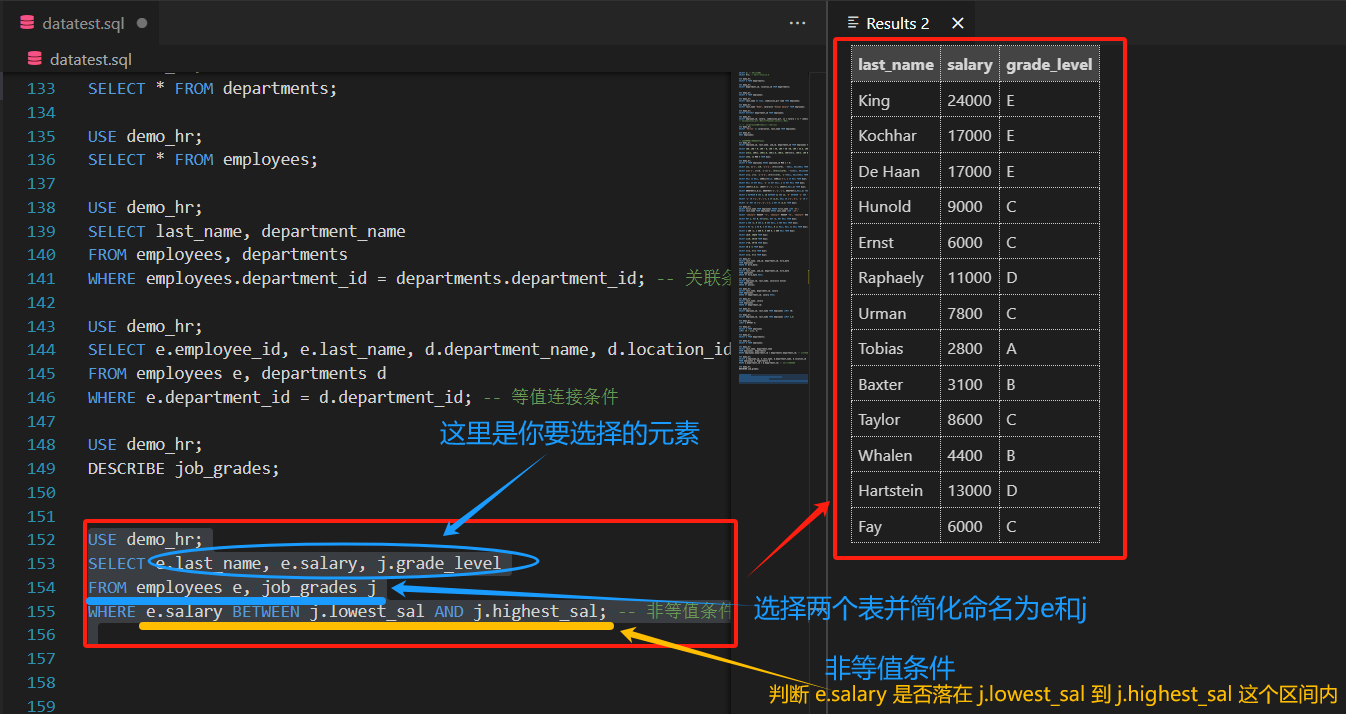
核心点在于:逐行匹配 employees 和 job_grades 表,只有员工工资符合等级区间时,才会把这两行数据 “拼接” 成一条结果返回。
2.2 自连接 vs 非自连接
2.2.1 自连接
- 定义:同一表通过别名虚拟为两张表(如“员工表”和“经理表”),通过关联字段连接(如员工的
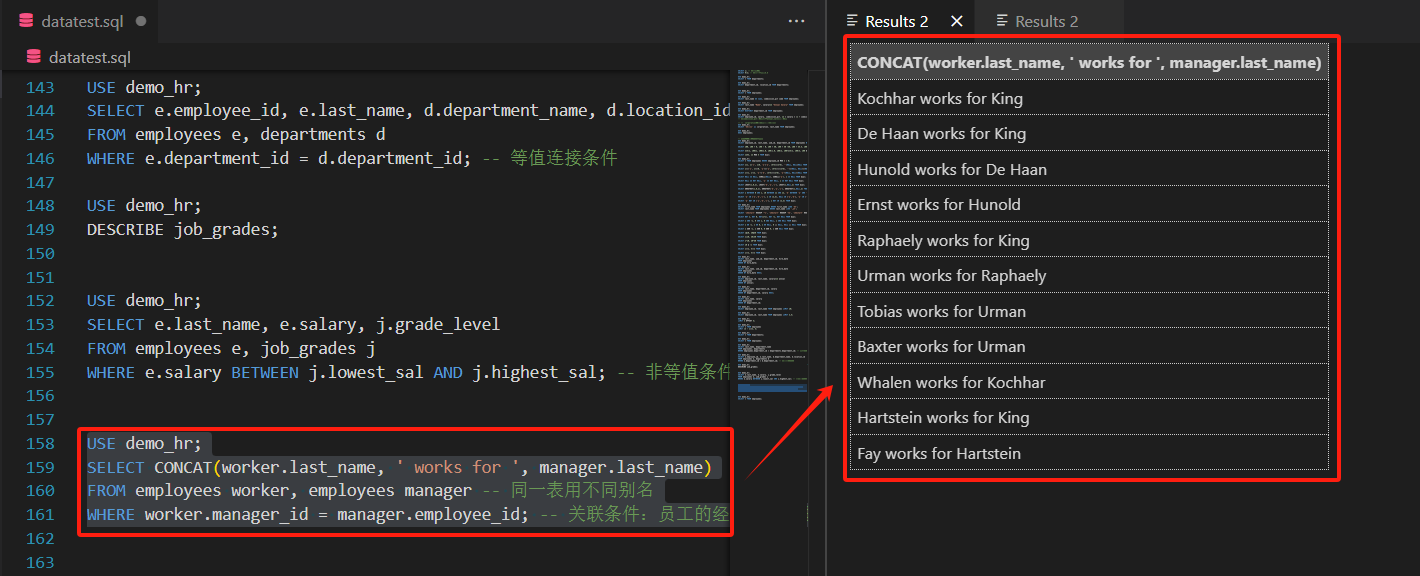
manager_id与经理的employee_id)。 - 示例:查询员工及其直属经理的姓名
SELECT CONCAT(worker.last_name, ' works for ', manager.last_name)
FROM employees worker, employees manager -- 同一表用不同别名
WHERE worker.manager_id = manager.employee_id; -- 关联条件:员工的经理ID=经理的员工ID
这里解释一下,为什么同一表里却要用不同的别名,
这个是因为数据库里实际只有 1 张 employees 表,
但查询需求是 “员工(worker )” 和 “经理(manager )” 的关联
也就是说,员工的 manager_id 对应经理的 employee_id 。
用别名 worker 和 manager 后,SQL 会把 employees 表逻辑上拆成两张虚拟表:
worker:代表员工角色,取的是员工的 last_name、manager_id 等数据。
manager:代表经理角色,取的是经理的 employee_id、last_name 等数据。
这是自连接查询的核心技巧,为了在逻辑上把一张表拆成多张虚拟表,解决字段冲突、清晰表达关联逻辑。
2.2.2 非自连接
- 定义:连接的表为不同表(如员工表与部门表),是最常见的多表查询形式,前述等值/非等值连接多为非自连接。
看看下面这个例子:
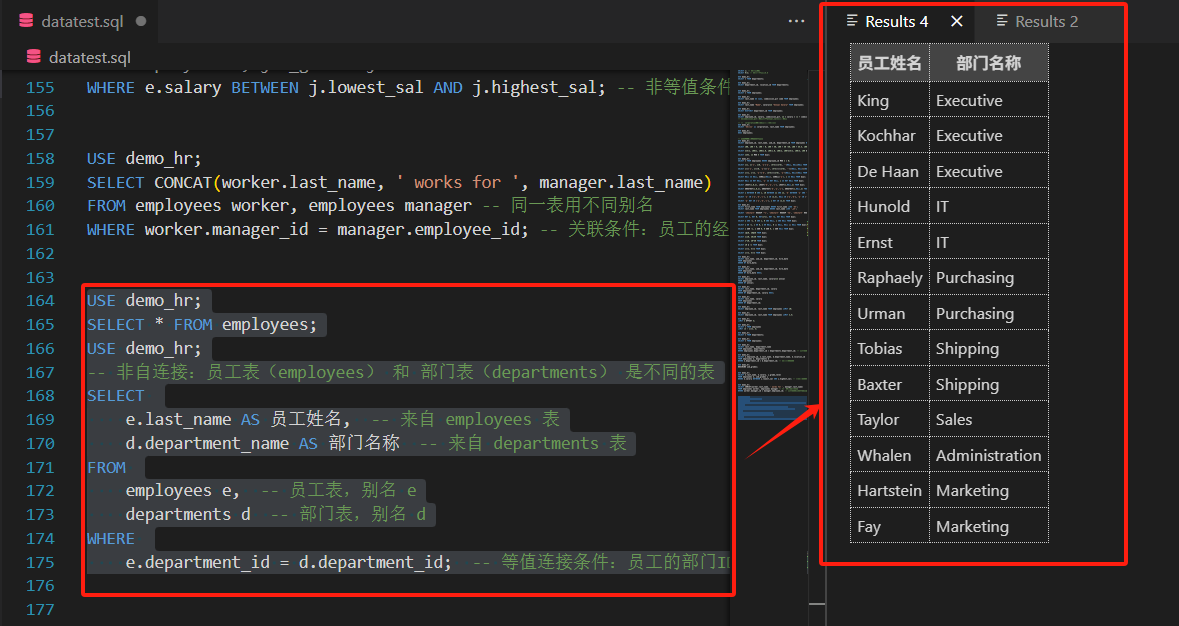
USE demo_hr;-- 非自连接:员工表(employees) 和 部门表(departments) 是不同的表
SELECT e.last_name AS 员工姓名, -- 来自 employees 表d.department_name AS 部门名称 -- 来自 departments 表
FROM employees e, -- 员工表,别名 edepartments d -- 部门表,别名 d
WHERE e.department_id = d.department_id; -- 等值连接条件:员工的部门ID = 部门的ID
我们可以看到,查询员工姓名和对应的部门名称
这里包含两张不同的表,通过 department_id 关联
所以这属于非自连接。
2.3 内连接 vs 外连接
2.3.1 内连接
- 定义:仅返回两表中满足连接条件的行,不包含不匹配的行。
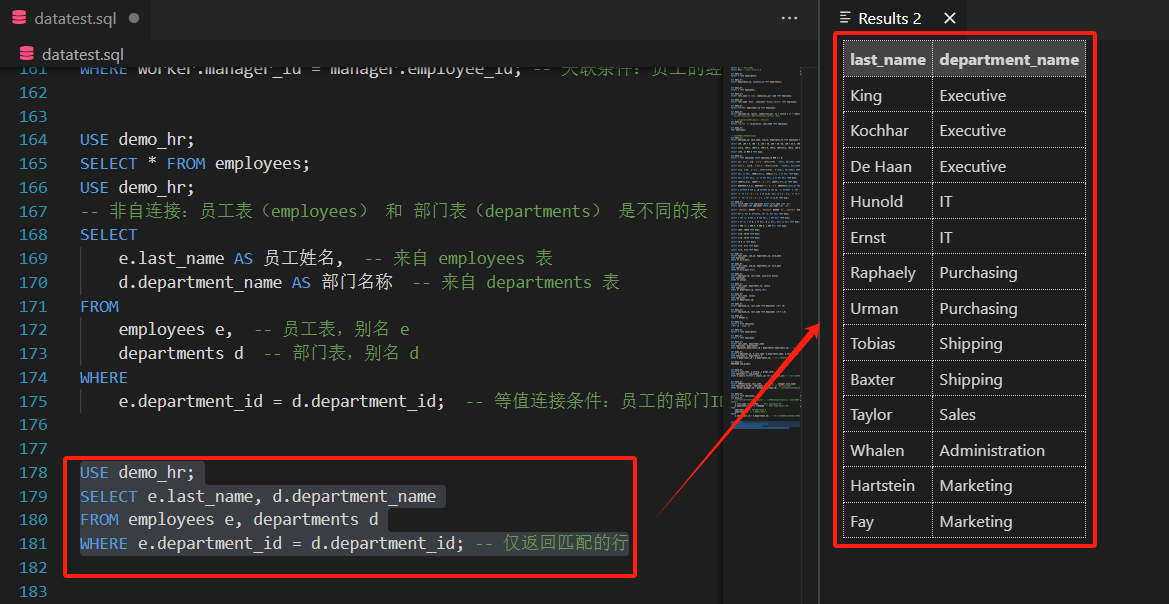
- 示例(SQL92语法):查询员工及其所属部门,仅显示有部门的员工
SELECT e.last_name, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id; -- 仅返回匹配的行
2.3.2 外连接
- 定义:除返回匹配行外,还返回某一表中不满足条件的行(主表的所有行),分为左外连接、右外连接和满外连接。
- 左外连接:以左表为主表,返回左表所有行及右表匹配行(右表无匹配则为NULL)。
示例(SQL99语法):SELECT e.last_name, d.department_name FROM employees e LEFT OUTER JOIN departments d ON e.department_id = d.department_id; -- 包含无部门的员工 - 右外连接:以右表为主表,返回右表所有行及左表匹配行(左表无匹配则为NULL)。
示例(SQL99语法):SELECT e.last_name, d.department_name FROM employees e RIGHT OUTER JOIN departments d ON e.department_id = d.department_id; -- 包含无员工的部门 - 满外连接:返回两表所有行(匹配及不匹配的),MySQL不直接支持,需用
LEFT JOIN UNION RIGHT JOIN模拟。
3 SQL99语法实现多表查询
SQL99通过JOIN...ON语法实现连接,结构更清晰,支持内连接、外连接等,层次性更强。
3.1 基本语法
SELECT 字段列表
FROM 表1
JOIN 表2 ON 表1与表2的连接条件
JOIN 表3 ON 表2与表3的连接条件; -- 连接多个表时逐层添加
ON子句专门用于指定连接条件,与其他过滤条件分离,可读性更高;INNER JOIN(可省略INNER)表示内连接,LEFT/RIGHT OUTER JOIN(可省略OUTER)表示外连接。
3.2 内连接(INNER JOIN)
- 语法:
SELECT 字段列表 FROM 表A INNER JOIN 表B ON 表A.关联字段 = 表B.关联字段; - 示例:查询员工、部门及所在城市(连接3个表)
SELECT e.employee_id, d.department_name, l.city FROM employees e JOIN departments d ON e.department_id = d.department_id JOIN locations l ON d.location_id = l.location_id; -- 第2个连接条件
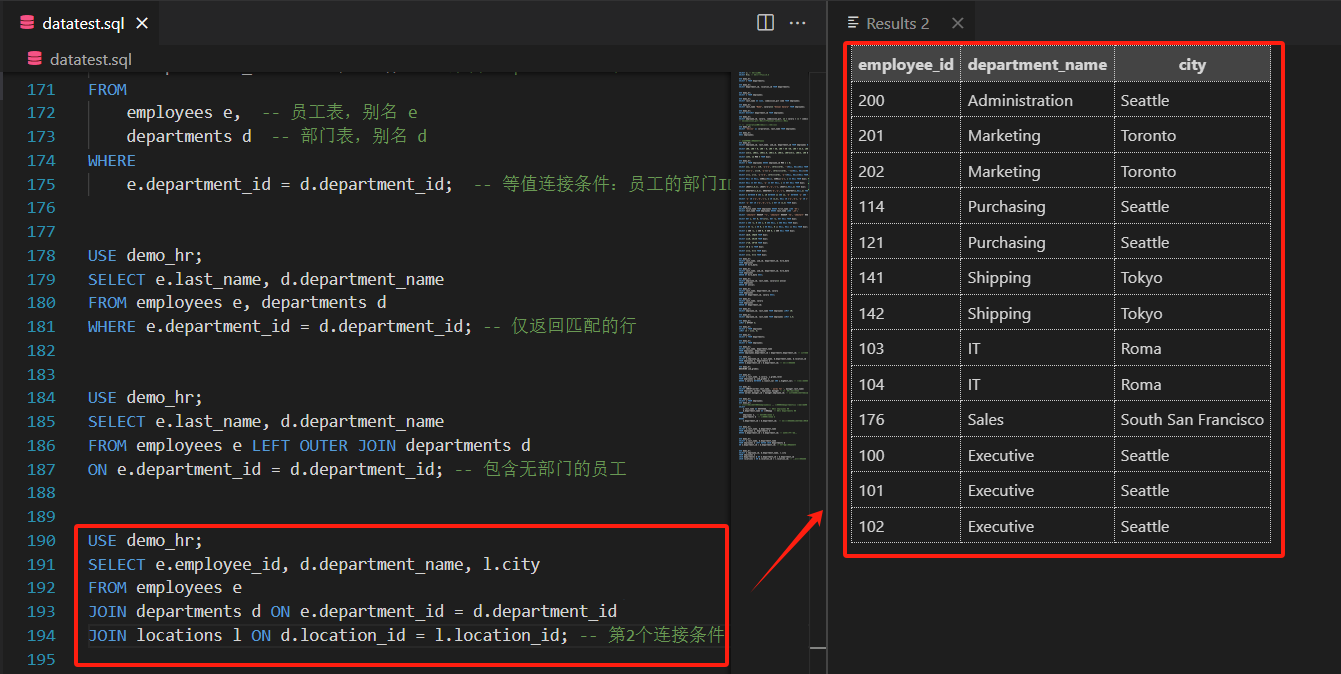
结构清洗可见,
就把用户所要的信息拿出来了。
3.3 外连接(OUTER JOIN)
- 左外连接:
SELECT 字段列表 FROM 表A LEFT JOIN 表B ON 表A.关联字段 = 表B.关联字段; -- 表A为主体
举个例子吧,
USE demo_hr;
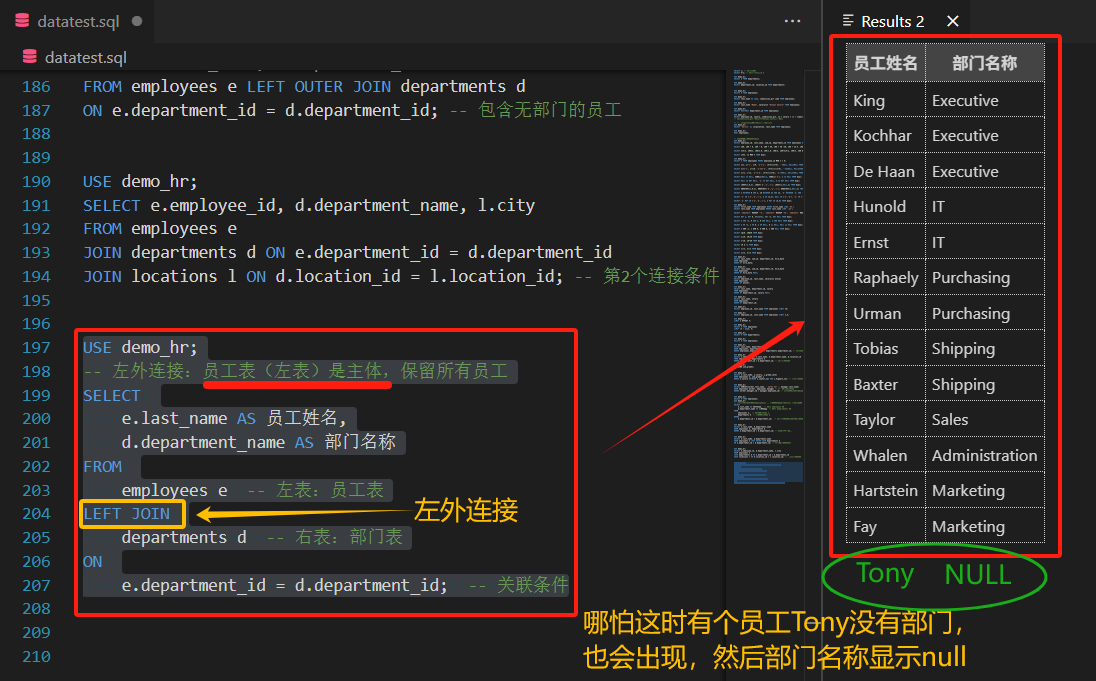
-- 左外连接:员工表(左表)是主体,保留所有员工
SELECT e.last_name AS 员工姓名,d.department_name AS 部门名称
FROM employees e -- 左表:员工表
LEFT JOIN departments d -- 右表:部门表
ON e.department_id = d.department_id; -- 关联条件
它的特点就是:查询所有员工的姓名,以及他们所属的部门名称,
即使员工没有部门,也要显示员工信息!!!
- 右外连接:
SELECT 字段列表 FROM 表A RIGHT JOIN 表B ON 表A.关联字段 = 表B.关联字段; -- 表B为主体
跟左外连接要做对比,如:
USE demo_hr;
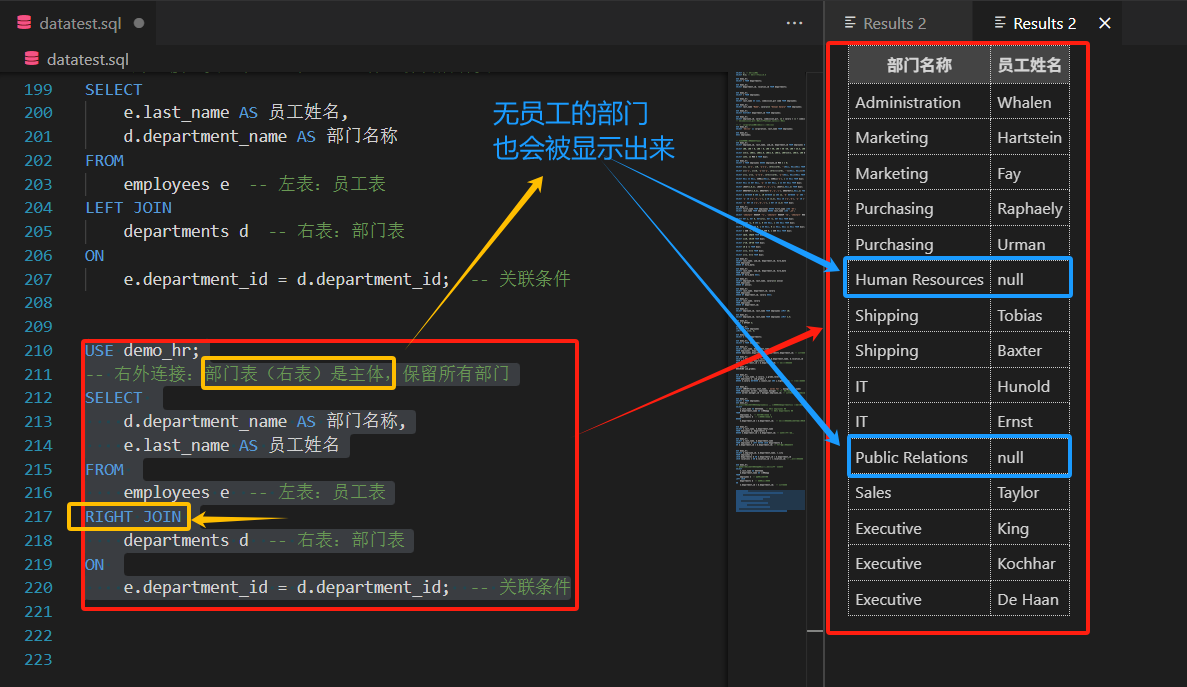
-- 右外连接:部门表(右表)是主体,保留所有部门
SELECT d.department_name AS 部门名称,e.last_name AS 员工姓名
FROM employees e -- 左表:员工表
RIGHT JOIN departments d -- 右表:部门表
ON e.department_id = d.department_id; -- 关联条件
它的特点是:所有部门都会显示,包括没有员工的部门,
哪怕这个部门没有员工,员工姓名 会显示 NULL!!!
这部分的内容好好感受一下,要理解清楚。
4 UNION的使用
用于合并多个SELECT语句的结果集,要求列数和数据类型一致。
4.1 语法与区别
UNION:合并结果并去除重复行;UNION ALL:合并结果保留重复行(效率更高,推荐在确定无重复时使用)。
4.2 示例
查询邮箱含a或部门编号>90的员工信息:
-- 方式1:OR
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id > 90;-- 方式2:UNION(去重)
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id > 90;
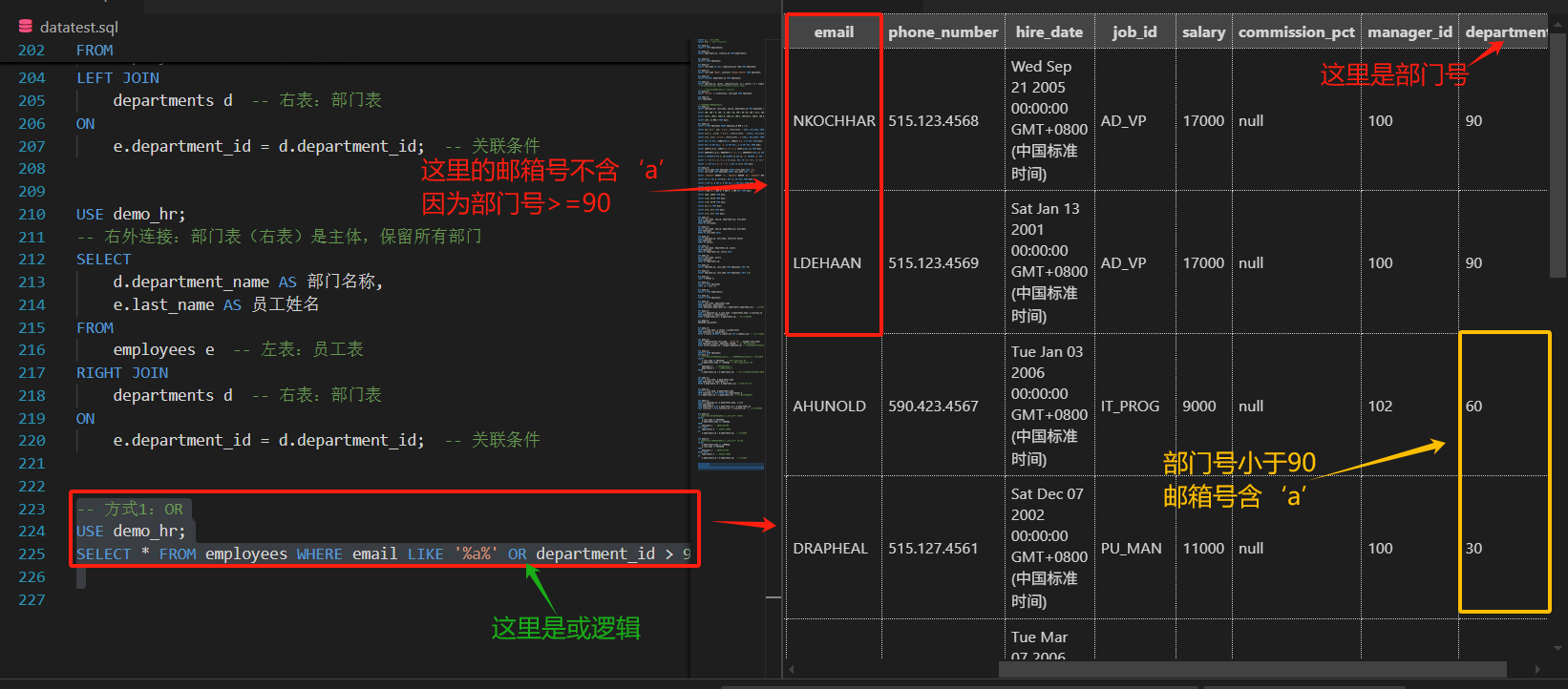
但是这里的话还是会有重复项。
用方式2就可以去除重复。
可以自己试一下,加深理解。
5 7种SQL JOIN的实现
基于内连接、外连接的组合,可实现7种数据关联查询场景,核心是控制匹配行与不匹配行的返回:
| 场景 | 实现方式 |
|---|---|
| 内连接(A∩B) | SELECT ... FROM A JOIN B ON 条件 |
| 左外连接(A全部) | SELECT ... FROM A LEFT JOIN B ON 条件 |
| 右外连接(B全部) | SELECT ... FROM A RIGHT JOIN B ON 条件 |
| A独有的行(A-A∩B) | SELECT ... FROM A LEFT JOIN B ON 条件 WHERE B.关联字段 IS NULL |
| B独有的行(B-A∩B) | SELECT ... FROM A RIGHT JOIN B ON 条件 WHERE A.关联字段 IS NULL |
| 满外连接(A∪B) | 左外连接结果 UNION ALL 右外连接结果(MySQL模拟) |
| 对称差(A∪B-A∩B) | A独有行 UNION ALL B独有行 |
6 SQL99语法新特性
6.1 自然连接(NATURAL JOIN)
自动匹配两表中所有同名字段并进行等值连接,无需手动指定关联条件。
示例:等价于通过department_id和manager_id等值连接
SELECT employee_id, last_name, department_name
FROM employees e NATURAL JOIN departments d;
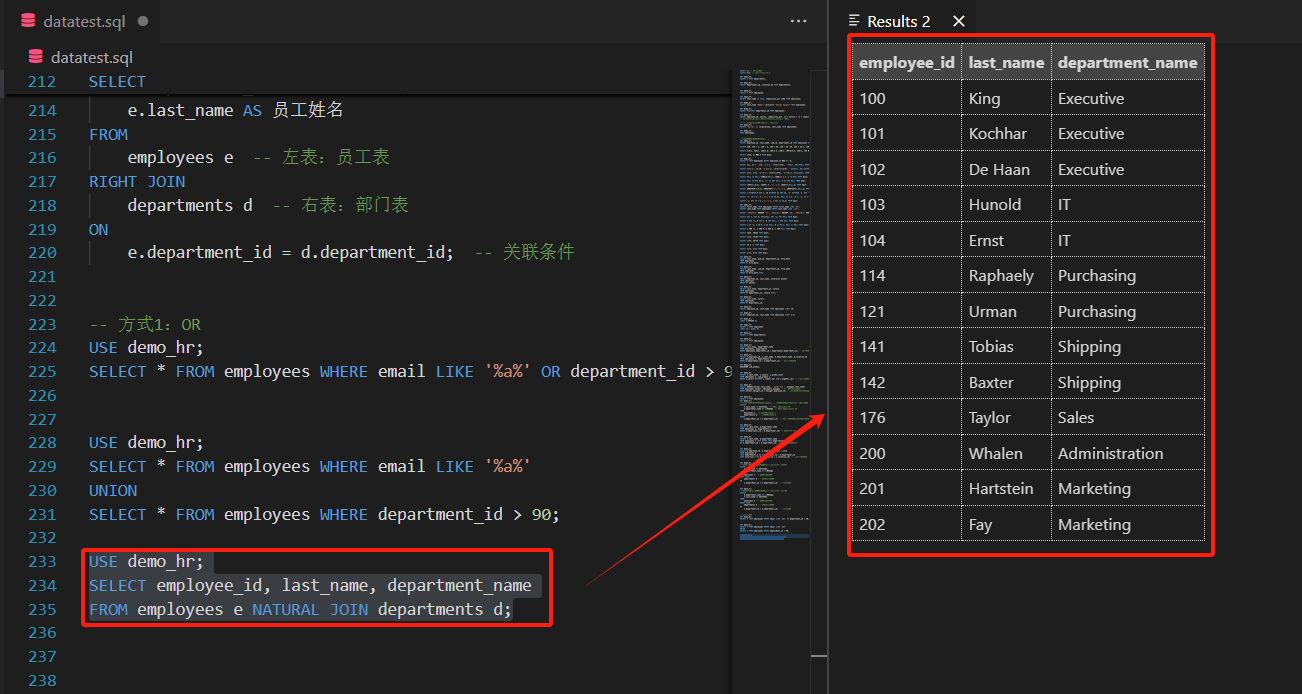
6.2 USING连接
指定单个同名字段进行等值连接,需在USING()中明确字段名。
示例:通过department_id连接(等价于ON e.department_id = d.department_id)
SELECT employee_id, last_name, department_name
FROM employees e JOIN departments d
USING (department_id);
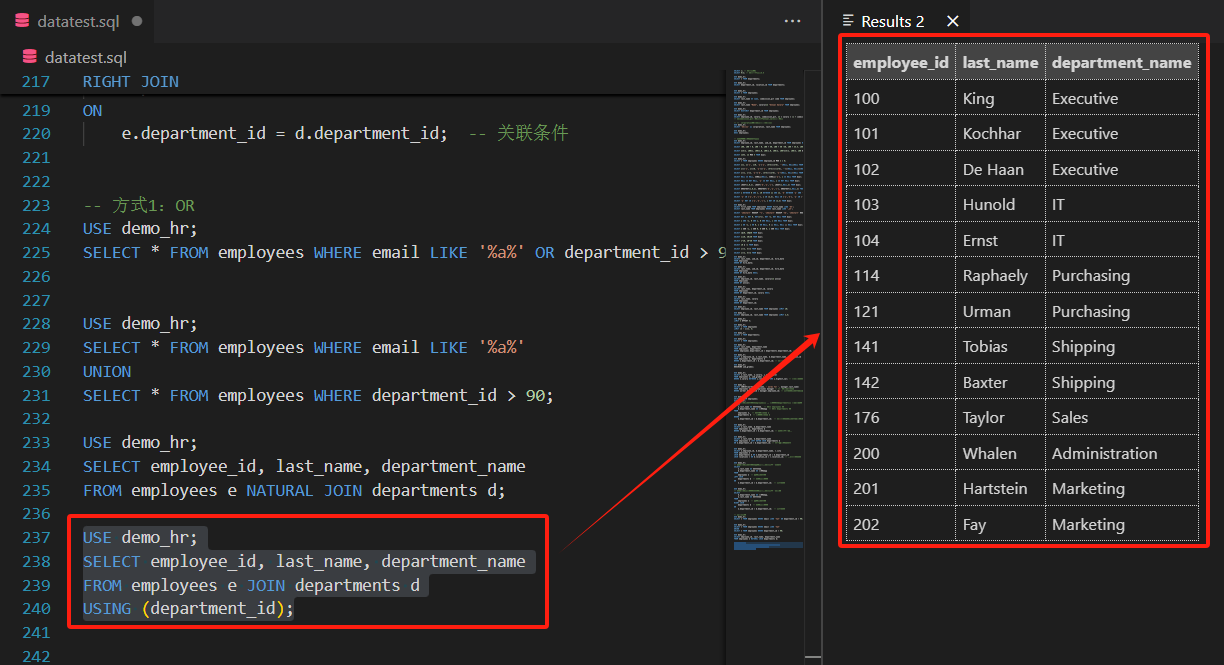
7 小结
多表查询是处理关联数据的核心技术,读完本文需要掌握:
- 基础逻辑:通过关联字段连接表,避免笛卡尔积(需添加有效连接条件);
- 连接类型:等值/非等值连、自连接、内/外连接;
- 语法规范:SQL99的
JOIN...ON更清晰,支持内连接、外连接及新特性(自然连接、USING); - 实用技巧:合理使用表别名、控制连接数量(避免不必要连接)、利用
UNION合并结果。
掌握这些基本上就具备了解决复杂数据关联查询的能力。