langchain4j之RAG 检索增强生成
RAG 检索增强生成
- 如何让大模型回答专业领域的知识
LLM 的知识仅限于它所训练的数据。如果你想让 LLM 了解特定领域的知识或专有数据,就需要用到 RAG
- 1.1微调大模型
在现有大模型的基础上,使用小规模的特定任务数据进行再次训练,调整模型参数,让模型更精确地处理特定领域或任务的数据。更新需重新训练,计算资源和时间成本高。
优点:一次会话只需一次模型调用,速度快,在特定任务上性能更高,准确性也更高。
缺点:知识更新不及时,模型训成本高、训练周期长。
应用场景:适合知识库稳定、对生成内容准确性和风格要求高的场景,如对上下文理解和语言生成质量要求高的文学创作、专业文档生成等。
- 1.2、RAG
Retrieval-Augmented Generation 检索增强生成
将原始问题以及提示词信息发送给大语言模型之前,先通过外部知识库检索相关信息,然后将检索结果和原始问题一起发送给大模型,大模型依据外部知识库再结合自身的训练数据,组织自然语言回答问题。通过这种方式,大语言模型可以获取到特定领域的相关信息,并能够利用这些信息进行回复。
优点:数据存储在外部知识库,可以实时更新,不依赖对模型自身的训练,成本更低。
缺点:需要两次查询:先查询知识库,然后再查询大模型,性能不如微调大模型
应用场景:适用于知识库规模大且频繁更新的场景,如企业客服、实时新闻查询、法律和医疗领域的最新知识问答等。
- 1.3、RAG常用方法
全文(关键词)搜索。 这种方法通过将问题和提示词中的关键词与知识库文档数据库进行匹配来搜 索文档。根据这些关键词在每个文档中的出现频率和相关性对搜索结果进行排序。
向量搜索 ,也被称为 “语义搜索”。文本通过 嵌入模型 被转换为 数字向量 。然后,它根据查询向量 与文档向量之间的余弦相似度或其他相似性 / 距离度量来查找和排序文档,从而捕捉更深层次的语 义含义。
混合搜索。 结合多种搜索方法(例如,全文搜索 + 向量搜索)通常可以提高搜索的效果。
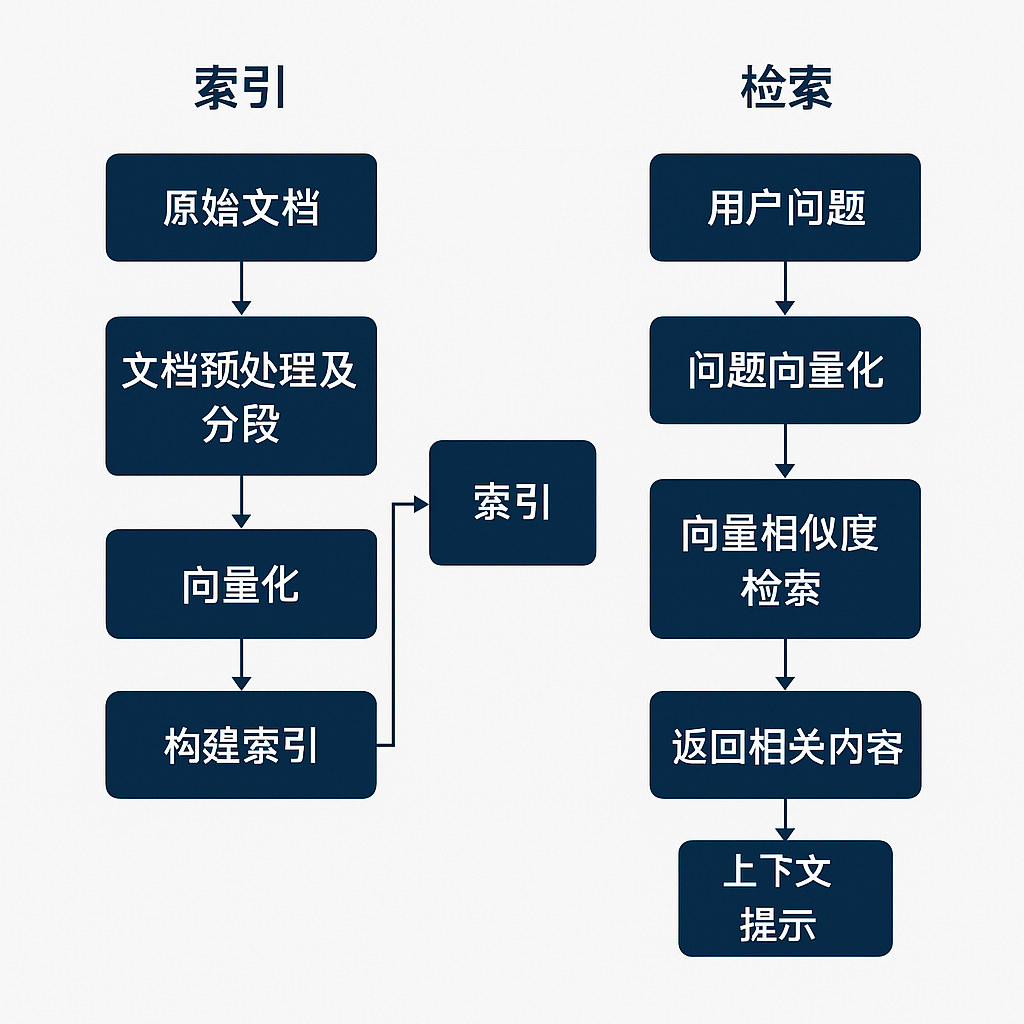
2. RAG的过程
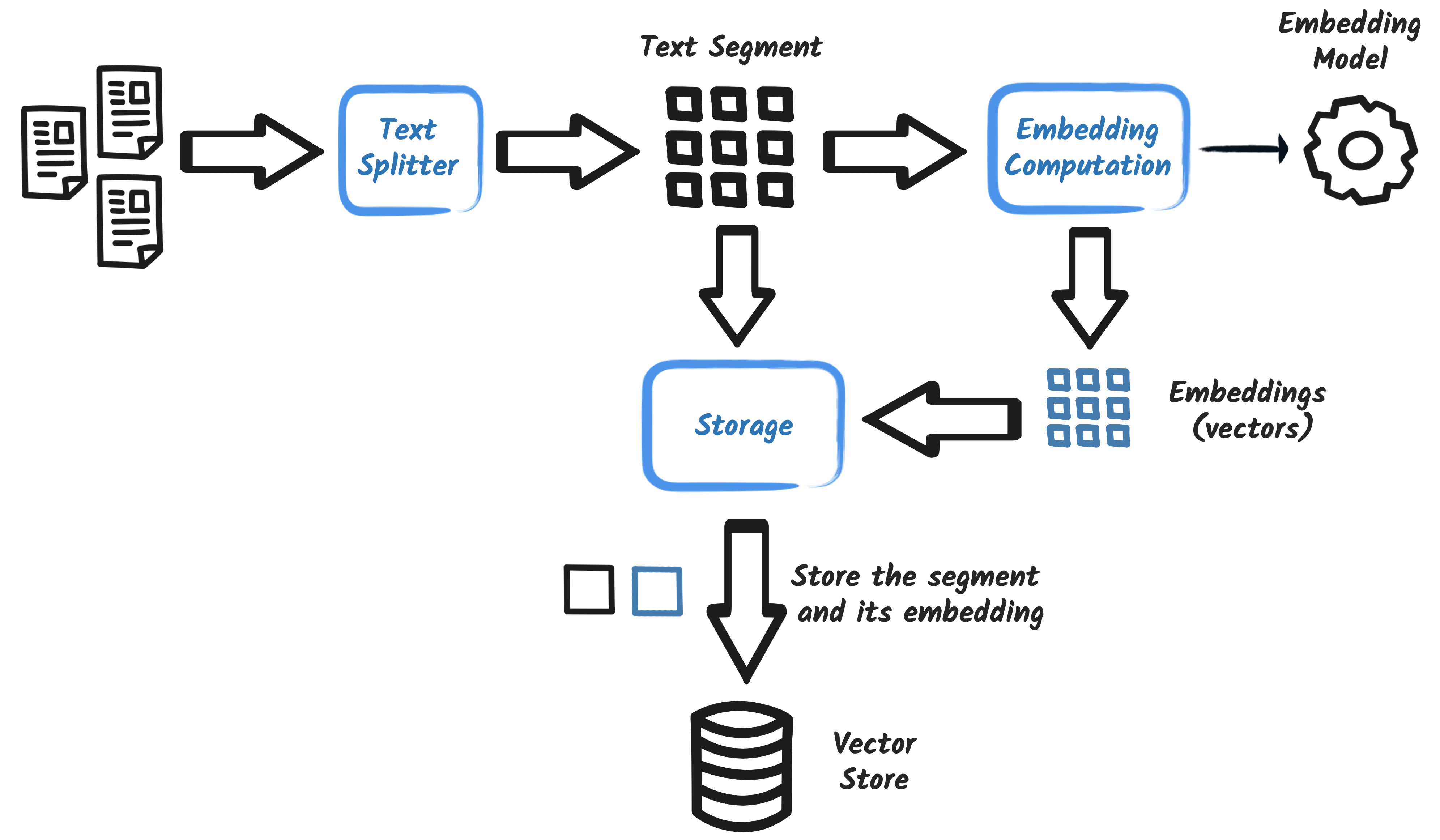
文档加载器(Document Loader)
用于从各种源读取原始文档,将其转为 Document 对象,以便后续处理。常见按来源分类如下:
🗂️ 本地文件与类路径
FileSystemDocumentLoader:从文件系统的指定路径(支持单个文件/目录递归)加载文档LangChain+5CSDN博客+5CSDN博客+5ClassPathDocumentLoader:从项目资源(classpath)加载文档,适合开发/测试环境CSDN博客+1CSDN博客+1
🌐 网络与动态网页
UrlDocumentLoader:从 URL 加载在线网页或文件内容CSDN博客+1CSDN博客+1SeleniumDocumentLoader:通过 Selenium 浏览器自动化加载动态渲染页面GitHub+5CSDN博客+5CSDN博客+5
☁️ 云存储
AmazonS3DocumentLoader:读取 AWS S3 桶中文档CSDN博客+1CSDN博客+1AzureBlobStorageDocumentLoader:从 Azure Blob 存储加载CSDN博客+1CSDN博客+1GoogleCloudStorageDocumentLoader:从 GCS 桶加载文件CSDN博客TencentCosDocumentLoader:支持腾讯云 COS 的文件加载掘金+5CSDN博客+5CSDN博客+5GitHubDocumentLoader:从 GitHub 仓库加载文件/目录CSDN博客+1CSDN博客+1
🧩 文档解析器(Document Parser)
加载出来的是原始文本或二进制,此时需解析器将其转换为结构化 Document 对象:
TextDocumentParser:适合 TXT、HTML、Markdown 等纯文本内容CSDN博客+1CSDN博客+1ApachePdfBoxDocumentParser:基于 PDFBox 解析 PDF 文档CSDN博客+1CSDN博客+1ApachePoiDocumentParser:处理 Office 文档(DOCX、PPTX、XLSX 等)CSDN博客+1CSDN博客+1ApacheTikaDocumentParser:万能解析器,能自动识别多种格式LangChain+4CSDN博客+4CSDN博客+4
🧩 文档分割器(Document Splitter)
LangChain4j 提供了 DocumentSplitter 接口及多种实现,用于将大文档切割为符合上下文处理和向量化需求的小块(chunk)。主要类型包括:
📄 常见分割器
| 分割器 | 切分方式 | 特点/应用场景 |
| DocumentByParagraphSplitter | 按段落(双换行) | 保存语义完整性,设置最大 tokens 限制(如 1024)后自动合并段落LangChain+15GitHub+15CodeSignal+15 |
| DocumentByLineSplitter | 按行(单换行) | 适合日志、配置文件,每行作为独立 chunk |
| DocumentBySentenceSplitter | 按句子 | 使用 Apache OpenNLP 识别句边界,超长句则交给子分割器(如按词切)处理 Javadoc |
| DocumentByWordSplitter | 按单词数量 | 固定词数为单位,适合无明显结构的纯文本 |
| DocumentByCharacterSplitter | 按字符数量 | 最原始的长度控制分割,适合对 tokens 不敏感场景 |
| DocumentByRegexSplitter | 使用正则表达式 | 自定义分隔规则,如 XML/HTML 标签或特定内容采集 |