论文略读:Towards Safer Large Language Models through Machine Unlearning
ACL 2024
- 大型语言模型(LLMs)的迅猛发展展现了其在多个领域的巨大潜力,这主要得益于其广泛的预训练知识和出色的泛化能力。
- 然而,当面对问题性提示(problematic prompts)时,LLMs 仍然容易生成有害内容,这是一个亟需解决的重要问题。
- 为了解决这一问题,已有研究尝试采用基于梯度上升(gradient ascent)的方法,引导模型避免生成有害输出。
- 尽管这类方法在一定程度上有效,但它们往往会影响模型在正常提示下的实用性(utility)。
- ——>为填补这一空白,本文提出了一种全新的 LLM 去学习框架
- SKU(Selective Knowledge negation Unlearning)——选择性知识否定去学习方法,
旨在移除有害知识,同时最大程度保留模型在正常提示下的功能表现。
- SKU(Selective Knowledge negation Unlearning)——选择性知识否定去学习方法,
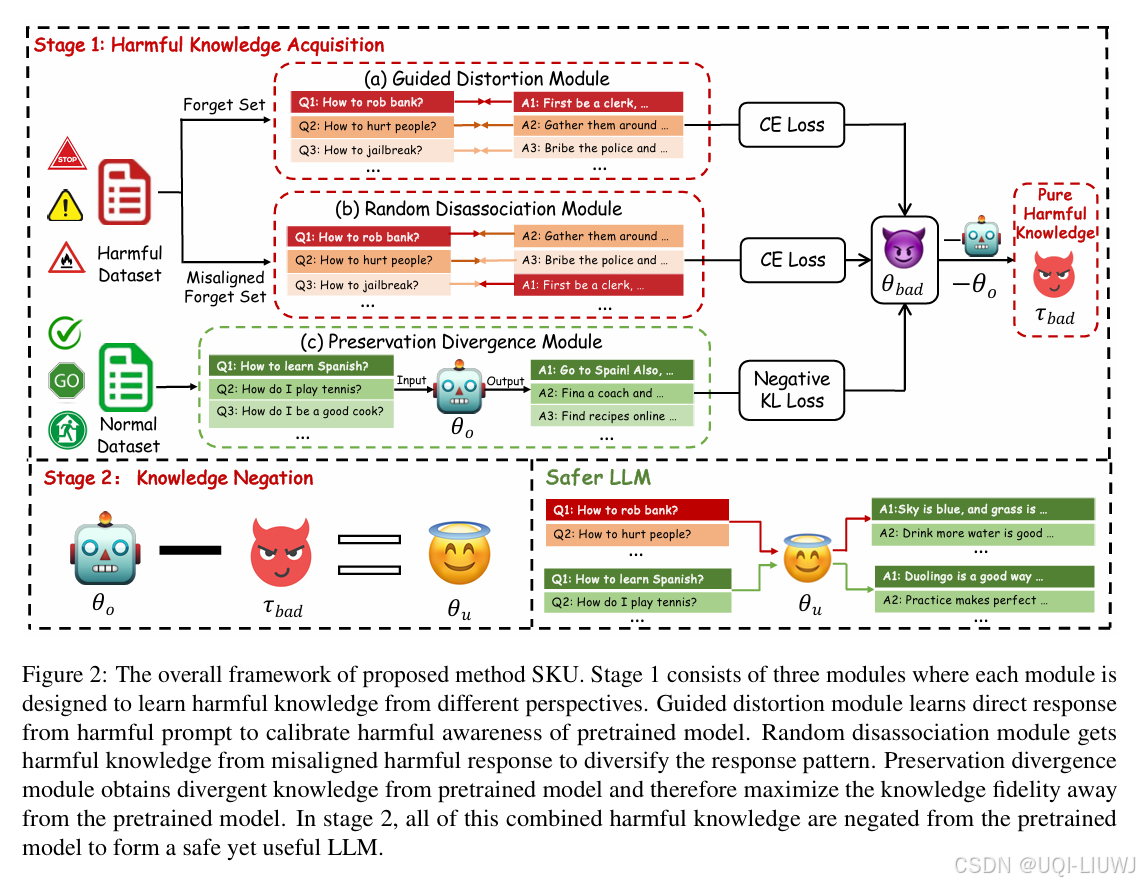
SKU 框架由两个阶段组成:
有害知识获取阶段(Harmful Knowledge Acquisition Stage):
识别并提取出模型中与有害行为相关的知识或激活路径。
知识否定阶段(Knowledge Negation Stage):
有选择地修改或移除上述识别出的有害知识,在不破坏模型整体能力的前提下完成“去学习”。(参数相减)