nerf-2020
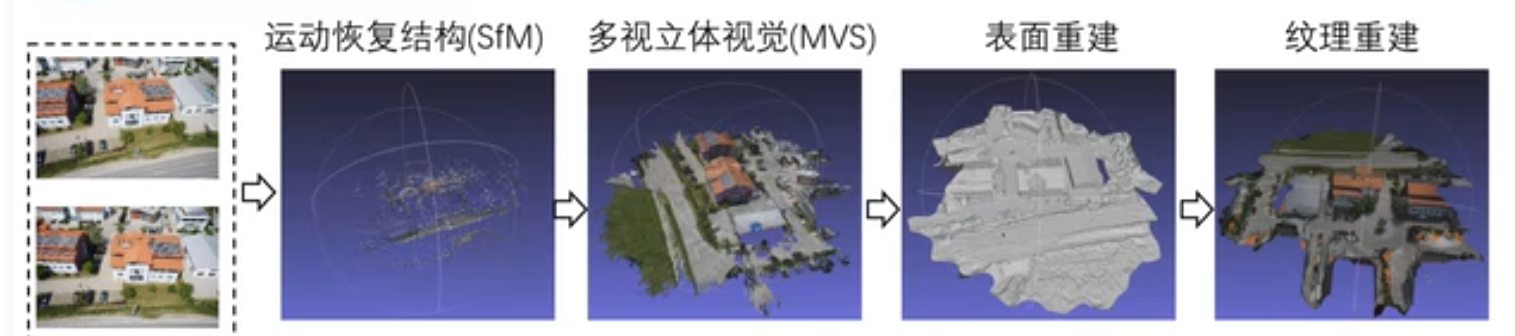
三维重建方法
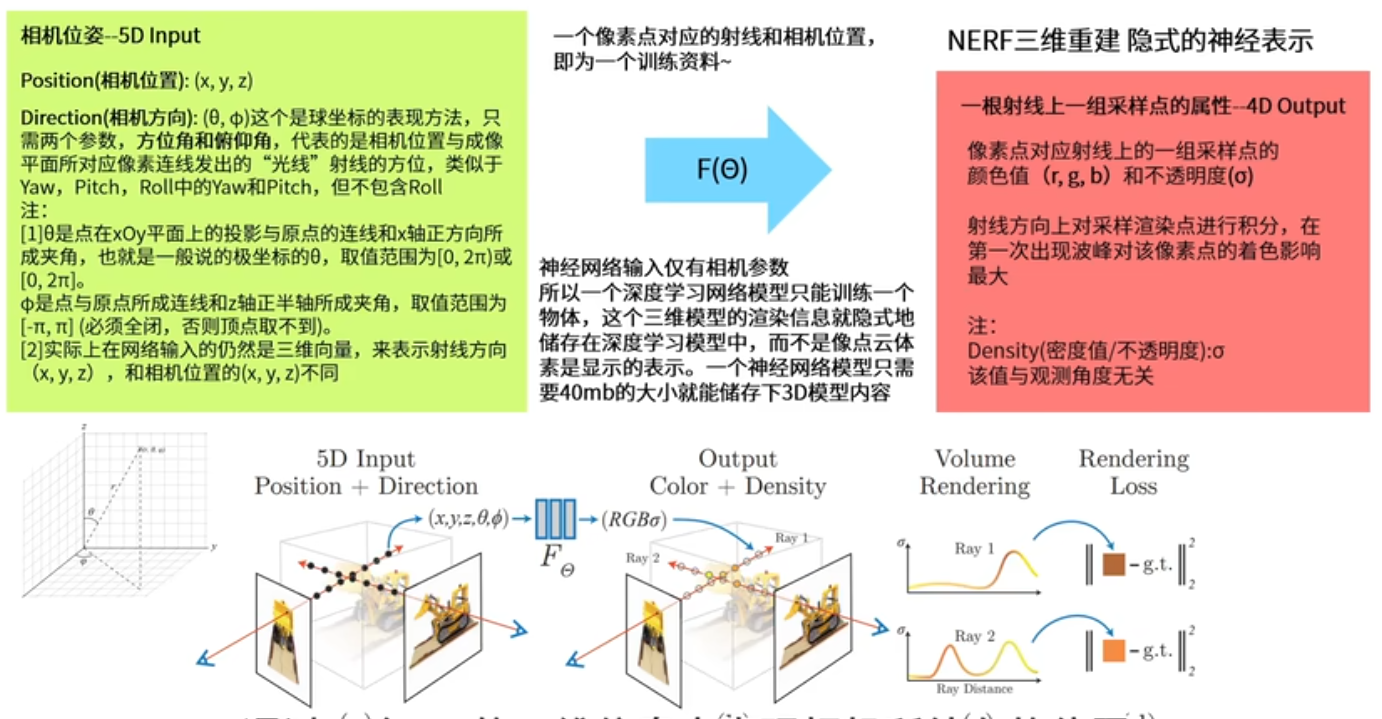
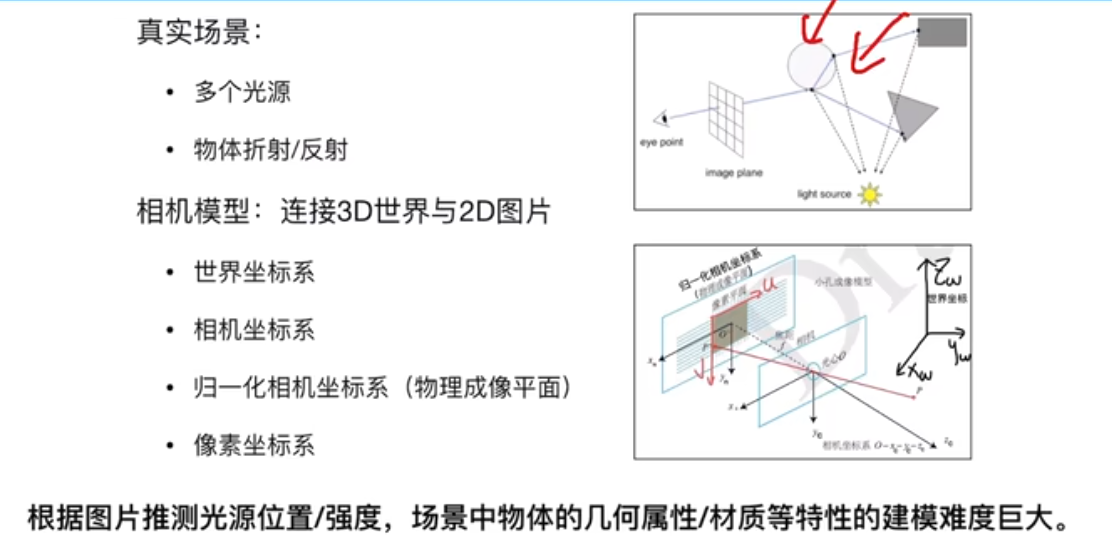
摄像机外参数(位姿,世界坐标系到相机坐标系 )
SFM

MVS
 稠密三维点云进行物理仿真、可视化不方便。
稠密三维点云进行物理仿真、可视化不方便。
表面重建(三角面片)

碰撞检测
纹理重建:

F^2NERF NERFStudio 3DGS
SAM算法抠图
meshlab
nerf原理1
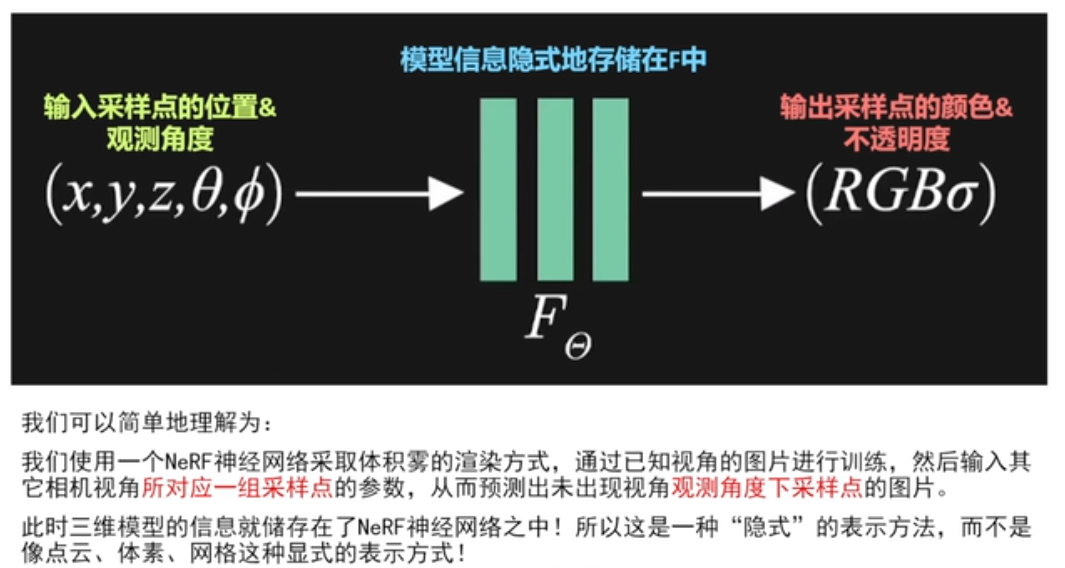
nerf神经隐式三维重建
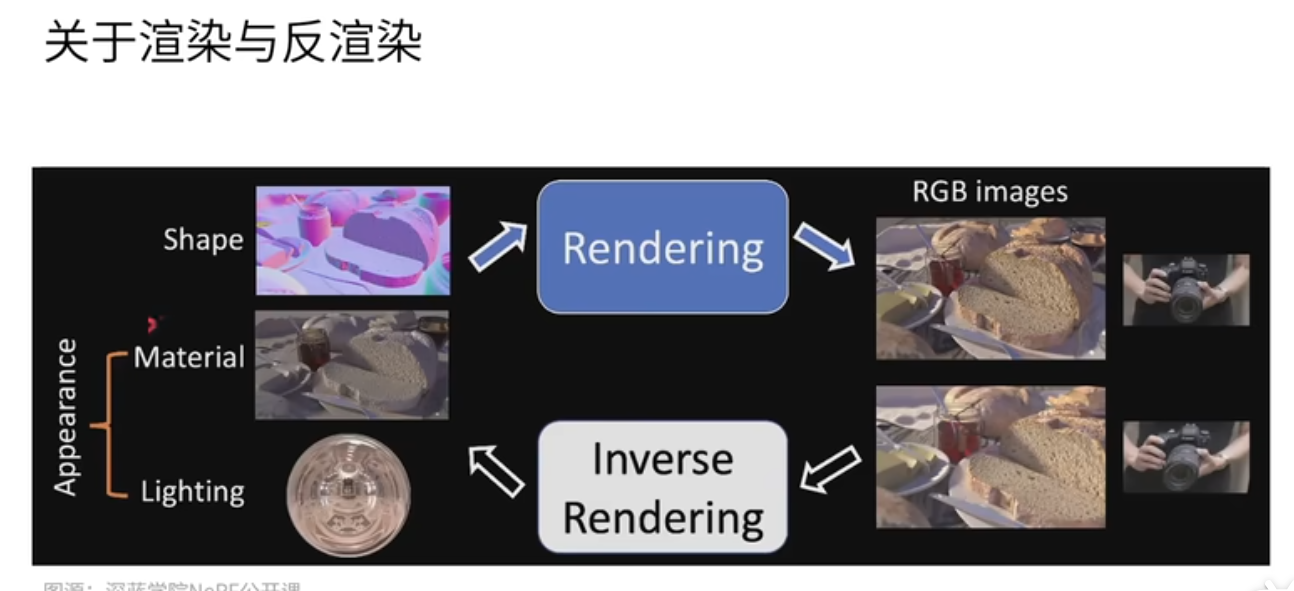
计算机图形学渲染基于三维模型、材质、光照的信息,通过一个特定的视角将物体渲染为一个画面。
反渲染(三维重建) 网格、体素、点云方式表示,还原一个三维模型。
以前三维模型重建是通过图片重建出一个点云、网格、体素的模型。
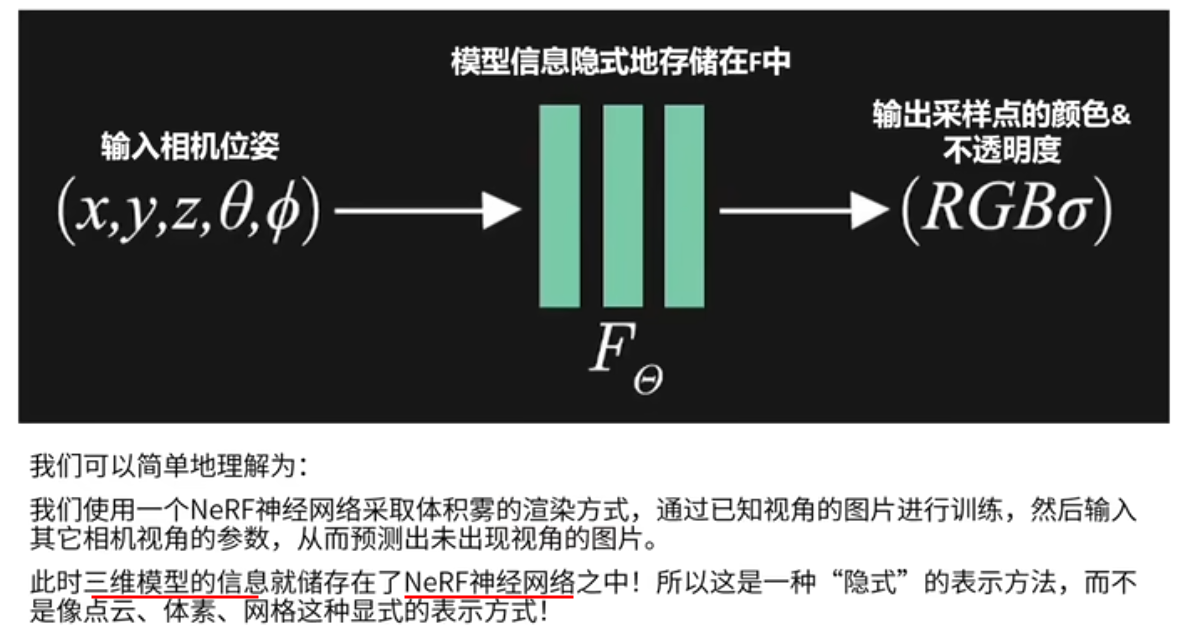
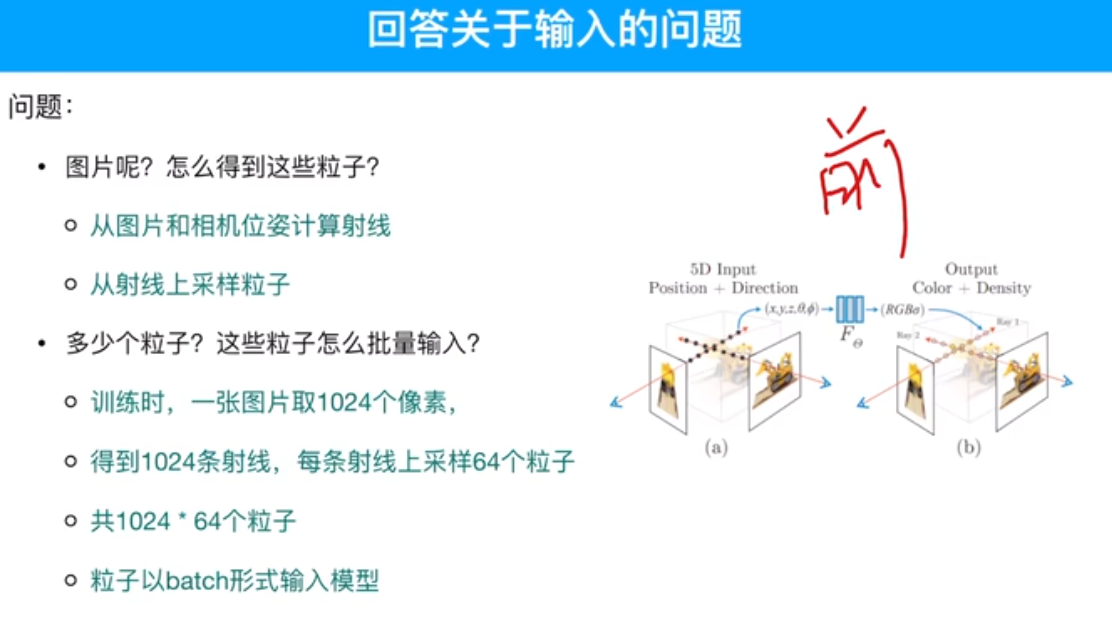
输入相机的位姿(位置+视图方向),输出是图像的RGB+不透明度alpha。
通过已知视角的图像进行训练。
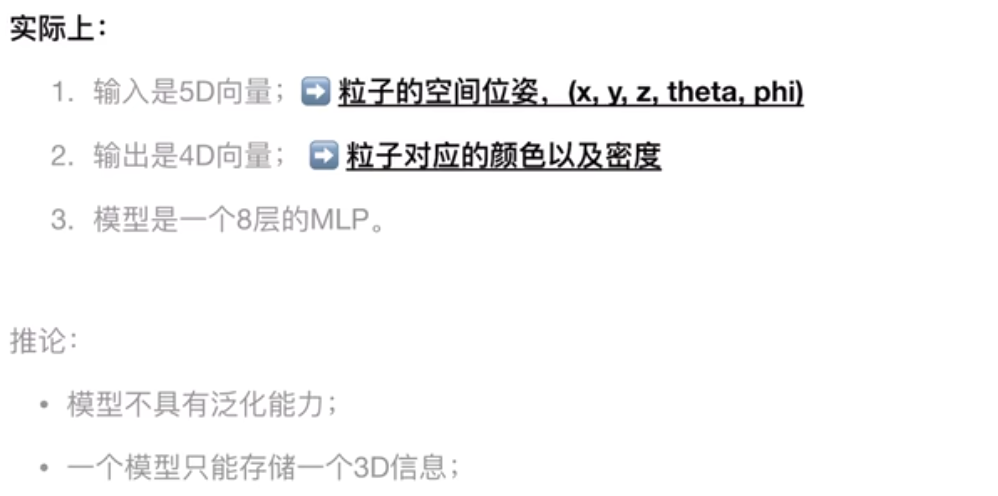
问题:一个NeRF神经网络模型只能存储一个三维物体或者三维场景的信息,只能用在一个物体上。每次要用nerf,都要对一个物体训练一个对应的nerf神经网络模型。
希望网络模型能用在多个场景
40M 一个模型
位置编码 高频信息

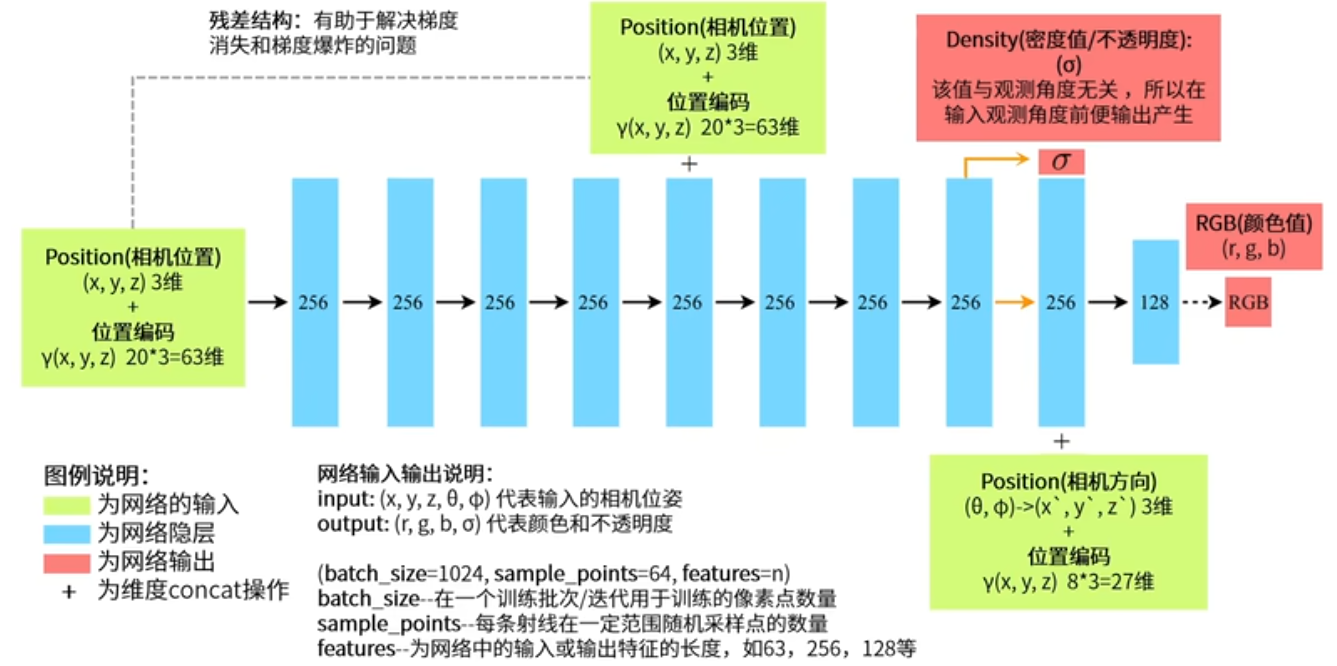

采样点
由相机的位姿可以得到采样点的位置和观测角度,实际输入的是这个。
推断出采样点颜色和不透明度。
基于相机位姿得到的采样点,其实是基于相机特定的角度而生成的一组点。
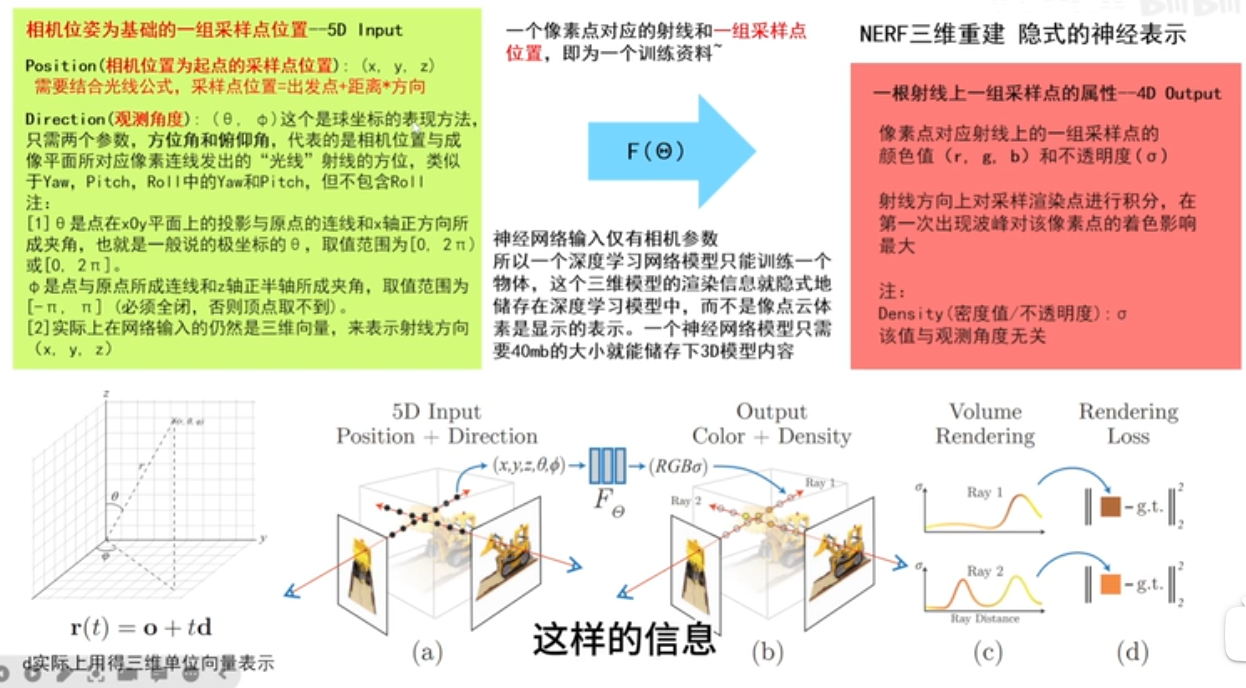
出发点:相机所在的位置
方向:相机所对应的朝向
距离:采样点沿着相机所发出的射线上所采样的点到原点的距离

位置编码作用:高频信息提取出来,只靠三个维度XYZ值,包含信息少,很难将高频信息凸显出来,三个维度的数值之间很难拉开差距,所以没有位置编码时整个生成得图片会特别光滑。
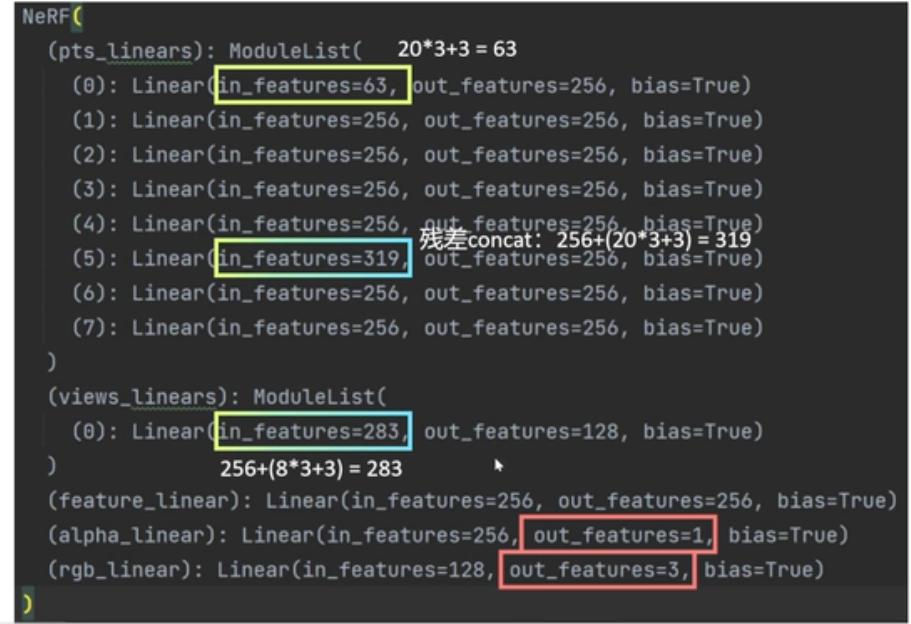
代码中 10组cos和sin组合形成20维位置编码。在xyz轴分别加入20维的内容,相当于对xyz轴分别做了特征增强。
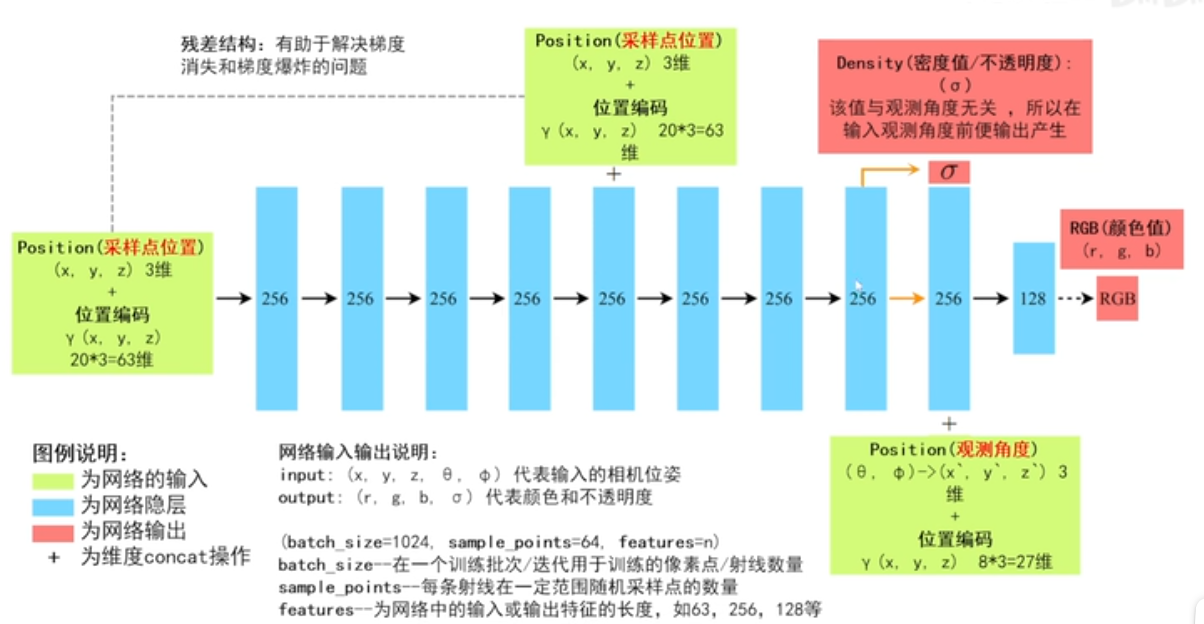
为何先将密度值输出出来 ?密度值和观测角度无关,在不同角度看物体时,不透明度不受观测角度的影响,只与采样点的位置有关,与采样点所对应的观测角度无关。
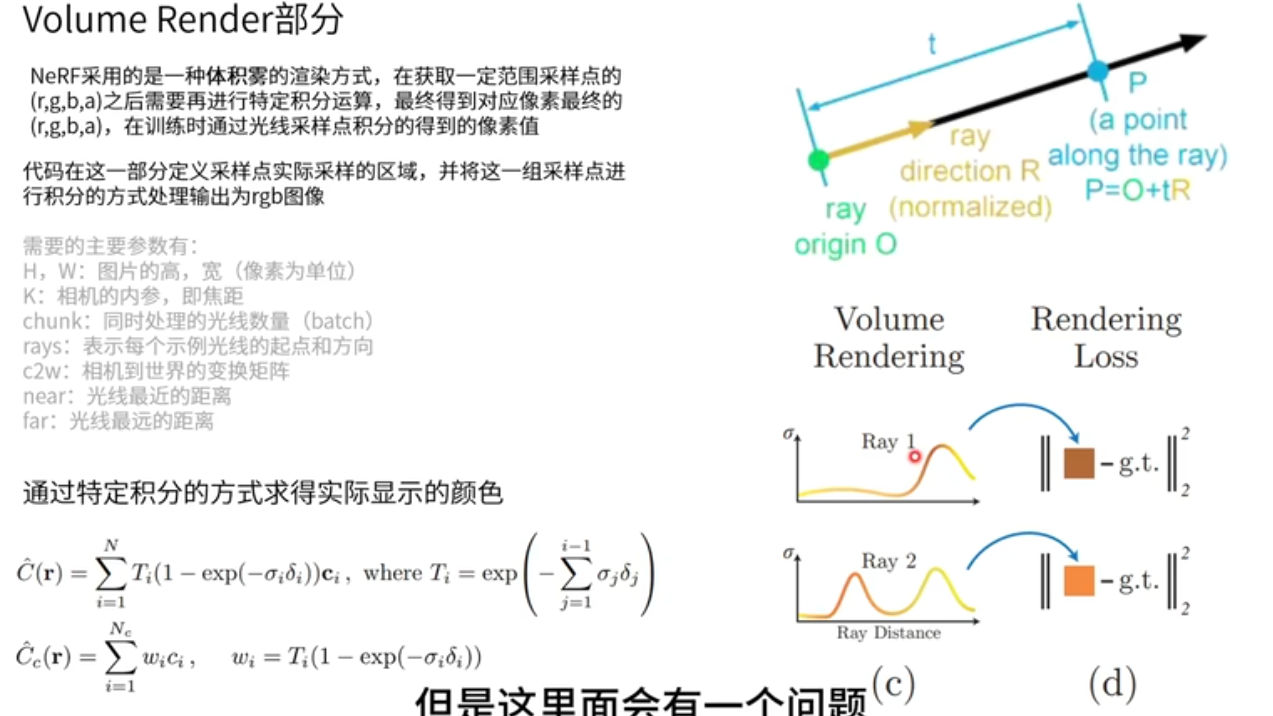
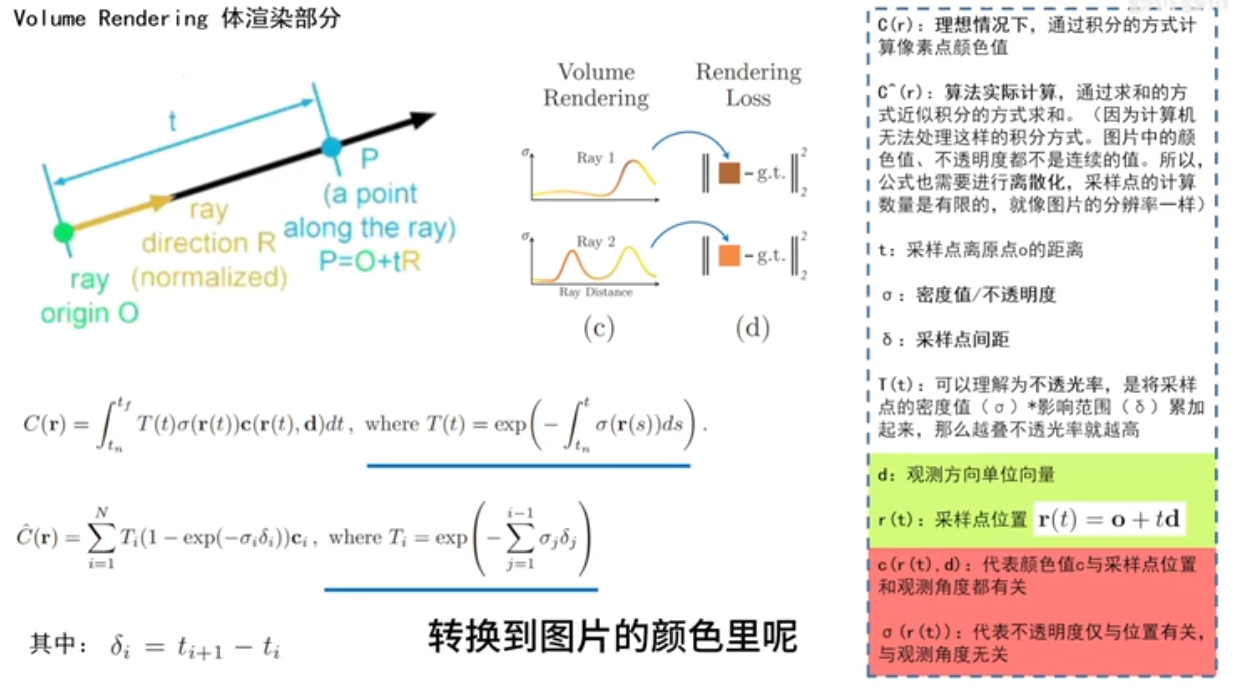
体渲染
如何将采样点的颜色值和不透明度转换到图片的颜色呢?
首先,采样点是如何获得的?基于相机的位姿,r(t) = o + td,得到采样点对应的位置r(t),o起点 相机所在的位置,td采样点到原点的距离,d单位方向向量,也就是观测角度。所以就能得到采样点位置了。采样点位置,输入网络,推理出采样点RGB颜色值和不透明度。
c(r) 理想情况下积分方式计算像素颜色值,如何计算?T不透光率,采样点密度和影响范围累加起来,遇到物体它的不透光率逐渐变高。将不透明的物体叠起来,越叠越深。不透明度值,r只和位置信息有关。
采样间距
近似积分(求和)方式完成体渲染,将一个像素点所对应的颜色通过这一组采样点的内容产生出来。
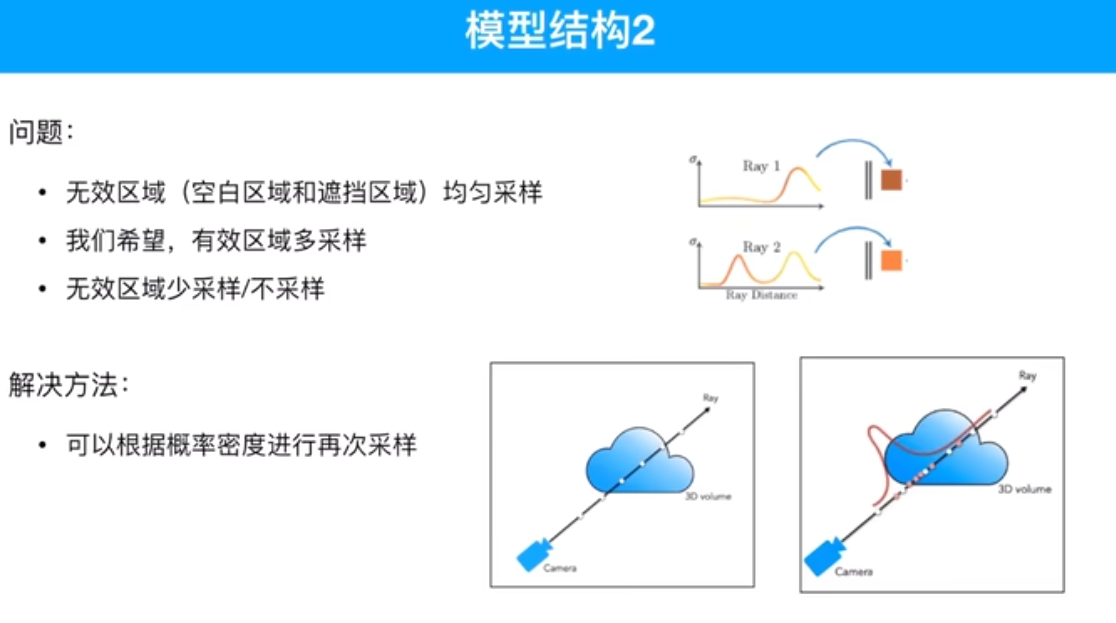
有采样点之后,也知道如何获得对应的图片,采样点的合理性?
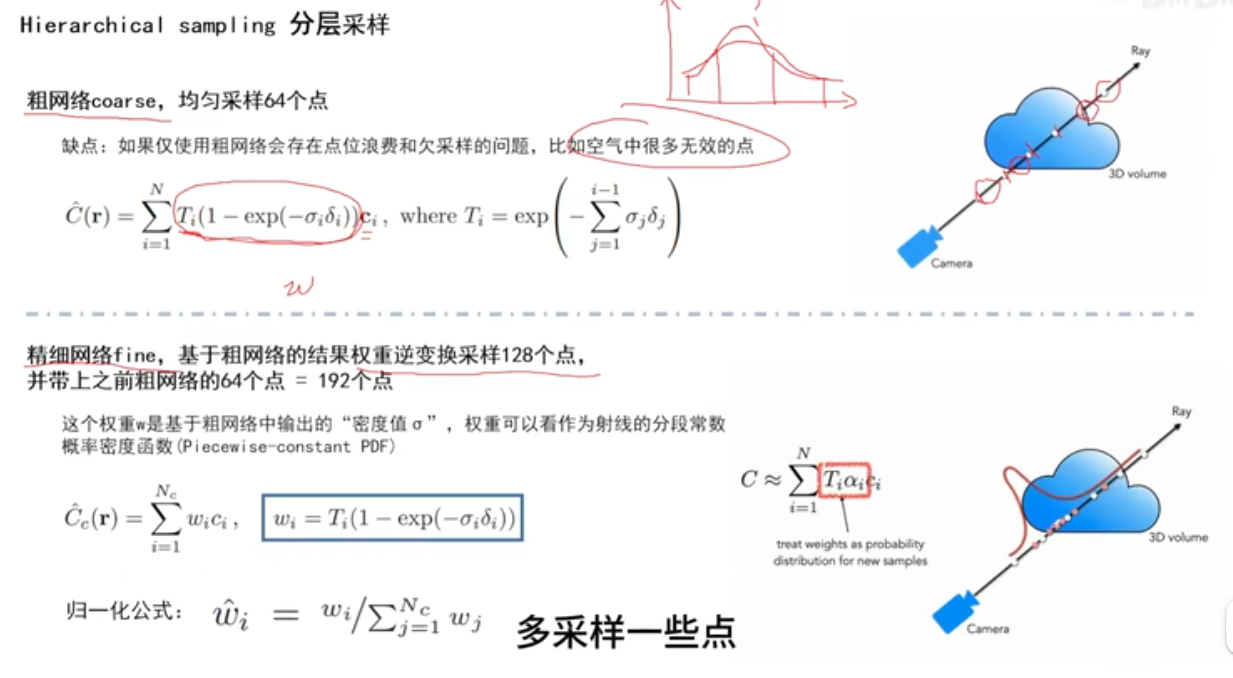
密度高多采样,密度低少采样。
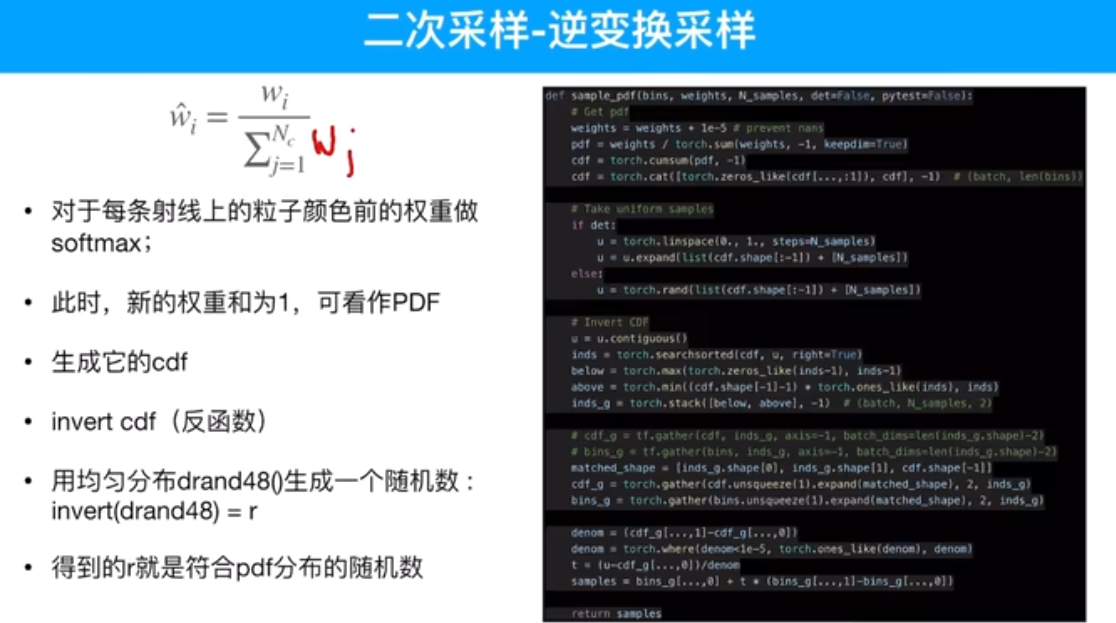
粗网络得到概率密度的函数值,精细网络重新做一个逆变化的采样。

像素点对应的颜色值和不透明度值一一比对。
数据准备
代码基于官方代码修改 源代码地址:https://github.com/Fyusion/LLFF/tree/master/llff/poses 本教程代码地址:https://github.com/superrice2020/ZoomLab_NeRF
colmap生成npy文件
重建自己的三维场景,先准备图片,用手持的手机摄像头,围绕着物体拍一圈,拍了141张,其实几十张就够,多了会出问题。
准备一个工具colmap version 3.8

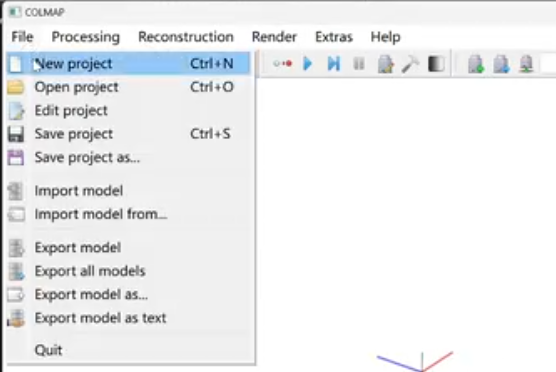
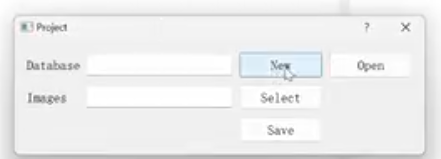
images同级目录下新建一个database.db文件
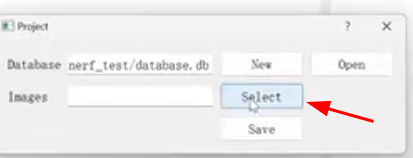
最后点击save
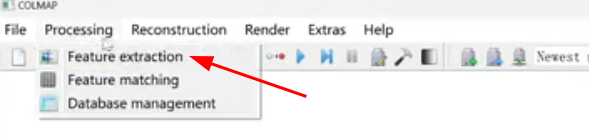
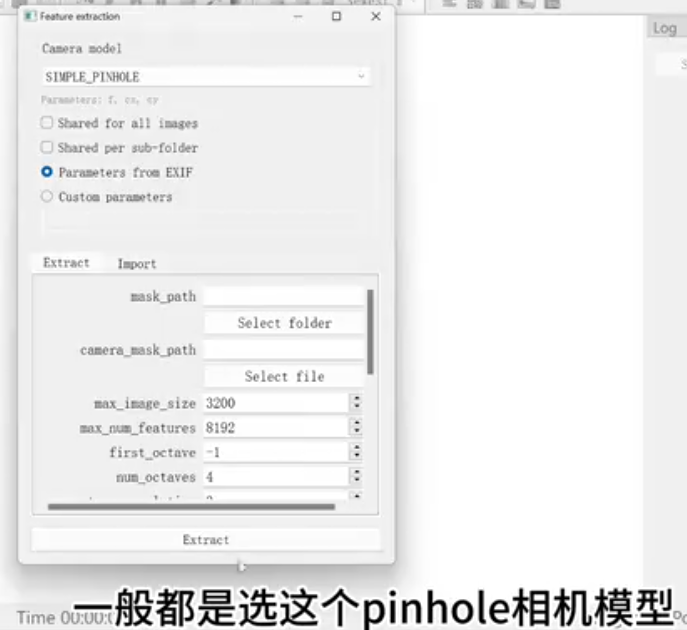
点击提取
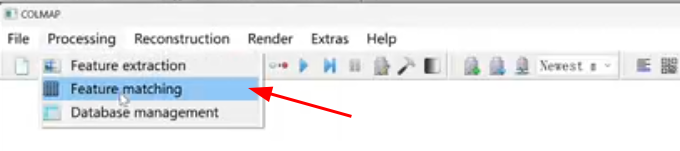
然后点击run
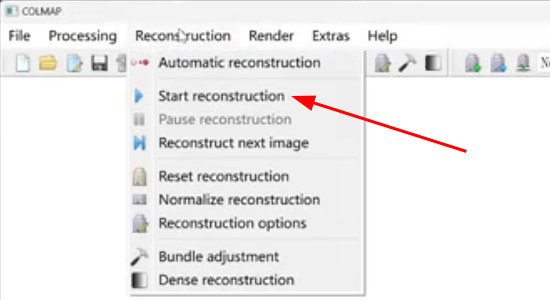
稀疏三维重建
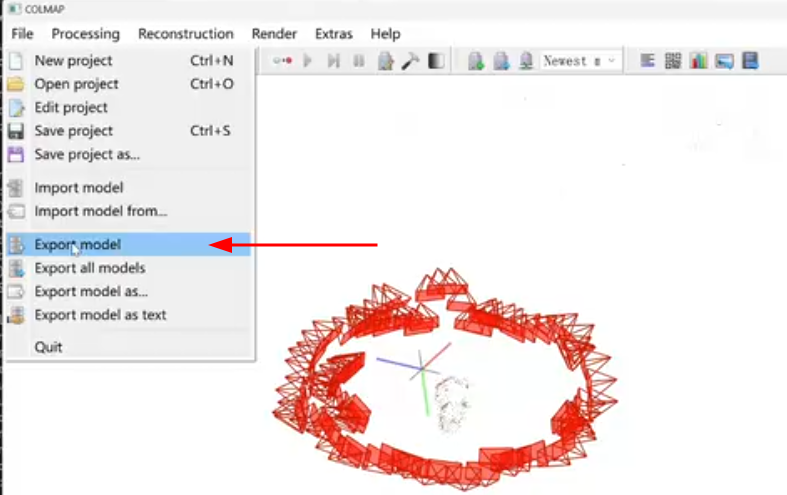
LLFF 代码
如果有没匹配上的图片,把这些图片删掉,重新跑一遍colmap
生成poses_bounds.npy文件,训练需要的。
也可以用单纯运行脚本代替colmap
生成新的相机视角位姿
读取.npy文件并进行处理
N*17,前12个参数 每个图片对应视角的旋转平移矩阵,后面3个图片宽高相机焦距,最后2个场景近点和远点。
对图片进行缩放同时也要对焦距缩放,符合成像的原理。
nerf要2次坐标系转换,colmap数据位于colmap坐标系下,先转换成LLFF数据集的坐标系,LLFF坐标系转换成nerf坐标系。
移轴操作
前向场景缩放(NDC),对360度环绕场景用处不大。为何要对前向场景缩放,它需要配合后续所使用的NDC方法,ndc要求整个场景必须位于一个平面。nerf设定这个平面z=-1, 确保整个场景在z=-1这个平面的后面。直接除以一个最小距离,让最小的距离变为1。再乘以bd_factor,确保最近点离相机的距离大于1.
recenter操作,对所有相机的位姿做一个平均,平均相机位置移到世界坐标系原点。平均相机坐标系和世界坐标系重合。相当于对整个场景做一个旋转平移变换。
一种情况是对360度环绕场景的数据处理,一种是对前向场景数据处理。
360度环绕场景的数据处理:一个步骤对场景缩放,第二个步骤生成新的相机视角用于测试。
缩放:先确定场景中心,通过所有的相机位姿发出一条射线,找到一个点,这个点离所有射线的距离最近。这个点为新的世界坐标系原点,来构建新的世界坐标系。
先得到z轴,所有相机位置和原点的连线的向量取一个平均,这样z轴坐标和原世界坐标的z轴坐标一致。随便找一个向量,进行叉乘得到新世界坐标系的x轴,得到x轴坐标系后,x轴跟z轴叉乘,得到y轴。得到了场景视角中心为原点的新的世界坐标系。相机位姿都处于新的世界坐标系下。
场景缩放,缩放半径,所有相机距离原点的平均距离,把所有相机进行缩放,相当于缩放到了单位圆的附近,这样对原相机视角处理完成了。
生成新的相机视角,先得到新的相机视角的轨迹,生成一个圆,在这个圆上生成新的相机视角。圆的半径,对所有相机位姿取平均,平均完成之后,
网络输入的是采样点
代码讲解
Embed cos sin 位置编码
网络输入的是采样点,每一条光线上的采样点。得到这个点的RGBA,然后通过体渲染的方式得到这条光线上的RGB,一条光线对应一个像素点,这个像素点在图像上有真实的RGB,计算出来的rgb和像素点上的rgb计算loss
如何根据图像和相机位姿得到光线?采样点要在光线上采样,像素点转换相机坐标系再转换到世界坐标系
rays_o 相机原点转换到世界坐标系,光线起点
rays_d 像素点转换到世界坐标系,光线方向
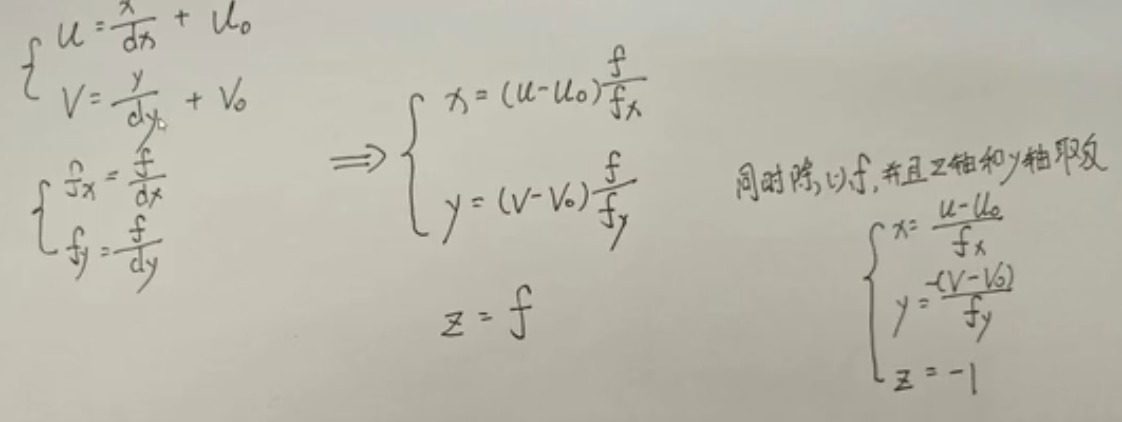
得到所有图像的光线,shuffle,然后训练
rander渲染 NDC计算
光线采样,采样点上加上扰动,
每个采样点都得到了rgba,怎么知道这条光线在这个像素点上的rgba?体渲染。
粗网络和精细网络是一样的。采样的方式不一样。
第一轮均匀采样(粗采样)有物体的位置采样点的权重大,无物体(空气)采样点权重小,画一个概率分布图。第二轮精细网络采样过程中,在权重大的地方采样点多些。
PSNR
参考
十分钟带你快速入门NeRF原理_哔哩哔哩_bilibili
手把手NeRF代码讲解——数据准备_哔哩哔哩_bilibili
yahboom 差速底盘 机械臂 教育
nerf-2


图片转5D的前处理,4D转图片的后处理。


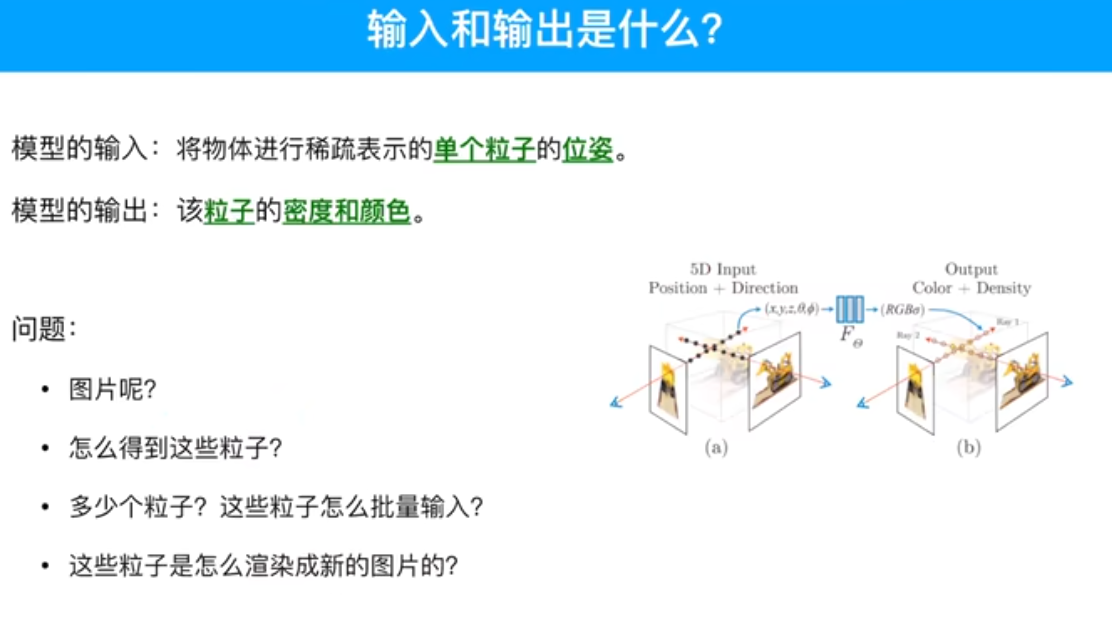
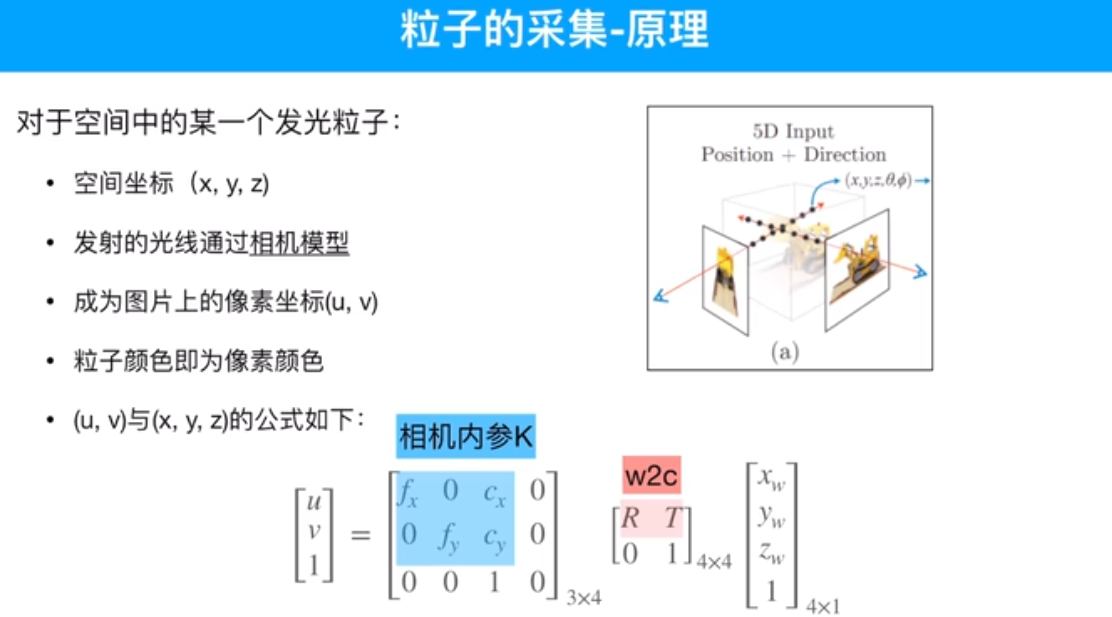
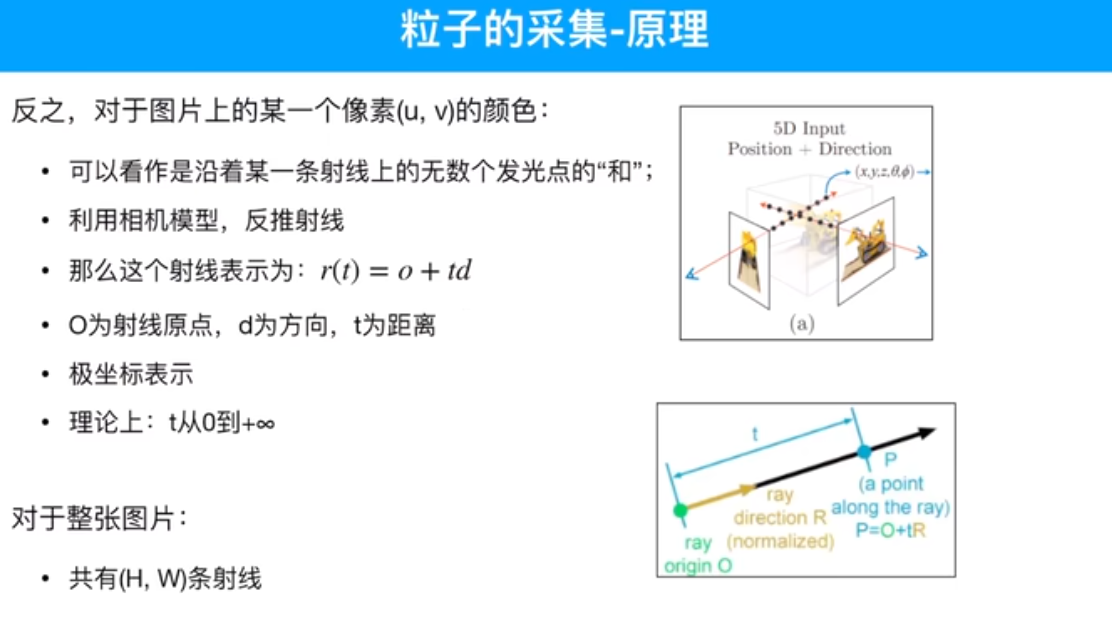
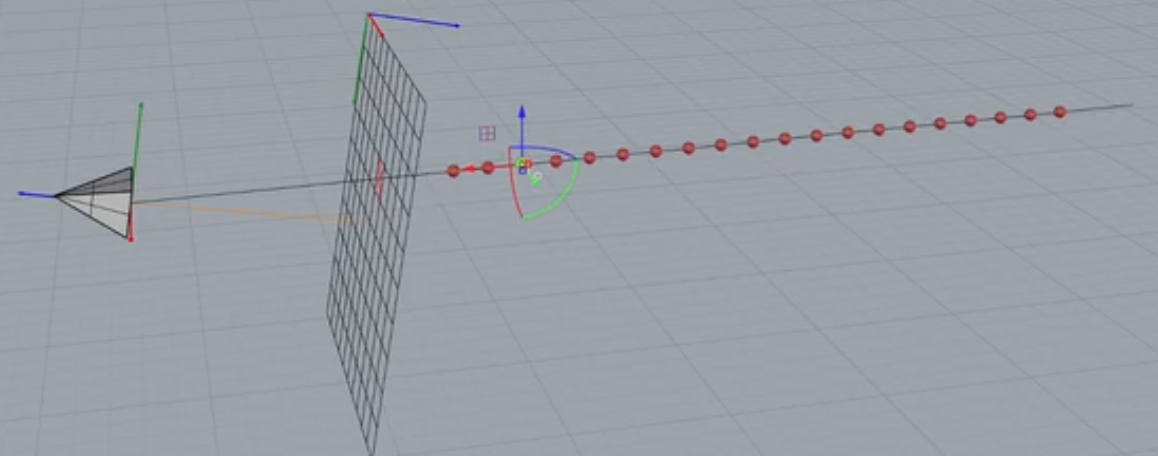
粒子和图片中像素值的关系。
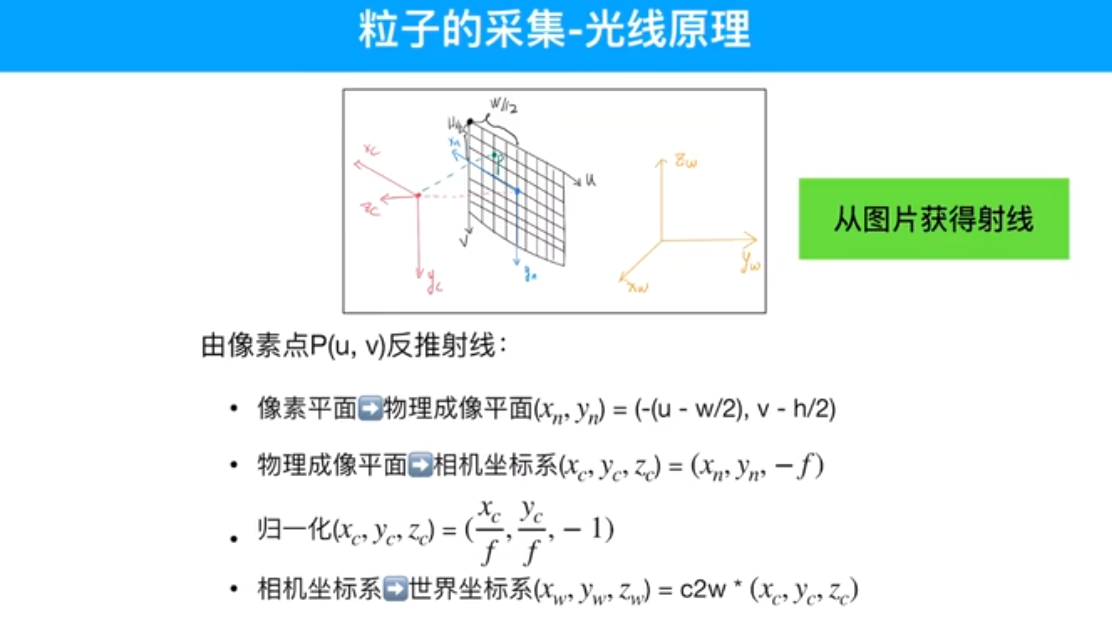


rays_d : (x-x0,y-y0,z-z0)
rays_o: x0, y0, z0
射线选取:在一个图片里随机选1024个像素,或者,在所有图片中选取1024个像素 进行训练。

每个采样点加了噪声或扰动,对特征的表达更鲁棒。

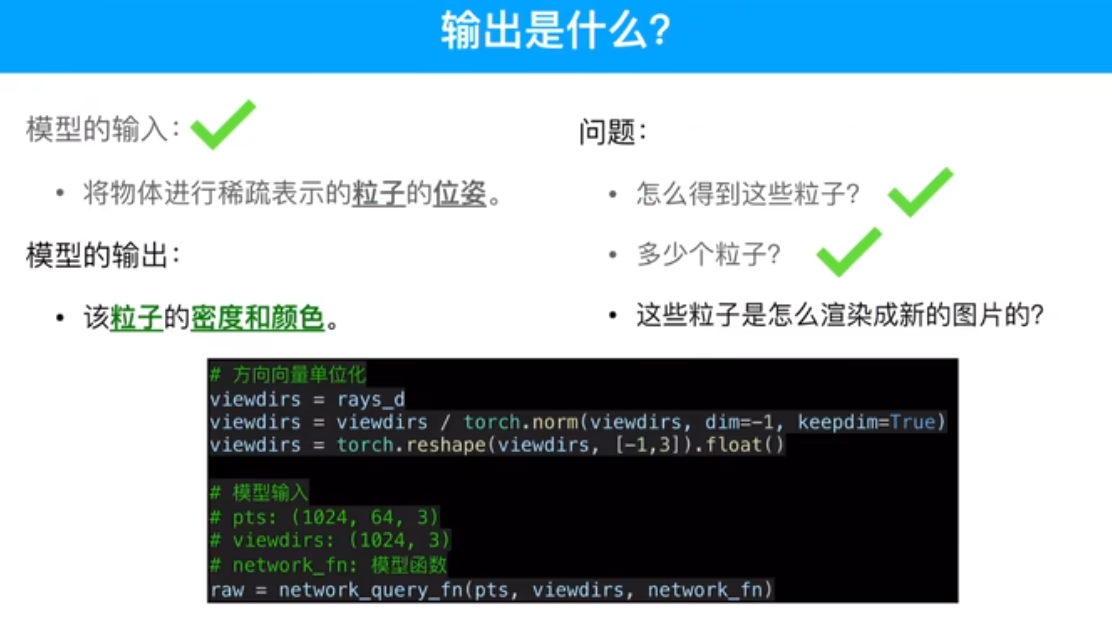
输入的是粒子,粒子是由图片得来的,通过相机原点和像素做射线,取射线上的采样点。
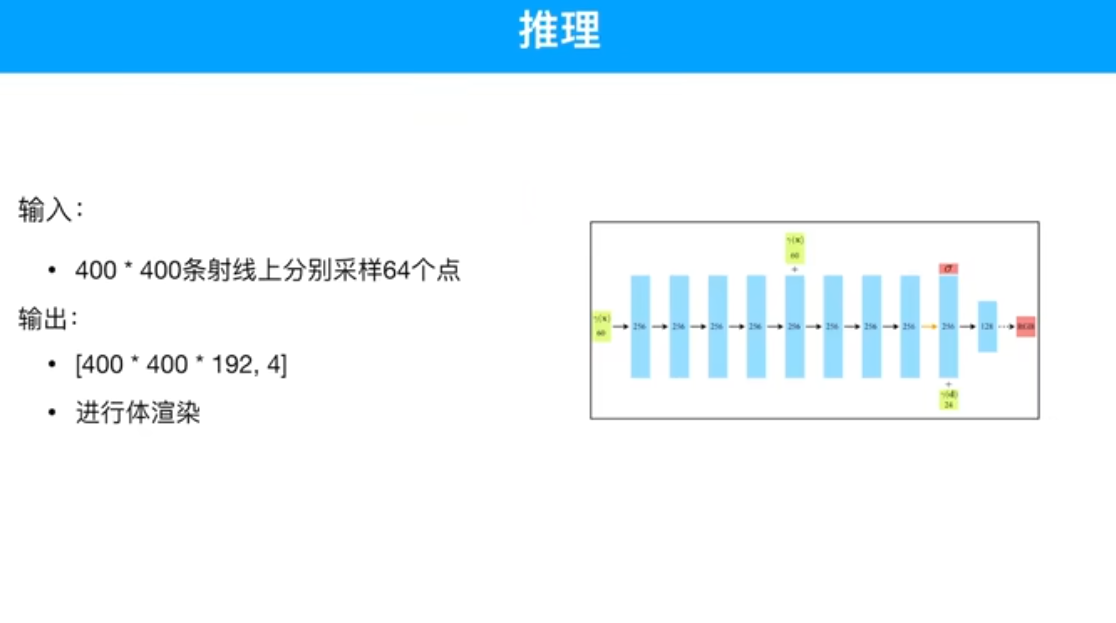
1024*64个点
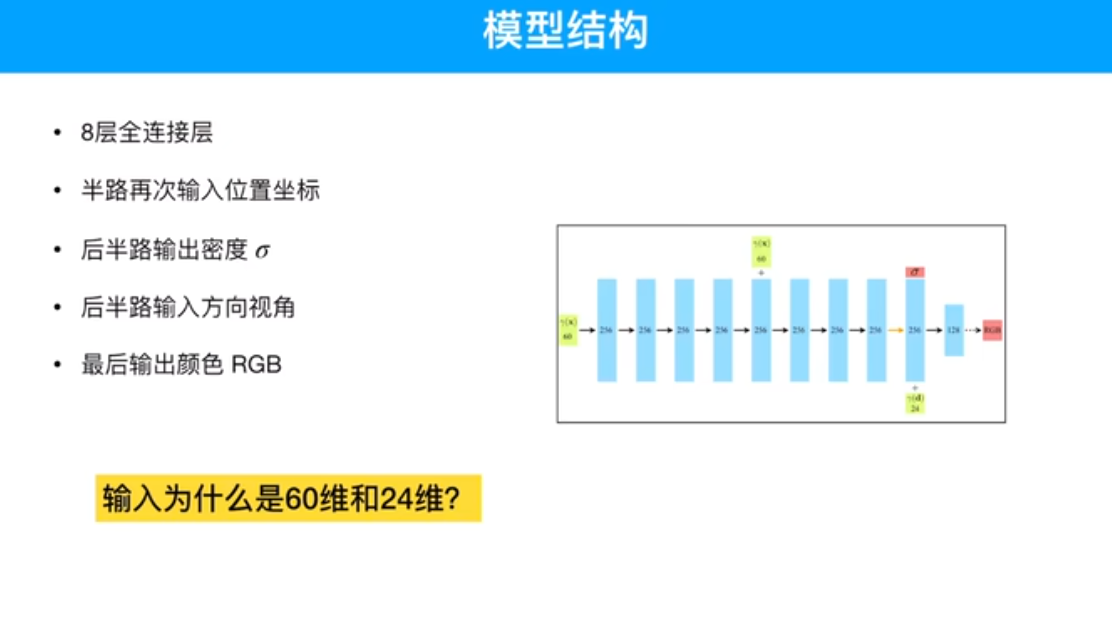

20D*3 = 60 3-xyz
8D*3 = 24 3-xyz
粒子的密度只和位置有关
颜色,因为各个角度不一样,和位置、角度都有关。

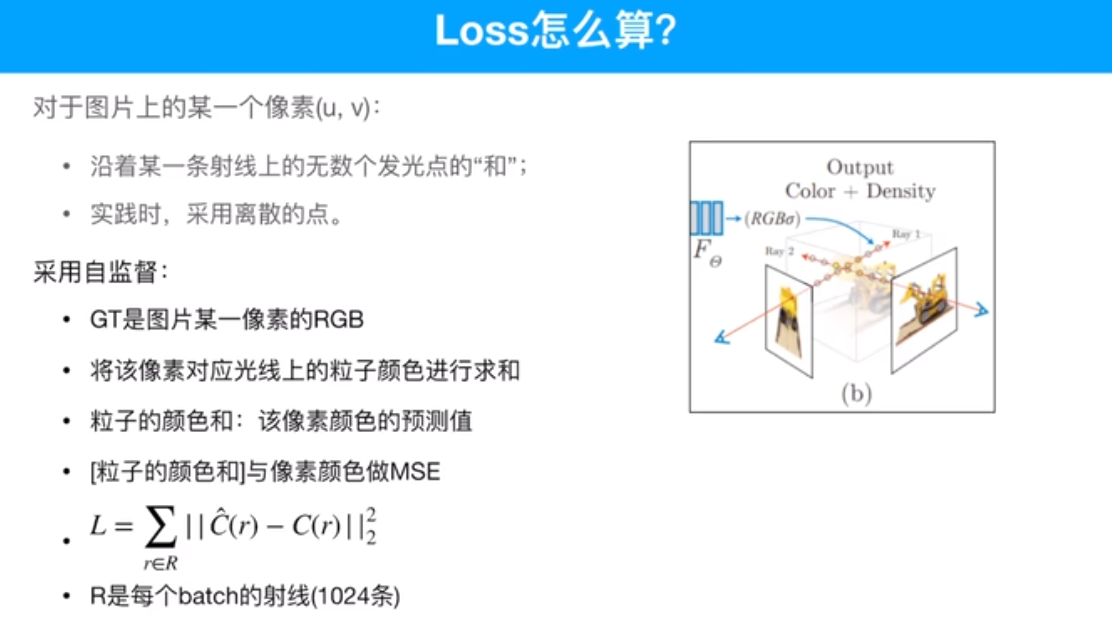
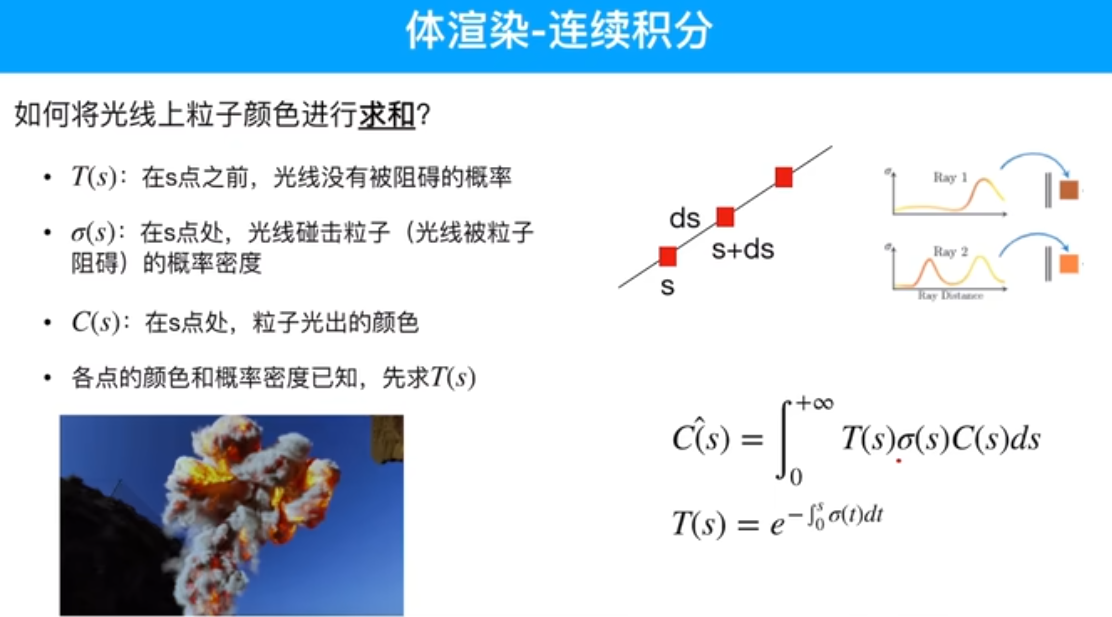
T表示光线没有被遮挡的概率
sigma 密度,密度越大越被遮挡。

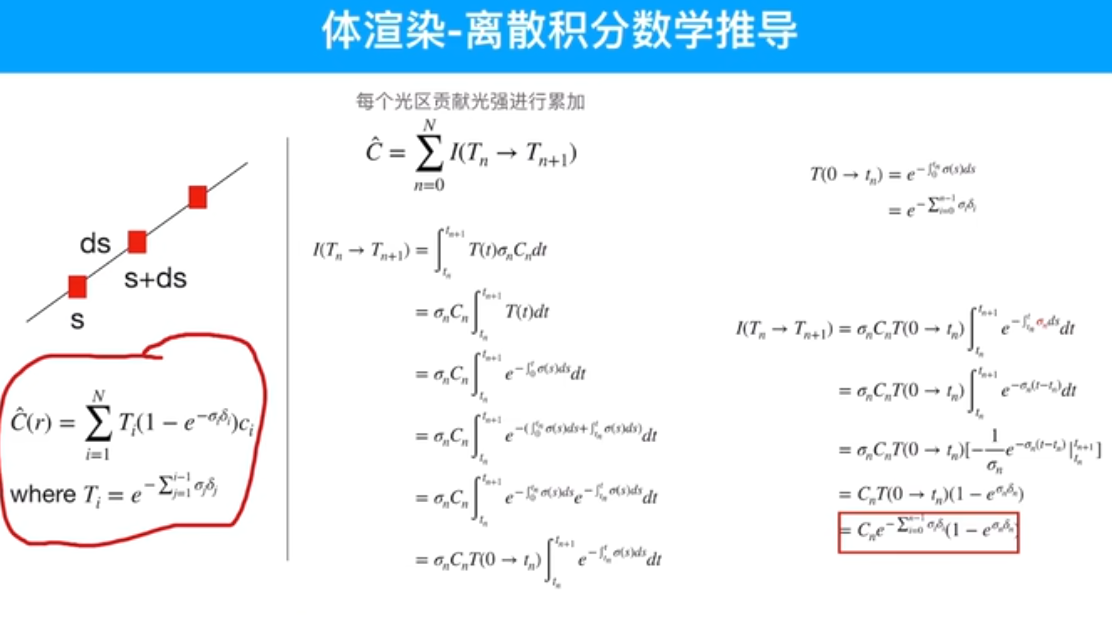
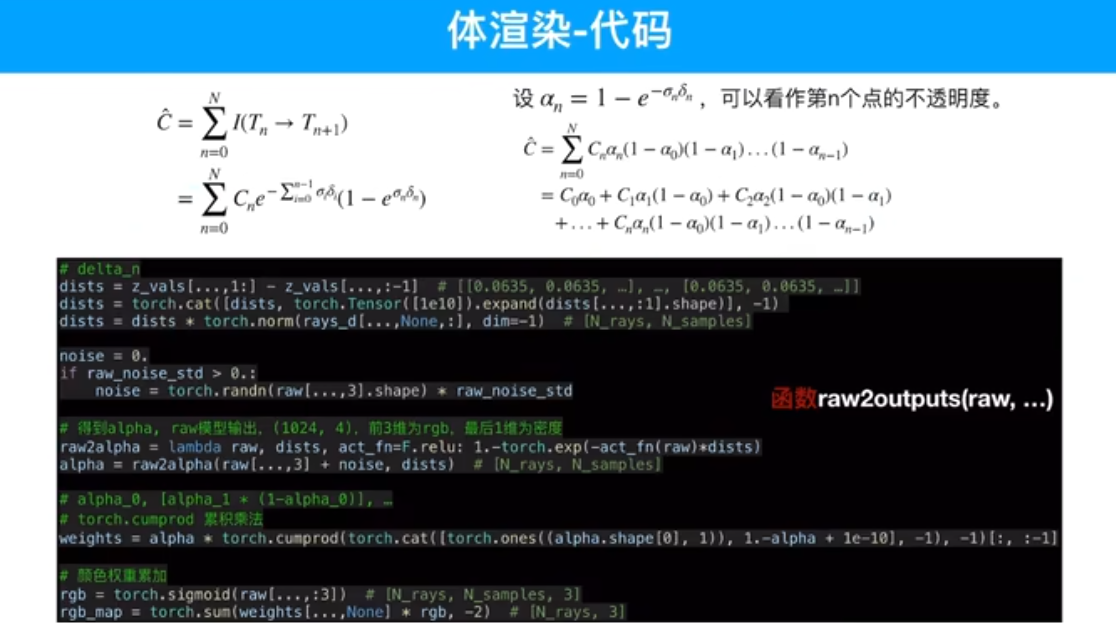
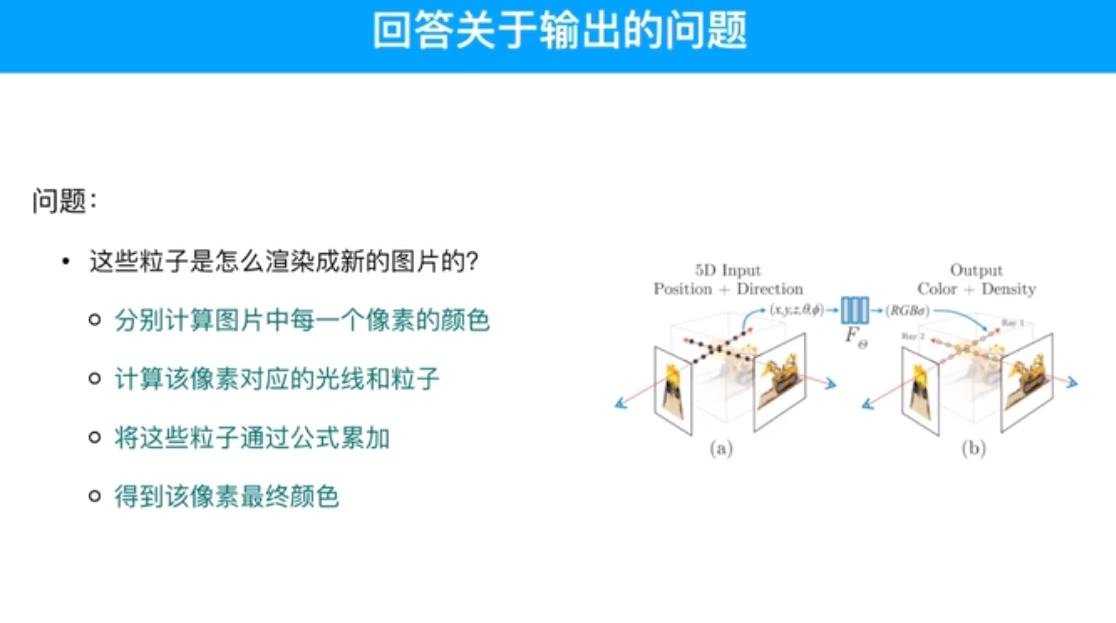
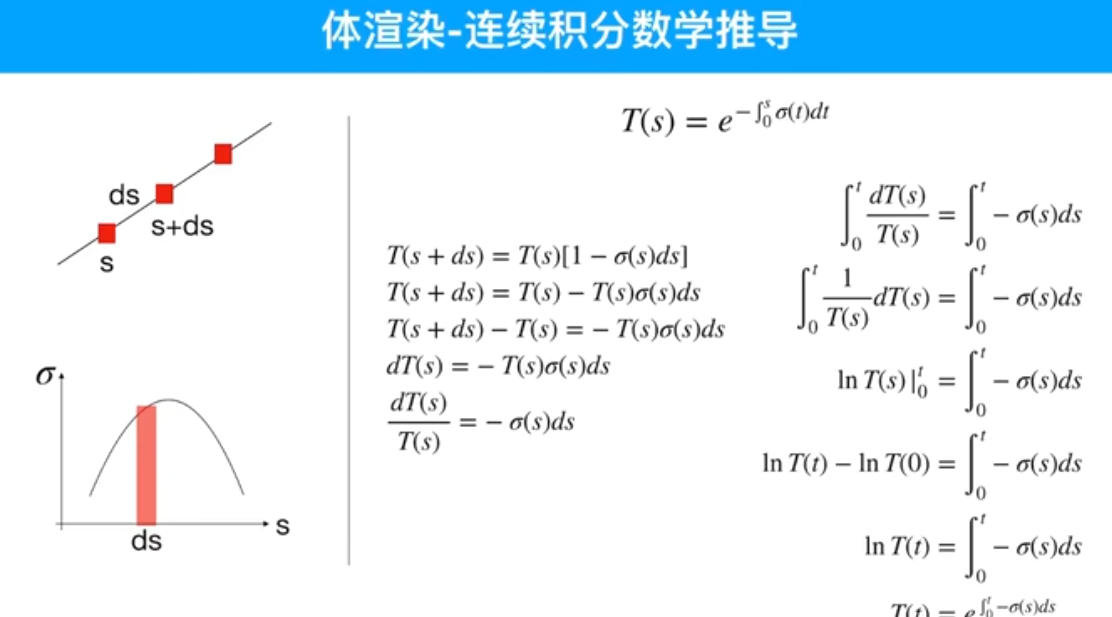
粒子输入模型时,不知道颜色,只知道位置,因为均匀采样了,把这些粒子的位姿输入到模型内部,模型通过计算给出每个粒子对应的颜色。然后通过这一串粒子算出这一个像素的颜色。颜色是预测值,再跟真值做一个MSE



【较真系列】讲人话-NeRF全解(原理+代码+公式)_哔哩哔哩_bilibili