旋转目标检测(Rotated Object Detection)技术概述
旋转目标检测(Rotated Object Detection)是计算机视觉中的重要任务,旨在检测图像中方向任意(非水平)的物体,并用带角度的矩形框(旋转框)或更复杂的形状(如四边形)表示。它在遥感(卫星/航拍图像)、场景文本检测、自动驾驶(车辆/行人)、工业质检等领域应用广泛。
以下是实现旋转目标检测的主要技术路线和方法,涵盖了从基础表示到先进架构和损失函数:
一、核心问题与基础表示
-
核心挑战: 如何有效表示和回归物体的方向(角度)信息,同时避免角度回归的周期性不连续问题(如0度和179度很接近,但数值差异大)。
-
基础表示法(旋转框):
-
五参数法 (x, y, w, h, θ): 最常用。
(x, y)是中心点,(w, h)是宽和高(通常 w > h),θ是旋转角度(通常定义范围是 [-90°, 0°)、[0°, 90°) 或 [-90°, 90°))。关键在于角度范围的定义和宽高的顺序需要一致。 -
八参数法 (x1, y1, x2, y2, x3, y3, x4, y4): 直接回归旋转框的四个角点坐标。表示更直接,但参数多,且需要保证点序(如顺时针或逆时针),回归难度稍大。
-
点集表示法: 回归一组有序的点(如四边形、多边形)来表示物体轮廓。更灵活,可表示非矩形物体,但计算更复杂。
-
二、主要技术路线与方法
(1)基于区域提议的双阶段方法 (Two-Stage)
思路: 首先生成大量的水平候选区域(Region Proposals),然后在第二阶段对这些区域进行精炼,预测旋转框参数。
代表性工作与改进:
RRPN (Rotation Region Proposal Network): 经典的旋转目标检测奠基工作。在Faster R-CNN的RPN基础上,为每个锚点引入多个角度(如6个),生成旋转候选框。第二阶段使用旋转ROI池化(Rotated ROI Align/Pooling)提取特征,预测精炼的旋转框。
R2CNN (Rotational Region CNN): 在Faster R-CNN基础上,第二阶段同时预测水平框和旋转框(或多尺度水平框),融合结果得到最终旋转框。避免显式使用旋转ROI池化。
RRD (Rotation-sensitive Regression for Detection): 设计旋转敏感的卷积滤波器,显式编码方向信息到特征中,提高方向回归精度。
RoI Transformer: 学习一个空间变换网络,将水平ROI特征图自适应地变换到旋转ROI的特征图,再送入后续检测头。比手工设计旋转ROI池化更灵活。
优点: 精度通常较高。
缺点: 速度相对较慢,流程复杂。
(2)单阶段方法 (One-Stage)
思路: 直接密集地在特征图上预测旋转框,无需单独的候选区域生成步骤。
代表性工作与改进:
RetinaNet-R (RetinaNet for Rotation): 在RetinaNet基础上,为每个锚点设置多个角度,直接预测旋转框的五个参数 (x, y, w, h, θ)。需要精心设计锚点角度。
SSD-R (SSD for Rotation): 类似思路应用于SSD框架。
RSDet (Refined Single-stage Detector): 提出“密集编码”表示法,将角度离散化为多个通道(类似分类),缓解角度回归不连续问题。使用“解耦检测头”分别处理位置/尺寸和角度信息。
Gliding Vertex (GV): 将旋转框表示为水平框 + 两个对边上的滑动顶点偏移量。有效避免了直接回归角度带来的边界不连续问题(0°和180°问题)。预测目标是一个水平矩形框和两个偏移量参数。
DCL (Densely Coded Label): 进一步改进密集编码思想,更有效地编码角度信息。
FCOS-R (FCOS for Rotation): 在无锚框的FCOS框架上扩展。预测中心点到旋转框四条边的距离(l, r, t, b)以及角度θ(或使用GV思路)。需要处理角度回归问题。
Rotated FCOS / ATSS-R: 在FCOS或ATSS基础上,增加角度预测分支,并优化角度表示和损失函数。
S2A-Net (Semantics-guided Single-shot Alignment Network): 利用特征对齐模块增强特征的方向敏感性,并引入语义引导提升小目标检测。
YOLOv8 - OBB:旋转目标检测的Backbone、Neck网络和目标检测的完全一致,只是Head层会有区别:三个尺度的特征图在head层除了生成3个预测Box的特征图(1,64,80,80)、(1,64,40,40)和(1,64,20,20);以及3个预测CLS的特征图(1,nc,80,80)、(1,nc,40,40)和(1,nc,20,20);还会另外生成3个通道数均为1,用来预测旋转角度的特征图Angle(1,1,80,80)、(1,1,40,40)和(1,1,20,20)。Angle分支为下图中浅蓝色部分(图源见水印):
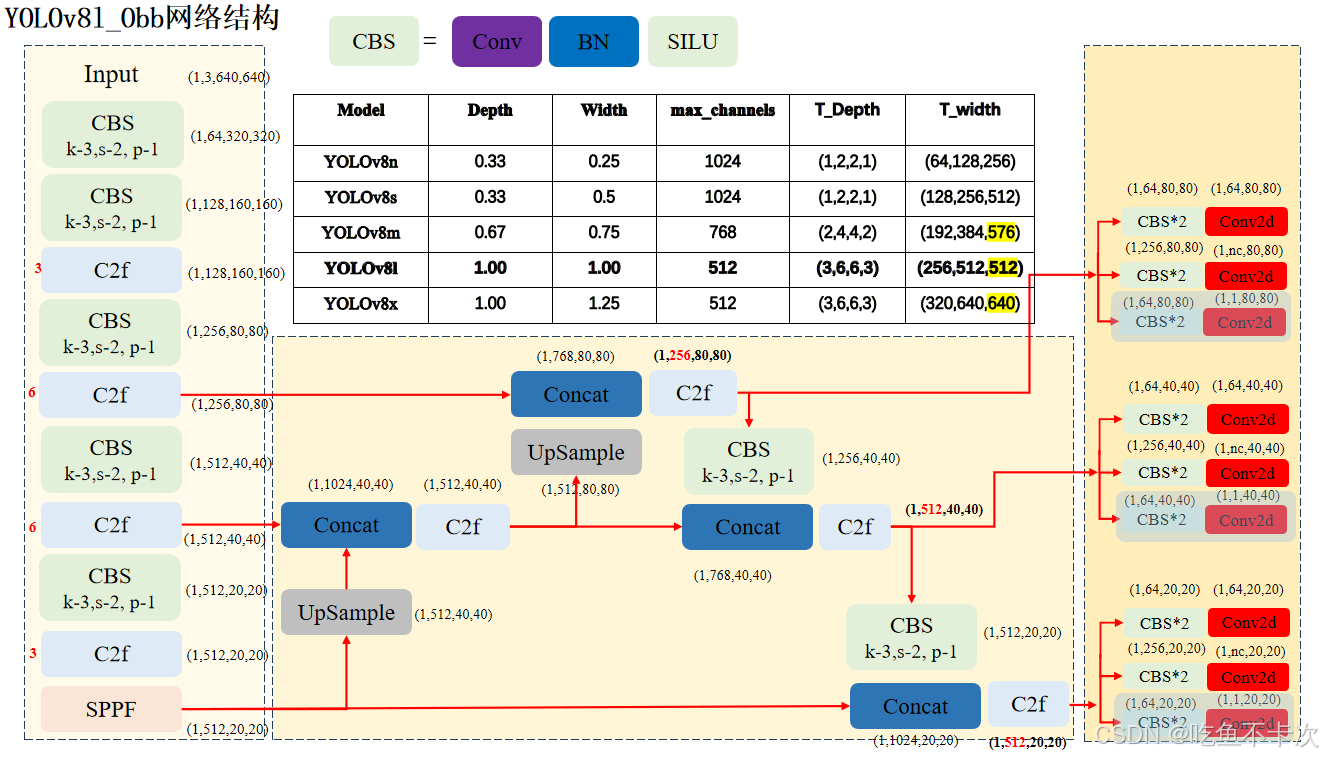
- Angel分支:如下图蓝色框区域内所示。该分支是由2个卷积组和1个卷积层构成,前两个卷积组的通道数需要符合max( ch[0] // 4, self.ne),ch[0]表示80*80尺度特征图的通道数,self.ne表示number of extra parameters,默认设置为1,这里是指只使用一个维度来预测角度(还有其他旋转框预测算法会使用三个维度的值来预测角度)。由图可知,YOLOv8l 中 80*80 尺度特征图的通道数是256,因此计算得到该分支头中前两个卷积层的通道数均是 64,最后一个卷积输出通道数是1。下图右边还展示了其他几个版本(n/s/m/x)的头部网络输出通道数变化。

【附:YOLOv8特征图是如何计算出最终的预测框的?以 (1,64,80,80) 特征图(对应小目标检测)为例逐步说明:
(1)特征图结构解析
64通道的组成:64 = 4(边界框坐标) × 16(reg_max 值)
每个坐标(x, y, w, h)用 16个值 表示离散概率分布(DFL机制)。
空间维度:80×80 表示特征图网格数,每个网格负责预测一个边界框。
(2)坐标值计算(DFL解码)
对每个网格位置 (i,j) 的64维向量,拆分为4组16维向量(每组对应一个坐标):
# 示例:位置 (i=10, j=20) 的向量
vector = [x0, x1, ..., x15, y0, y1, ..., y15, w0, ..., w15, h0, ..., h15]计算坐标值(以 x 为例):
对16个值做 Softmax 得到概率分布:
加权求和得到连续坐标:
同样方法计算 y, w, h,得到归一化的坐标值 (x, y, w, h) ∈ [0, 16]。
示例:若 Softmax 后概率集中在 k=8 和 k=9,则
表示精确偏移。
(3)坐标解码到图像空间
将归一化坐标映射回原图尺度(以 80×80 特征图为例,stride=8):
a. 中心点坐标解码
-
公式:
-
σ:Sigmoid 函数,约束偏移在
[-0.5, 1.5](跨网格预测)。 -
(i,j):网格索引(如
i=10, j=20)。 -
stride=8:特征图的下采样倍数。
计算示例:
# 中心点坐标:(172.0, 92.0)
x_pred = 8.3 -> σ(8.3) ≈ 1.0 -> (1.0*2 - 0.5 + 20) * 8 = (1.5 + 20)*8 = 172.0
y_pred = 7.8 -> σ(7.8) ≈ 1.0 -> (1.0*2 - 0.5 + 10) * 8 = (1.5 + 10)*8 = 92.0b. 宽高解码
-
公式:
-
-
anchor_w, anchor_h:该尺度的参考宽高(COCO 中stride=8时约为(10.7, 13.7))。
计算示例:
# 边界框尺寸:(42.8, 54.8)
w_pred = 9.1 -> σ(9.1) ≈ 1.0 -> (1.0*2)^2 * 10.7 = 4 * 10.7 = 42.8
h_pred = 8.5 -> σ(8.5) ≈ 1.0 -> (1.0*2)^2 * 13.7 = 4 * 13.7 = 54.8(4)多尺度融合与后处理
a. 生成所有预测框
| 特征图尺寸 | 网格数 | 预测框数 | 负责目标大小 |
|---|---|---|---|
80×80 | 6400 | 6400 | 小目标 |
40×40 | 1600 | 1600 | 中目标 |
20×20 | 400 | 400 | 大目标 |
总计:6400 + 1600 + 400 = 8400个预测框
b. 置信度过滤:分类分支输出 (1,80,80,80)(COCO的80类):
对每个框取 Sigmoid 得到类别置信度。保留置信度 > 阈值(如0.5)的框。
c. 非极大值抑制(NMS)
非极大值抑制(Non-Maximum Suppression, NMS)算法概述-CSDN博客![]() https://blog.csdn.net/qq_54708219/article/details/149480574?spm=1001.2014.3001.5502
https://blog.csdn.net/qq_54708219/article/details/149480574?spm=1001.2014.3001.5502
-
步骤:
-
按置信度降序排序所有框。
-
从最高置信度框开始,移除与其IoU > 阈值(如0.7)的同类别框。
-
重复直至处理完所有框。
-
-
输出:最终检测结果(去重后的边界框 + 类别 + 置信度)。
】
优点: 速度更快,结构相对简单。
缺点: 精度有时略低于优秀的两阶段方法(差距在缩小),小目标检测仍是挑战。
(3)基于关键点/角点的方法
思路: 将旋转框检测转化为检测物体的中心点或角点(如四边形的四个角),然后通过点组合或后处理得到旋转框。
代表性工作:
CenterNet-R: 在CenterNet框架上预测中心点、尺寸 (w, h) 和偏移量 (offset)。对于旋转框,增加一个角度θ分支。同样面临角度回归问题。
CornerNet-R / ExtremeNet-R: 检测物体的角点或极值点,然后通过分组算法(如嵌入向量)将属于同一个物体的点组合起来形成四边形。天然适合表示旋转物体。分组步骤是关键和潜在瓶颈。
优点: 表示灵活(可扩展到非矩形),部分方法速度快。
缺点: 点分组可能复杂且容易出错,特别是物体密集重叠时;后处理可能较慢。
(4)基于分割的方法
思路: 先进行实例分割得到物体的精确掩码,然后从掩码中拟合出最小外接旋转矩形框(或直接输出四边形)。常用后处理算法有OpenCV的minAreaRect。
代表性框架: Mask R-CNN -> minAreaRect。
优点: 能获得非常精确的物体轮廓,拟合出的旋转框通常很贴合。
缺点: 计算开销大(需要像素级预测);拟合矩形框的步骤是后处理,无法端到端优化旋转框指标;对小、细长物体拟合可能不稳定。
三、关键技术与改进点
(1)旋转不变/等变特征学习
目标: 使网络提取的特征对物体的旋转具有不变性(类别特征)或等变性(位置/方向特征)。
方法:
旋转数据增强: 在训练时随机旋转图像和标注框,是最常用且有效的基础方法。
可变形卷积: 能自适应学习采样位置,一定程度上捕捉旋转形变。
旋转卷积/群卷积: 显式设计在不同角度上共享权重的卷积核(如 ORN, Rotated Convolution)。计算成本较高。
方向敏感特征图: 如RRD,显式学习不同方向的滤波器响应。
(2)旋转框的表示与参数化
角度范围限制: 将θ限制在 [-90°, 0°) 或 [0°, 90°) 等范围,避免180°歧义(一个矩形有两种表示法)。
宽高顺序约定: 通常约定 w 代表长边,h 代表短边(或反之),并与角度范围定义保持一致。
避免直接回归角度:
角度分类: 将角度离散化为多个区间(如180个bin,每2°一个),预测角度类别(或同时预测类别和偏移量)。
点偏移表示: 如Gliding Vertex (GV),将旋转框参数化为水平框+滑动顶点偏移。
向量表示: 如预测两条相邻边的向量。
(3)损失函数设计
回归损失 (L1/Smooth L1): 直接用于回归 (x, y, w, h, θ)。但Smooth L1对角度θ不友好,因为周期性边界问题(0°和180°数值差大但实际是同一个方向)。
IoU-based 损失: 更符合检测评估指标。
- 旋转IoU (RIoU): 计算两个旋转框的交并比。计算相对复杂且不可导(早期)。
- 近似IoU损失: 如使用投影法计算近似IoU,使其可导。
- GIoU/DIoU/CIoU for Rotation: 将水平框的IoU变体推广到旋转框。
- SkewIoU: 高效计算旋转矩形IoU及其导数的库/方法。
- KLD (Gaussian Kullback-Leibler Divergence): 将旋转框建模为二维高斯分布,计算两个高斯分布之间的KLD作为损失。能更好地处理角度和长宽比。
- GWD (Gaussian Wasserstein Distance): 另一种基于高斯分布的距离度量,用作损失函数。
- ProbIoU: 基于概率分布的IoU近似。
角度特定损失:
- Circular Smooth L1 (CSL): 将角度视为圆形空间,在圆形域上计算 Smooth L1 损失。有效解决边界不连续问题。
- Densely Coded Label (DCL) Loss: 结合密集编码表示的损失。
任务解耦损失: 将位置/尺寸回归和角度回归分开,使用不同的损失函数或分支。
(4)特征对齐与采样
-
旋转ROI对齐/池化: 在双阶段方法中,根据预测的旋转框角度从特征图中精确提取旋转区域内的特征。
-
可变形ROI对齐: 增强对旋转形变的适应能力。
-
对齐卷积/对齐模块: 在单阶段或特征提取阶段引入对齐操作,使特征与目标方向对齐(如 S2A-Net)。
四、常用数据集与评估指标
-
数据集:
-
DOTA: 大规模遥感图像数据集,包含15类、各种方向、尺度和密度的目标。是旋转检测的基准数据集。
-
HRSC2016: 高分辨率舰船数据集。
-
UCAS-AOD: 飞机和汽车数据集。
-
ICDAR 2015 (Incidental Scene Text): 自然场景中的任意方向文本检测。
-
MSRA-TD500: 多语言长文本行检测。
-
-
评估指标:
-
mAP (mean Average Precision): 最核心指标。计算不同IoU阈值(通常为0.5, 对于旋转框用旋转IoU)下的平均精度。
-
AP50, AP75: IoU阈值分别为0.5和0.75时的AP。
-
精度、召回率、F1分数: 在特定IoU阈值下计算。
-
速度 (FPS): 每秒处理的图像帧数。
-
五、技术选型考虑因素
-
精度要求: 双阶段方法(如RoI Transformer)通常精度最高;单阶段(如Rotated FCOS, S2A-Net)在速度和精度间取得较好平衡。
-
速度要求: 单阶段方法(特别是无锚框的FCOS变种)通常更快;基于关键点的方法(CenterNet)也可能很快。
-
目标形状: 规则矩形(旋转框足够) vs. 不规则形状(可能需要点集/分割方法)。
-
目标密度: 密集场景下,基于关键点/角点的方法分组可能困难;单/双阶段方法相对鲁棒。
-
目标尺度: 小目标检测是难点,需要关注特征金字塔、上下文信息、高分辨率特征图等设计(如S2A-Net)。
-
角度范围与变化: 所有目标都近似水平?还是任意方向?是否需要处理极端长宽比?
-
计算资源: 双阶段、基于分割的方法计算开销更大。
六、总结与趋势
-
主流趋势: 单阶段方法凭借较好的速度-精度平衡成为研究和应用热点,尤其是基于FCOS、ATSS等无锚框框架的改进版本(如Rotated FCOS, S2A-Net)。GV、CSL、KLD/GWD等改进表示法和损失函数极大地缓解了角度回归问题。
-
关键技术点: 解决角度表示与回归的不连续性问题(CSL, GV, KLD等)和提升旋转不变/等变特征表达能力(数据增强、可变形卷积、特征对齐等)是核心。
-
挑战:
-
极端小目标、极端长宽比目标(如电线、舰船)的检测。
-
密集排列、严重遮挡场景下的目标区分。
-
旋转IoU计算的效率和可导性(虽有改进,仍是瓶颈)。
-
设计更高效、轻量化的旋转检测器。
-
-
未来方向:
-
更鲁棒、高效的角度表示和损失函数。
-
结合视觉Transformer探索全局上下文和旋转关系建模。
-
自监督/半监督学习减少对大量旋转标注数据的依赖。
-
设计专为旋转检测优化的轻量级骨干网络和检测头。
-
多模态融合(如结合深度、热红外信息)提升复杂场景下的检测能力。
-
选择哪种技术取决于具体的应用场景、性能需求和资源限制。目前没有“一刀切”的最佳方案,需要根据实际情况评估和选择,并可能结合多种技术进行优化。