DAY19 常见的特征筛选算法
@浙大疏锦行
知识点:
- 方差筛选
- 皮尔逊相关系数筛选
- lasso筛选
- 树模型重要性
- shap重要性
- 递归特征消除REF
作业:对心脏病数据集完成特征筛选,对比精度
1 特征筛选
目的:特征筛选的本质是从原始特征集中选择出对目标任务最有价值的子集,最终服务于模型性能和分析效率的提升
原理:特征筛选的原理基于 “特征重要性评估”:通过量化每个特征与目标变量的关联度、或特征对模型的贡献度,保留得分高的特征,剔除得分低的特征。不同方法的核心差异在于 “如何定义和计算重要性”
流程:评估特征与目标的 “相关性” 或 “贡献度”–>设定筛选标准(阈值或数量)–>确保筛选后的子集 “最优”
2 作业
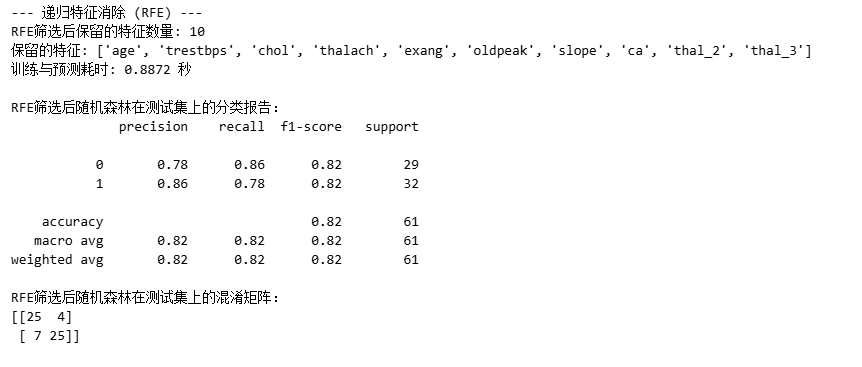
首先需要使用默认参数的随机森林进行训练,便于后续精度的对比
2.1 方差筛选
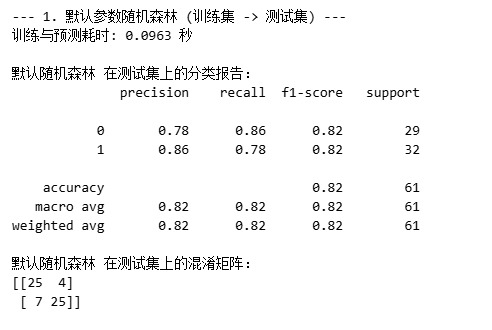
核心逻辑:方差越小的特征,携带的信息越少,对模型的贡献也越小,可以直接剔除。因此计算每个特征的方差,设定方差阈值,保留方差高于阈值的特征。
print("--- 方差筛选 (Variance Threshold) ---")from sklearn.feature_selection import VarianceThreshold
import timestart_time = time.time()selector = VarianceThreshold(threshold=0.01)X_train_var = selector.fit_transform(X_train)X_test_var = selector.transform(X_test)selected_features_var = X_train.columns[selector.get_support()].tolist()print(f"方差筛选后保留的特征数量: {len(selected_features_var)}")
print(f"保留的特征: {selected_features_var}")rf_model_var = RandomForestClassifier(random_state=42)rf_model_var.fit(X_train_var, y_train)rf_pred_var = rf_model_var.predict(X_test_var)end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")print("\n方差筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_var))print("方差筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_var))
2.2 皮尔逊相关系数筛选
** 核心逻辑**:剔除与目标变量 “线性关联性弱” 的特征,保留关联性强的特征。
print("--- 皮尔逊相关系数筛选 ---")
from sklearn.feature_selection import SelectKBest, f_classif
import timestart_time = time.time()# 计算特征与目标变量的相关性,选择前k个特征(这里设为10个,可调整)
# 注意:皮尔逊相关系数通常用于回归问题(连续型目标变量),但如果目标是分类问题,可以用f_classif
k = 10
selector = SelectKBest(score_func=f_classif, k=k)
X_train_corr = selector.fit_transform(X_train, y_train)
X_test_corr = selector.transform(X_test)selected_features_corr = X_train.columns[selector.get_support()].tolist()
print(f"皮尔逊相关系数筛选后保留的特征数量: {len(selected_features_corr)}")
print(f"保留的特征: {selected_features_corr}")rf_model_corr = RandomForestClassifier(random_state=42)
rf_model_corr.fit(X_train_corr, y_train)
rf_pred_corr = rf_model_corr.predict(X_test_corr)end_time = time.time()
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n皮尔逊相关系数筛选后随机森林在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_corr))
print("皮尔逊相关系数筛选后随机森林在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_corr))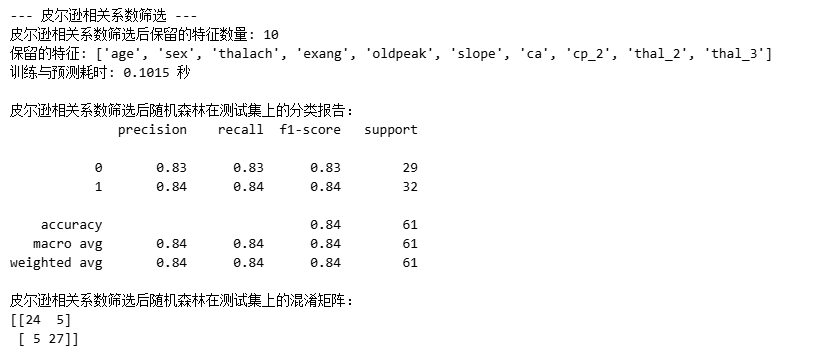
2.3 lasso筛选
核心逻辑:在进行线性回归的同时,通过引入L1正则化项(即惩罚项),强制将一些不重要特征的回归系数压缩到0,从而实现特征筛选。

2.4 树模型自动性

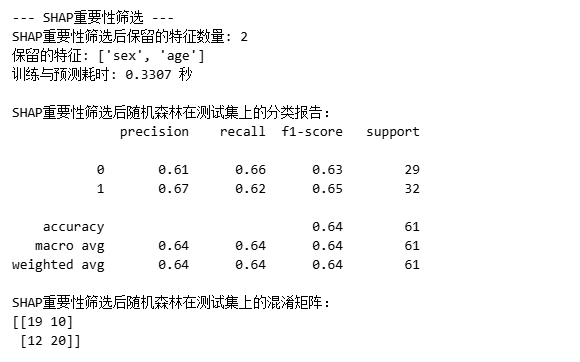
2.5 SHAP重要性筛选
2.6 递归特征消除RFE
核心思想:是通过递归地移除最不重要的特征,逐步缩小特征集,直到达到预设的特征数量或满足其他停止条件。