Pytorch02:深度学习基础示例——猫狗识别
一、第三方库介绍
| 库/模块 | 功能 |
|---|---|
| torch | 提供张量操作、自动求导、优化算法、神经网络模块等基础设施。 |
| torchvision | 计算机视觉工具集,提供预训练模型、数据集、图像转换等功能。 |
| datasets (torchvision) | 用于加载常见数据集(如 ImageNet、CIFAR-10、MNIST)。 |
| transforms (torchvision) | 提供图像数据的预处理、数据增强操作(如大小调整、裁剪、转换为张量、归一化等)。 |
| nn (torch) | 用于定义和构建神经网络,包含各类网络层、损失函数等。 |
| optim (torch) | 提供优化算法(如 Adam、SGD、RMSprop)用于更新神经网络权重。 |
| DataLoader (torch.utils.data) | 用于批量加载数据,支持多线程加载数据,按批次读取数据。 |
| Image (PIL) | 用于图像处理(加载、裁剪、旋转、缩放、保存图像等)。 |
| ResNet18_Weights (torchvision.models) | 提供 ResNet18 模型的预训练权重,可用于迁移学习。 |
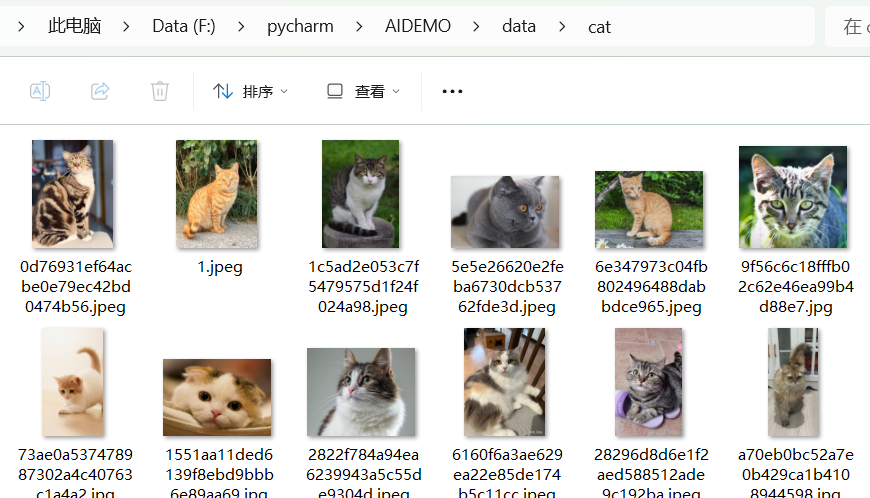
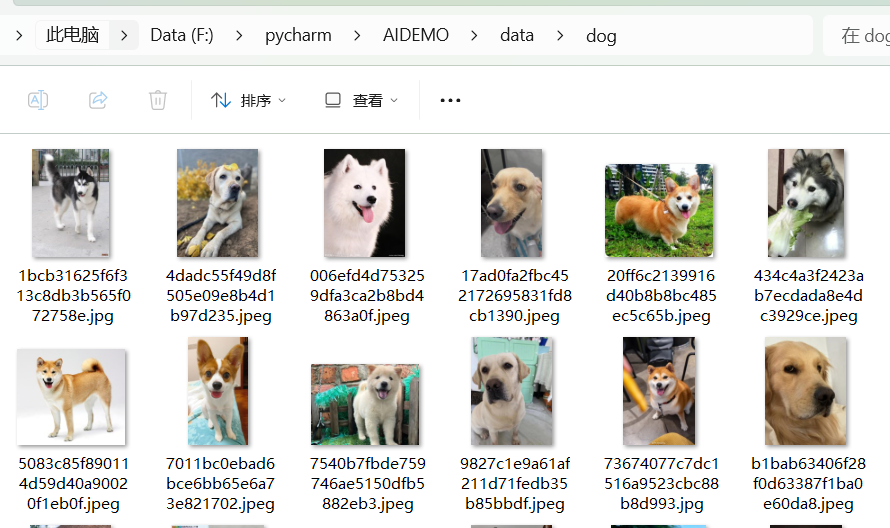
二、训练数据集介绍
三、原理简介
该代码使用PyTorch训练一个基于ResNet-18的猫狗分类模型。通过加载并处理数据、训练模型、调整最后输出层、使用Adam优化器进行反向传播,并在每个训练周期输出损失与准确率。训练完毕后,保存模型用于后续预测。
四、代码思路简介
- 加载数据 → 使用
datasets.ImageFolder加载猫狗数据集,并应用图像转换。 - 构建模型 → 使用预训练的 ResNet-18 模型,修改输出层以适应2类分类。
- 定义损失和优化器 → 使用交叉熵损失函数和 Adam 优化器。
- 训练模型 → 遍历数据集,前向传播、计算损失、反向传播、更新模型参数。
- 保存模型 → 训练完成后,保存模型权重。
- 预测图片 → 加载已训练模型,输入图片进行预测并输出分类结果。
五、代码
场景:使用pytorch识别猫狗
猫的图片路径:F:\pycharm\AIDEMO\data\cat
狗的图片路径:F:\pycharm\AIDEMO\data\dog
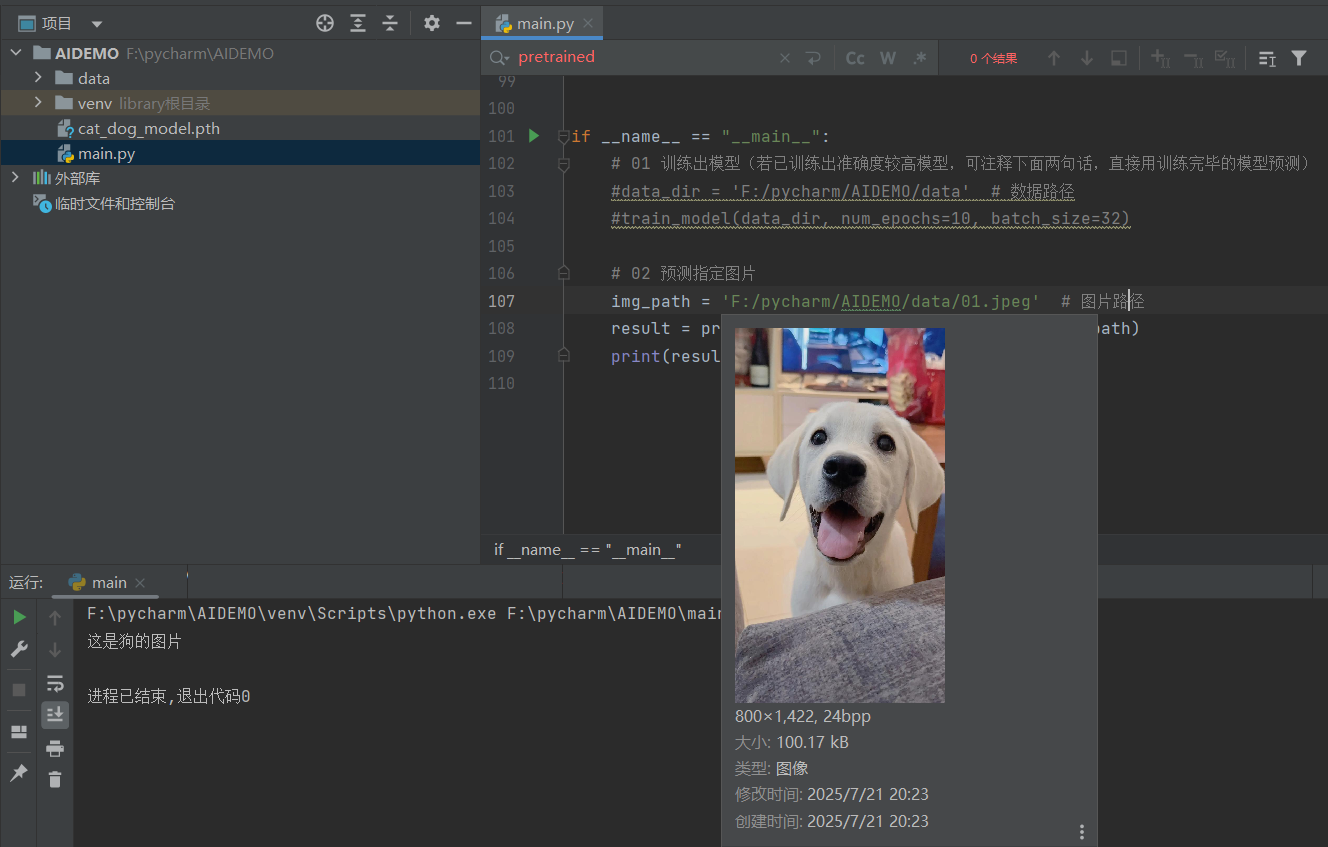
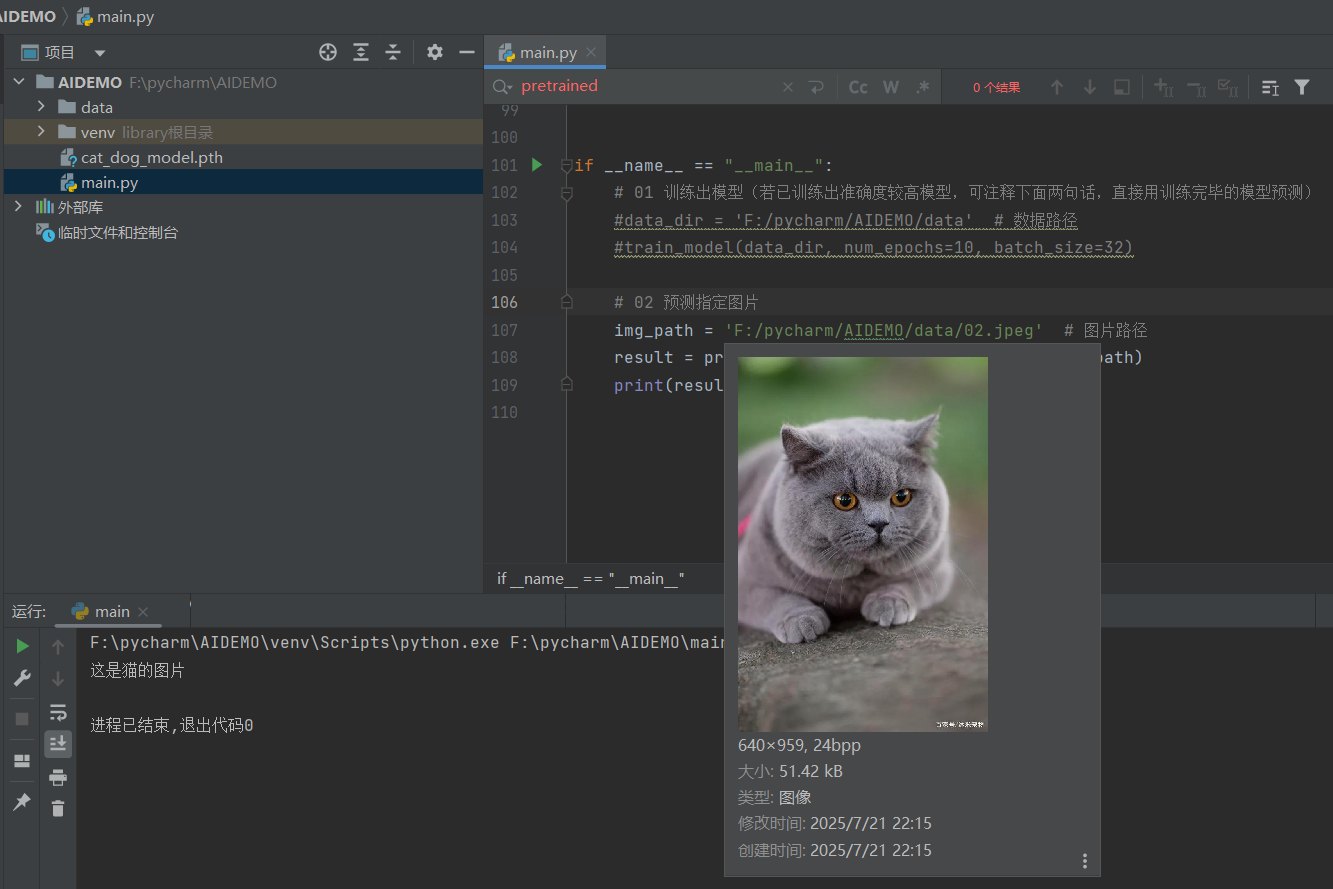
需要判断的图片:F:\pycharm\AIDEMO\01.jpeg
import torch
import torchvision
from torchvision import datasets, transforms
from torch import nn, optim
from torch.utils.data import DataLoader
from PIL import Image
from torchvision.models import ResNet18_Weights# 定义transform类(视觉转换类,将图片格式转化为张量格式)
transform = transforms.Compose([transforms.Resize((128, 128)), # 将图片缩放到统一大小transforms.ToTensor(), # 转换为Tensor格式transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化处理
])def train_model(data_dir, num_epochs=10, batch_size=32, save_path='cat_dog_model.pth'):"""训练模型并保存。:param data_dir: 数据路径,包含cat和dog文件夹:param num_epochs: 训练周期,默认为10:param batch_size: 批次大小,默认为32:param save_path: 模型保存路径,默认为'cat_dog_model.pth'"""# 1. 加载训练数据train_data = datasets.ImageFolder(root=data_dir, # 数据路径transform=transform)print(train_data.class_to_idx) # 输出文件夹编号,例如这里输出{'cat': 0, 'dog': 1},表达0代表猫猫,1代表狗狗train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)# 2. 使用预训练的ResNet18模型model = torchvision.models.resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)model.fc = nn.Linear(model.fc.in_features, 2) # 修改输出层以适应2类分类(猫、狗)# 3. 定义损失函数和优化器criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 4. 开始训练模型for epoch in range(num_epochs):model.train() # 设置模型为训练模式running_loss = 0.0 # 初始化损失值correct = 0 # 模型预测准确数total = 0 # 模型预测总数for images, labels in train_loader:optimizer.zero_grad() # 清除之前的梯度outputs = model(images) # 前向传播,得出预测结果loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数running_loss += loss.item()# 计算准确率_, predicted = torch.max(outputs, 1) # 获取预测结果total += labels.size(0) # 累计总样本数correct += (predicted == labels).sum().item() # 累计预测正确的样本数# 输出训练周期的损失和准确率accuracy = 100 * correct / total # 计算准确率print(f'周期 [{epoch + 1}/{num_epochs}], 损失: {running_loss / len(train_loader):.4f}, 准确率: {accuracy:.2f}%')if accuracy == 100: # 准确率达到100%就停止训练,避免过度拟合break# 保存训练模型torch.save(model.state_dict(), save_path)def predict_image(model_path, img_path):"""加载训练好的模型并进行图片预测。:param model_path: 训练好的模型路径:param img_path: 需要预测的图片路径:return: 预测结果(猫或狗)"""# 加载模型model = torchvision.models.resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)model.fc = nn.Linear(model.fc.in_features, 2)model.load_state_dict(torch.load(model_path))model.eval() # 设置模型为评估模式# 预测指定图片img = Image.open(img_path)img = transform(img).unsqueeze(0) # 将图片处理成张量输出并增加batch维度# 模型预测with torch.no_grad(): # 不需要梯度计算,只是进行模型预测outputs = model(img)_, predicted = torch.max(outputs, 1)# 输出预测结果return "这是猫的图片" if predicted.item() == 0 else "这是狗的图片"if __name__ == "__main__":# 01 训练出模型(若已训练出准确度较高模型,可注释下面两句话,直接用训练完毕的模型预测)data_dir = 'F:/pycharm/AIDEMO/data' # 数据路径train_model(data_dir, num_epochs=10, batch_size=32)# 02 预测指定图片img_path = 'F:/pycharm/AIDEMO/data/01.jpeg' # 图片路径result = predict_image('cat_dog_model.pth', img_path)print(result)
六、输出结果展示