【论文研读】SlowFast Networks for Video Recognition
论文简介
标题:SlowFast Networks for Video Recognition
作者:Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, Kaiming He
期刊:IEEE
年份:2019
引用:C. Feichtenhofer, H. Fan, J. Malik and K. He, "SlowFast Networks for Video Recognition," 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019, pp. 6201-6210, doi: 10.1109/ICCV.2019.00630.
论文模型架构
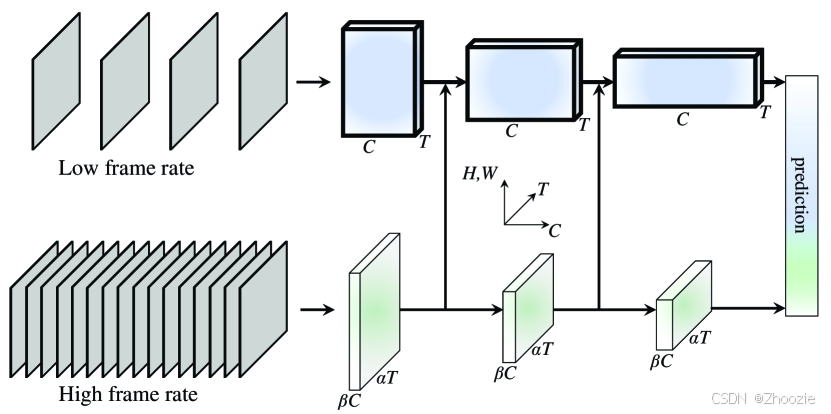
上图为 SlowFast 网络分为两种 Slow pathway 与 Fast pathway,而在其过程中又将 Fast 路径的输出结果通过侧向连接送入 Slow 通道,最终进行结果预测。
Slow pathway & Fast pathway
Slow 通道主要捕捉视频中的空间语义信息(如物体、场景等静态或缓慢变化的特征)。其采取了Low frame rate 获取低频图像数据。在论文实验中 Slow 通道设置了每秒跳过16帧(τ=16),即若按30FPS每秒的视频,刷新速度大约每秒2帧采样。将 Slow 通路采样的帧数表示为 T ,原始片段长度是 T×τ 帧。
Fast 通道主要捕捉快速运动信息(如动作细节、瞬时变化)。其采取了 High frame rate 用于获取高频图像数据。
Fast 通道追求高帧率、高时间分辨率以及低通道数量。为了实现高帧率,Fast 通道使用小的时序步长 τ/α ( 其中,α>1 是 Fast 和 Slow 通路之间的帧率比,Fast 通道采样帧数为 αT 会比 Slow 通道密集α倍)。为了实现高时间分辨率,Fast 通道到分类前的全局池化层之前,都没有使用任何时间下采样层(既没有时间池化也没有时间步长卷积)。为了实现低通道数量,Fast 通道数量通常为 Slow 通道数的 β ( β<1 )倍。
Lateral connections
Slow 通道和 Fast 通道两条通道的信息会进行融合,由 Fast 通道将信息传递至 Slow 通道,故而一条通路不会对另一条通路学习到的表示一无所知。
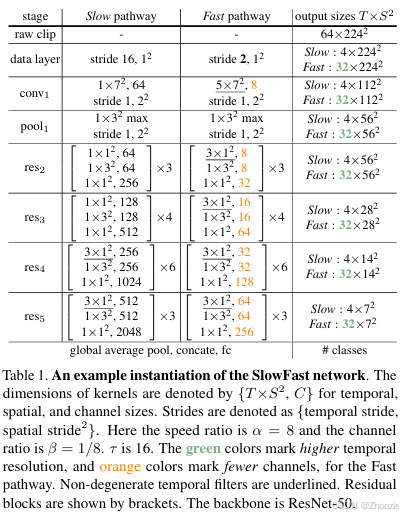
论文相关实验
论文在四个数据集(Kinetics-400 、Kinetics-600、Charades、AVA)中进行了实验验证。其中前三个数据集用于验证动作分类,最后一个数据集用于验证动作检测。
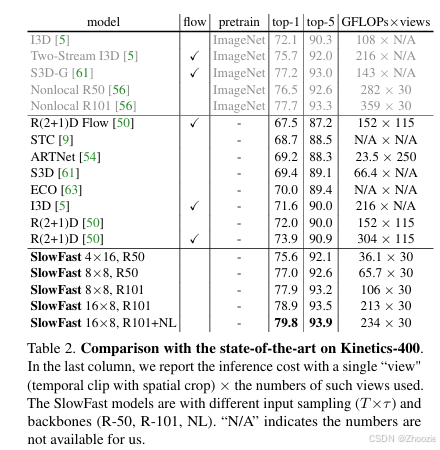
论文在Kinetics-400上取得很好的效果,实验数据如下图:
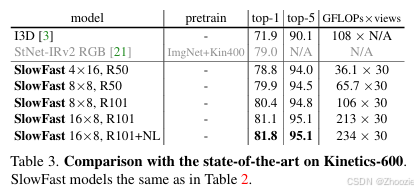
论文在Kinetics-600上的数据如下:
论文在AVA数据集上进行实验得到如下数据: