【Linux】2. Linux下的C/C++开发环境
本文主要介绍了C/C++的在Linux下的开发环境,先简单介绍了编译链接过程,为学习C/C++项目做铺垫。介绍了3种开发工具:gcc/g++编译器、gdb调试器、makefile项目构建工具。然后介绍了动静态库以及版本控制器git的使用方法。
Linux下的C/C++开发环境
- 一、C/C++项目环境
- 1. 编译链接过程简述
- 2. gcc/g++编译器
- 3. gdb调试器
- 4. Makefile自动化项目构建工具
- 4.1 make命令和Makefile文件
- 4.2 Makefile基本语法规则
- 二、动静态库
- 1. 函数库的概念
- 2. 动静态库的操作
- 三、git版本控制器
- 1. git的介绍
- 2. gitee的使用
一、C/C++项目环境
1. 编译链接过程简述
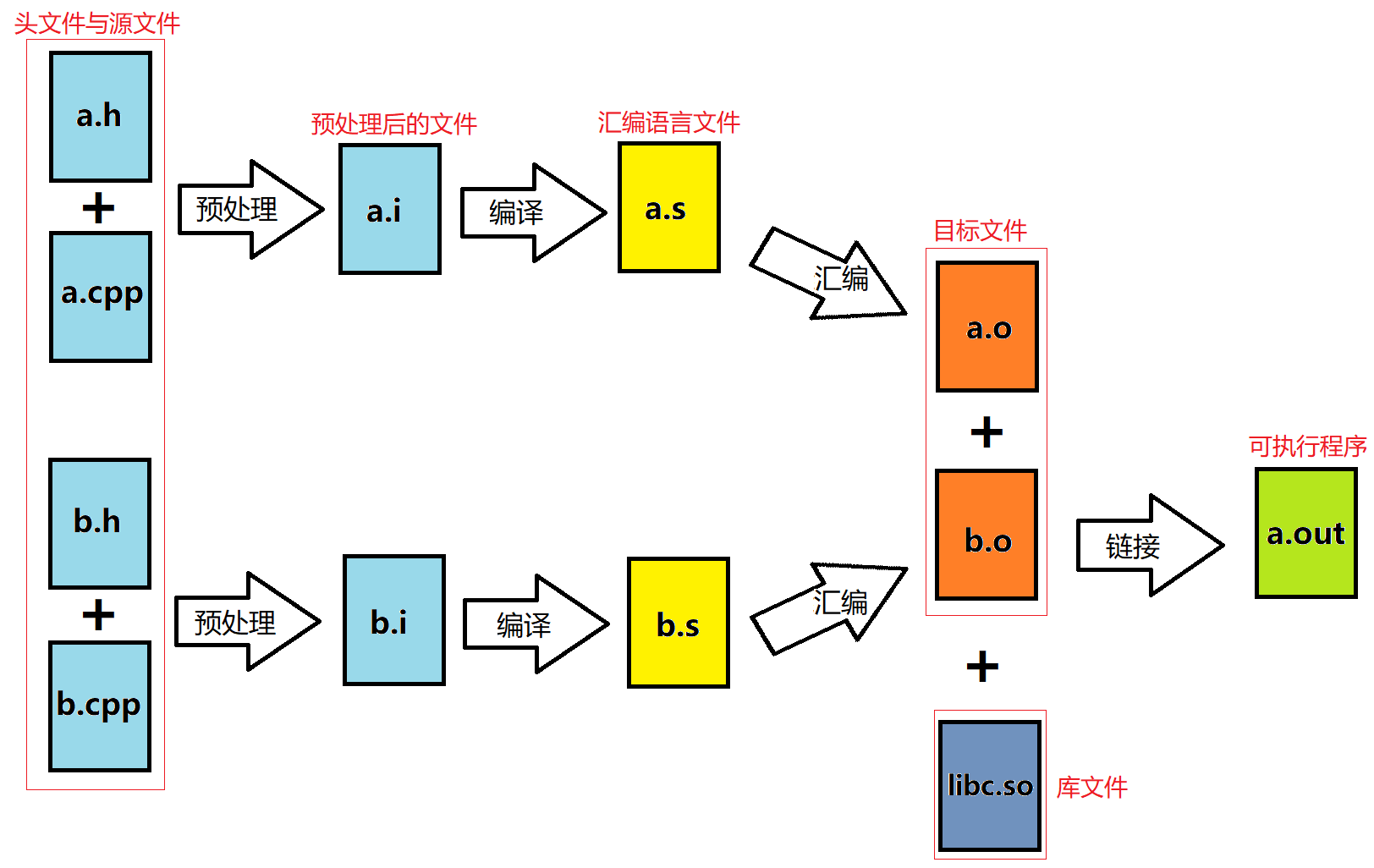
C/C++代码编译成可执行程序需要经历以下4个步骤:
- 预处理:
head.h + source.cpp => source.i- 头文件展开:将头文件的内容复制到源文件中。
- 去注释:将注释内容替换成空格。
- 宏替换、条件编译等预编译语法的执行。
- 编译:
source.i => source.s- 将每一个预处理后的源文件转换为汇编语言文件。
- 汇编:
source.s => source.o- 将每个汇编语言文件编译成二进制指令文件,该文件称为目标文件。
- 链接:
source.o + lib.so => a.out- 目标文件中可能调用了其他目标文件的内容,也调用了库函数中的内容,将它们链接到一起形成一个可执行的二进制文件。
注意:
- 预处理后还是C语言文件,只是没有任何注释和预处理指令。并且引入的头文件中的全部内容被拷贝到源文件中。
- 目标文件是计算机可以识别的二进制指令,但是并不能直接执行,只有经过链接的才能形成可执行文件。
- 通常预处理、编译、汇编三个过程会口头简称为编译,因此生成程序的过程会简称为编译链接。
2. gcc/g++编译器
gcc是C语言的编译器,g++是C++语言的编译器,二者用法基本相似。在Linux系统中可以使用这两个命令分别编译C/C++代码。
gcc编译的源文件名称须以
.c后缀结尾,g++以.cpp或.cc后缀结尾。
(1)逐步编译源文件
gcc [-op] [source.c] -o [name] # 将source.c文件编译成name文件gcc -E source.c -o source.i # 将source.c预处理,并将结果写入source.i文件中
gcc -S source.i -o source.s # 将source.i编译成汇编语言,并写入source.s文件中
gcc -c source.s -o source.o # 将source.s编译成目标文件,并写入source.o文件中
gcc source.o -o source # 将source.o链接,形成source可执行程序g++ source.cpp -o source # 将source.cpp源文件编译链接形成可执行文件source
-o:将编译后文件输出到指定文件中(相当于为生成的文件起名字),没有时文件名默认为a.out-E:预处理源文件,预处理后的文件一般以.i为后缀名(预处理)。-S(大写):将文件编译成汇编语言,汇编语言文件以.s为后缀名(编译)。-c(小写):将文件编译成二进制的目标文件,目标文件以.o为后缀名(汇编)。
-s、-c并非只能编译预处理好的文件,若是参数为源文件,也可以直接编译到汇编语言和目标文件的阶段。gcc/g++不带步骤选项时,会直接完成编译链接等步骤,一步到位生成可执行程序。-o选项后紧接着是生成文件的名称,这个选项和命名可以放在gcc/g++的后面,如g++ -o source source.cpp。
(2)多文件编译
一个可执行程序的源文件和头文件可能不止一个,gcc/g++可以同时对多个文件进行编译。
- 多文件编译时可以不用在指令中书写头文件,因为头文件在源文件中已经被引用(写了头文件也不会报错,后面部分代码中会写入头文件以便更全面展示编译链接过程)。
- 将需要编译的源文件用空格隔开,放在gcc/g++指令后即可。
# 将source_1.cpp、source_2.cpp、source_3.cpp编译成source程序
g++ source_1.cpp source_2.cpp source_3.cpp -o source
(3)编译器优化
使用编译器优化选项可以生产内存更小、效率更高的可执行程序。
g++ main.cpp -o a.out -O3 # 使用O3级别的优化,将main.cpp编译成a.out可执行程序
-O0:没有优化。-O1:为缺省值,默认的优化级别。-O2:优化级别比-O1高。-O3:优化级别最高。
(4)编译其他形式的程序
这里是gcc/g++一些选项的汇总,详解在本文后面都有介绍:
g++ -g main.cpp -o a.out # 生成debug版本的a.out程序,用于gdb调试gcc -o a.out main.c -I . -L . -lab # 使用函数库ab生成a.out程序,头文件和库文件在当前目录
gcc -static -o a.out main.c -I . -L . -lab # 使用静态库库libab.a生成a.out程序,头文件和库文件在当前目录gcc -fPIC -c source.c -o object.o # 生成与地址无关代码的目标文件object.o
gcc -shared object.o -o libab.so # 用object.o创建动态库libab.so
-
调试有关选项:在本文《gdb调试器》处。
-g:生成debug版本程序,程序内有调试信息,用来调试程序以便发现程序的错误。
-
动静态库有关选项:在本文《动静态库》处。
-
-static:在链接时强制使用静态库生成程序。 -
-shared:创建动态库。 -
-fPIC:生成与地址无关的代码,解决动态库每次加载进内存时,地址变化的问题,生成目标文件时使用。 -
-I:链接时指定头文件地址。 -
-L:链接时指定库文件地址。 -
-l:指定函数库名称,函数库要去掉lib和后缀,如libab.so是-lab。
-
3. gdb调试器
gdb是程序调试器,能对debug版本的程序进行调试,追踪程序运行过程,以便查找出程序的错误。
编译出的程序分为debug和release版本。
- release版本为程序的正式发行版本,程序在编译过程中一般会被编译器优化,因此release版本的程序运行效率更高、占用内存更小。
- debug版本为程序的调试版本,被开发者用来发现程序中的错误,为了保证程序中的语句不会被忽略,debug版本程序在编译中不会被编译器优化,并且会在程序中额外插入用来调试的代码和信息,因此该版本程序运行效率较低,占用内存更大。
gdb只能对debug版本的程序进行调试,gcc/g++中的-g选项可以编译出debug版本的程序。
gcc -g main.c -o a.out # 将main.c编译成debug版本的a.out程序gdb a.out # 调试a.out程序
q(quit):退出调试
(1)运行与逐语句
r(run):运行,有断点时运行到第一个断点处阻塞。n(next):逐过程运行,执行下一条语句,遇到调用函数时,不会跳转至函数内部。s(step):逐语句运行,执行下一条语句,可以进入函数(包括库函数)。c(continue):运行至下一个断点处。until [num]:跳转到第num行。finish:强制执行完当前函数,函数内部的断点会被跳过。Enter键可以自动记忆上一次操作,如点击s后,继续点击Enter就能继续逐语句运行程序。
(2)代码显示与追踪变量
l(list):显示代码。一次显示10行,继续往下显示只需要继续输入l即可。l [num]:显示第num行开始的代码,及往后10行。l [function]:显示函数名为function的代码,显示10行。l [file]:[num]和l [file]:[function]可分别指定源文件显示第num行或函数名为function的代码。
p [var](point):打印var变量的值。display [var]:追踪var变量的值,即每次停下都显示var变量的值。undisplay [id]:取消对编号为id的变量的追踪。(变量每次显示时都会显示编号)set [var]=[value]:修改变量var的值为value,可以在调试时为变量修改值。
(3)断点设置
-
b(breakpoint):设置断点。b [num]:在num行打断点。b [file]:[num]:在源文件file中第num行打断点。b [file]:[function]:在源文件file中,function函数内的第一行打断点。
-
info b:查看断点信息。- Num:断点编号。
- Type:断点类型。
- Disp:断点状态。
- Enb:断点是否可用。
- Address:断点地址。
- What:断点所在的行号。
- breakpoint already hit 1 time表示此断点被命中1次。
-
d(delete):删除断点。d [id]:删除编号为id的断点。(id为断点编号,可以用info b查看,此处不能是行号)d breakpoints:删除所有断点。
-
disable:禁用断点。disable b [id]:禁用编号为id的断点,被禁用后该断点不再生效。- disable b:禁用所有断点。
-
enable:启用断点。enable b [id]:重新启用编号为id的断点。enable b:启用所有断点。
调试实例:
gdb c.out # 调试c.out程序# 此处省略了gdb程序的相关信息# 从第0行显示main.cpp的代码
(gdb) l main.cpp:0
1 #include <iostream>
2 #include "head.h"
3
4 int main() {
5 std::cout << "Hello World" << std::endl; # 第5行将会设置断点
6
7 int a = 20, b = 30;
8 std::cout << add(a, b) << " " << sub(a, b) << std::endl; # 第8行将会设置断点
9 return 0;
10 }# 从第0行显示head.h的代码
(gdb) l head.h:0
1 int add(int a, int b) {
2 return a + b;
3 }
4
5 int sub(int a, int b) {
6 return a - b;
7 }# 设置一个断点在main.cpp第5行
(gdb) b main.cpp:5
Breakpoint 1 at 0x400850: file main.cpp, line 5.
# 设置一个断点在main.cpp第8行
(gdb) b main.cpp:8
Breakpoint 2 at 0x40087a: file main.cpp, line 8.
# 查看所有断点
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400850 in main() at main.cpp:5
2 breakpoint keep y 0x000000000040087a in main() at main.cpp:8# 开始运行
(gdb) r
Starting program: /home/wss/cppTest/c.out Breakpoint 1, main () at main.cpp:5
5 std::cout << "Hello World" << std::endl; # 执行到第一个断点处
Missing separate debuginfos, use: debuginfo-install glibc-2.17-326.el7_9.3.x86_64 libgcc-4.8.5-44.el7.x86_64 libstdc++-4.8.5-44.el7.x86_64
(gdb) n # 执行下一条语句
Hello World
7 int a = 20, b = 30;
(gdb) c # 执行到下一个断点处,即第8行断点
Continuing.Breakpoint 2, main () at main.cpp:8
8 std::cout << add(a, b) << " " << sub(a, b) << std::endl;
(gdb) s # 进入sub函数并执行下一条语句
sub (a=20, b=30) at head.h:6
6 return a - b;
(gdb) finish # finish直接执行完该函数
Run till exit from #0 sub (a=20, b=30) at head.h:6
0x0000000000400889 in main () at main.cpp:8
8 std::cout << add(a, b) << " " << sub(a, b) << std::endl;
Value returned is $1 = -10
(gdb) s # 进入add函数并执行下一条语句
add (a=20, b=30) at head.h:2
2 return a + b;
(gdb) finish # finish直接执行完该函数
Run till exit from #0 add (a=20, b=30) at head.h:2
0x000000000040089a in main () at main.cpp:8
8 std::cout << add(a, b) << " " << sub(a, b) << std::endl;
Value returned is $2 = 50
(gdb) n # 继续向下执行
50 -10
9 return 0;
(gdb) n
10 }
(gdb) n
0x00007ffff720f555 in __libc_start_main () from /lib64/libc.so.6
(gdb) n
Single stepping until exit from function __libc_start_main,
which has no line number information.
[Inferior 1 (process 13263) exited normally]
(gdb) q # 退出调试
4. Makefile自动化项目构建工具
4.1 make命令和Makefile文件
一个软件项目由可执行程序、文档、图片资源等组成,每种文件通常不止一个,这些文件之间相互配合完成了该项目提供的服务,如QQ、微信等聊天软件不仅要提供聊天程序的执行,还要保存联系人、聊天内容等资源,甚至提供其他服务(微信支付、小程序等),这些只凭借一个文件是难以完成的。
因此为了构建一个项目,需要编译多个程序、生成多个文件、其中会产生一系列错综复杂的关系,如a文件需要依靠b和c生成,c文件由需要凭借其他文件生成等,在面对文件极多的大型工程时,仅靠人力去梳理这些关系并完成文件的生成过程是不现实的。为了解决这个问题,专门引入了一个程序make来完成项目的构建工作,而make命令则是依靠Makefile文件中写入的文件生成过程来实现自动化构建。
- make:是一个命令,该命令会读取Makefile文件,按照里面的文件生成过程自动构建整个项目工程。
- Makefile:是一个文件,文件里根据特定的语法规则定制了项目的编译过程,可以用
make命令将这些编译过程一键执行,不需要再手动依次编译每个程序,极大简化了开发过程。
使用方法:
- 在代码存在的目录下创建一个
Makefile/makefile文件(首字母不区分大小写)。 - 在
Makefile文件中写好编译过程。 - 执行
make命令构建项目。
4.2 Makefile基本语法规则
(1)依赖关系与依赖方法
构建一个项目工程时,开发者写好的源文件、文档或其他文件等进行编译或其他操作,生成实现项目功能的可执行程序和其他文件等,在这个过程中可能会产生许多临时文件,也有一些难以梳理的复杂关系,但其中的每一个步骤都是将一些文件通过某些方法生成另一些文件,因此Makefile中的语法都是在描述 “一些文件以某种方法生成某些文件“的过程。
- 依赖关系:用于描述文件生成的关系:如a的生成需要b、c文件。
- 语法:
目标文件列表:依赖文件列表。 - 目标文件:最终生成的文件。
- 依赖文件:生成目标文件时所需要的文件。当文件有多个时用空格隔开,若不需要依赖文件可以不写。
- 语法:
- 依赖方法:是文件生成过程的具体指令,如源文件
a.c生成a.out程序的具体指令就是gcc -o a.out a.c。- 语法:
[commands],就是生成文件的命令,需要用tab保存缩进,且不能用4个空格缩进,依赖方法可以有多条,每条占一行。
- 语法:
- 注释:在Makefile文件中的使用
#符号行注释。
a.out:head.h main.c # 依赖关系,a.out文件靠head.h和main.c生成gcc head.h main.c -o a.out # 依赖方法,生成a.out的具体命令
(2)依赖关系的执行顺序
依赖关系的推导过程:
-
当出现多个依赖关系时,会从上往下依次执行。
-
当某个依赖关系中的依赖文件不存在时,会执行下一个依赖关系,看下一个依赖关系中的目标文件是否有上一个关系的依赖文件,若是还没有,则继续向下依次寻找,直到凑齐了刚刚的依赖关系需要的依赖文件,则会返回去执行,生成它的目标文件。
-
若是执行到最后都没有找到依赖关系所缺失的依赖文件,则会报错。
因此依赖关系的执行次序是一个栈结构,会依次向下推导所需要依赖文件,找到后回来再执行依赖方法。
以下是将a.h、a.c、b.h、b.c、main.c按照预处理、编译、汇编、链接形成一个可执行程序a.out的过程:
main函数在main.c文件中,其中引用了a.h和b.h头文件。a.h和b.h中分别是a.c和b.c中函数函数体的声明。以下注释中的顺序(1)、(2)、(3)…标注了实际执行顺序
# 最终目的是编译出a.out可执行程序
a.out:main.o a.o b.o # (1)main.o和a.o和b.o不存在,向下寻找。(17)生成a.out,执行完毕gcc -o a.out a.o b.o main.o# 生成a.o文件的过程
a.o:a.s # (2)a.s不存在,向下寻找。(6)生成a.o,集齐一个gcc -c a.s -o a.o
a.s:a.i # (3)a.i不存在。(5)生成a.sgcc -S a.i -o a.s
a.i:a.c # (4)a.c存在,生成a.i,向上回溯。gcc -E a.c -o a.i# 生成b.o的过程
b.o:b.s # (7)b.s不存在。(11)生成b.o,集齐2个gcc -c b.s -o b.o
b.s:b.i # (8)b.i不存在。(10)生成b.sgcc -S b.i -o b.s
b.i:b.c # (9)b.c存在,生成b.i,向上回溯。gcc -E b.c -o b.i# main
main.o:main.s # (12)main.s不存在。(16)生成main.o,全部集齐,向上回溯。gcc -c main.s -o main.o
main.s:main.i # (13)main.i不存在。(15)生成main.sgcc -S main.i -o main.s
main.i:main.c a.h b.h # (14)main.c、a.h和b.h存在,生成main.i,向上回溯。gcc -E main.c a.h b.h -o main.i
make 目标文件:
make指令只会默认生成第一个目标文件,只有第一个目标文件没有生成时才会向下推导并执行当,它被生成后不会在往下继续执行。- 若要生成
Makefile中除了第一个以外的目标文件,可以用make指令指定目标文件名生成,如make file_4(执行目标文件为file_4的依赖方法)。 - 若要生成多个文件,可以将第一个目标文件设为
all,将被生成的多个文件作为all的依赖文件。最终不会生成一个名为all的文件,因为依赖方法中没有生成all文件的语句。(若是当前目录中存在all这个文件,则可能不被执行,本文下面.PHONY关键字处会解释)
all:file_1 file_2 file_3 # make:只生成3个文件
# 以下分别是make指令生成3个文件的依赖关系和依赖方法
file_1:touch file_1
file_2:touch file_2
file_3:touch file_3# make指令生成3个文件后,不会执行后面的语句了
file_4: # make file_4:指定该依赖方法的执行touch file_4
注意:若是目标文件没有依赖文件,即使没有生成目标文件也不会继续往下推导执行,因为推导过程是在后面的目标文件里找它的依赖文件,而它没有依赖文件可以被推导。
file_1:touch file # 执行到此戛然而止,没有依赖文件被推导。
file_2:touch file_2
(3)clean与.PHONY关键字
当已经生成了目标文件,再次执行make时,只有依赖文件发生过变化的目标文件才会被更新。这是为了防止重复编译。(大型软件的编译过程非常耗时,重复编译会浪费更多时间,判断文件是否修改的依据是文件的mtime有没有变化)
若是想让没有修改过的文件也更新,则可以把目标文件删掉,让make重新生成。但是一个个删除非常费劲,可以定义一个clean目标文件,将依赖方法写成删除文件的语句,执行make clean命令就能自动删除目标文件,也不会生成clean文件。
clean:rm -f a.out # make clean执行该语句删除a.out,且没有生成clean文件
若是当前目录下恰好有一个文件叫做clean,当执行make clean时,会把clean文件当成目标文件,检查它是否被修改过,若没有被修改过时,则不会执行它的依赖方法,无法做到删除其他目标文件。此时便引入了关键字.PHONY
.PHONY:目标文件:将目标文件设为伪目标,伪目标不被视为文件,而是当成一种命令,当前目录中存在同名文件时,不会检查文件是否需要更新,而是直接执行它的依赖方法。
.PHONY:clean # 将clean设为伪目标
clean: # make clean会直接执行依赖方法,不管clean文件是否需要更新rm -f a.out
一般all也会被设置为伪目标,防止all文件的存在影响多个依赖文件的依赖方法执行。
.PHONY:all # 将all设为伪目标
all:file_1 file_2 file_3
... ... # 此处省略n个字
(4)变量
在Makefile中可以定义变量,变量可以简化重复的命令。
- 定义变量:
VAR = value。为了方便区分变量名和值,通常情况下会将变量名大写,值小写。 - 获取变量值:
$(VAR)。当变量名只有一个字符时可以省略(),如$A。 - 获取变量值可以是任意字符串,获取变量时会直接将值原封不动地展开。
CC = gcc # 定义变量
# 下面故意带上选项-o和空格,且a.out漏掉一个t(为了演示获取值是原样展开,实际别这么写)
OP_OBJ = -o a.oua.out:main.c# 在$(OP_IBJ)后手动补一个t,会发现变量展开后它们拼接在一起,变成-o a.out$(CC) $(OP_OBJ)t main.c # gcc -o a.out main.c可以成功执行
常用的内置变量:
$@:依赖关系中的目标文件。$^:依赖关系中的所有依赖文件。$<:第一个依赖文件。
a.out:main.c head.hgcc -o $@ $^ # gcc -o a.out main.c head.h
变量定义与获取顺序(了解):
- 在使用
$获取变量之前,Makefile会先将所有的变量先赋值,再进行获取变量值的操作。即使$获取变量值在定义变量之前,也不会出错。 - 若是一个变量有多条定义语句,则会以最后一条语句为准。
- 因此
=的作用更像是变量定义,而非变量赋值,变量的定义被优先执行。
A = $(B) # A=b,依然可以获取到B的值
B = bC = c # C重复定义,它的值是最后一条语句决定,为d
D = $(c) # D的值为d,C不等于c
C = d# 以上代码执行顺序为:
# 1.先获取变量值:B=b C=d
# 2.再$获取变量值:A=b D=d
变量赋值与顺序(了解):
:=冒号和等号才是真正意义上的赋值,VAR := value是对变量赋值,受从上到下的顺序影响。
A := $(B) # A的值为b,B的值来源于定义,即最后一条语句
B := c # B的当前值被修改为c
A := $(B) # A的值为cA = a
B = b
变量的定义和赋值顺序了解一下即可,非常不建议将定义写在赋值和获取值的后面,会造成极大的阅读障碍。
二、动静态库
1. 函数库的概念
(1)函数库的概念
多人合作完成一个项目时会考虑一个问题:如何把自己写好的代码让别人使用?
最简单的方法就是将写好的源文件和头文件给使用者发送过去,使用者将这些文件和自己的源代码编译链接形成一个可执行文件。这样做会有几个缺点:
- 我们写的源代码会直接被使用者看到,导致我们的源码泄漏。
- 使用者需要对我们的源文件进行编译,会消耗一定的时间。
- 若是源文件数量很多,文件的传输和编译就会非常不方便,也容易遗漏文件。
我们可以将源文件(.c)编译成二进制目标文件(.o)提供给使用者,使用者通过目标文件就可以链接我们写好的代码生成可执行文件。但是这样只能解决前两个问题,第三个问题仍然无法解决,因此我们要将这些目标文件(.o)打成一个包,给对方提供一个打包好的文件即可。
函数库:就是将这些编译好的目标文件打包成的一个文件,简称库。库的本质就是目标文件(.o)的集合。
虽然目标文件被打包成了一个函数库,但我们无法看到它们里面都有什么函数,因此使用库函数时,必须搭配对应的头文件,头文件中是函数的声明。在源代码中引用头文件就能使用该函数库了。
(2)函数库的分类
按是否被官方收录分类:
- 标准库:一些函数由于频繁被使用,每种编程语言的官方机构就会将它们打包称为一个通用的库,被称为标准库,标准库是每种编程语言几乎默认自带的函数库,可以直接使用。常见的有C语言的C标准库、C++的stl库等
- 第三方库:还有一部分函数库没有被官方机构收录,这种函数库称为第三方库,通常情况下需要在对应的网站下载下来使用。
按函数库的链接方式分类:
程序使用了函数库后,函数库中被引用的代码就会写入可执行程序中,但是想C标准库这种函数库几乎被每个程序引用,若是每个程序都要将C标准库中的部分代码复制到程序中,程序所占用的内存就会极大,若是让多个程序共享使用这个C标准库,就能节省很多空间。因此根据是否共享函数库里的代码,将函数库的链接方式分为了静态链接和动态链接,函数库也被分为了静态库和动态库。
- 静态链接:链接生成可执行程序时,会将函数库中被引用的函数全部复制到程序中,用于静态链接的函数库叫静态库。
- 动态链接:在链接时只会将被引用的函数"地址"复制到程序中,在程序"运行"时才链接到动态库并执行函数,用于动态链接的叫动态库,也叫共享库。
关于函数库的其他问题:
- 函数库中是已经编译好的目标文件,里面是可以执行的二进制指令,因此只要被引用是可以直接执行的,不需要额外编译。链接只是将这些可以执行的指令打包到一起,形成一个程序。
- 动态库虽然被共享,但不存在多个程序同时争抢使用的现象,函数库只会被读取,可以被同时使用。
- Linux下默认生成的可执行文件是动态链接,使用动态库。并且大多数指令都是动态链接,不能随便将动态库删除。因此几乎所有操作系统会自带动态库。当机子中没有安装静态库时可以使用
yum intall glibc-static指令安装。
动静态链接的优缺点:
- 静态链接:
- 优点:程序后续不受函数库的影响,已经复制了函数的具体实现。
- 缺点:程序占用内存大,影响存储和传输。
- 静态链接:
- 优点:程序占用内存小,方便存储和传输。
- 缺点:程序后续容易受函数库的影响,如函数库升级、删除等。
(3)函数库的命名
Linux下函数库的命名:前缀lib + 函数库名 + 后缀.so 或 .a。
- 静态库:
libxxx.a,(xxx是函数库的名字) - 动态库:
libxxx.so,(如C标准库/lib64/libc.so.6,c是名字,6是它的版本)
Windows下的函数库命名:函数库名 + 后缀.dll 或 .lib。
- 静态库:
xxxx.lib。 - 动态库:
xxxx.dll。
2. 动静态库的操作
(1)查看程序的链接方式
file:查看文件类型,可以查看可执行程序是动态链接还是静态链接。
- 显示信息中含有
dynamically linked就是动态链接。 - 显示信息中含有
statically linked就是静态链接。
file a.out # 查看a.out的链接方式
# 显示信息中有dynamically linked,是动态链接
a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=d43c500e99eabd2e0e7f22df87e06518e805fd6b, not stripped
(2)创建静态库
ar:将目标文件打包成静态库。
ar [-op] [libxxx.a] [objects.o]ar -c libtest.a # 将obj_1.o和obj_2.o打包成libtest.a
ar -rc libtest.a obj_1.o obj_2.o # 创建静态库libtest.a并添加obj_1.o和obj_2.o
ar -d libtest.a obj_1.o # 从静态库libtest.a中删除obj_1.o
ar -x libtest.a obj_1.o # 从静态库libtest.a中提取出obj_1.o
ar -t libtest.a # 显示libtest.a中的目标文件列表
-c:创建静态库。-r:往静态库中添加目标文件。若静态库中目标文件有更新,则替换旧文件。-d:删除静态库中的目标文件。-x:从静态库中提取目标文件,若是不指定目标文件名则全部提取出来。-t:显示静态库中的目标文件列表。-v:显示详细过程。
(3)创建动态库
动态库每次被加载到内存中的地址通常不固定(由操作系统决定),为了避免动态库地址经常变化导致程序无法链接到动态库,需要在编译目标文件时生成与位置无关的代码(即代码在内存中的任何位置都能被找到),gcc/g++编译器提供了-fPIC选项可以生成与位置无关的代码。
gcc -c -fPIC [source.c] -o [object.o]gcc -c -fPIC source.c -o object.o # 将source.c编译成与位置无关的目标文件object.o
静态库不需要生成与位置无关的代码,因为函数实现全部被复制到程序里了,运行时不用找静态库的代码了。
gcc中的-shared选项可以创建动态库。
gcc -shared [objects.o] -o [libxxx.so]gcc -shared obj_1.o obj_2.o -o libtest.so # 将obj_1.o和obj_2.o打包成libtest.so动态库
(4)使用函数库
使用函数库链接程序时,需要用到函数库及对应头文件的地址。
gcc/g++中提供了选项可以选择函数库:
-I [path]:头文件所在目录的地址。-L [path]:函数库所在目录的地址。-lxx:指定函数库名称,xx是函数库的名字,要去掉lib和后缀,如libc.so则是-lc。-static:强制使用静态链接生成程序。gcc/g++默认情况下优先使用动态库,若是没有动态库则使用静态库。
gcc -o a.out main.c -I . -L . -labc # 链接库abc,头文件和函数库都在当前目录
gcc -static -o a.out main.c -I . -L . -labc # 链接静态库libabc.a,头文件和库在当前目录
以下情况可以不指定头文件或函数库的地址编译或运行程序:
-
放在系统目录下:可以在链接时不显示指定路径,但依然要指定库名称,如
-labc,程序运行时会自动找到函数库。- 头文件(或头文件的软、硬链接)放在当前目录或
/usr/include目录。 - 函数库(或库文件的软、硬链接)放在
/lib64目录下(这个行为也就是软件的安装)。
- 头文件(或头文件的软、硬链接)放在当前目录或
-
配置环境变量:
-
C语言头文件的目录地址添加到环境变量
C_INCLUDE_PATH,C++头文件的目录地址添加到环境变量CPLUS_INCLUDE_PATH。 -
函数库的目录地址添加到环境变量
LIBRARY_PATH,可以在链接时不显示指定函数库路径,但依然要指定库名称。 -
函数库的目录地址添加到环境变量
LD_LIBRARY_PATH,可以让程序在运行时找到函数库。
export C_INCLUDE_PATH=$C_INCLUDE_PATH:[c_head_path] # 添加C语言头文件地址 export LIBRARY_PATH=$LIBRARY_PATH:[path] # 编译时用的库文件地址 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:[path] # 运行时用的库文件地址以上是临时添加环境变量的命令,重新打开
shell时会重置,若永久添加则要修改配置文件,这部分内容在《环境变量》部分。 -
-
添加
.conf配置文件:只能让程序在运行时找到动态库,gcc/g++链接还需要指定地址。-
/etc/ld.so.conf.d/目录下的.conf后缀文件是系统用来搜索动态库路径的文件,里面存储着动态库路径。 -
创建一个
libxxx.conf(xxx为库名),然后将该文件放入/etc/ld.so.conf.d/目录下(sudo)。 -
执行
ldconfig命令更新系统的配置文件(sudo)。
touch libxxx.conf # 创建libxxx.conf文件 vim libxxx.conf # 用vim(或者其他方法)写入动态库地址 sudo mv ./libxxx.conf /etc/ld.so.conf.d/ # 将文件移动到系统目录下 sudo ldconfig # 更新配置文件 -
三、git版本控制器
1. git的介绍
git:是一个管理代码的软件,通常一个项目代码量巨大且有些需要多人合作完成,大量的代码不方便每个人阅读,最后编译链接时将代码进行合并也是颇为麻烦,git软件的出现就是为了解决这个问题。git会将一个项目的代码组织起来,显示每个人提交的代码以及改动信息,方便每个人的阅读,极大程度上节省了代码的管理成本和合作成本。由于像git这类软件会将每个版本的代码记录并管理,因此这一类型的软件也叫版本控制器。
git是一个免费的版本控制软件,用来存储和管理我们的代码。常见的版本控制器还有svn等。
git的发展历史(了解)
- 在2002年以前,世界各地的志愿者把源代码文件通过diff的方式发给Linus,然后由Linus本人通过手工方式合并代码。Linus坚定地反对CVS和SVN等版本控制器,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比CVS、SVN好用,但那是付费的,和Linux的开源精神不符。
- 到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。
- Linux社区中各路大神聚集,有一些程序员按耐不住躁动的心理,试图破解BitKeeper的协议,被BitMover公司发现,于是BitMover公司勃然大怒,收回了Linux社区的免费使用权
- Linus不堪重负用手工合并代码,于是花了两周时间用C写了一个分布式版本控制系统,取名为git,并也将其开源了。然后git的开源代码经过各路大神的疯狂迭代,诞生了第一版本的git。之后将Linux源码放在git上托管。
- 一些程序员和商人发现商机,自建了网站,供世界各地的程序员托管代码,这个网站便是GitHub。
- 由于GitHub的服务器相对于国内太远,导致访问的速度太慢,经常出现一些问题,于是出现了国内的git代码托管网站gitee。这也是我们所使用的git代码托管网站
2. gitee的使用
gitee:是一个远程托管代码的网站,我们会将代码上传到该网站进行管理。
gitee的使用方法:
- 创建远端仓库:
- 远端仓库是gitee网站提供的存储并管理代码的地方,相当于一个云盘,我们把代码存储到云盘,以后即使是换设备了或是多个不同的设备也可以将云盘里的代码下载下来使用或提交。我们要先在gitee上注册一个账号,并创建一个远端仓库。
- 远端仓库下载到本地:
- 下载后我们在服务器上就拥有了一个本地仓库。我们对代码的操作都是在本地仓库上进行的,将编写代码并提交到本地仓库。
- 本地仓库同步到远端:
- 也就是把本地仓库的内容上传到gitee里的远端仓库,保证远端仓库与本地仓库内容的一致性。
(1)注册账号并创建远端仓库
- 在gitee官网注册账号,跟着官网提示即可,需要进行邮箱校验。
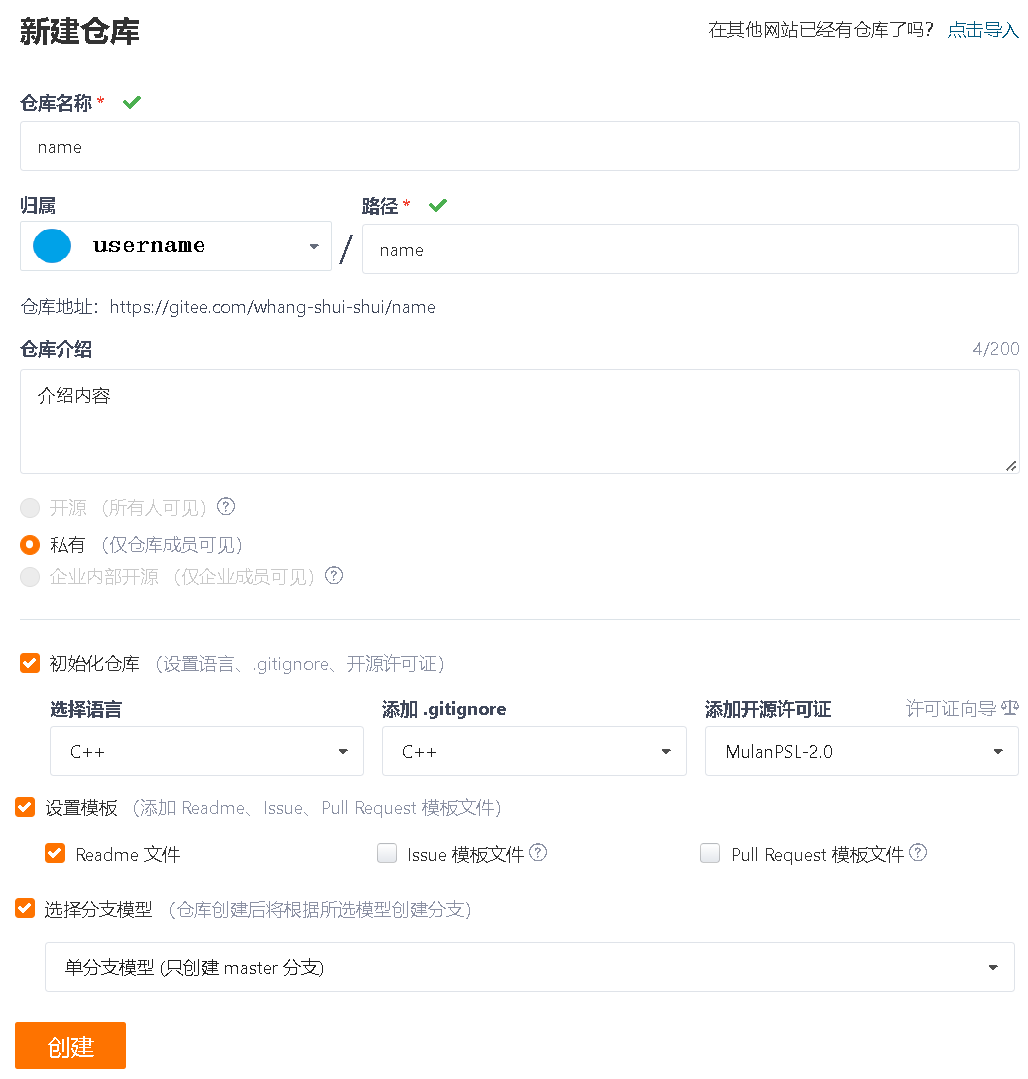
- 登录成功后,进入点击
+,选择新建仓库,并按照自己需求填好信息就可以创建仓库了

- 然后点击仓库可以将其设置成开源的(git仓库:就是一个目录,我们的代码都会上传到该目录)
安装git:在服务器上安装git。
sudo yum install -y git
设置用户名和邮箱:
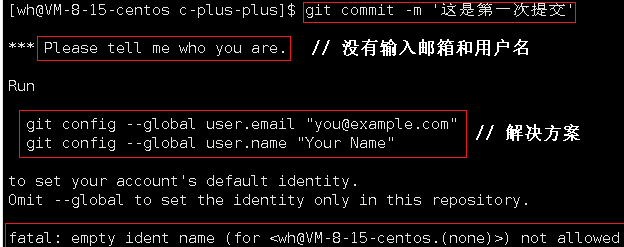
- 首次使用
git时,会提示你输入邮箱和用户名,为了方便后续查看你代码的同志联系你 - 没有设置邮箱和用户名时,你提交代码会失败,因为
git不知道是谁提交的代码。解决方法是用以下指令设置用户名和邮箱
git config user.email "邮箱" # 设置邮箱
git config user.name "用户名" # 设置用户名
3. gitee提交当天会显示一个小绿方块,小绿点颜色深浅只与当日提交次数有关,与提交的代码量无关,无需太过关注
(2)下载项目到本地
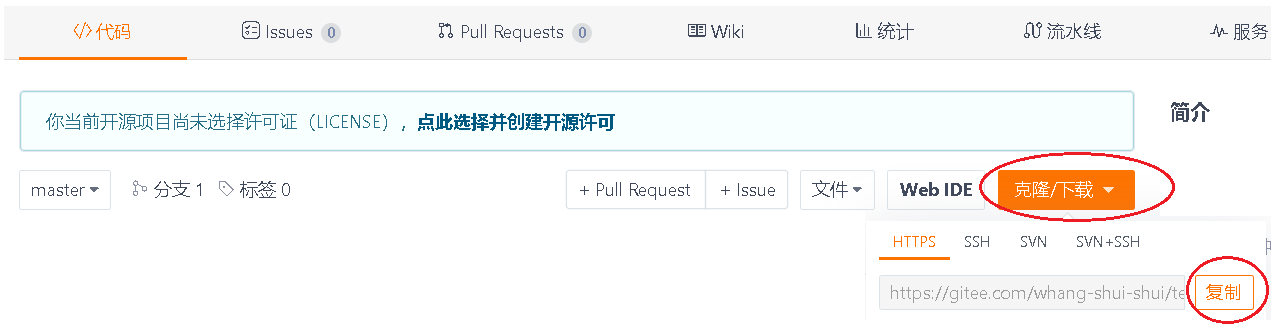
- 获取远端仓库的网址:在gitee网站上,打开自己所建立的仓库,点击【克隆/下载】,复制其网址。
- 下载项目到本地:在Linux服务器上进入自己将要下载项目的目录。使用
git clone 网址命令下载远端仓库,输入自己的gitee账号和密码即可完成。
git clone [网址]
将远端仓库同步到本地:若是已有本地仓库,可以将远端仓库内容同步到本地仓库。
git pull
- 下载好后我们发现该目录下出现了一个文件夹,进入该文件夹中有3个文件和一个隐藏文件
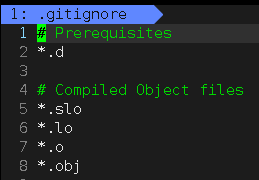
LICENSE:开源许可证README.md:说明文档,用来介绍你的仓库README.en.md:英文说明文档.gitignore:该文件内容是各种文件的后缀,出现在该文件中的文件类型都会被忽略上传
(3)本地仓库的代码操作
- 添加新增的文件到git本地仓库
git add [files] # 添加新增文件到git本地仓库
- 删除文件
git rm [files] # 删除本地仓库的files文件
- 重命名或移动文件
与mv一样,第二个参数是目录则是移动,是文件就是重命名。
git mv [file] [path] # 移动file到path目录
git mv [file] [file_new] # 将file文件重命名为file_new
- 提交改动到本地仓库
git commit . # 提交改动到本地仓库
- commit提交时可以使用
-m选项添加提交日志- 提交日志是解释这次提交对代码进行了哪些修改等。
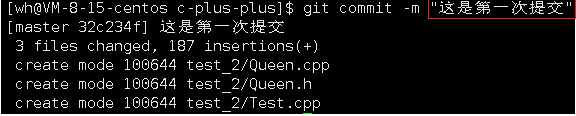
- 查看提交日志:
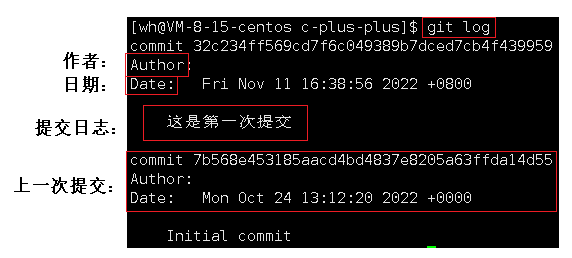
git log
git log
- 查看上次提交之后是否有对文件进行再次修改
git status
(4)代码上传到远端
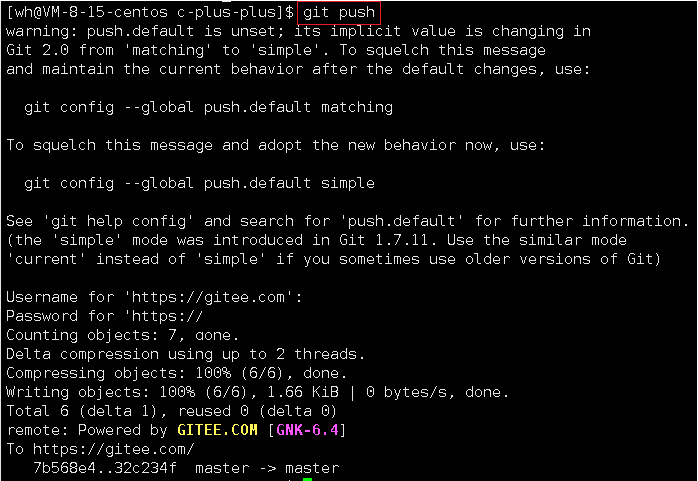
- 提交内容到远端仓库:
git push,然后输入用户名和密码即可完成提交(push的本质就是同步本地仓库内容到远端)
git push可以设置免密码提交,但是不推荐
通常我们写完后,提交代码到本地仓库并同步到远端步骤,可以直接简单打一套丝滑小连招:
git add . # 添加当前目录下的所有文件到本地仓库
git commit -m '第一次提交' # 提交改动和日志“这是第一次提交”到本地仓库
git push # 同步本地仓库的内容和远端仓库的内容
- 然后我们的代码就提交到gitee网站远端了
