深入浅出MyBatis缓存:如何让数据库交互飞起来
深入浅出MyBatis缓存:如何让数据库交互飞起来
你是否遇到过这样的场景:系统在高并发下响应缓慢,数据库监控显示CPU飙升,日志里充斥着大量重复SQL?作为开发者,我曾亲眼目睹一个简单的配置查询拖垮整个系统。今天我们就来聊聊MyBatis如何通过缓存机制解决这类性能痛点。
一、为什么需要缓存?
想象一下图书馆管理员的工作场景:
- 每次有人问《三体》的位置都要跑库房查找(数据库查询)
- 相同问题每天被问几十次(重复SQL)
- 馆藏更新时需要重新查找(数据变更)
缓存的核心价值就是避免这种重复劳动。当MyBatis执行查询时:
// 第一次查询:访问数据库
User user1 = sqlSession.selectOne("getUserById", 1); // 第二次查询:直接从内存返回结果
User user2 = sqlSession.selectOne("getUserById", 1);
通过减少80%以上的数据库交互,我们的应用吞吐量可提升3-5倍,这在电商大促、秒杀场景中尤为关键。
二、MyBatis两级缓存解密
1. 一级缓存:会话级"便签本"
- 特性速览:
- 默认开启且不可关闭
- 作用域:单个SqlSession内
- 生命周期:随会话创建而建,随会话关闭而亡
工作流程:
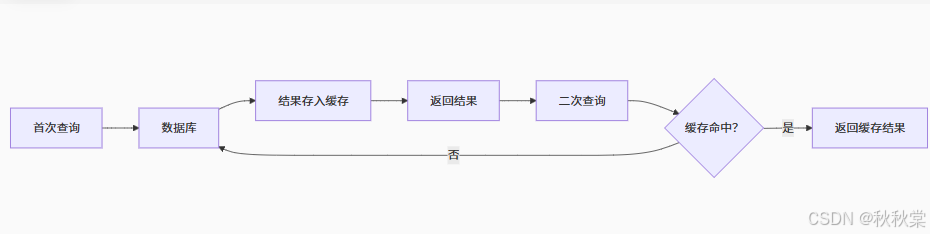
注意事项:
// 示例:写操作清空缓存
sqlSession.selectOne("getUserById", 1); // 缓存生效
sqlSession.update("updateUser", user); // 清空缓存!
sqlSession.selectOne("getUserById", 1); // 重新查询数据库
2. 二级缓存:共享"图书馆"
- 核心优势:跨会话共享数据
- 启用步骤:
<!-- mybatis-config.xml --> <settings><setting name="cacheEnabled" value="true"/> </settings><!-- UserMapper.xml --> <mapper namespace="com.example.UserMapper"><cache/> <!-- 关键!启用二级缓存 --> </mapper>
数据流转机制:
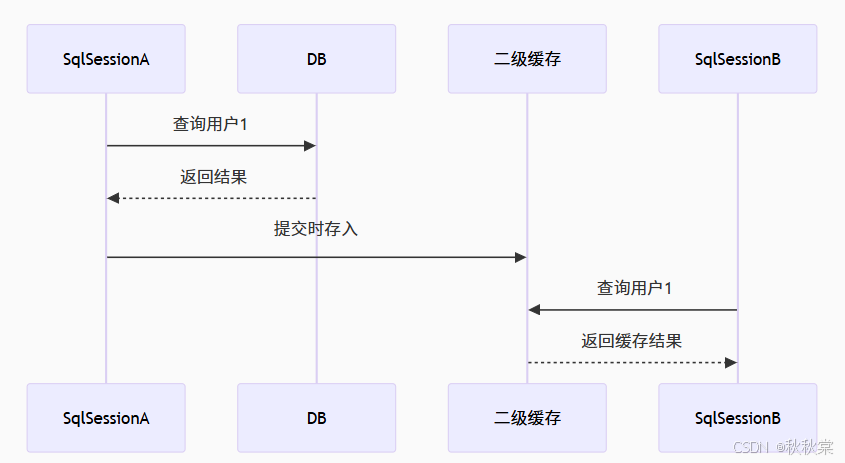
避坑指南:
- 缓存对象必须实现
Serializablepublic class User implements Serializable {// 必须实现序列化接口 } - 更新操作自动清空缓存
- 分布式环境需集成Redis等方案
三、缓存 vs 延迟加载:黄金搭档
| 特性 | 延迟加载 | 缓存机制 | 协作效果 |
|---|---|---|---|
| 解决痛点 | N+1查询问题 | 重复查询问题 | 既避免冗余查询又减少重复IO |
| 作用范围 | 对象关联关系 | 查询结果集 | 完整优化查询链路 |
| 最佳场景 | 多表级联查询 | 高频单表查询 | 复杂业务场景全覆盖 |
协作示例:
// 开启延迟加载
<setting name="lazyLoadingEnabled" value="true"/>// 查询+缓存组合拳
User user = userMapper.getUserWithOrders(1);
// 首次访问订单触发延迟加载
List<Order> orders = user.getOrders();
// 二次访问直接读缓存
List<Order> cachedOrders = user.getOrders();
四、实战中的缓存策略
1. 选型决策树
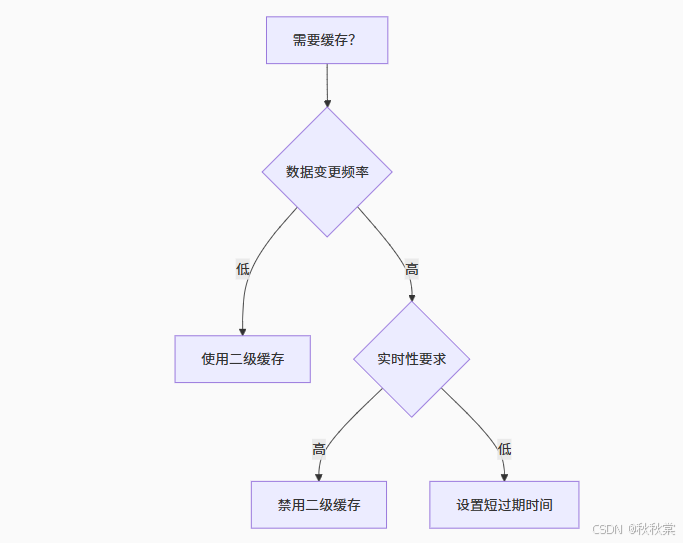
2. 性能优化组合拳
-
基础配置:
<!-- 推荐缓存设置 --> <cache eviction="LRU"flushInterval="60000"size="1024" readOnly="true"/> -
第三方缓存集成(Ehcache示例):
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
3. 避坑清单
- 缓存穿透:对空结果进行缓存
- 缓存雪崩:设置随机过期时间
- 脏读风险:金融系统慎用二级缓存
- 调试技巧:
DEBUG [main] - Cache Hit Ratio [com.example.UserMapper]: 0.5
五、最佳实践总结
-
一级缓存:信任但验证
- 注意在写操作后主动刷新数据
- 避免在长会话中积累过大缓存
-
二级缓存:精确制导武器
// 典型适用场景 @CacheNamespace // 注解方式启用 public interface ConfigMapper {@Select("SELECT * FROM sys_config")List<Config> getAll(); } -
黄金法则:
- 读多写少用缓存
- 关联查询开延迟
- 高频变更设短期
- 集群环境用Redis
在我的架构实践中,通过二级缓存+Redis的方案,某配置服务的QPS从1200提升至8500,数据库负载下降90%。记住:缓存不是银弹,而是精密的齿轮——只有与业务场景精准咬合,才能释放最大价值。