【C++详解】STL-stack、queue的模拟实现,容器适配器,deque双端队列介绍
文章目录
- 一、stack使用
- 二、stack容器适配器方式实现
- 三、queue的使用
- 四、queue容器适配器方式实现
- 五、数组结构/链式结构的优缺点
- 六、deque
- deque的结构
- deque迭代器
- deque总结
一、stack使用

栈在结构上是一种容器适配器,我们看它的第二个模板参数container,默认是从一个容器deque里获取数据,也就是它是复用其他容器适配转换出来的,至于复用的是什么容器由模板参数决定。区别于之前介绍的list、vector,它们的第二个模板参数都是从内存池里获取数据。
容器适配器底层是不支持迭代器的,所以也不支持范围for,(若支持迭代器随意遍历的话就和栈的后进先出的特点相违背)。
栈的使用非常简单,因为具体细节已经在数据结构初阶介绍过了,小编做了几个测试,代码如下:
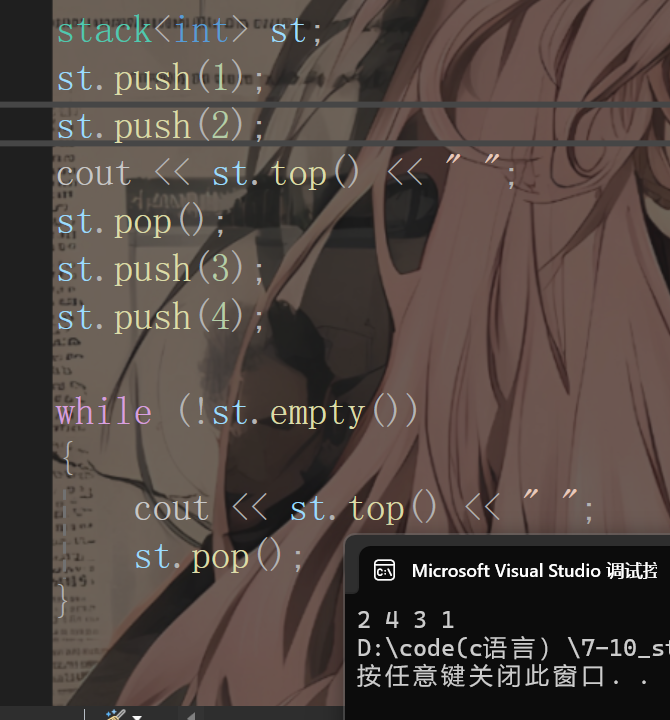
二、stack容器适配器方式实现
template<class T, class Container = vector<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}const T& top() const{return _con.back();}T& top(){return _con.back();}private:Container _con;};
库里面是用deque做的缺省值,我们对deque还不了解,所以先用vector来替代一下这里底层适配器用vector list 都可以,因为stack不用头插头删。
三、queue的使用

队列也是一种容器适配器,具体使用也不过多介绍了,测试如下:
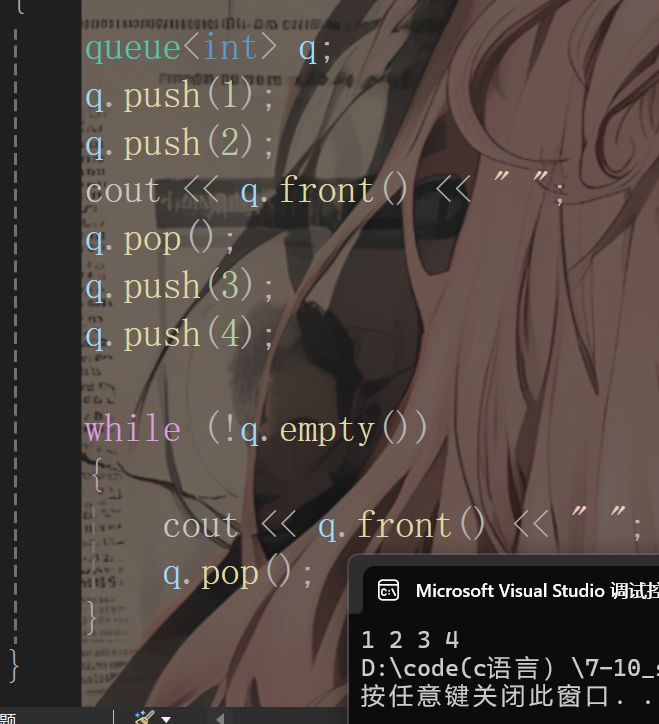
四、queue容器适配器方式实现
template<class T, class Container = list<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}const T& back() const{return _con.back();}T& back(){return _con.back();}const T& front() const{return _con.front();}T& front(){return _con.front();}private:Container _con;};
要注意queue只能用list做底层容器,因为vector的不支持头插头删,强行头插头删效率太低。
五、数组结构/链式结构的优缺点
在介绍deque之前我们先来总结一下数组结构与链式结构分别的优缺点,然后能对deque的设计有更深层次的理解。


数组和链表正好就是互补的关系,把各自的有优点都发挥到了极致,我们接下来来看deque是如何另辟蹊径的。
六、deque
deque是双端队列,虽然名字里有队列,但是它不保证数据先进先出。
我们知道vector不支持头插头删,list不支持下标的随机访问,而deque它既支持尾插尾删,头插头删,也支持下标的随机访问,那这意味着deque可以完全替代list和vector了吗?当然不是,这个世界是公平的,上帝给你开了一扇窗,必然会关掉你的一扇门,deque也是这样,它具有局限性,虽然它什么都能做,那么就注定了它做的每一项都不会极致。
deque的结构
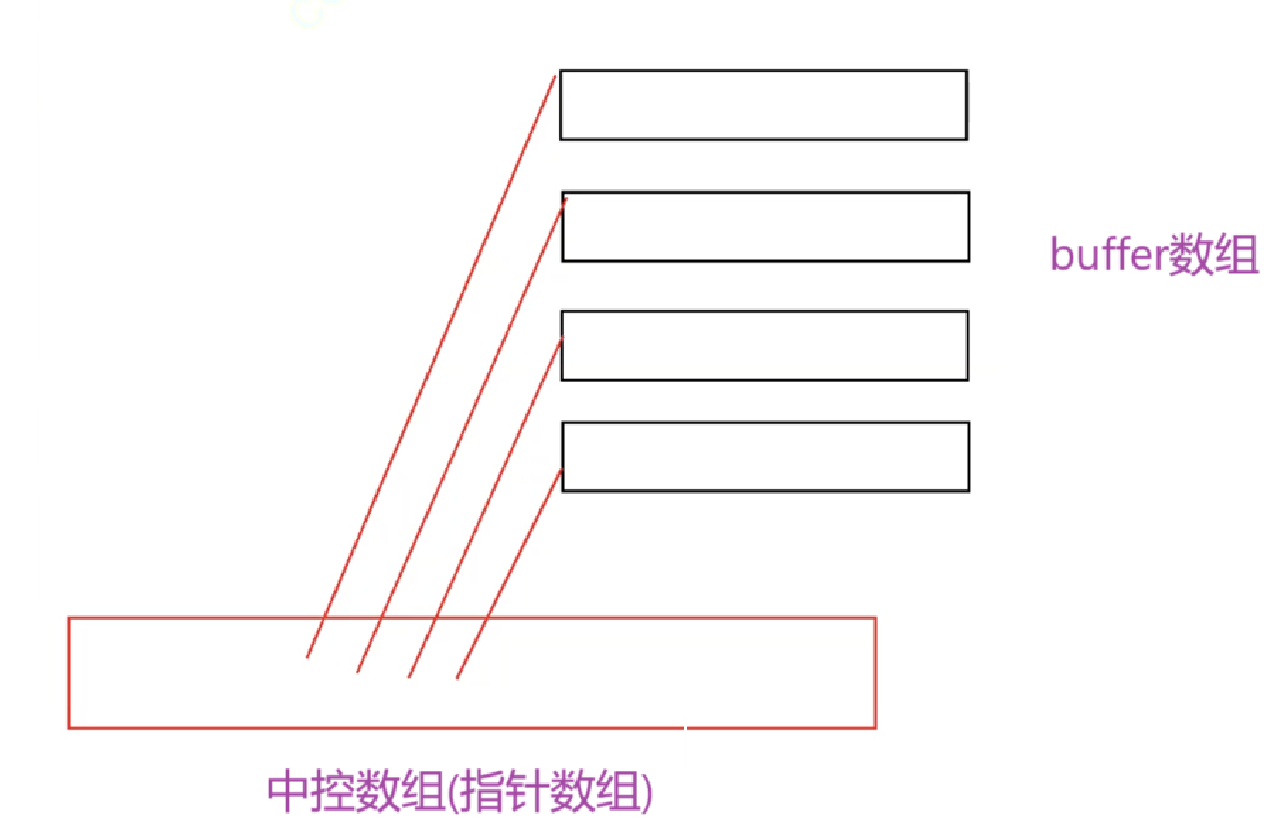
deque里有一个中控数组,还有许多buffer数组,中控数组里存的是buffer数组的指针。
中控数组满了也要扩容,但是deque相比于数组结构,它的扩容代价就要低一些,因为扩容时只用拷贝指针数据。因为中控数组的连续存储的所以也支持下标的随机访问,并且每一个buffer数组也是连续的,所以缓存命中率也有保证。而且空间不够了也只开辟一个buffer数组,不像数组一样倍数扩容,所以不会造成很严重的空间浪费。乍一看好像很哇塞,但是事实真是如此吗?想知道答案跟着小编来继续学习吧。
deque迭代器
deque的迭代器是和它的结构融合在一起的,它的遍历与插入删除操作都要依赖它的迭代器。
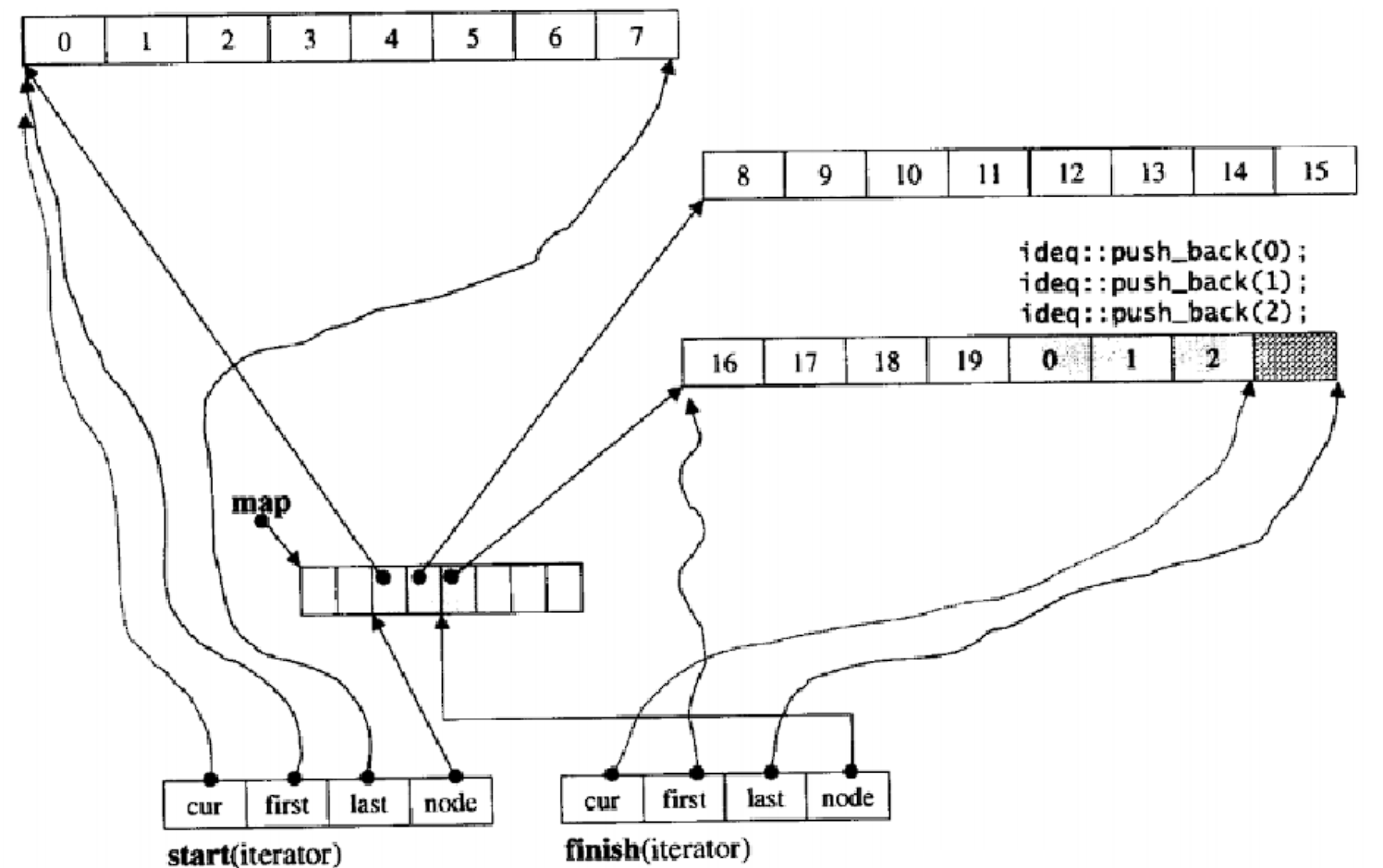
结构: 首先它有两个迭代器:start和finish,每个迭代器有四个指针,cur是最重要的,它指向的是当前迭代器访问到了哪个位置,另外三个指针都是为了维护它而创造的,first指向当前迭代器访问的数据所在的buffer数组的第一个数据,last指向的buffer数组的最后一个数据的下一个位置,node指向当前buffer数组在中控数组的位置,是二级指针。(中控数组里的数据是指针)
所以迭代器解引用返回的是cur指向的数据,迭代器++ 就是cur++,当把一个buffer遍历完后再cur++就不同了,另外三个指针也要改变,首先node++,把node的值给first,last为first加一个buffer的数据个数,这样就从下一个buffer的第一数据开始继续遍历了。迭代器比较相等本质是比较cur的值是否相等。
尾插/尾删:若finish的cur指向数据所在的buffer数组没满,直接尾插,若满了需要到下一个buffer里插入,deue尾插的效率比vector和list都高,因为它扩容不用拷贝旧数据,也不用mallic结点。尾删很好实现,小编就不浪费时间了。
头插/头删:如果要头插一定需要开一个buffer数组,因为第一个数据一定在buffer数组的第一个位置,这里也解释了为什么我们不从中控数组的开头开始放数据,如果从开头放的话头插不仅要开buffer数组,还要对中控数组扩容。头插要从新开buffer的尾开始,从后往前插,因为deque也是一种线性表,这样数据的逻辑结构才是连续的。
下标访问:我们要访问数据要找到它在第几个buffer和在这个buffer的第几个位置,用/和%就可以计算,比如我们要访问第12个,若每个buffer有8个数据,那么12/8为1代表在第一个buffer,12%8为4代表在第一个buffer的第四个位置。而这里可能会出现一种情况,当第一个buffer数组不满时,也就是我们头插了数据但是没有把第一个buffer数组插满,这是需要把第一个buffer数组补满再计算,比如我们还是访问第12个,而第一个buffer数组插入了两个数据,这是需要12 + (cur - first) 也就是 12 + 6为18,以18来作为/和%的数据。总的来看deque的下标访问由于需要/ %计算,效率会比vector低,但是还是比list高多了。

deque总结
1、适合头尾插入删除,效率很高。
2、下标随机访问效率也不错,但是处理大量数据效率略低于vector。
3、中间位置插入删除效率低,需大量挪动数据,和vector差不多。
4、相比vector(下标随机访问效率高)和list(任意位置插入删除效率高),它的优点都不够极致,但是他在头尾的插入删除效率上做到了极致(vector要扩容拷贝数据,list要频繁申请结点),所以它非常适合作为栈和队列的默认适配容器。
在实际工作中,vector 和 list 交替使用就足以解应付绝大部分场景了,若遇到频繁插入删除和少量下标访问可以用deque。
以上就是小编分享的全部内容了,如果觉得不错还请留下免费的关注和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
