redis速记
1.什么是缓存穿透?怎么解决?
答:缓存穿透是指用户请求的数据在缓存(如 Redis)和数据库(如 MySQL)中都不存在,导致每次请求都必须绕过缓存直接查询数据库,最终大量无效请求集中冲击数据库的现象。
其核心问题在于:缓存的 “拦截” 作用失效(因为缓存中没有该数据),而数据库也无法返回有效结果,导致所有请求都直接打到数据库,可能引发数据库过载、响应延迟甚至宕机。
解决方案:针对缓存穿透的核心矛盾(“缓存和数据库都无数据,导致请求直达数据库”),解决方案的本质是在请求到达数据库前,提前拦截无效请求,或减少无效请求对数据库的直接冲击。
1. 布隆过滤器(Bloom Filter):提前拦截 “绝对不存在” 的请求
原理:
布隆过滤器是一种空间效率极高的概率性数据结构,它可以提前将数据库中 “已存在的所有有效 key”(如所有合法的用户 ID、商品 ID)存入其中。当有新请求来时,先通过布隆过滤器判断该 key 是否 “可能存在”:
- 若布隆过滤器判断 “不存在”,则直接返回空结果(无需查询缓存和数据库);
- 若判断 “可能存在”,再继续查询缓存和数据库(因为布隆过滤器有极小的误判率,即 “不存在的 key 可能被误判为存在”)。
优势:
- 内存占用小(相比缓存全量 key),查询速度快(O (1)),适合拦截大量无效请求;
- 能从源头过滤掉 “绝对不存在” 的 key,大幅减少数据库压力。
注意点:
- 存在误判率(可通过调整哈希函数数量和位数组大小降低,但无法完全消除),可能导致少量不存在的 key 被误判为 “可能存在”,仍需查询数据库;
- 数据更新时需同步更新布隆过滤器(如新增数据时添加 key,删除数据时需谨慎,因为布隆过滤器不支持高效删除)。
2. 缓存空值(Null Value):避免重复查询不存在的数据
原理:
当数据库查询结果为 “空”(即数据不存在)时,不直接返回空结果,而是将这个 “空值” 作为缓存值存入缓存,并设置一个较短的过期时间(如 1-5 分钟)。后续相同的请求会直接从缓存获取 “空值”,无需再查询数据库。
优势:
- 实现简单,无需额外组件,能快速拦截重复的无效请求;
- 适合应对短期集中的无效请求(如用户输入错误参数的场景)。
注意点:
- 需设置合理的过期时间:时间过长会导致缓存中积累大量空值,浪费内存;时间过短则无法有效拦截重复请求;
- 可能被恶意攻击利用(如伪造大量不同的不存在 key,导致缓存中存入大量空值,占用内存),需配合其他策略(如限流)使用。
3. 业务层校验与过滤:从源头减少无效请求
原理:
在请求到达缓存或数据库前,通过业务逻辑对请求参数进行合法性校验,直接过滤掉明显无效的请求。
常见手段:
- 参数格式校验:比如用户 ID 必须为正整数,过滤负数、字符串等非法格式;
- 范围校验:比如商品 ID 的有效范围是 1-100 万,直接拦截超出范围的请求;
- 白名单机制:对于核心业务(如支付、用户信息),仅允许白名单内的 key 通过查询。
优势:
- 成本低,无需依赖缓存或数据库,直接在应用层拦截,效率高;
- 能针对性过滤业务场景中的无效请求。
4. 接口限流与熔断:控制请求总量
原理:
通过限流算法(如令牌桶、漏桶)限制单位时间内的请求数量,或通过熔断机制(如 Sentinel、Hystrix)在数据库压力过大时,暂时停止对无效请求的处理,避免数据库被压垮。
适用场景:
- 应对突发的恶意攻击(如短时间内大量不同的无效请求);
- 作为兜底策略,防止其他措施失效时数据库过载。
5. 数据预热:减少缓存未命中的概率
原理:
在系统启动或低峰期,提前将数据库中 “高频访问的有效数据” 加载到缓存中,减少缓存未命中的情况。虽然不能直接解决缓存穿透,但能降低无效请求的相对比例。
缓存穿透
定义:指查询一个「不存在的数据」时,由于缓存和数据库中都没有该数据,导致每次请求都会直接穿透缓存,全部打到数据库上。如果这类请求量很大,可能会压垮数据库。
缓存击穿
定义:指一个「热点 key」(被高频访问的 key)在缓存中突然失效(比如过期),此时大量请求同时访问该 key,缓存未命中,导致所有请求瞬间打到数据库,造成数据库短期内压力骤增。
缓存雪崩
定义:指「大量缓存 key 在同一时间集中过期」,或 Redis 服务本身宕机,导致缓存层整体失效,此时所有请求全部涌向数据库,数据库因无法承载高并发而崩溃。
| 维度 | 缓存穿透 | 缓存击穿 | 缓存雪崩 |
|---|---|---|---|
| 针对的 key | 不存在的 key | 存在的热点 key | 大量 key(或 Redis 集群) |
| 触发原因 | 数据本身不存在 | 热点 key 突然失效 | 大量 key 集中过期 / Redis 宕机 |
| 影响范围 | 单个无效 key 的高频请求 | 单个热点 key 的突发请求 | 整体缓存层失效,全量请求 |
缓存穿透保护:
// 布隆过滤器实现
public class BloomFilter {private BitSet bitSet;private int size;private HashFunction[] hashFunctions;public BloomFilter(int size, int hashCount) {this.bitSet = new BitSet(size);this.size = size;this.hashFunctions = new HashFunction[hashCount];for (int i = 0; i < hashCount; i++) {hashFunctions[i] = new HashFunction(size, i);}}public void add(String key) {for (HashFunction f : hashFunctions) {bitSet.set(f.hash(key), true);}}public boolean contains(String key) {for (HashFunction f : hashFunctions) {if (!bitSet.get(f.hash(key))) {return false;}}return true;}private static class HashFunction {private int size;private int seed;public HashFunction(int size, int seed) {this.size = size;this.seed = seed;}public int hash(String key) {int result = 1;for (char c : key.toCharArray()) {result = seed * result + c;}return (size - 1) & result;}}
}缓存击穿保护:
// 互斥锁实现
public class CacheBreakdownProtection {private RedisTemplate<String, Object> redisTemplate;private Map<String, Lock> lockMap = new ConcurrentHashMap<>();public Object getWithLock(String key, Callable<Object> loader) {Object value = redisTemplate.opsForValue().get(key);if (value != null) {return value;}Lock lock = lockMap.computeIfAbsent(key, k -> new ReentrantLock());try {lock.lock();// 双重检查value = redisTemplate.opsForValue().get(key);if (value == null) {value = loader.call();redisTemplate.opsForValue().set(key, value, 30, TimeUnit.MINUTES);}return value;} catch (Exception e) {throw new RuntimeException(e);} finally {lock.unlock();lockMap.remove(key);}}
}缓存雪崩保护:
// 随机过期时间实现
public class CacheAvalancheProtection {private RedisTemplate<String, Object> redisTemplate;private ThreadLocalRandom random = ThreadLocalRandom.current();public void setWithRandomExpire(String key, Object value, long baseExpire, long delta) {long expireTime = baseExpire + random.nextLong(delta);redisTemplate.opsForValue().set(key, value, expireTime, TimeUnit.SECONDS);}// 集群模式下使用多级缓存public Object getWithMultiLevelCache(String key, Callable<Object> loader) {Object value = redisTemplate.opsForValue().get(key);if (value != null) {return value;}value = localCache.get(key);if (value != null) {return value;}try {value = loader.call();setWithRandomExpire(key, value, 1800, 600); // 30分钟±10分钟localCache.put(key, value);return value;} catch (Exception e) {throw new RuntimeException(e);}}
}综合保护:
// 综合防护策略
public class CacheProtectionService {private BloomFilter bloomFilter;private CacheBreakdownProtection breakdownProtection;private CacheAvalancheProtection avalancheProtection;public Object safeGet(String key, Callable<Object> loader) {// 1. 检查布隆过滤器if (!bloomFilter.contains(key)) {return null;}// 2. 尝试获取缓存Object value = breakdownProtection.getWithLock(key, () -> {// 3. 数据加载逻辑Object loadedValue = loader.call();// 4. 设置随机过期时间avalancheProtection.setWithRandomExpire(key, loadedValue, 1800, 600);// 5. 更新布隆过滤器bloomFilter.add(key);return loadedValue;});return value;}
}2.redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
强一致性:需要让数据库与redis高度保持一致,因为要求时效性比较高。采用读写锁保证的强一致性。使用Redisson实现的读写锁。在读的时候添加共享锁,可以保证读读不互斥、读写互斥。当更新数据的时候,添加排他锁。它是读写、读读都互斥,这样就能保证在写数据的同时,是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是,读方法和写方法上需要使用同一把锁才行。排他锁底层使用的也是SETNX,它保证了同时只能有一个线程操作锁住的方法。
最终一致性:数据同步可以有一定的延时(这符合大部分业务需求)。采用的阿里的Canal组件实现数据同步:不需要更改业务代码,只需部署一个Canal服务。Canal服务把自己伪装成mysql的一个从节点。当mysql数据更新以后,Canal会读取binlog数据,然后再通过Canal的客户端获取到数据,并更新缓存即可。
3.为什么要优先保证数据库一致性,先更新缓存会怎么样?
在处理数据同步时优先保证数据库一致性,核心是因为数据库是数据的最终持久化存储,是数据真实性的权威来源。从实际项目场景来看,若先更新缓存,可能出现 “缓存更新成功但数据库更新失败” 的情况:比如xxxx项目更新中,若先修改了 Redis 中的模板缓存,却因网络波动等导致 MySQL 中模板数据更新失败,会使缓存中留存错误数据,后续所有依赖该缓存的请求都会获取到不一致信息,且难以快速发现和修正。
而先更新数据库再处理缓存,即使缓存更新失败,后续请求查询时会因缓存未命中而从数据库加载最新数据并重建缓存,能通过 “数据库的正确性” 兜底,保证数据最终一致。这也与项目中对 Redis 缓存的使用逻辑一致 —— 缓存本质是提升查询效率的辅助存储,其一致性需依赖数据库这一核心载体来保障。
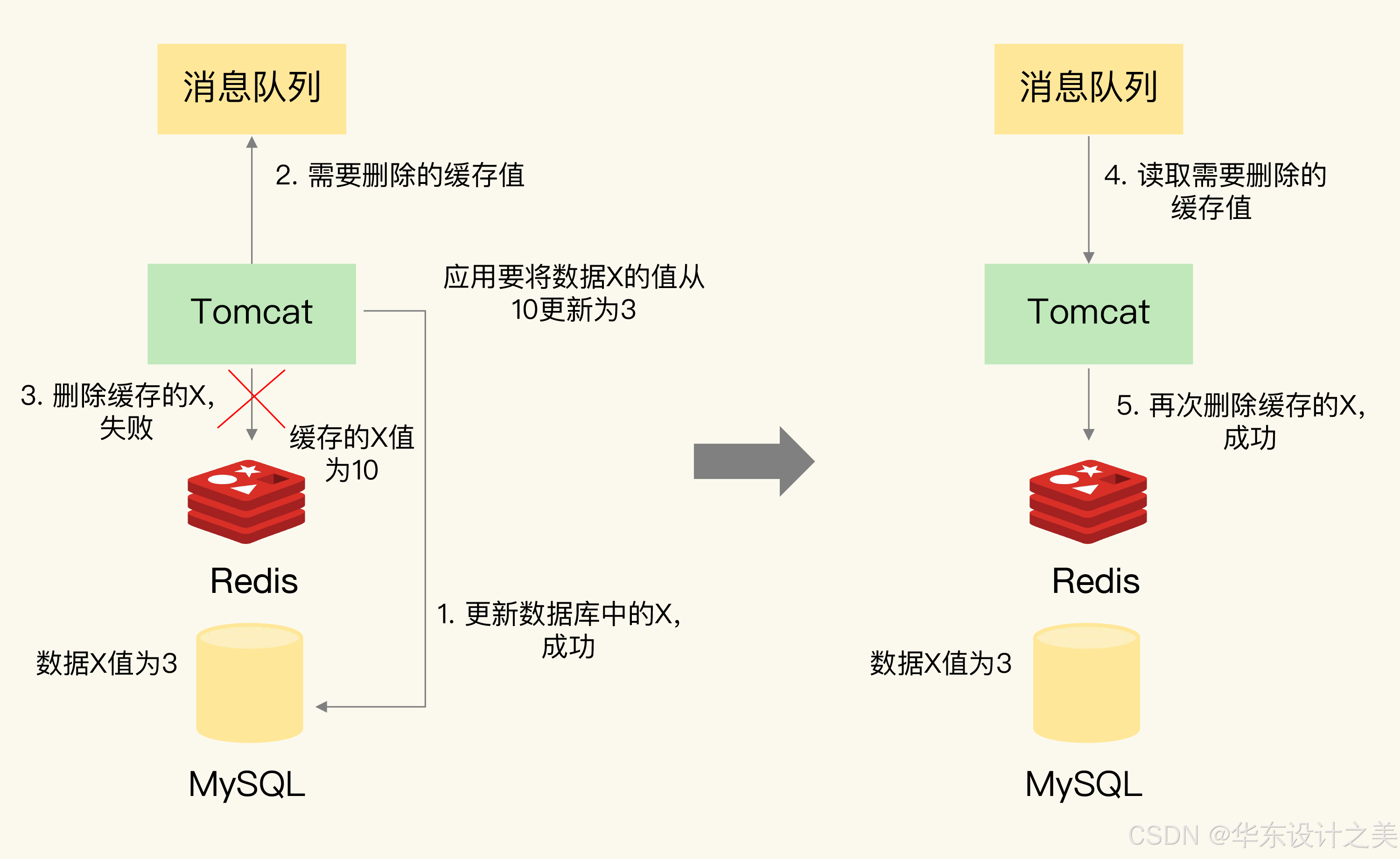
4.你听说过延时双删吗?为什么不用它呢?
延时双删是一种在高并发场景下解决数据库与缓存双写一致性问题的策略,其核心思想是通过两次删除缓存操作,配合一定的延迟时间,尽量保证在数据库更新完成后,旧数据不会因并发请求被错误地重新写入缓存。以下是其实现原理和关键步骤:
基本流程
- 先删除缓存:在更新数据库前,先删除 Redis 中的对应缓存,防止后续请求读取到旧数据。
- 更新数据库:执行 MySQL 等数据库的更新操作。
- 延时后再次删除缓存:更新数据库完成后,等待一段时间(如 1-3 秒),再次删除 Redis 缓存。
- 目的:确保在数据库更新期间,若有请求读取到旧数据并写入缓存,通过第二次删除操作清除该脏数据。
为什么需要延时?
在高并发场景下,可能存在以下时序问题:
- 步骤 1 删除缓存后,若有新请求在数据库更新前读取数据,会从数据库获取旧值并重新写入缓存。
- 步骤 2 更新数据库,此时缓存中仍为旧值,导致后续请求读取到不一致的数据。
通过延时,可以等待数据库更新完成后,再执行第二次删除,确保旧数据被彻底清除。
延时时间如何确定?
通常需要根据业务场景的数据库更新耗时和请求处理耗时来估算,一般设置为1-3 秒。例如:
- 若数据库更新操作平均耗时 200ms,可设置延时为 1 秒,确保大部分更新操作已完成。
- 对于更复杂的业务,可通过压测或监控数据动态调整延时时间。
优缺点
- 优点:实现简单,成本低,能解决大部分并发场景下的数据不一致问题。
- 缺点:
- 无法保证强一致性:极端情况下(如第二次删除失败)仍可能存在短暂不一致。
- 性能损耗:延时操作会增加请求响应时间,影响吞吐量。
- 延时时间难精准控制:不同业务场景的最优延时时间差异较大。
适用场景
- 适用于读多写少、对一致性要求不是极致严格的场景(如商品价格、用户信息等)。
- 不适用于金融交易等需要强一致性的场景(通常需借助分布式事务或中间件)。
实际项目中的替代方案
在实际项目中,更倾向于使用:
- 异步消息队列:通过 MQ 异步更新缓存,利用重试机制保证最终一致性。
- 订阅数据库 binlog:如通过 Canal 监听 MySQL 变更,自动同步到 Redis,减少人工干预。
- 设置合理的缓存过期时间:作为兜底策略,即使出现不一致,过期后会自动刷新。
5.redis做为缓存,数据的持久化是怎么做的?这两种持久化方式有什么区别呢,优缺点?分别介绍一下这两种持久化方式那个恢复得更快?
Redis 的数据持久化主要通过两种方式实现:RDB(Redis Database)和 AOF(Append Only File)。
RDB 是通过生成数据集的时间点快照来实现持久化的。它会在指定的时间间隔内,将内存中的所有数据以二进制的形式写入磁盘的 RDB 文件中,比如可以配置 “每 5 分钟内有 1000 次写操作就触发一次快照”。
AOF 则是通过记录所有写操作命令来实现持久化的。服务器在执行完一个写命令后,会将该命令追加到 AOF 文件的末尾,当 Redis 重启时,会通过重新执行 AOF 文件中的所有命令来恢复数据。
两者的区别主要体现在以下方面:
从数据完整性来看,RDB 可能会丢失最后一次快照后的所有数据,因为它是定时快照;而 AOF 可以通过配置 “everysec”(每秒同步一次)等策略,最多丢失 1 秒内的数据,完整性更好。
从文件大小来看,RDB 是二进制压缩存储,文件体积较小;AOF 记录的是命令文本,相同数据下文件体积更大,即使有重写机制优化,通常也比 RDB 大。
从性能影响来看,RDB 在触发快照时会通过 fork 子进程处理,主进程不阻塞,但 fork 操作在数据量大时可能有短暂阻塞;AOF 的追加操作是异步的,对主进程影响小,但 AOF 重写时也可能有一定性能消耗。
在恢复速度上,RDB 更快。因为 RDB 是二进制文件,加载时直接解析还原数据即可;而 AOF 需要逐条执行命令,尤其是当 AOF 文件较大时,恢复速度会明显慢于 RDB。
6.Redis的数据过期策略有哪些? Redis的数据淘汰策略有哪些?
一、数据过期策略(处理已过期的 Key)
Redis 采用 「定期删除 + 惰性删除」组合策略 ,平衡 CPU 性能与内存利用率。
惰性删除(Lazy Deletion)
- 触发时机:仅当访问(读 / 写)已过期的 Key 时,才会检查并删除。
- 优点:避免主动扫描带来的 CPU 开销,适合低频访问的过期 Key。
- 缺点:若过期 Key 长期未被访问,会导致内存泄漏(如用户会话缓存长期未失效)。
定期删除(Periodic Deletion)
- 执行逻辑:默认每 100ms 随机抽取 20 个设置过期时间的 Key,删除其中已过期的;若过期比例>25%,重复抽取,单次扫描耗时不超过 25ms。
- 优点:主动清理部分过期 Key,防止内存膨胀。
- 缺点:随机抽样可能遗漏大量过期 Key(如集中过期的热点数据)。
二、数据淘汰策略(内存不足时的兜底方案)
当 Redis 内存达到maxmemory阈值时,根据以下 8 种策略淘汰数据(区分「是否设置过期时间」):
| 策略分类 | 策略名称 | 淘汰逻辑 | 适用场景 |
|---|---|---|---|
| 仅过期 Key | volatile-lru | 淘汰最近最少使用(LRU)的过期 Key | 缓存临时数据(如验证码、短期会话),保留永久数据 |
volatile-lfu | 淘汰最不频繁使用(LFU)的过期 Key(Redis 4.0+) | 区分短期高频访问的临时数据(如活动促销页缓存) | |
volatile-ttl | 优先淘汰剩余 TTL 最短的过期 Key | 需精准控制过期顺序的场景(如倒计时活动) | |
volatile-random | 随机淘汰过期 Key | 无明显冷热数据区分的临时缓存 | |
| 所有 Key | allkeys-lru | 淘汰全体 Key 中最近最少使用的 | 通用缓存场景(如商品详情页),不区分是否过期 |
allkeys-lfu | 淘汰全体 Key 中最不频繁使用的(Redis 4.0+) | 长期冷热数据分明(如用户行为日志缓存) | |
allkeys-random | 随机淘汰全体 Key | 数据访问频率均匀的场景(如测试环境) | |
| 不淘汰 | noeviction(默认) | 拒绝写入新数据(读正常),防止数据丢失 | 不允许丢失数据的场景(如持久化配置中心) |
三、核心区别与选择建议
| 维度 | 过期策略(已过期 Key) | 淘汰策略(内存不足) |
|---|---|---|
| 触发条件 | Key 已过期 | 内存超过阈值 |
| 目标 | 释放过期内存 | 腾出空间写入新数据 |
| 典型场景 | 会话超时、验证码失效 | 突发流量导致内存不足 |