第二十三篇文档格式互转大师:Python实现PDF、Word、图片、Markdown的高效转换!你的万能转换器!
常见办公格式互转
- 前言: 文档格式不统一,转换麻烦
- 1.PDF与图片互转:批量处理
- 1.1DF转多张图片:将PDF内容提取为图像
- 1.2多张图片合并为一张PDF:快速制作PDF文档
- 2.实现Word与PDF互转:一键搞定报告、合同格式!
- 2.1Word批量转PDF:最常见的文档分发需求
- 2.2PDF转Word:挑战与限制并存的“逆向工程”
- 3.Python实现Markdown转PDF/Word
- 3.1Markdown语法速览:简洁高效的写作方式
- 3.2Markdown转PDF/Word:用Python打通文档生态
- 4.你的“文档格式转换工厂”!
- 5.尾声:文档格式互转,解锁文件管理新维度!
前言: 文档格式不统一,转换麻烦
我们在日常生活中经常碰到这样的场景。
客户要求提交简历必须是PDF,但你只有Word版,手动转换后格式全乱。
需要从PDF报告中提取图表,却发现无法直接复制,只能一张张截图。
制作演示文稿,收集到的图片大小、格式五花八门,插入后需要反复调整。

我们今天将手把手教你如何利用Python,轻松实现:
PDF与图片互转: 批量提取PDF中的图片,或将多图合为PDF。
Word与PDF互转: 轻松实现Word批量转PDF,甚至尝试PDF转Word。
Markdown文档转换: 让你的极客笔记瞬间变成专业PDF/Word报告。
最终,你将拥有一个强大的文档格式转换工厂,
让你的文件管理和传输效率翻倍,老板看了都点赞!
1.PDF与图片互转:批量处理
PDF虽然方便查看,但要提取其中的图片或将大量图片打包成PDF,手动操作非常麻烦。
Python能帮你批量处理这些需求,实现PDF转图片和图片转PDF的自动化!
如何实现呢?
PDF转图片: PyMuPDF可以渲染PDF页面,并将其保存为图片。
图片转PDF: Pillow可以创建图片,PyMuPDF可以将图片插入到PDF页面。
1.1DF转多张图片:将PDF内容提取为图像
场景: 你收到一份有插图的PDF报告,想把里面的图表或每一页都提取出来作为图片素材,用于
PPT或网页展示。手动截图不仅分辨率低,还耗时。
方案: 利用PyMuPDF,可以批量将PDF的每一页高质量地转换为图片,并支持多种图片格式和分辨率。
安装:
pip install PyMuPDF
代码:
import fitz # PyMuPDF
import osdef pdf_to_images(pdf_path, output_folder, img_format="png", dpi=200):"""将PDF文件的每一页转换为一张图片。这是PDF转图片和Python文件转换的核心功能。:param pdf_path: 源PDF文件路径:param output_folder: 图片输出文件夹:param img_format: 输出图片格式 (如 "png", "jpeg", "jpg"):param dpi: 图片分辨率 (Dots Per Inch),DPI越高图片越清晰但文件越大"""if not os.path.exists(pdf_path): return print(f"❌ PDF文件不存在:{pdf_path}")os.makedirs(output_folder, exist_ok=True)print(f"🚀 正在将 '{os.path.basename(pdf_path)}' 转换为多张图片...")try:doc = fitz.open(pdf_path)zoom = dpi / 72 # 计算缩放比例 (1英寸=72点)mat = fitz.Matrix(zoom, zoom) # 缩放矩阵for page_num in range(doc.page_count):page = doc.load_page(page_num)pix = page.get_pixmap(matrix=mat) # 获取页面的像素图output_image_path = os.path.join(output_folder, f"{os.path.splitext(os.path.basename(pdf_path))[0]}_page_{page_num+1}.{img_format}")# 保存像素图为图片文件pix.save(output_image_path)print(f" ✅ 已生成图片:'{os.path.basename(output_image_path)}'")doc.close()print(f"✨ PDF批量转图片完成!结果保存到:'{output_folder}'")return Trueexcept Exception as e:print(f"❌ PDF转图片失败:{e}")return Falseif __name__ == "__main__":# 准备测试PDF文件 (多页,包含文本和可能图片)source_pdf = os.path.expanduser("~/Desktop/presentation.pdf")if not os.path.exists(source_pdf):doc = fitz.open()p1 = doc.new_page(); p1.insert_text(fitz.Point(50,50), "第一页内容和图表");p2 = doc.new_page(); p2.insert_text(fitz.Point(50,50), "第二页内容");doc.save(source_pdf); doc.close()output_images_folder = os.path.expanduser("~/Desktop/PDF转图片结果")# 示例1:将PDF转换为PNG图片,分辨率200DPIpdf_to_images(source_pdf, output_images_folder, img_format="png", dpi=200)# 示例2:转换为JPG图片,分辨率300DPI (更高质量,更大文件)# pdf_to_images(source_pdf, os.path.join(os.path.dirname(output_images_folder), "PDF_to_JPG"), img_format="jpg", dpi=300)
操作:
安装库: pip install PyMuPDF。
准备PDF文件: 在桌面准备一个多页PDF(如presentation.pdf)。
修改代码路径和参数: 修改 source_pdf、output_images_folder 和 img_format/dpi。
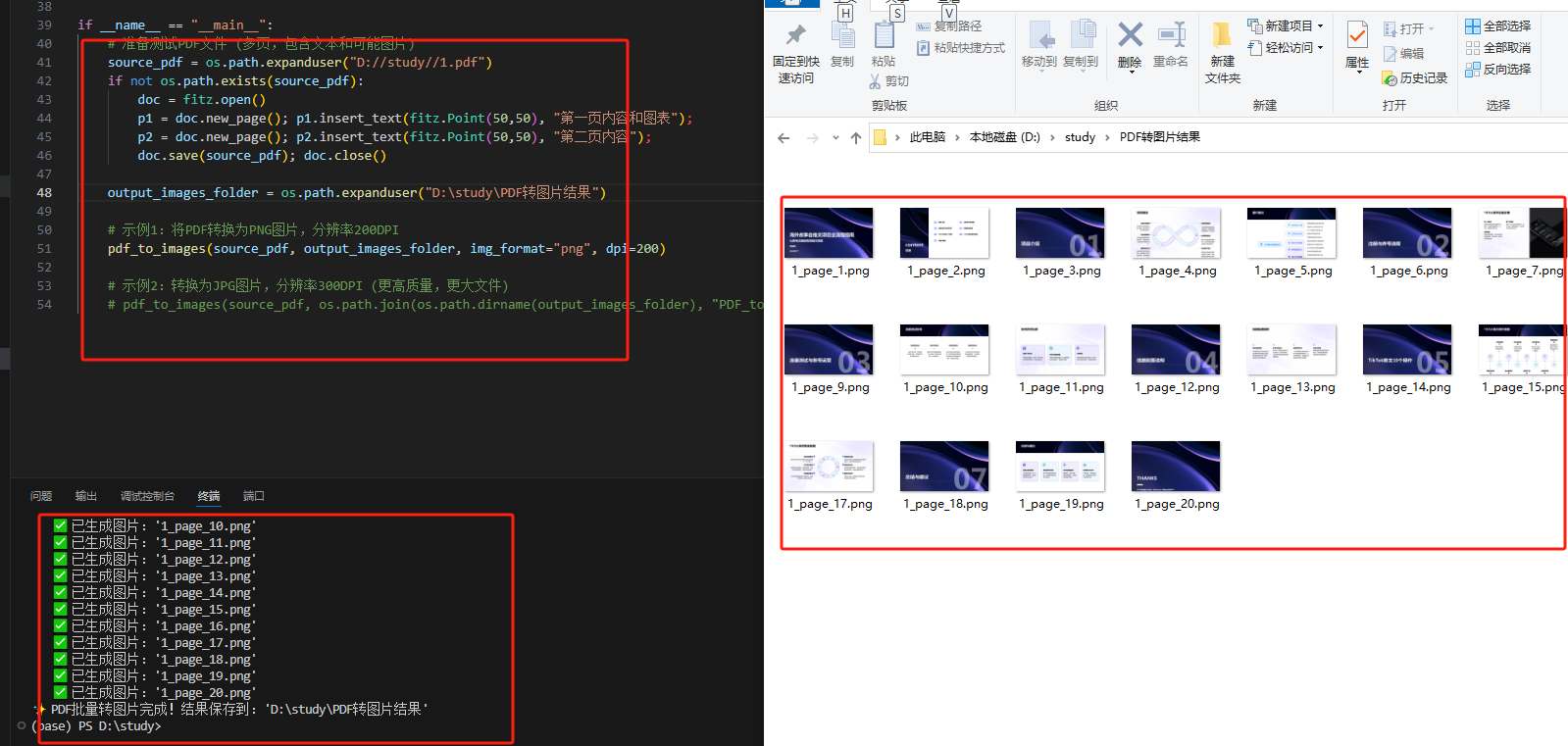
运行: 运行 python pdf_to_images.py。
效果展示:

1.2多张图片合并为一张PDF:快速制作PDF文档
场景: 你有大量图片(如扫描件、产品图集、幻灯片截图),需要将它们快速整理成一份PDF文档,方便分享或存档。
方案: PyMuPDF能让你将多张图片一键合并为一张多页PDF文档,并可以控制每张图片在PDF中的显示方式。
代码:
import fitz # PyMuPDF
from PIL import Image # 用于处理图片
import osdef images_to_pdf(image_paths, output_pdf_path):"""将多张图片合并为一个PDF文件。这是Python文件转换和图片转PDF的核心功能。:param image_paths: 包含所有要合并的图片文件路径的列表:param output_pdf_path: 输出PDF文件路径"""if not image_paths: return print("❌ 没有提供图片文件路径。")os.makedirs(os.path.dirname(output_pdf_path), exist_ok=True)print(f"🚀 正在合并 {len(image_paths)} 张图片到 '{os.path.basename(output_pdf_path)}'...")doc = fitz.open() # 创建一个新的PDF文档try:for img_path in image_paths:if not os.path.exists(img_path):print(f"⚠️ 图片文件不存在,跳过:{os.path.basename(img_path)}")continue# 为每张图片创建一个新页面# fitz.open(img_path) 可以直接打开图片文件作为PDF文档处理img_doc = fitz.open(img_path)new_page_width = img_doc[0].rect.widthnew_page_height = img_doc[0].rect.heightimg_doc.close() # 关闭临时文档# 创建一个新页面,尺寸与图片匹配 (或者使用A4尺寸,然后缩放图片)page = doc.new_page(width=new_page_width, height=new_page_height) # 插入图片到页面 (覆盖整个页面)rect = page.rect # 页面大小page.insert_image(rect, filename=img_path)print(f" ✅ 已添加图片:'{os.path.basename(img_path)}' 到PDF。")doc.save(output_pdf_path)print(f"✨ 图片合并到PDF完成!结果保存到:'{output_pdf_path}'")return Trueexcept Exception as e:print(f"❌ 图片合并到PDF失败:{e}")return Falsefinally:doc.close()if __name__ == "__main__":# 准备测试图片文件 (多张)img1_path = os.path.expanduser("~/Desktop/scan_page1.png")img2_path = os.path.expanduser("~/Desktop/scan_page2.png")output_pdf = os.path.expanduser("~/Desktop/scanned_document.pdf")# 简单创建模拟图片文件if not os.path.exists(img1_path):Image.new('RGB', (800, 600), color = 'red').save(img1_path)if not os.path.exists(img2_path):Image.new('RGB', (800, 600), color = 'blue').save(img2_path)images_to_convert = [img1_path, img2_path]images_to_pdf(images_to_convert, output_pdf)
步骤:
安装库: pip install PyMuPDF Pillow。
准备图片文件: 在桌面准备多张图片文件(如scan_page1.png, scan_page2.png)。
修改代码路径: 修改 images_to_convert 列表中的路径和 output_pdf。
运行: 运行 python images_to_pdf.py。
效果展示:

2.实现Word与PDF互转:一键搞定报告、合同格式!
Word和PDF是职场中最常用的两种文档格式。Python能帮你一键在它们之间进行高效转换,彻底告别文档格式不统一的烦恼!
实现:
Word转PDF: 通常需要借助外部工具或虚拟打印功能,因为它涉及Word文档的渲染。docx2pdf是一个不错的选择。
PDF转Word: 这是一个挑战性任务,因为PDF主要用于显示,不含结构信息。虽然有库能提取文本,但保留原始排版非常困难
2.1Word批量转PDF:最常见的文档分发需求
场景: 你需要将几十份Word报告或合同转换成PDF格式,方便分发和防止篡改。手动另存为PDF,效率低下。
方案: docx2pdf库能帮你一键批量将Word文档转换为PDF,并保持良好的格式。
代码:
from docx2pdf import convert # 导入转换函数
import osdef batch_word_to_pdf(source_folder, output_folder):"""批量将Word文档转换为PDF文件。这是Word转PDF和Python文件转换的核心功能。:param source_folder: 源Word文档文件夹路径:param output_folder: 输出PDF文件文件夹"""if not os.path.exists(source_folder): return print(f"❌ 源文件夹不存在:{source_folder}")os.makedirs(output_folder, exist_ok=True)print(f"🚀 正在批量将 '{source_folder}' 下的Word文档转换为PDF...")processed_count = 0# 遍历文件夹中的所有.docx文件for filename in os.listdir(source_folder):if filename.lower().endswith('.docx'):source_path = os.path.join(source_folder, filename)output_pdf_path = os.path.join(output_folder, os.path.splitext(filename)[0] + ".pdf")try:# **核心操作:调用 docx2pdf.convert()**convert(source_path, output_pdf_path)print(f" ✅ 转换成功:'{filename}' -> '{os.path.basename(output_pdf_path)}'")processed_count += 1except Exception as e:print(f"❌ 转换 '{filename}' 失败:{e}。请确保Office/WPS等已安装。")else:print(f"ℹ️ 跳过非Word文件:{filename}")print(f"✨ Word批量转PDF完成!共转换 {processed_count} 个文件。")return Trueif __name__ == "__main__":# 准备测试Word文档 (放入一些.docx文件)source_word_folder = os.path.expanduser("~/Desktop/MyWordReports")output_pdf_folder = os.path.expanduser("~/Desktop/PDFReports")os.makedirs(source_word_folder, exist_ok=True)# 简单创建模拟Word文档from docx import Document as DocxDocumentif not os.path.exists(os.path.join(source_word_folder, "report1.docx")):doc = DocxDocument(); doc.add_paragraph("这是报告1"); doc.save(os.path.join(source_word_folder, "report1.docx"))if not os.path.exists(os.path.join(source_word_folder, "contract.docx")):doc = DocxDocument(); doc.add_paragraph("这是一份合同"); doc.save(os.path.join(source_word_folder, "contract.docx"))batch_word_to_pdf(source_word_folder, output_pdf_folder)
步骤:
安装库: pip install docx2pdf。注意:docx2pdf库需要你的系统安装了Microsoft Office Word、WPS Office或LibreOffice,它会调用这些软件进行转换。
准备Word文件: 在桌面创建MyWordReports文件夹,放入一些.docx文件。
修改代码路径: 修改 source_word_folder 和 output_pdf_folder。
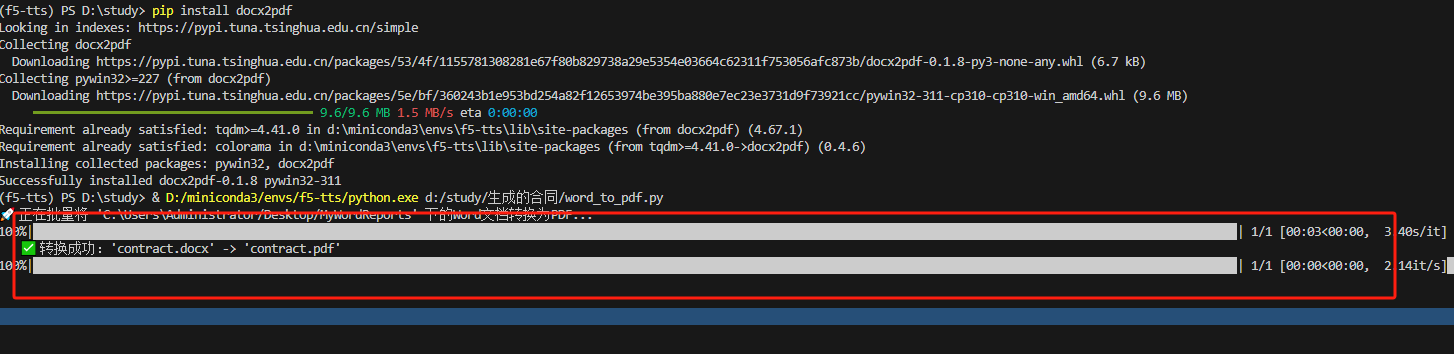
运行: 运行 python word_to_pdf.py。

效果展示:
2.2PDF转Word:挑战与限制并存的“逆向工程”
场景: 你收到一份PDF文档,但需要对其内容进行编辑,或提取其结构化信息到Word中。PDF的固定格式让你束手无策。
方案: PDF转Word是一个非常困难的“逆向工程”! 因为PDF是用来“显示”的,它不包含Word那样的段落、字体、样式等结构化信息。
难点:Python库(如pdfminer.six、PyMuPDF用于提取文本,但要完美还原Word格式,几乎不可能。通常需要借助外部专业工具(如Adobe Acrobat、在线转换器)或复杂的OCR技术。PyMuPDF可以提取文本,但排版还原困难。
代码:
import fitz # PyMuPDF
import osdef pdf_to_text(pdf_path, output_txt_path):"""从PDF文件中提取纯文本内容。这是PDF转Word(文本部分)的基础。:param pdf_path: 源PDF文件路径:param output_txt_path: 输出文本文件路径"""if not os.path.exists(pdf_path): return print(f"❌ PDF文件不存在:{pdf_path}")os.makedirs(os.path.dirname(output_txt_path), exist_ok=True)print(f"🚀 正在从 '{os.path.basename(pdf_path)}' 提取文本...")try:doc = fitz.open(pdf_path)text_content = ""for page_num in range(doc.page_count):page = doc.load_page(page_num)text_content += page.get_text() # 提取页面所有文本doc.close()with open(output_txt_path, "w", encoding="utf-8") as f:f.write(text_content)print(f"✅ 文本提取成功!保存到:'{output_txt_path}'")return Trueexcept Exception as e:print(f"❌ 文本提取失败:{e}")return Falseif __name__ == "__main__":source_pdf = os.path.expanduser("~/Desktop/sample_pdf.pdf")output_txt = os.path.expanduser("~/Desktop/extracted_text.txt")# 简单创建模拟PDF文件if not os.path.exists(source_pdf):doc = fitz.open(); doc.new_page().insert_text((50,50), "这是PDF中的文本内容。"); doc.save(source_pdf); doc.close()pdf_to_text(source_pdf, output_txt)
步骤:
安装库: pip install PyMuPDF。
准备PDF文件: 在桌面准备一个包含文本的PDF文件(如sample_pdf.pdf)。
修改代码路径: 修改 source_pdf 和 output_txt。
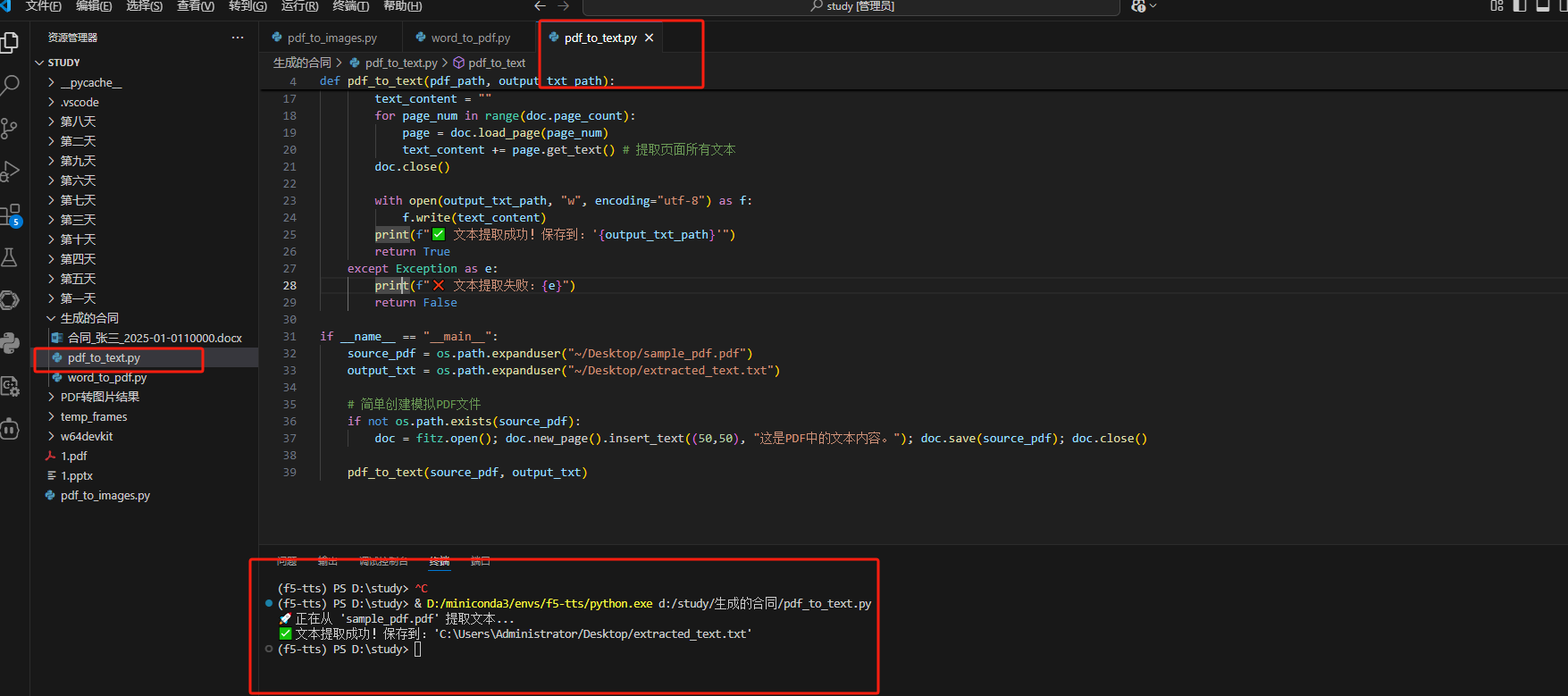
运行: 运行 python pdf_to_text.py。
效果展示:
3.Python实现Markdown转PDF/Word
Markdown是一种轻量级标记语言,它让你用纯文本轻松写作,并能方便地转换为各种文档格式。Python结合pandoc(一个强大的文档转换工具)或特定的Markdown解析库,能帮你实现Markdown转PDF或Markdown转Word,这是Python文件转换的高阶应用!
作用: Markdown文件通过解析器转换为中间格式(如HTML),再由渲染器转换为目标格式。pandoc是命令行工具,Python可以调用它。
3.1Markdown语法速览:简洁高效的写作方式
Markdown语法简单直观,常用语法如下:
[表格:Markdown常用语法速查表]
| 语法 | 效果 | 示例 |
|---|---|---|
| # 标题 | 一级标题 | # 这是标题 |
| 粗体 | 粗体 | 重要 |
| 斜体 | 斜体 | 强调 |
| - 列表项 | 无序列表 | - 项目1 |
| 1. 列表项 | 有序列表 | 1. 步骤1 |
| 链接 | 超链接 | CSDN |
代码 | 行内代码 | print() |
| 代码块 | python ... |
3.2Markdown转PDF/Word:用Python打通文档生态
场景: 你用Markdown写了大量笔记和文档,现在需要将它们导出为专业排版的PDF报告或Word文档,方便分享给非技术人员。
方案: 我们可以通过Python调用pandoc命令行工具,实现Markdown文件到PDF或Word的转换。这需要你的系统安装pandoc。
安装Pandoc:
访问Pandoc官网 (pandoc.org) 下载并安装。安装后,确保pandoc已添加到系统环境变量。
在终端运行 pandoc --version 验证安装。
代码:
import os
import subprocess # 用于运行外部命令行命令def convert_markdown_to_pdf_word(markdown_path, output_path, target_format="pdf"):"""将Markdown文件转换为PDF或Word文档。这是Markdown转PDF/Word和Python文件转换的核心功能。:param markdown_path: 源Markdown文件路径:param output_path: 输出PDF或Word文件路径:param target_format: 目标格式 ("pdf", "docx")"""if not os.path.exists(markdown_path): return print(f"❌ Markdown文件不存在:{markdown_path}")os.makedirs(os.path.dirname(output_path), exist_ok=True)print(f"🚀 正在将 '{os.path.basename(markdown_path)}' 转换为 {target_format.upper()} 格式...")try:if target_format == "pdf":# pandoc markdown.md -o output.pdf --pdf-engine=xelatex (或pdflatex)command = ['pandoc', markdown_path, '-o', output_path, '--pdf-engine=xelatex'] # 需要安装LaTeX发行版如MiKTeX/Tex Liveelif target_format == "docx":# pandoc markdown.md -o output.docxcommand = ['pandoc', markdown_path, '-o', output_path]else:print("⚠️ 未知的目标格式。")return False# 运行pandoc命令result = subprocess.run(command, capture_output=True, text=True, encoding='utf-8')if result.returncode == 0:print(f"✅ 转换成功!保存到:'{output_path}'")return Trueelse:print(f"❌ 转换失败!错误信息:{result.stderr}")return Falseexcept FileNotFoundError:print("❌ Pandoc未安装或未添加到PATH。请访问 pandoc.org 安装。")return Falseexcept Exception as e:print(f"❌ 转换失败:{e}")return Falseif __name__ == "__main__":source_md = os.path.expanduser("~/Desktop/my_notes.md")output_pdf = os.path.expanduser("~/Desktop/my_notes.pdf")output_docx = os.path.expanduser("~/Desktop/my_notes.docx")# 简单创建模拟Markdown文件if not os.path.exists(source_md):with open(source_md, "w", encoding="utf-8") as f:f.write("# 我的自动化笔记\n\n- 项目进展\n- **重要事项**\n\n```python\nprint('Hello')\n```")# 示例1:Markdown转PDF (需要安装LaTeX发行版,如MiKTeX或Tex Live)print("\n--- 示例1:Markdown转PDF ---")convert_markdown_to_pdf_word(source_md, output_pdf, target_format="pdf")# 示例2:Markdown转Wordprint("\n--- 示例2:Markdown转Word ---")convert_markdown_to_pdf_word(source_md, output_docx, target_format="docx")
步骤:
安装Pandoc: 从pandoc.org下载并安装,并确保其添加到系统PATH。如果转PDF,你还需要安装一个LaTeX发行版(如MiKTeX for Windows, TeX Live for Linux/macOS)。
准备Markdown文件: 在桌面创建my_notes.md。
修改代码路径: 修改 source_md 等路径。
运行: 运行 python markdown_converter.py。
效果展示:

4.你的“文档格式转换工厂”!
我们深入学习了PyMuPDF、Pillow、docx2pdf、subprocess等库/工具,实现了:
PDF与图片互转: 轻松将PDF页面批量转换为图片,或将多张图片合并为PDF,实现像素级掌控。
Word与PDF互转: 一键批量将Word转PDF,并知晓PDF转Word的挑战与提取文本方法。
Markdown文档转换: 利用pandoc,将Markdown笔记转换为专业的PDF/Word文档。
5.尾声:文档格式互转,解锁文件管理新维度!
通过本篇文章,你已经掌握了文档格式互转的强大能力,为你的办公自动化之旅又增添了一个重量级技能!你学会了如何利用Python和外部工具,高效地实现PDF、Word、图片、Markdown之间的各种转换。
除了今天学到的格式转换功能,你还希望Python能帮你实现哪些更复杂的文档处理需求?比如:自动将Excel数据填充到PDF表单?或者实现PDF的批量OCR识别?在评论区分享你的需求和想法,你的
建议可能会成为我们未来文章的灵感来源!
敬请期待! 文档自动化模块至此圆满收官!在后续文章中,我们将继续深入Python办公自动化的宝库,探索如何利用Python实现邮件自动化,让你的邮件收发和管理工作效率翻倍!同时,本系列所有代码都将持续更新并汇总在我的GitHub仓库中,敬请关注!