yolov8-pos/yolov11-pos 训练
一、前言
最近需要做草莓识别以及摘取,需要对草莓识别,并获取草莓头和草莓尖这2个关键点,故关注到可使用yolov8-pos / yolov11-pos 解决,对 yolov11-pos 进行了实验。
假设有 c个 类别, n个特征点 yolov11-pos 单张图在640尺度下输出特征图是 1*8400*(4+c+n*3),相当于有8400个长度为(4+c+n*3)的特征, 4表示预测框的中心点x,y坐标,宽、高;c表示 c个类的预测概率,n*3是 n个点 , 每个点 有 x y 属性(无效0,不可见1,可见2) , 这3个值。
二、数据集制作
(1)识别对象
我的识别对象主要有草莓熟果、果梗,这2类对象,关键点数量为2,草莓的头和尖,果梗虽然不识别关键点,但是也必须有2个点,这里我就取边框的 (中心点x坐标,边框的y坐标top坐标)和(中心点x坐标,边框的y坐标bottom坐标 ) 像是下面的
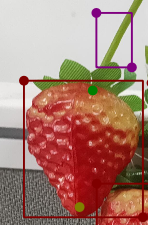
这个是labelme 画出来的,梗的2个点可以直接生成,所以在标注的时候可以不画出来
(2)labelme 软件画标注
采集足够数据后,需要对这2类的矩形框和关键点画出来,使用labelme 软件打开这个文件夹。显示如下
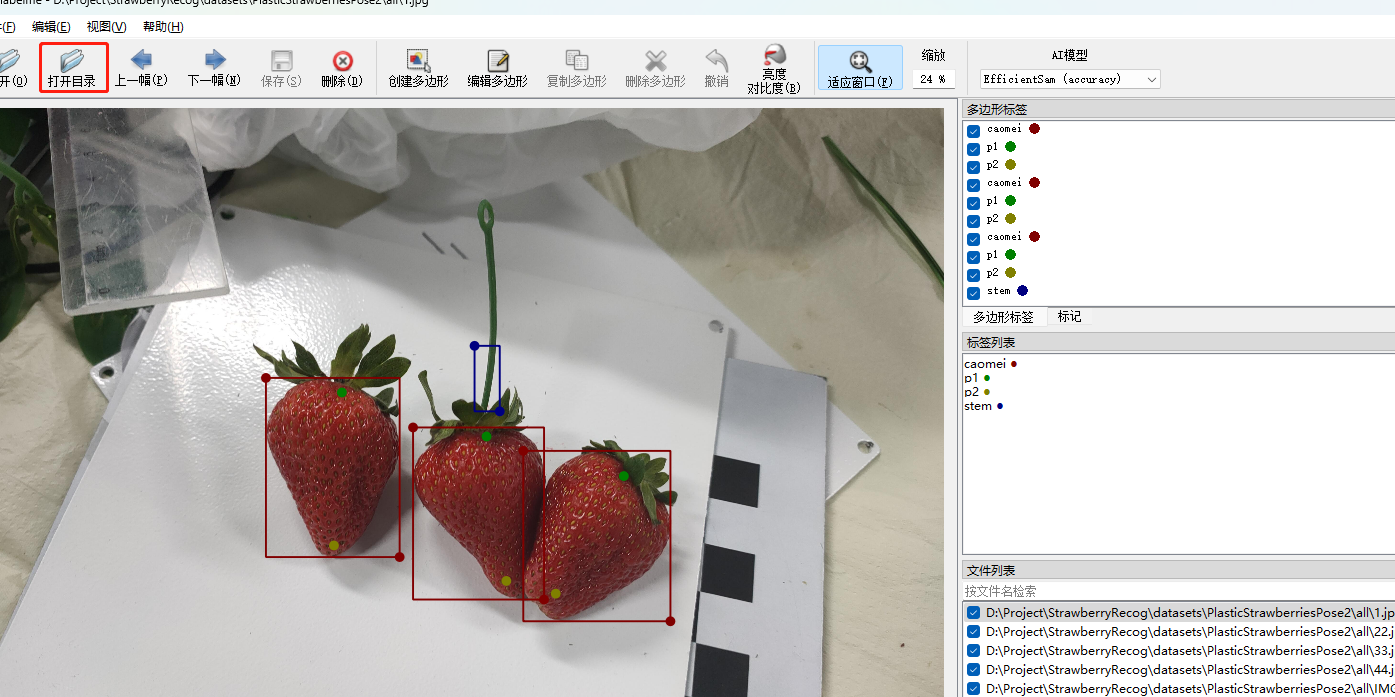
然后画框的时候注意,为了使框和关键点是对应的,便于后续转换json文件为 txt文件,需要每次画一个框后,把2个关键点也画一画;
画框是:编辑-》创建矩形
画点是:编辑-》创建控制点
画一个框和对应2个点,在后边可显示出顺序关系,caomei矩形框之后是p1和p2两个点

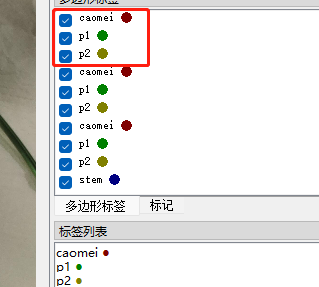
标注完成后,labelme软件是生成和图片同名字的json文件。
(3)把所有json文件给转换成yolo格式的txt文件
yolo格式的txt文件中一行是一个识别对象,一个对象是 1个框2个点,共有 (1+4+n*3)个数据,也即是 (1+4+2*3)=11个数据,跟前面讲输出维度(4+c+n*3)有些点点不同,但本质一致。
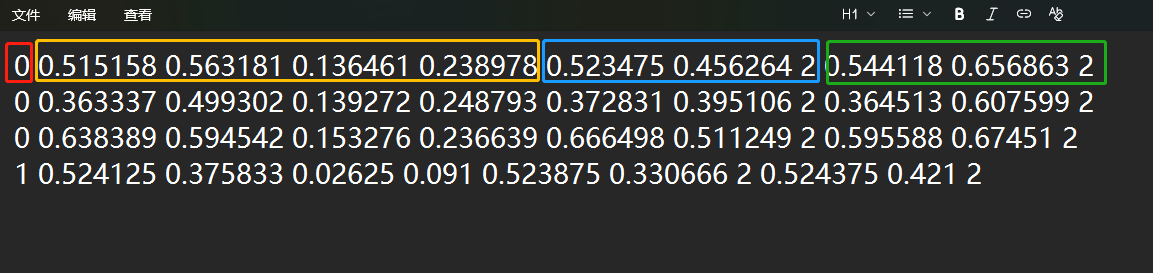
(1+4+2*3),也即 第1个数是类别号,1个类别的类别值就是0 ,2个类别就是0或1 ;3个类别就是0 或1或2,以此类推;4就是边框归一化的中心点 x ,y坐标 宽 和 高 坐标 ;2*3, 也即2个点,每个点有3个数值, x , y , 属性(无效0,不可见1,可见2),无效就是这个点不在图像中了,不可见就是点在图像中,但是被遮挡,可见就是点在图像中,且未被遮挡。
在我这都是默认可见 2 了。现在需要编写脚本转换一下,我把图片和相应json文件放在 all文件夹,需要生成 txt 文件在 pos_txt , 脚本如下:
import json
import os
import copyfrom tool import getXyXydef read_jsonfile( path):with open(path, "r", encoding='utf-8') as f:return json.load(f)def check_lists(a, b, c):# 确保所有列表长度一致if len(a) != len(b) or len(a) != len(c):raise ValueError("所有列表的长度必须相同")# 检查每个位置上的数字是否符合要求 (例如,数字之间相差1)for i in range(len(a)):if not (b[i] == a[i] + 1 and c[i] == a[i] + 2):raise ValueError(f"第 {i + 1} 个位置的元素不符合规律:a={a[i]}, b={b[i]}, c={c[i]}")def checkShapeData( shape_data ):caomei_id = []for d_i , d in enumerate(shape_data ) :if d["label"] == 'caomei':caomei_id.append( d_i )p1_id = []for d_i , d in enumerate(shape_data ) :if d["label"] == 'p1':p1_id.append( d_i )p2_id = []for d_i , d in enumerate(shape_data ) :if d["label"] == 'p2':p2_id.append( d_i )try:check_lists(caomei_id, p1_id, p2_id)except ValueError as e:print(f"错误: {e}")return caomei_id,p1_id,p2_iddef genPosTxt(pos_all, txt_path, im_h, im_w):f_txt = open(txt_path, 'w')for e in pos_all:if len(e) == 3:x1, y1, x2, y2 = e[0]x_center = (x1 + x2) / 2 / im_wy_center = (y1 + y2) / 2 / im_hwidth = (x2 - x1) / im_wheight = (y2 - y1) / im_hif width < 0 or height < 0:print("error!")f_txt.write("%s %s %s %s %s " % (0, round(x_center, 6), round(y_center, 6), round(width, 6), round(height, 6)))for p in e[1:]:p1_x, p1_y = pp1_xx = p1_x / im_wp1_yy = p1_y / im_hf_txt.write("%s %s %s " % (round(p1_xx, 6), round(p1_yy, 6), 2))f_txt.write("\n")else:x1, y1, x2, y2 = e[0]x_center = (x1 + x2) / 2 / im_wy_center = (y1 + y2) / 2 / im_hwidth = (x2 - x1) / im_wheight = (y2 - y1) / im_hf_txt.write("%s %s %s %s %s " % (1, round(x_center, 6), round(y_center, 6), round(width, 6), round(height, 6)))for p in e[1:-1]:p1_x, p1_y = pp1_xx = p1_x / im_wp1_yy = p1_y / im_hf_txt.write("%s %s %s " % (round(p1_xx, 6), round(p1_yy, 6), 2))f_txt.write("\n")f_txt.close()def processJsonFile( json_path , txt_path):obj = read_jsonfile( json_path )shape_data = obj["shapes"]im_h = obj["imageHeight"]im_w = obj["imageWidth"]caomei_id, p1_id, p2_id = checkShapeData( shape_data )pos_all = []for d_i , shape_dict in enumerate(shape_data ) :if d_i in caomei_id:pt_temp = shape_dict["points"]cm = getXyXy( pt_temp )temp = [cm, ]temp.append( shape_data[ d_i+1 ]["points"][0] )temp.append(shape_data[d_i + 2]["points"][0] )pos_all.append( temp ) #这里是一条记录elif d_i not in caomei_id and d_i not in p1_id and d_i not in p2_id:stem_pt = shape_data[ d_i ]["points"]stem_box = getXyXy( stem_pt )temp = [stem_box, ]pt1 = [ (stem_box[0]+stem_box[2])/2-1 , stem_box[1]+1 ] # x 中心点, 和 toppt2 = [ (stem_box[0]+stem_box[2])/2+1 , stem_box[3]-1 ] # x 中心点, 和 bottomtemp.append( pt1 )temp.append( pt2 ) #这里也要保持9个temp.append( 1 )pos_all.append( temp )genPosTxt(pos_all, txt_path, im_h, im_w)if __name__=="__main__":img_r = r"all"save_r = "pos_txt"for json_n in os.listdir( img_r ):if "json" not in json_n:continuejson_path = os.path.join( img_r , json_n )save_path = os.path.join( save_r , json_n.replace("json" , "txt") )processJsonFile( json_path , save_path )在 pos_txt 文件夹中生成所有图片对应的yolo格式 txt 标注文件
(4)制作 images 和 labels 文件夹
在all 同级目录,创建 images 和 labels 文件夹 ,每个文件夹里分别创建 train 文件夹和 val文件夹。运行下面脚本可以把all 中图片 和 pos_txt 中标注文件 ,数量按8比2拷贝过来,完成数据集制作
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 27 17:10:01 2024@author: WIN10
"""import os
import shutil
import randompic_src = r"all"
txt_src = r"pos_txt"thr = 0.8
pic_format = "jpg"pic_dst = r"./"pic_dst_train = os.path.join( pic_dst, "images\\train" )
pic_dst_val = os.path.join( pic_dst, "images\\val" )txt_dst_train = os.path.join( pic_dst, "labels\\train" )
txt_dst_val = os.path.join( pic_dst, "labels\\val" )def main():txt_name_l = []# 遍历文件夹中的所有文件 , 是根据标注文件 txt 去找图片for filename in os.listdir(txt_src):if "class" in filename:continueif filename.endswith('.txt'): # 找到以 .txt 结尾的文件txt_name_l.append( filename )#打乱排序random.shuffle( txt_name_l )train_n = int( thr * len( txt_name_l ))for txt_n in txt_name_l[:train_n]:pic_src_p0 = os.path.join( pic_src , txt_n.replace("txt" , pic_format ) )txt_src_p0 = os.path.join( txt_src , txt_n )pic_train = os.path.join( pic_dst_train , txt_n.replace("txt" , pic_format ) )txt_train = os.path.join( txt_dst_train , txt_n )shutil.copyfile(pic_src_p0 , pic_train )shutil.copyfile(txt_src_p0, txt_train)for txt_n in txt_name_l[train_n:]:pic_src_p0 = os.path.join( pic_src , txt_n.replace("txt" , pic_format ) )txt_src_p0 = os.path.join( txt_src , txt_n )pic_val = os.path.join( pic_dst_val , txt_n.replace("txt" , pic_format ) )txt_val = os.path.join( txt_dst_val , txt_n )shutil.copyfile(pic_src_p0 , pic_val )shutil.copyfile(txt_src_p0, txt_val )if __name__ == "__main__":main()
三、训练
(1)下载好官方yolo11代码文件,修改 ultralytics/cfg/models/11/yolo11-pose.yaml
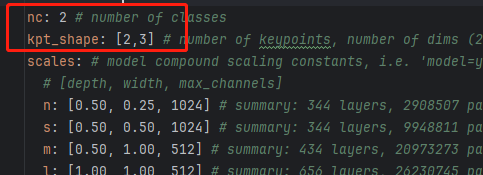
nc 类别改2 kpt_shape 改为 [2,3]
(2)修改 ultralytics/cfg/datasets/caomei_pose.yaml , 自己创建个
内容是:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# Dogs dataset http://vision.stanford.edu/aditya86/ImageNetDogs/ by Stanford
# Documentation: https://docs.ultralytics.com/datasets/pose/dog-pose/
# Example usage: yolo train data=dog-pose.yaml
# parent
# ├── ultralytics
# └── datasets
# └── dog-pose ← downloads here (337 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/Project/StrawberryRecog/datasets/PlasticStrawberriesPose3 # dataset root dir
train: images/train # train images (relative to 'path') 6773 images
val: images/val # val images (relative to 'path') 1703 images# Keypoints
kpt_shape: [2,3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)# Classes
names:0: caomei1: stem# Download script/URL (optional)
#download: https://github.com/ultralytics/assets/releases/download/v0.0.0/dog-pose.zip
(3)训练脚本
在官方代码目录下创建 train_pos.py
import warningswarnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':# 注意 名字上要是yolo11s-pose.yaml 才表示使用的是s , 否则认为用的是nmodel = YOLO('ultralytics/cfg/models/11/yolo11-pose.yaml') model.load('weights/yolo11n.pt') # loading pretrain weights ,需要对应好 n,s m l x model.train(data='ultralytics/cfg/datasets/caomei_pose.yaml',cache=False,imgsz=640,epochs=300,batch=16,device='0',name='exp',)path = model.export(format="onnx", opset=12, dynamic=False, half=False)最后一行是转换为 onxx 文件,便于部署到C++端或C+端等等
四、训练好的权值文件
训练完成后,将得到pt格式权值文件,onnx格式权值文件
五、模型openvino部署
这部分请参考下一篇《yolov8-pos/yolov11-pos openvino C++部署》