如何用Kaggle免费GPU
1. 起因,目的
事情是这样的,我最近对AI绘画和图像识别产生了浓厚的兴趣,想训练一个能区分“好”与“坏”画风的模型。为了追求更高的准确率,我将目光投向了强大的预训练模型库 timm,并从中选择了一位“重量级选手”——DINOv2 Large (vit_large_patch14_reg4_dinov2.lvd142m)。
我满怀信心地在本地搭建好环境,准备开始训练。然而,当我运行脚本的那一刻,现实给了我沉重一击:我的 12GB 显存瞬间被占满,命令行无情地抛出了 CUDA out of memory 错误。
我的目的很明确:我不想因为硬件限制而放弃使用这个强大的模型。我需要找到一个免费的云端平台,它能提供足够强大的GPU资源,让我顺利完成这次模型训练。
经过一番探索,我将目光锁定在了数据科学竞赛平台 Kaggle。它不仅提供免费的计算资源,其GPU的配置甚至超出了我的预期!这便是我利用Kaggle解决本地硬件瓶颈的完整记录。
2. 先看效果
话不多说,先上最终在Kaggle上成功运行的截图。这正是我在本地无法实现的场景:
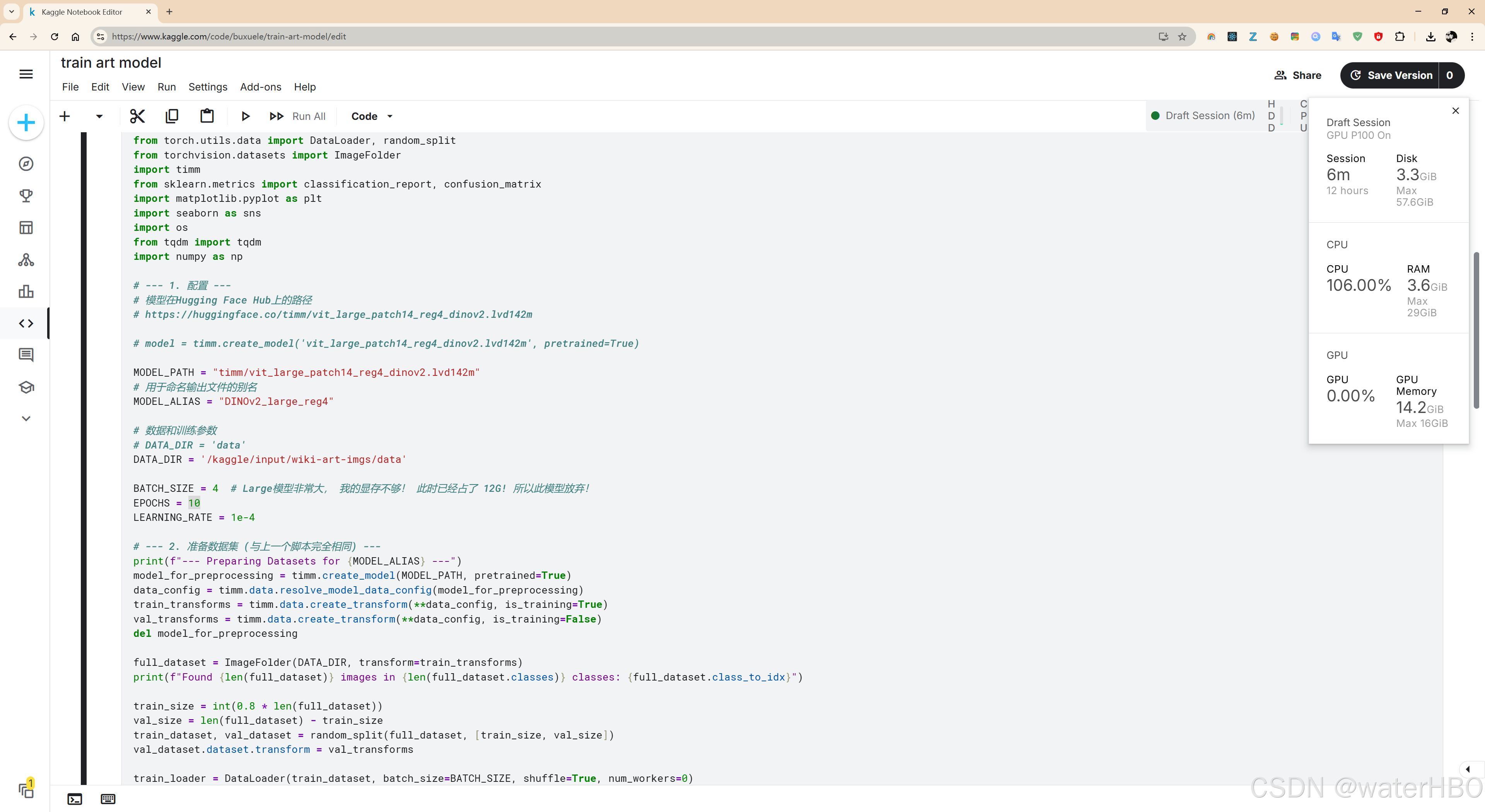
从图中可以看到,我们成功地在Kaggle提供的免费 Tesla P100 GPU 上运行了训练任务。右侧的资源监控显示,显存占用一度高达 14.2GB,这完美解释了为什么我本地的 12GB 显卡会“爆显存”。Kaggle的强大资源,让这一切成为可能。
3. 过程
下面,我将详细拆解整个操作过程,从准备数据到修改代码,再到最终在本地进行预测。
### 步骤一:本地的准备工作(至关重要)
为了将我们的图片数据上传到Kaggle,最高效的方式是先将其打包。
找到你本地存放图片的 `data` 文件夹(里面应该包含 `good` 和 `bad` 两个子文件夹),将它压缩成一个 `data.zip` 文件。
### 步骤二:Kaggle平台的设置
1. **创建Notebook并开启GPU**:登录Kaggle,点击 "Create" -> "New Notebook"。在右侧的 "Settings" 面板中,找到 "Accelerator" 选项,选择 "GPU"。通常你会获得 P100 或 T4 两种强大的GPU。
2. **上传数据集**:在右侧面板切换到 "Data" 选项卡,点击 "+ Add Data",然后选择 "Upload Dataset"。将你准备好的 `data.zip` 上传。上传成功后,你的数据路径会变成类似 `/kaggle/input/your-dataset-name/data` 的形式。
### 步骤三:代码适配与训练(关键)
这一步是核心。我们需要将本地的训练代码粘贴到Kaggle Notebook中,并进行关键的修改,使其适应云端环境。
代码 1: 适配Kaggle环境的完整训练脚本
这份代码已经根据Kaggle的环境做好了修改。你只需复制粘贴,并修改 DATA_DIR 为你自己的数据路径即可运行。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import ImageFolder
import timm
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import os
from tqdm import tqdm
import numpy as np# --- 1. 配置 ---
MODEL_PATH = "timm/vit_large_patch14_reg4_dinov2.lvd142m"
MODEL_ALIAS = "DINOv2_large_reg4"# --- [Kaggle 修改 1]: 修改数据路径和训练参数 ---
# !!! 将 'your-dataset-name' 替换为你自己在Kaggle上上传时的数据集名称 !!!
DATA_DIR = '/kaggle/input/your-dataset-name/data' # 在Kaggle P100(16GB)上,我们可以使用更大的批量,加速训练
BATCH_SIZE = 8
EPOCHS = 10
LEARNING_RATE = 1e-4
# 在Kaggle上使用多核CPU加载数据
NUM_WORKERS = 2 # 检查路径是否存在,避免低级错误
if not os.path.exists(DATA_DIR):raise FileNotFoundError(f"Kaggle data directory not found: {DATA_DIR}")# --- 2. 准备数据集 ---
print(f"--- Preparing Datasets for {MODEL_ALIAS} ---")
model_for_preprocessing = timm.create_model(MODEL_PATH, pretrained=True)
data_config = timm.data.resolve_model_data_config(model_for_preprocessing)
train_transforms = timm.data.create_transform(**data_config, is_training=True)
val_transforms = timm.data.create_transform(**data_config, is_training=False)
del model_for_preprocessing # 及时释放显存full_dataset = ImageFolder(DATA_DIR, transform=train_transforms)
print(f"Found {len(full_dataset)} images in {len(full_dataset.classes)} classes: {full_dataset.class_to_idx}")train_size = int(0.8 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
val_dataset.dataset.transform = val_transforms# --- [Kaggle 修改 2]: 更新 DataLoader 以使用多核与pin_memory ---
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=True)
print("Datasets and DataLoaders are ready.")# --- 3. 模型构建 ---
print(f"\n--- Building {MODEL_ALIAS} Model ---")
num_classes = len(full_dataset.classes)
model = timm.create_model(MODEL_PATH, pretrained=True, num_classes=num_classes)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
print(f"Model built for {num_classes} classes and moved to {device}.")# --- 4. 训练 ---
print(f"\n--- Starting Fine-tuning for {MODEL_ALIAS} ---")
# 此处省略了原有的训练循环、评估、保存模型等代码,它们与本地版本完全相同
# ... 完整的训练和评估循环 ...
# 训练完成后,模型会被保存在 /kaggle/working/ 目录下
# 你可以从右侧的 "Data" -> "Output" 面板下载 .pth 文件
print("\nTraining and evaluation complete!")
### 步骤四:下载成果并在本地进行预测
当Kaggle上的训练完成后,你就可以下载训练好的模型文件(例如 `DINOv2_large_reg4_finetuned_best.pth`)到本地。
一个关键问题是:我本地 12GB 的显存能运行这个模型进行**预测**吗?
答案是:**极有可能可以!** 因为预测(Inference)比训练(Training)消耗的显存要少得多,它不需要存储梯度和优化器状态。
我们需要修改本地的预测脚本来加载新模型。
代码 2: 在本地运行的预测脚本
这个脚本用于对新图片进行自动分类,它加载了我们在Kaggle上训练好的模型。
import torch
import timm
from PIL import Image
import os
import shutil
from tqdm import tqdm# --- 1. 配置 (加载我们在Kaggle上训练好的模型) ---
# [本地修改 1]: 确保模型架构和权重路径正确
MODEL_PATH = "timm/vit_large_patch14_reg4_dinov2.lvd142m" # 必须和训练时一致
MODEL_WEIGHTS_PATH = "DINOv2_large_reg4_finetuned_best.pth" # 从Kaggle下载的文件# 输入和输出文件夹名称
INPUT_DIR = "new_images_to_predict"
OUTPUT_GOOD_DIR = "pred_good"
OUTPUT_BAD_DIR = "pred_bad"# 类别标签 (必须和训练时一致: {'bad': 0, 'good': 1})
CLASS_NAMES = ['bad', 'good']# --- 2. 模型构建与加载 ---
print("--- Loading the fine-tuned model ---")
model = timm.create_model(MODEL_PATH, pretrained=False, num_classes=len(CLASS_NAMES))
try:model.load_state_dict(torch.load(MODEL_WEIGHTS_PATH))
except FileNotFoundError:print(f"FATAL ERROR: Model weights '{MODEL_WEIGHTS_PATH}' not found.")exit()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval() # 切换到评估模式
print(f"Model loaded successfully on {device}.")# [本地修改 2]: 确保使用了 torch.no_grad(),这是低显存预测的关键
with torch.no_grad():# ... 此处省略了原有的文件遍历、图片预处理、预测和移动文件的代码 ...# ... 它与你提供的 step3_predict.py 脚本逻辑一致 ...print("Prediction process complete.")
4. 结论 + todo
通过这次实践,我深刻体会到了云平台的强大之处。
结论:
- 硬件不再是瓶颈:当本地硬件不足以支撑你的雄心壮志时,像Kaggle这样的免费云平台是绝佳的解决方案。
- Kaggle资源慷慨:每周30小时的GPU配额、高达16GB显存的P100 GPU,足以应对绝大多数个人项目和学术研究。
- 适配是关键:从本地迁移到云端,核心工作就是修改文件路径和根据更强的硬件调整训练参数(如
BATCH_SIZE)。 - 分清训练与预测:训练时的高显存占用不代表预测时也如此。在本地设备上对云端训练好的大模型进行推理是完全可行的。
Todo (后续可探索的方向):
- 探索多GPU训练:Kaggle还提供
T4 x2的选项,可以尝试修改代码使用nn.DataParallel来进一步加速训练。 - 超参数调优:在解决了硬件问题后,可以更专注于调整学习率、优化器、训练周期等超参数,以获得更好的模型性能。
- 尝试更多模型:
timm库是一个巨大的宝藏,可以继续尝试其他有趣的大模型。