python网络爬虫(第一步:网络爬虫库、robots.txt规则(防止犯法)、查看获取网页源代码)
python网络爬虫(第一步:网络爬虫库、robots.txt规则(防止犯法)、查看获取网页源代码)
(学习第二步在这里)
python网络爬虫(第二步:安装浏览器驱动,驱动浏览器加载网页、批量下载资源)-CSDN博客
网络爬虫库
-
urllib库
作为Python内置的标准HTTP库,urllib提供了基础的网络请求功能。其优势在于无需额外安装,适合快速验证性开发或受限环境使用。但由于API设计较为底层,处理复杂请求时需要编写更多样板代码,开发效率相对较低。 -
requests库
这个广受欢迎的第三方库在urllib基础上进行了高层封装,提供了更符合Python风格的API设计。支持会话保持、自动编解码等高级特性,大幅提升了开发效率。其简洁的语法和丰富的文档使其成为日常爬虫开发的首选工具。 -
scrapy框架
这是一个专业级的爬虫框架,采用完整的架构设计。不仅支持高性能的并发爬取,还内置了数据处理管道、中间件系统等企业级功能。适合构建复杂的分布式爬虫系统,学习曲线相对较陡但扩展性极强。 -
selenium工具
通过浏览器自动化技术,selenium能够完美处理动态渲染的网页内容。虽然执行效率较低,但在需要模拟用户操作或破解反爬机制时具有不可替代的优势。除了爬虫应用,还广泛用于Web自动化测试领域。
robots.txt规则(防止犯法)
robots.txt 是网站用来指导搜索引擎爬虫(如 Googlebot、Baiduspider)如何抓取网站内容的文本文件,遵循 Robots 排除协议(REP)。它放置在网站的根目录(如 https://example.com/robots.txt),供爬虫在访问其他页面前优先读取。
基本规则
-
User-agent-
指定规则适用的爬虫名称,
*表示所有爬虫。 -
示例:
User-agent: Googlebot # 仅对谷歌爬虫生效 User-agent: * # 对所有爬虫生效
-
-
Disallow-
禁止爬虫访问的路径(支持通配符
*)。 -
示例:
Disallow: /private/ # 禁止访问 /private/ 目录 Disallow: /tmp/*.html # 禁止所有 /tmp/ 下的 .html 文件
-
-
Allow-
允许爬虫访问的路径(优先级高于
Disallow)。 -
示例:
Allow: /public/ # 允许访问 /public/ 目录 Allow: /search/ # 允许访问 /search/ 路径
-
-
Sitemap-
指定网站的站点地图(XML格式)位置,帮助爬虫发现内容。
-
示例:
Sitemap: https://example.com/sitemap.xml
-
常见规则示例
1. 禁止所有爬虫访问全站
User-agent: *
Disallow: /
2. 禁止所有爬虫访问特定目录
User-agent: *
Disallow: /admin/
Disallow: /logs/
3. 针对不同爬虫设置不同规则
User-agent: Googlebot
Allow: /news/
Disallow: /draft/
User-agent: Baiduspider
Disallow: /
4. 允许爬虫访问部分动态参数页面
User-agent: *
Allow: /search?q=*
Disallow: /search?*&private=*
如果网站没有robots.txt规则,如下:
一般默认允许用户使用爬虫工具访问,但仍要遵循《中华人民共和国网络安全法》
如:人民邮电出版社![]() https://www.ptpress.com.cn/robots.txt
https://www.ptpress.com.cn/robots.txt
如果网站有robots.txt规则(以b站为例):
bilibili.com/robots.txt![]() https://www.bilibili.com/robots.txt
https://www.bilibili.com/robots.txt
所有爬虫通用规则(针对所有爬虫)
-
禁止访问的路径
-
Disallow: /medialist/detail/
屏蔽所有爬虫访问/medialist/detail/目录下的内容(如某些媒体详情页)。 -
Disallow: /index.html
禁止抓取根目录下的index.html文件。
-
-
最终兜底规则
-
最后的
User-agent: *+Disallow: /
优先级最高,表示未明确允许的其他爬虫将完全禁止访问整个网站(之前单独允许的爬虫除外)。
-
针对特定爬虫的例外规则
以下爬虫被单独允许访问全站(不受最终 Disallow: / 限制):
-
Yisouspider(神马搜索) -
Applebot(苹果搜索) -
bingbot(微软必应) -
Sogou(搜狗蜘蛛) -
360Spider(360搜索) -
Googlebot(谷歌) -
Baiduspider(百度) -
Bytespider(字节跳动) -
PetalBot(华为花瓣搜索)
社交媒体爬虫的特殊权限
仅允许以下机器人访问 /tbhx/hero 路径(可能是活动页或英雄页面):
-
facebookexternalhit(Facebook) -
Facebot(Facebook) -
Twitterbot(Twitter)
其他路径仍被禁止。

学习查找获取网页源代码
网页空白处右键,点击 “检查”
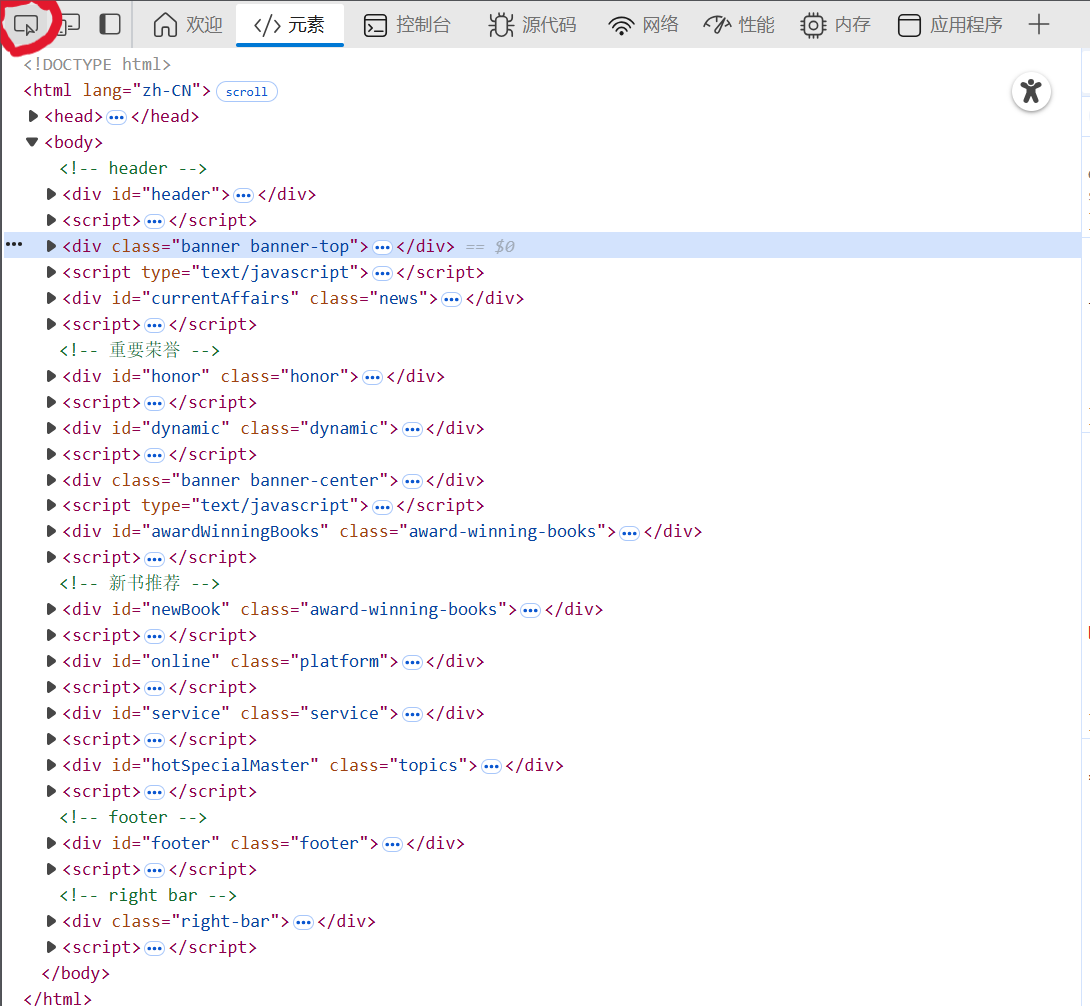
点击左上角的按键
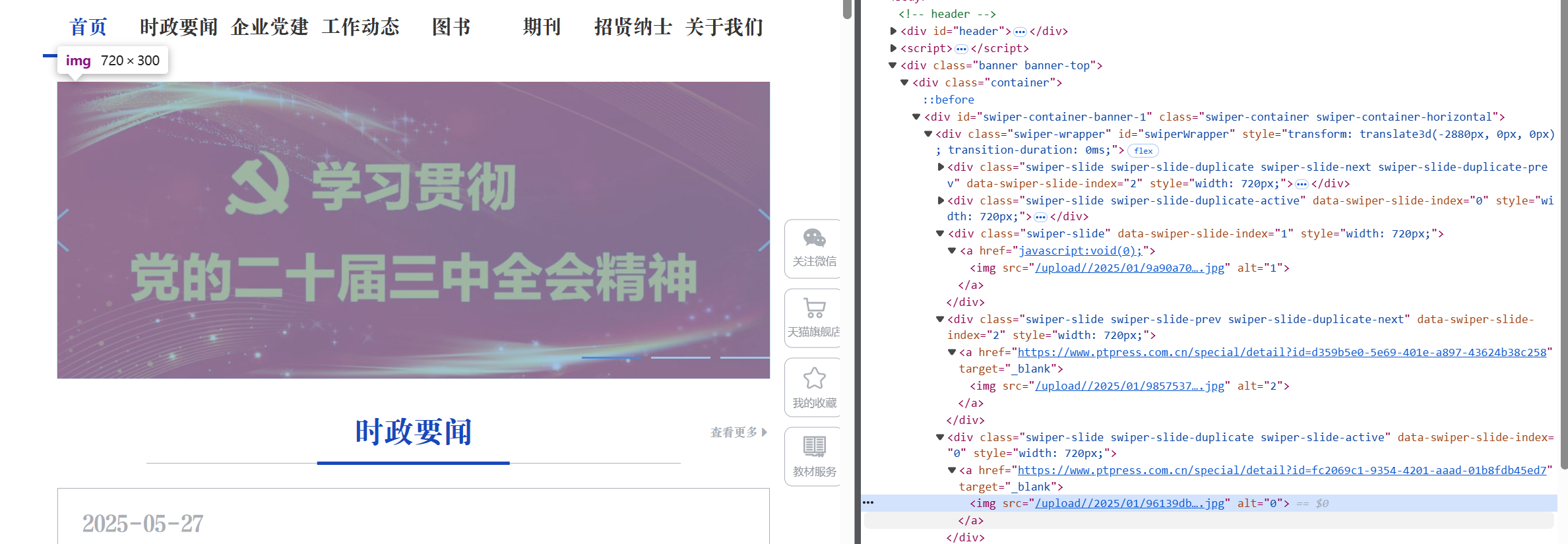
将鼠标移动到页面中需要找的图片或者文本,点击后,右侧会跳转至代码所处位置
双击蓝色标记处,复制路径,或右键复制元素
现在我们来做一些练习吧:
代码 1
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.text)
运行结果:打印出人民邮电出版社官网的 HTML 源代码。
代码解析:该函数使用 requests 库的 get 方法向指定 URL 发送 HTTP GET 请求,获取网页内容并存储在响应对象 r 中,r.text 返回网页的文本内容。
代码 2
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=excel')
print(r.text)
运行结果:打印出人民邮电出版社官网搜索关键词 “excel” 后的搜索结果页面的 HTML 源代码。
代码解析:向指定 URL 发送带关键词参数的 GET 请求,获取搜索结果页面内容。
代码 3
import requests
info ={'keyword':'excel' }
r = requests.get('https://www.ptpress.com.cn/search',params=info)
print(r.text)
print(r.url) #输出:https://www.ptpress.com.cn/search?keyword=excel运行结果:先打印出完整的请求 URL(人民邮电出版社),再打印搜索结果页面的 HTML 源代码。
代码解析:通过 params 参数传递字典形式的查询参数,构建完整请求 URL 并获取响应内容。
代码 4
import requests
r = requests.get('https://www.ptpress.com.cn')
print(r.status_code) #输出:200
if r.status_code==200:print(r.text)
else:print('本次访问失败')
运行结果:先打印 HTTP 状态码(200 表示成功),若成功则打印网页 HTML 源代码,否则打印访问失败提示。
代码解析:通过 status_code 属性判断请求是否成功,并根据结果进行不同处理。
状态码200:请求成功
状态码301:网页内容被永久转移到其他URL
状态码404:请求的网页不存在
状态码500:内部服务器错误
代码 5
import requests
r = requests.get('https://www.baidu.com')
r.encoding = r.apparent_encoding
print(r.text)
运行结果:打印百度首页的 HTML 源代码,确保中文能正常显示。
代码解析:通过 apparent_encoding 属性自动检测网页实际编码,并将其赋值给 encoding 属性,解决中文乱码问题。
代码 6
按上面操作获取一个图片的路径
import requests
r = requests.get('https://cdn.ptpress.cn/uploadimg/Material/978-7-115-41359-8/72jpg/41359.jpg')
f2 = open('b.jpg','wb')
f2.write(r.content)
f2.close()
运行结果:将指定 URL 的图片下载并保存为本地文件 b.jpg。
代码解析:使用 content 属性获取响应的二进制内容(适用于图片、文件等),并以二进制写入模式将内容写入文件。
代码 7
import requests
import re
r = requests.get('https://www.ryjiaoyu.com/tag/details/7')
result = re.findall(r'title=(.+?)">(.+?)</a></h4>',r.text)
for i in range(len(result)):print('第',i+1,'本书: ',result[i][1])
运行结果:打印出网页中匹配正则表达式的书籍标题信息。
代码解析:使用正则表达式从网页文本中提取书籍标题信息,返回一个包含匹配结果的列表,并遍历打印。
学爬虫一定要学正则表达式,很简单,去这里学:
python正则表达式re(Regular Expression)-CSDN博客![]() https://blog.csdn.net/2302_78022640/article/details/149300302?spm=1011.2415.3001.5331
https://blog.csdn.net/2302_78022640/article/details/149300302?spm=1011.2415.3001.5331
以下内容知识点速过
代码 8
'''post 请求'''
import requests
d={'OldPassword':'123python','NewPassword':'123456python','ConfirmPassword':'123456python'}
r = requests.post('https://account.ryjiaoyu.com/change-password', data=d)
print(r.text)
运行结果:打印密码修改页面的响应内容。
代码解析:使用 post 方法向指定 URL 发送包含表单数据的 HTTP POST 请求,用于提交数据(如修改密码)。(看终端)
代码 9
import requests
fp ={"file":open('bitbug.ico','rb')}
r = requests.post('http://httpbin.org/post',files = fp)
print(r.text)
运行结果:打印httpbin.org测试服务返回的包含上传文件信息的响应内容。
代码解析:通过 files 参数上传文件,将本地文件以二进制模式打开并作为请求的一部分发送。(看终端)
代码 10
'''会话'''
import requests
s = requests.Session()
data = {'Email': '15156883862','Password': '123python','RememberMe': 'true','__RequestVerificationToken': 'qh6oY_zP255k2dk83pW5ZNajoAMQD9QxP3tLOK5f54wmccKgzOPCoUhHP5ICO5xlqg2yyLZM_NisZJyOzNszwZcKEteXOInHEv6sW9HlY9Q1'}
r1 = s.post('https://account.ryjiaoyu.com/log-in?returnUrl=https%3a%2f%2fwww.ryjiaoyu.com%2f',data=data)
r2 = s.get('https://www.ryjiaoyu.com/user')
print(r1.text, r2.text)
运行结果:依次打印登录页面和用户页面的响应内容。
代码解析:使用 Session 对象保持会话状态,在登录后可以访问需要权限的页面。
代码 11
'''代理服务器'''
import requests
proxie = {'http':'http://115.29.199.16:8118'}
r = requests.get('https://www.ryjiaoyu.com/',proxies= proxie)
print(r.text)
运行结果:打印通过代理服务器访问网页的响应内容。
代码解析:通过 proxies 参数设置代理服务器,用于隐藏真实 IP 或突破访问限制(爬多了被网站拉黑了)。
代码 12
import requests
import re
def get_Token(s):r0 = s.get('https://account.ryjiaoyu.com/log-in?ReturnUrl=https%3A%2F%2Fwww.ryjiaoyu.com%2Fuser')result = re.findall(r'__RequestVerificationToken(.+)value="(.+)" />', r0.text)return r0,result[0][1]
s = requests.Session()
r0,Token = get_Token(s)
data = {'__RequestVerificationToken':Token,'Email': '15156883862','Password': '123python','RememberMe': 'true'}
r1 = s.post('https://account.ryjiaoyu.com/log-in?returnUrl=https%3a%2f%2fwww.ryjiaoyu.com%2f',data=data)
r2 = s.get('https://www.ryjiaoyu.com/user')
f0 = open('登录前前的网页.html','w',encoding='utf-8')
f1 = open('登录前的网页.html','w',encoding='utf-8')
f2 = open('登录后的网页.html','w',encoding='utf-8')
f0.write(r0.text)
f1.write(r1.text)
f2.write(r2.text)
f0.close()
f1.close()
f2.close()
运行结果:将登录过程中的三个页面内容分别保存为本地 HTML 文件。
代码解析:定义函数获取 CSRF 验证令牌,使用 Session 对象保持会话状态完成登录,并将不同阶段的页面内容保存到文件中。
(学习第二步在这里)
python网络爬虫(第二步:安装浏览器驱动,驱动浏览器加载网页、批量下载资源)-CSDN博客