RocketMQ 高可用集群架构与一致性机制解析
分布式场景中一致性问题:
1.服务器不稳定:随时泵机的可能
2.网络问题:导致请求丢失
3.网速问题:难以保证请求顺序性,最终结果数据一致性需要操作顺序性保证
4.快速响应:不能因为一致性,导致响应以集群中最慢的为准。
常见的算法
弱一致性算法:DNS系统,Gossip协议(Redis Cluster )
强一致性算法:Basic-Paxos、Multi-Paxos包括Raft系列(Nacos的JRaft,Kafka的Kraft以及RocketMQ的Dledger)、ZAB(Zookeeper)
Raft
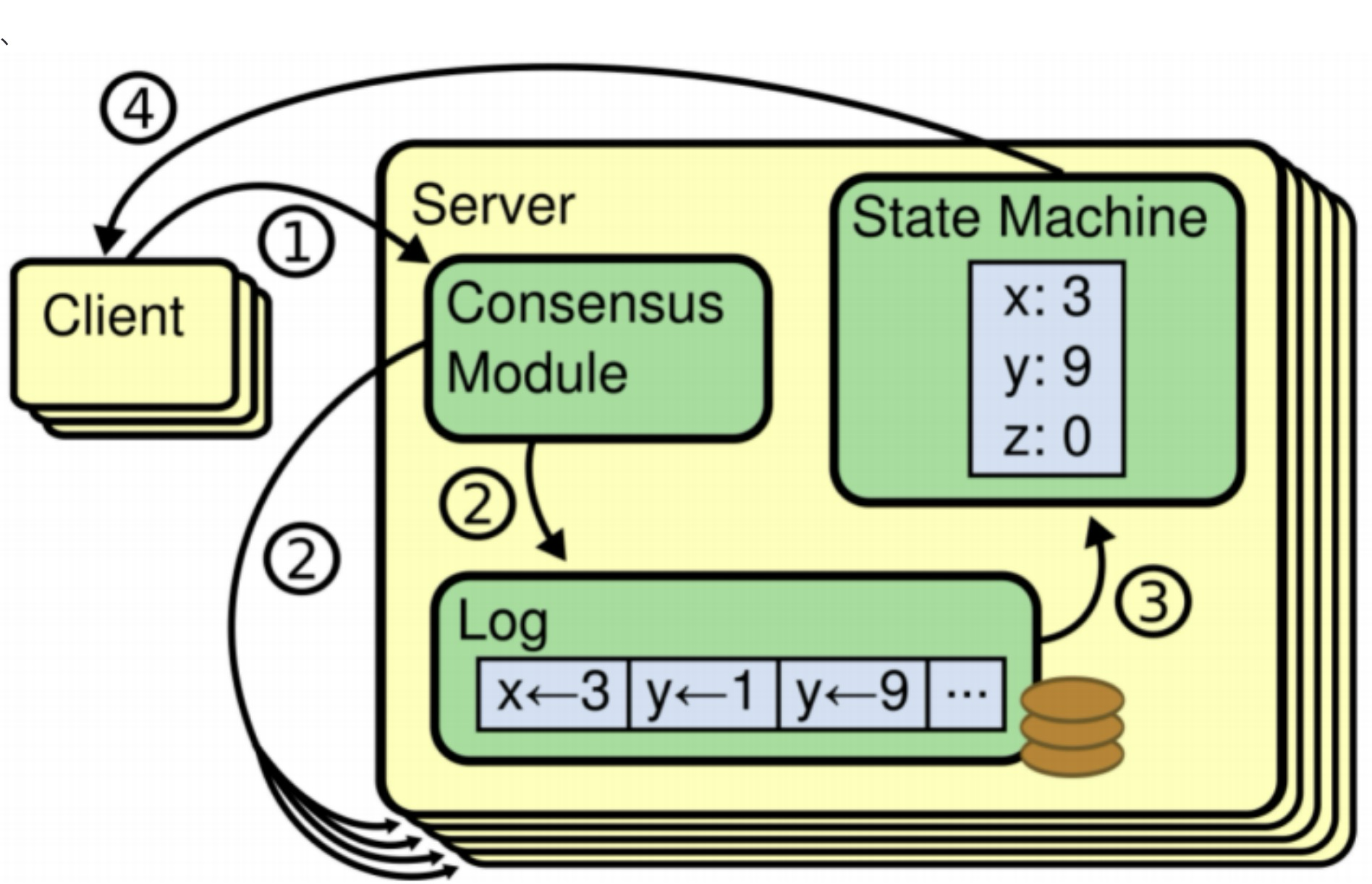
log日志保存在server上的操作日志,每个命令成为Entry,主要是保证Entry的顺序一致,而不是Entry不会丢失(最终一致性),所有的操作最终都会落入State Machine。
工作流程:
1.多个server选举产生leader,负责客户端请求
2.leader通过一致性协议,像节点发送心跳以及客户端命令
3.每个节点将指令保存到log中,此时的uncommit状态
4.当大多数共同保存了Entry,就可以执行指令,保存到State Machine里,此时Entry状态为commit;
需要考虑的点:
角色:Leader、Follower和Candidate
log中的指针,一个是commit节点,一个是Leader往follower里发送后数据的指针
等待时间/超时时间:随机时间150ms到300ms 选举leader用到
脑裂问题:网络波动导致,通过Term任期解决
数据丢失情况:因为要保证只能有一个主节点,因此,脑裂期间,小Term里的数据会丢失。
因此他Raft是CP的。
协议具体实现步骤
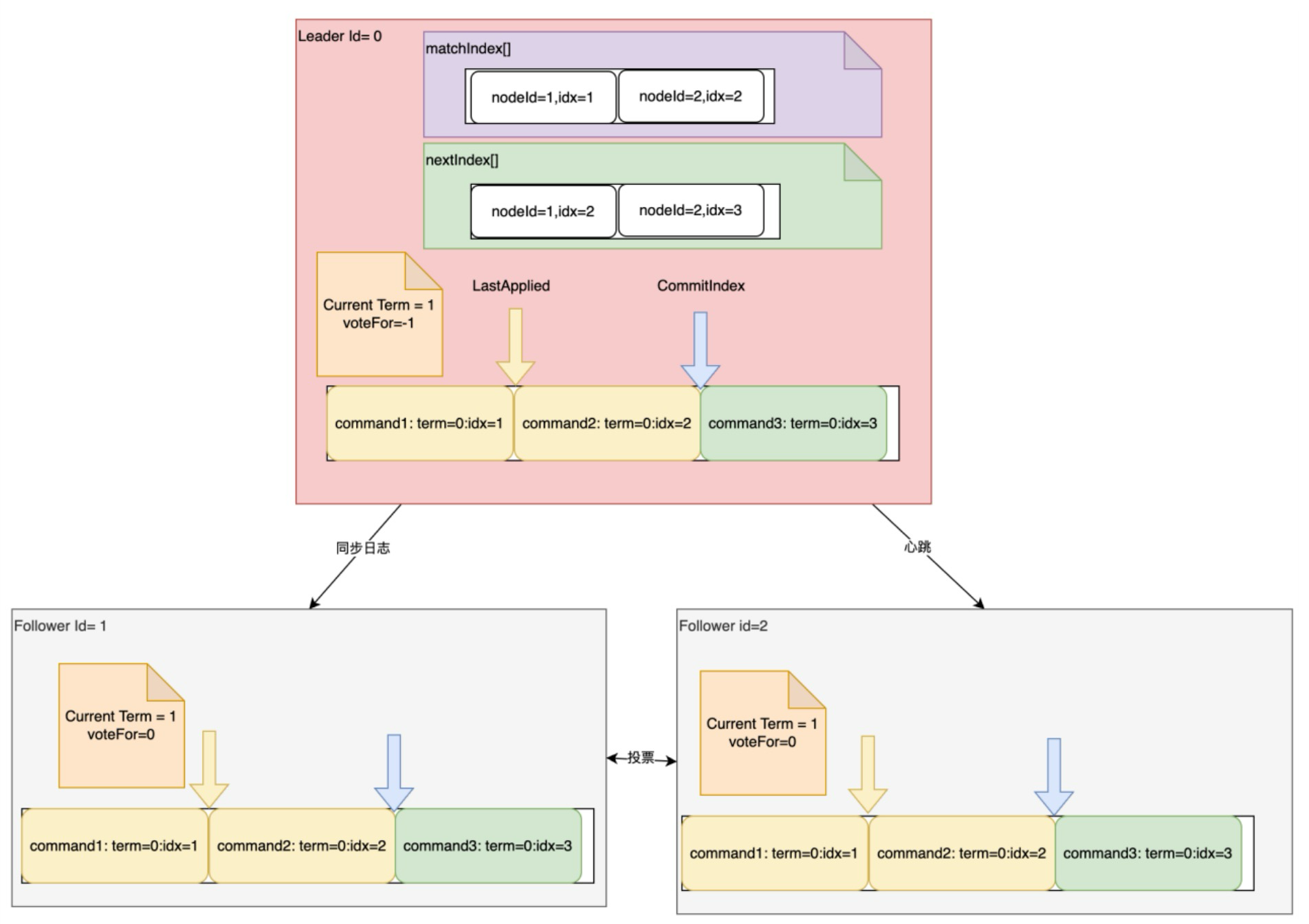
传递时必要数据:
1.voteFor:投票给了谁
2.Current Term:当前的任期
3.logs[]日志entry,以及每个Entry内部的指令、任期、序号ID
4.蓝色箭头:已经commit的指针
5.黄色箭头:同步到的Entry进度
除此之外,leader还要维护matchindex[] 表示提交指针 和 nextIndex[] 表示同步指针
leader选举细节:
term:当前任期
candidateId:投票的候选人ID
lastLogIndex:候选人的最后日志Entry索引
last logo term:候选人最后日志目录的任期号
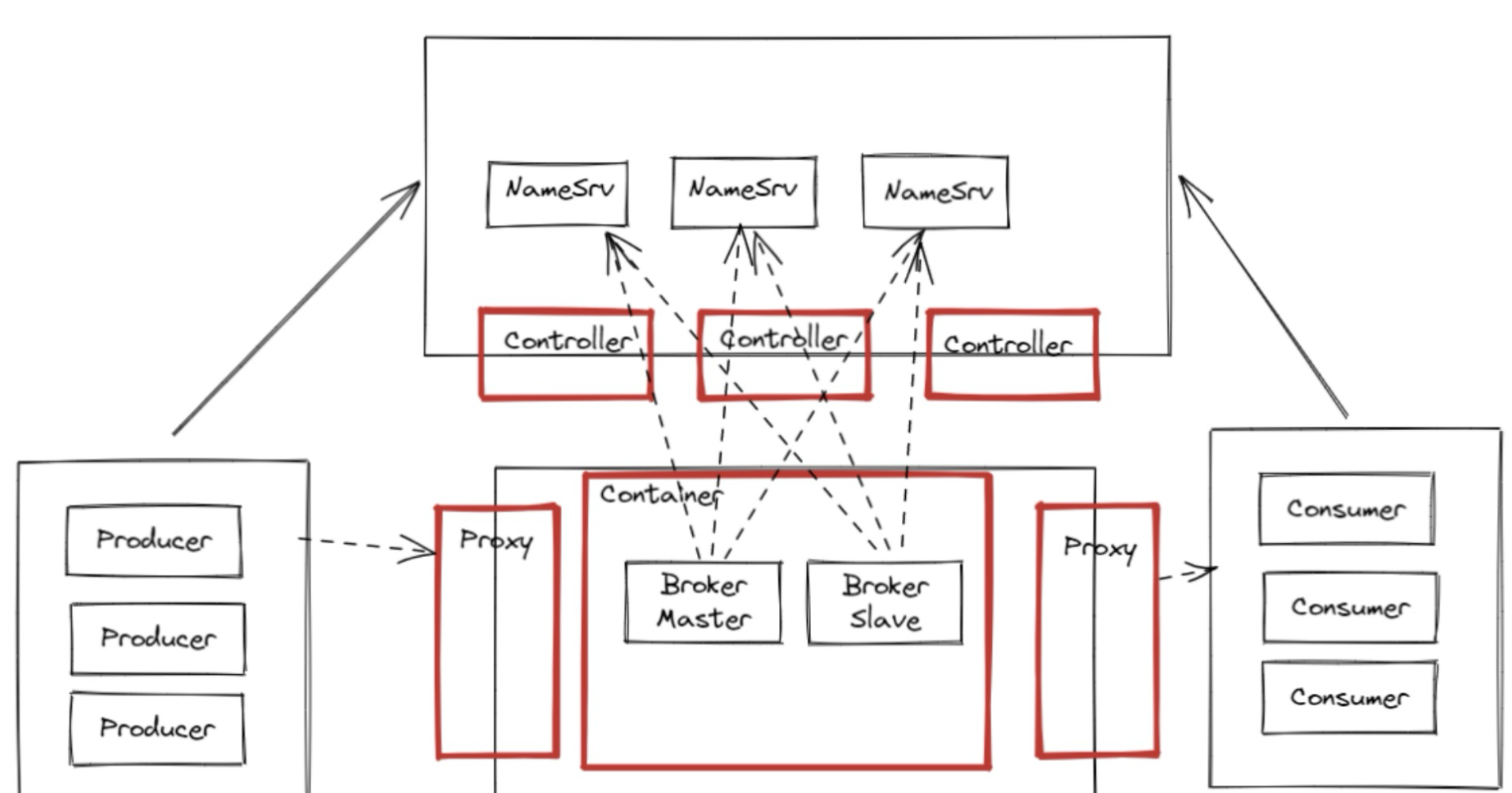
Controller(主从切换的高可用集群)
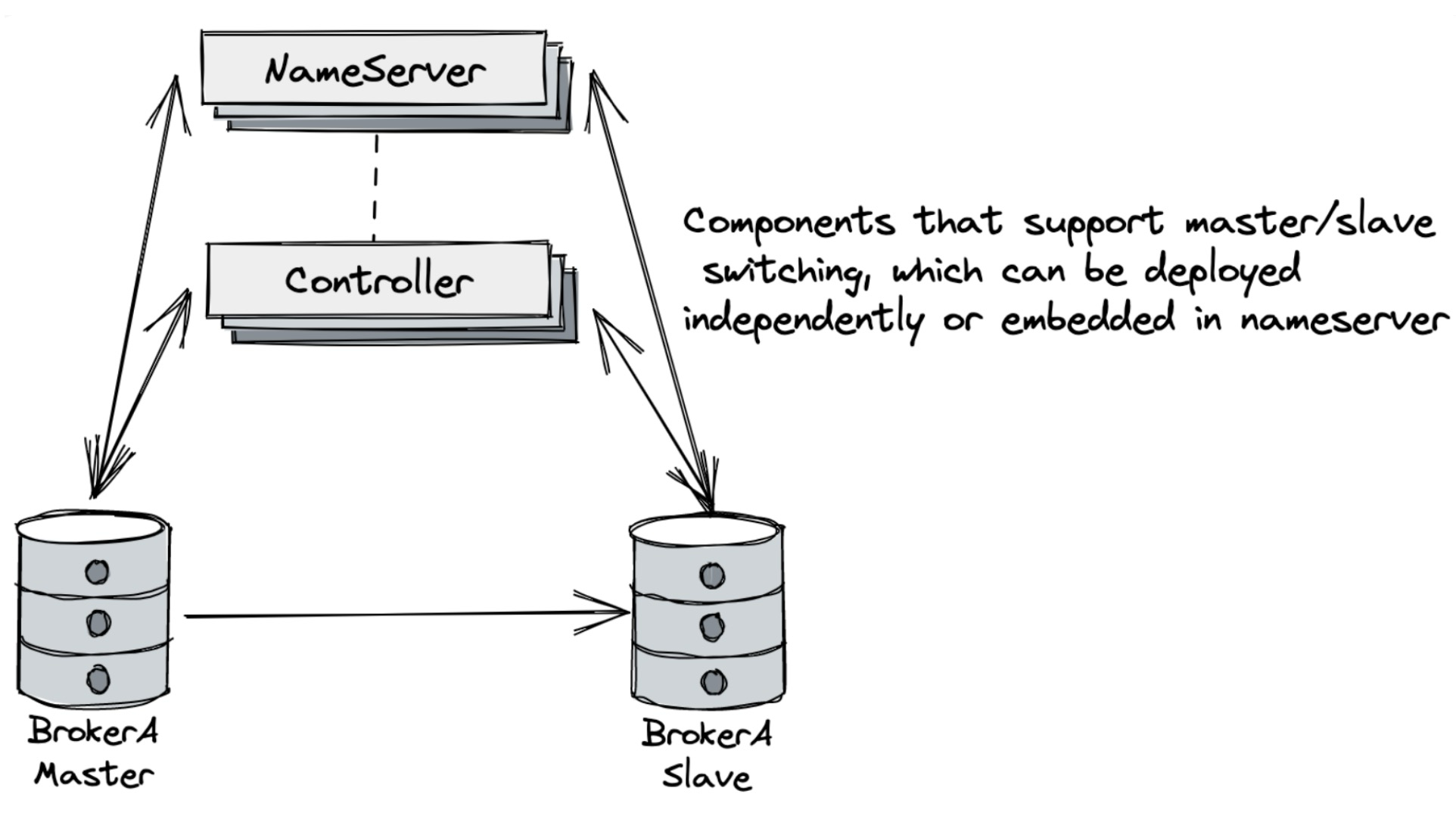
controller只负责主从切换;同步数据是原来主从结构的(sycn和async方式)
为什么用它:解耦,性能高 。 缺点:不能保证强一致性。
部署官网: https://rocketmq.apache.org/zh/docs/deploymentOperations/03autofailover
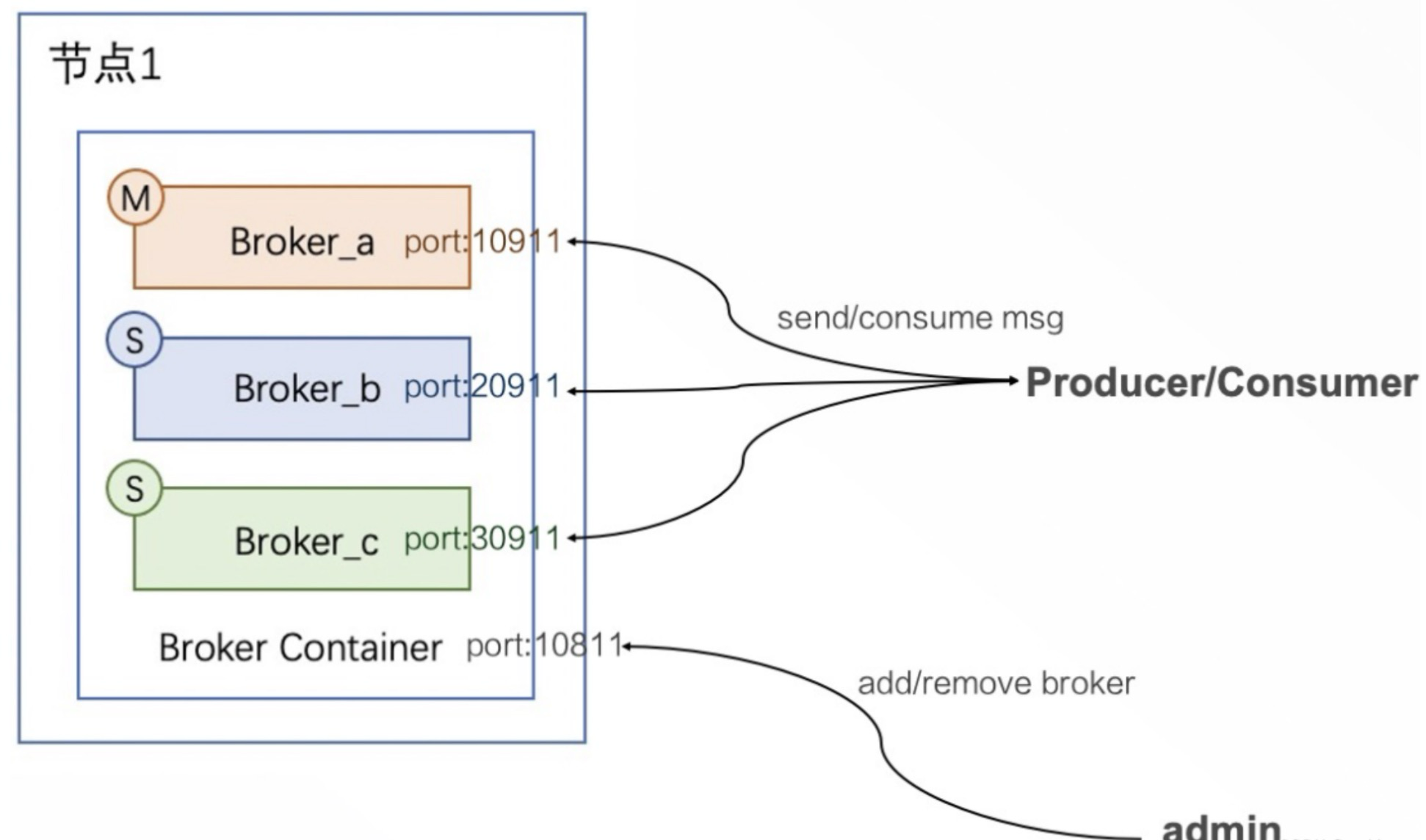
Broker Container容器机制:
5.x版本中提供了新的模式BrokerContainer,一个BrokerContainer进程可以放多个Broker,这些broker可以是Master Broker、Slave Broker、DledgerBroker从而提高整体性能
proxy