【字节跳动】数据挖掘面试题0019:带货直播间推荐:现在有一个带货的直播间,怎么把它精准地推送给有需要的用户
文章大纲
- 带货直播间推荐系统:原理、算法与实践
- 一、推荐系统在带货直播中的重要性
- 二、数据收集与处理
- 1. 用户数据
- 2. 直播间数据
- 3. 用户行为数据
- 4. 数据处理与特征工程
- 三、推荐算法实现
- 1. 基于内容的推荐
- 2. 基于协同过滤的推荐
- 3. 基于知识图谱的推荐
- 4. 混合推荐算法
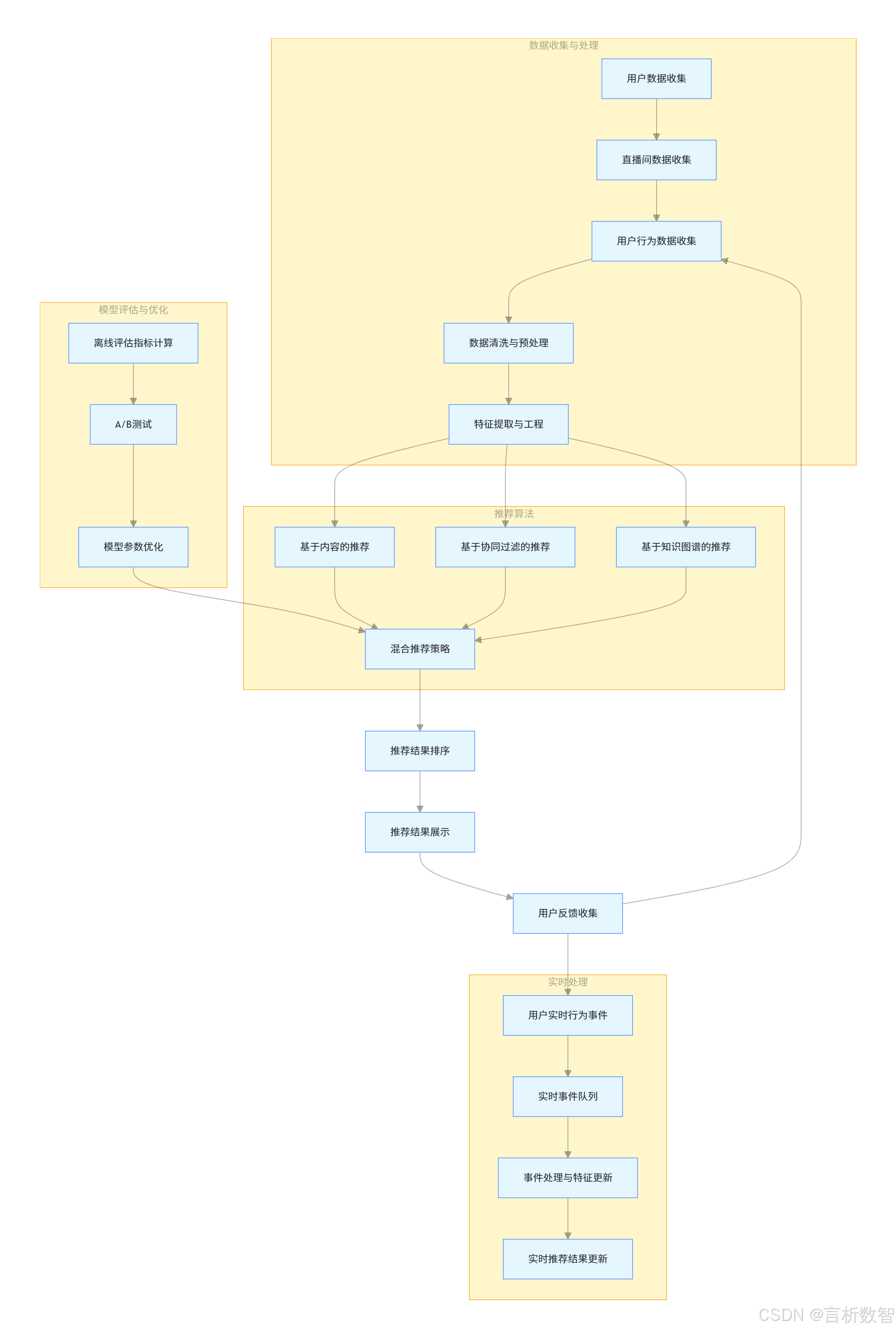
- 四、实时推荐系统架构
- 五、推荐系统评估
- 六、实际应用中的挑战与解决方案
- 1. 冷启动问题
- 2. 实时性要求
- 3. 推荐多样性与准确性的平衡
- 4. 可扩展性问题
- 七、总结与展望
带货直播间推荐系统:原理、算法与实践
在电商直播蓬勃发展的今天,如何将合适的带货直播间精准推送给有需求的用户,成为提升平台转化率和用户体验的关键。
- 本文将深入探讨带货直播间推荐系统的核心原理、算法实现和工程实践,并结合具体代码案例进行详细解析。
一、推荐系统在带货直播中的重要性
- 带货直播作为一种新兴的电商模式,具有实时性、互动性强的特点。
- 但同时也面临信息过载的问题:平台上的直播间数量众多,内容和品类丰富多样,用户很难快速找到符合自己兴趣和需求的直播间。
推荐系统通过分析用户行为和偏好,能够为每个用户提供个性化的直播间推荐,帮助用户发现感兴趣的内容,提高直播观看时长和商品购买转化率。
一个好的带货直播间推荐系统可以带来以下价值:
- 提高用户粘性和活跃度:通过精准推荐,用户更容易找到感兴趣的直播间,从而增加在平台上的停留时间。
- 提升商品转化率:将用户可能感兴趣的商品直播间推荐给他们,能够有效提高购买意愿。
- 增加主播曝光机会:优质的直播间能够被更多潜在观众发现,提高主播的影响力和收益。
- 优化平台资源分配:帮助平台更好地管理和推荐内容,提高整体运营效率。
二、数据收集与处理
推荐系统的基础是数据。在带货直播间推荐场景中,我们需要收集和处理多种类型的数据,包括用户特征、直播间特征和用户行为数据。
1. 用户数据
用户数据包括用户的基本信息和兴趣偏好,例如:
import pandas as pd
import numpy as np
from datetime import datetime# 模拟用户数据
def generate_user_data(num_users=1000):"""生成模拟的用户数据"""user_ids = [f"user_{i}" for i in range(1, num_users + 1)]genders = np.random.choice(['男', '女'], size=num_users)ages = np.random.randint(18, 60, size=num_users)locations = np.random.choice(['北京', '上海', '广州', '深圳', '杭州', '成都', '其他'], size=num_users)interests = np.random.choice(['服装', '美妆', '数码', '家电', '食品', '母婴', '家居', '运动'], size=num_users)user_data = pd.DataFrame({'user_id': user_ids,'gender': genders,'age': ages,'location': locations,'interest': interests})return user_data
2. 直播间数据
直播间数据描述了 每个直播间的特征,例如直播类别、主播信息、直播时间和商品价格等:
# 模拟直播间数据
def generate_live_data(num_lives=200):"""生成模拟的直播间数据"""live_ids = [f"live_{i}" for i in range(1, num_lives + 1)]categories = np.random.choice(['服装', '美妆', '数码', '家电', '食品', '母婴', '家居', '运动'], size=num_lives)anchors = [f"主播_{i}" for i in range(1, num_lives + 1)]start_times = [datetime.now() + pd.Timedelta(hours=np.random.randint(0, 24), minutes=np.random.randint(0, 60)) for _ in range(num_lives)]expected_durations = np.random.randint(1, 6, size=num_lives) # 直播时长(小时)product_prices = np.random.uniform(10, 1000, size=num_lives) # 平均产品价格live_data = pd.DataFrame({'live_id': live_ids,'category': categories,'anchor': anchors,'start_time': start_times,'expected_duration': expected_durations,'product_price': product_prices})return live_data
3. 用户行为数据
用户行为数据记录了 用户与直播间的交互历史,是推荐系统的核心数据:
- 用户对直播间的兴趣程度,结合用户兴趣和直播间类别,如果用户兴趣与直播间类别匹配,兴趣分数更高。
- 价格因素,假设用户对价格有不同偏好
- 地理位置因素
- 综合兴趣分数:
score = interest_score * 0.5 + price_score * 0.3 + location_match * 0.2
# 模拟用户历史行为数据
def generate_user_behavior_data(user_data, live_data, num_records=5000):"""生成模拟的用户行为数据"""user_ids = user_data['user_id'].tolist()live_ids = live_data['live_id'].tolist()records = []for _ in range(num_records):user_id = np.random.choice(user_ids)live_id = np.random.choice(live_ids)# 用户对直播间的兴趣程度,结合用户兴趣和直播间类别user_row = user_data[user_data['user_id'] == user_id].iloc[0]live_row = live_data[live_data['live_id'] == live_id].iloc[0]# 如果用户兴趣与直播间类别匹配,兴趣分数更高interest_score = 0.8 if user_row['interest'] == live_row['category'] else 0.2# 价格因素,假设用户对价格有不同偏好price_preference = np.random.choice(['低', '中', '高'])if (price_preference == '低' and live_row['product_price'] < 100) or \(price_preference == '中' and 100 <= live_row['product_price'] < 500) or \(price_preference == '高' and live_row['product_price'] >= 500):price_score = 0.7else:price_score = 0.3# 地理位置因素location_match = 0.6 if user_row['location'] == '其他' else 0.3# 综合兴趣分数score = interest_score * 0.5 + price_score * 0.3 + location_match * 0.2# 基于分数决定用户是否会点击或观看直播间clicked = np.random.choice([True, False], p=[score, 1-score])if cl