MySQL索引与事务详解:用大白话讲透核心概念
引言:为什么要学MySQL高级特性?
想象一下,你经营着一家网店,刚开始只有100个用户,简单的SQL查询就能应付。但随着业务增长,用户达到100万,查询突然变慢,订单支付出现重复扣款,这时候就需要深入理解MySQL的高级特性了。
本文将用生活化的例子、直观的图片和可执行的代码,带你彻底搞懂MySQL的核心技术点,包括索引、事务、存储引擎等。即使你是初学者,也能轻松跟上!
一、MySQL架构:数据库的"五脏六腑"
1.1 数据库就像一家餐厅
如果把MySQL比作一家餐厅:
- 连接层:门口的接待员,负责迎接顾客(客户端连接)并核对身份(权限验证)
- 服务层:后厨的厨师团队,负责解析订单(SQL语法分析)、优化烹饪流程(查询优化)
- 引擎层:不同的烹饪设备(如烤箱、炒锅),负责实际处理食材(数据存储和提取)
- 存储层:食材仓库,负责保存所有原材料(物理文件存储)
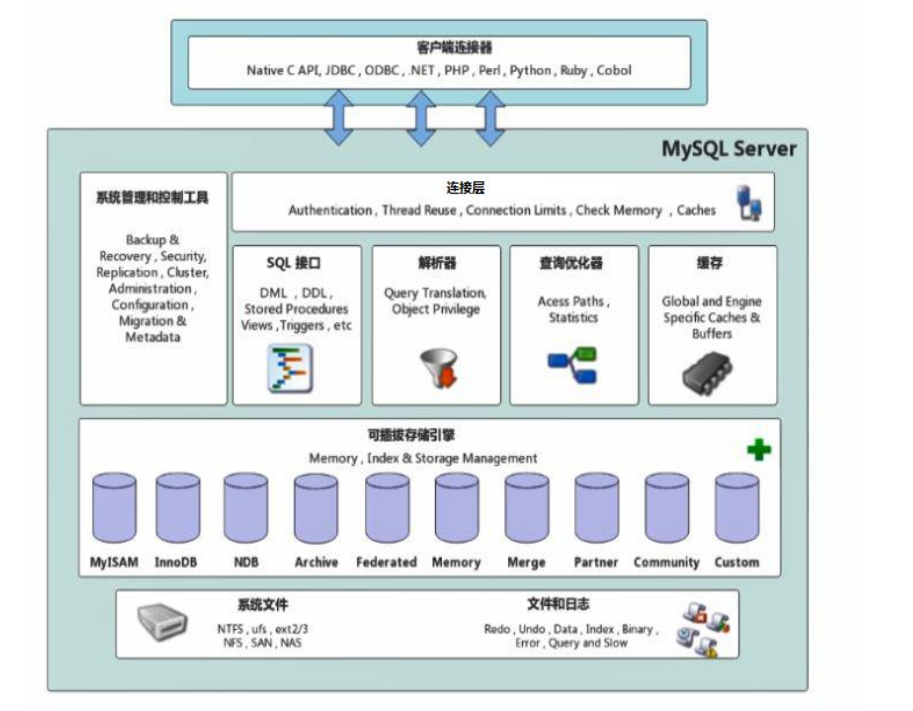
1.2 关键组件的作用
- 查询缓存:就像厨师记住常客的订单,重复的查询可以直接返回结果(MySQL 8.0已移除,改用应用层缓存)
- 优化器:决定最佳烹饪步骤,比如先切菜还是先炒菜(选择最优索引和执行计划)
- 存储引擎:不同的烹饪设备擅长不同菜式,比如InnoDB适合做"精细小炒"(事务处理),MyISAM适合"大锅饭"(快速查询)
二、存储引擎:选对工具干对事
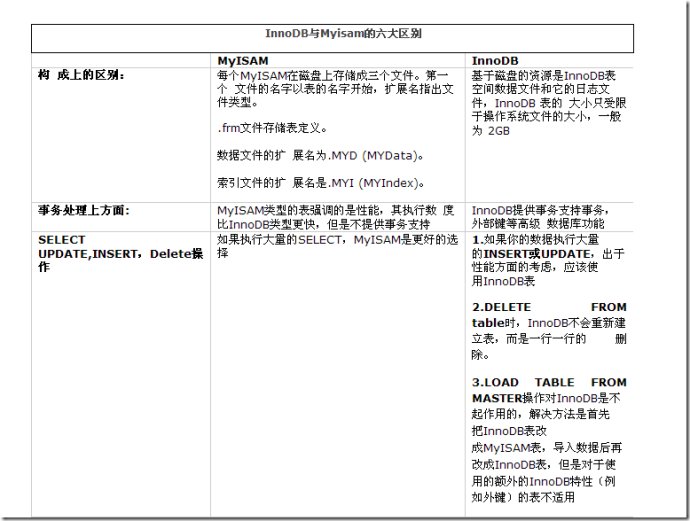
2.1 InnoDB vs MyISAM:两位厨师的较量
| 特性 | InnoDB(精细厨师) | MyISAM(快餐厨师) |
|---|---|---|
| 事务支持 | ✅ 支持(能做复杂套餐) | ❌ 不支持(只能单点) |
| 锁机制 | 行级锁(精准操作) | 表级锁(一锅端) |
| 外键约束 | ✅ 支持(食材搭配检查) | ❌ 不支持(随便搭配) |
| 崩溃恢复 | ✅ 自动修复(打翻盘子能复原) | ❌ 需手动修复(打翻就完蛋) |
| 全文索引 | ✅(MySQL 5.6+) | ✅ |
2.2 什么场景选哪种引擎?
选InnoDB的情况:
- 电商订单系统(需要事务保证支付和库存一致性)
- 社交平台(高并发读写,如同时点赞评论)
- 银行转账(ACID特性确保资金安全)
选MyISAM的情况:
- 个人博客(读多写少,简单查询)
- 日志存储(插入频繁,查询简单)
- 数据仓库(批量导入,很少更新)
代码示例:查看和修改存储引擎
-- 查看表使用的引擎
SHOW TABLE STATUS LIKE 'users';-- 创建表时指定引擎
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50)
) ENGINE=MyISAM;-- 修改表的引擎
ALTER TABLE users ENGINE=InnoDB;
三、索引:数据库的"新华字典"目录
3.1 没有索引会怎样?
想象你要在一本1000页的字典中找"MySQL"这个词,如果没有目录(索引),你需要从第一页翻到最后一页,这就是全表扫描。有了索引,你可以直接定位到"M"开头的页码,这就是索引的作用。
3.2 B+树索引:最常用的"目录结构"
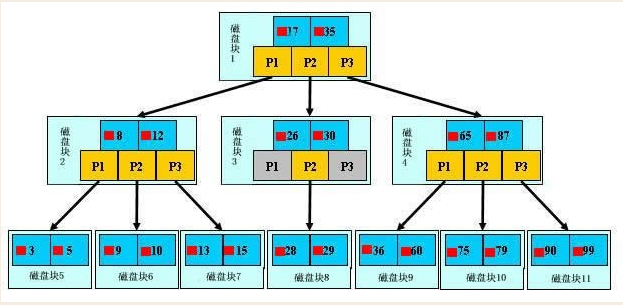
B+树索引就像多层目录:
- 根节点:相当于字典的"部首目录"(最高层索引)
- 叶子节点:实际数据页,所有叶子节点用链表连接(方便范围查询)
- 非叶子节点:只存索引值,不存实际数据(节省空间,提高查询速度)
特点:
- 高度低(通常3-4层),即使数据量很大也能快速定位
- 叶子节点有序且相连,适合范围查询(如
BETWEEN ... AND ...)
3.3索引分类
主键索引:设定为主键后数据库会自动建立索引
ALTER TABLE 表名 add PRIMARY KEY 表名(列名);
删除建主键索引:
ALTER TABLE 表名 drop PRIMARY KEY ;
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
创建单值索引
CREATE INDEX 索引名 ON 表名(列名);
删除索引:
DROP INDEX 索引名;
组合索引(复合索引):
即一个索引包含多个列,在数据库操作期间,复合索引比单值索引所需要的
开销更小(对于相同的多个列建索引),当表的行数远大于索引列的数目时可
以使用复合索引.
创建复合索引:
CREATE INDEX 索引名 ON 表名(列 1,列 2…);
删除索引:
DROP INDEX 索引名 ON 表名;
3.4 索引失效的12个坑(附解决方案)
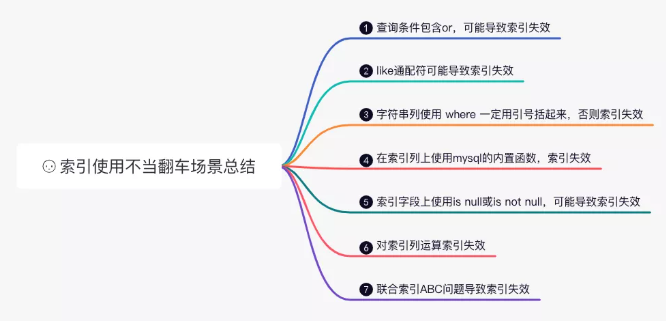
1. 对索引列使用函数
-- 失效
SELECT * FROM orders WHERE YEAR(create_time) = 2023;
-- 优化
SELECT * FROM orders WHERE create_time >= '2023-01-01' AND create_time < '2024-01-01';
2. 隐式类型转换
-- 失效(phone是字符串类型)
SELECT * FROM users WHERE phone = 13800138000;
-- 优化
SELECT * FROM users WHERE phone = '13800138000';
3. LIKE以%开头
-- 失效
SELECT * FROM articles WHERE title LIKE '%MySQL';
-- 优化(使用全文索引)
ALTER TABLE articles ADD FULLTEXT INDEX ft_title(title);
SELECT * FROM articles WHERE MATCH(title) AGAINST('MySQL');
4. OR连接非索引列
-- 失效(age有索引,address无索引)
SELECT * FROM users WHERE age = 25 OR address = '北京';
-- 优化
SELECT * FROM users WHERE age = 25
UNION
SELECT * FROM users WHERE address = '北京';
5. 复合索引不遵循最左前缀原则
-- 索引为(name, age),失效
SELECT * FROM users WHERE age = 25;
-- 优化
SELECT * FROM users WHERE name = '张三' AND age = 25;
当然还有索引失效的例子,我就不一一举例了
3.5回表查询
回表查询是 MySQL 中一种常见的查询现象,它发生在通过索引查询数据时,无法仅依靠索引就获取到所需的全部列数据,需要再次回到数据表中获取完整数据行。
原理
MySQL 中,索引的数据结构一般是 B + 树,普通索引树的叶子节点存储的是索引列值和对应的主键值,聚簇索引(一般是主键索引)的叶子节点直接存储完整的数据行。当使用普通索引进行查询时,如果查询的列不仅包含索引列,还包含其他列,而这些其他列的数据在普通索引中不存在,就需要根据普通索引查到的主键值,再到聚簇索引(也就是数据表本身)中查询完整的数据行,这个过程就叫回表查询。
示例
假设我们有一个students表,结构如下:
CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(50),age INT,INDEX idx_name (name)
);
假设表中已经插入下面3条数据
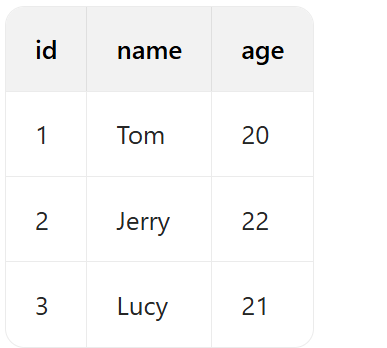
现在执行查询
SELECT id, age
FROM students
WHERE name = 'Tom';
由于name列上有普通索引idx_name,MySQL 会先通过idx_name索引快速定位到name为Tom的记录,在普通索引树中,叶子节点存储的是name列的值和对应的主键id值,所以此时能获取到id的值(假设为1)。
但查询结果还需要age列的值,而age列不在idx_name索引中,因此需要根据获取到的主键id值(这里是1),再到聚簇索引(即数据表本身)中查找id为1的完整数据行,进而获取到age的值,这个第二次从数据表获取数据的过程就是回表查询。
四、事务隔离级别:数据库的"社交距离"
4.1 什么是事务?
事务就像网购下单的过程:
- 选商品→下单→支付→扣库存,这一系列操作必须全部成功或全部失败
- 如果支付成功但库存没扣,会超卖;如果库存扣了但支付失败,会少卖
4.2 并发事务的"社交问题"
当多个事务同时操作数据库,就像多人同时编辑一份文档,会出现以下问题:
脏读:读到别人"草稿"内容
- 事务A:修改了数据但未提交(写了草稿)
- 事务B:读取到事务A的未提交数据(看到草稿)
- 事务A:回滚(删除草稿)
- 事务B:读到的数据是"脏"的(基于草稿做决策)
不可重复读:同一句话前后说的不一样
- 事务A:第一次读数据(听到一句话)
- 事务B:修改并提交数据(改了这句话)
- 事务A:第二次读数据(听到另一个版本)
幻读:数据像"幻觉"一样出现或消失
- 事务A:查询符合条件的记录(数房间里的人)
- 事务B:插入符合条件的新记录(新进来一个人)
- 事务A:再次查询,发现多了一条记录(以为出现幻觉)
你可能会觉得不可重复读和幻读差不多,我给你一句话总结区别
不可重复读:数据被改了(行内容变化),结果是 “同一条数据前后读不一样”。
幻读:数据变多 / 少了(行数量变化),结果是 “符合条件的结果集行数前后不一样”。
4.3 四种隔离级别:设置合适的"社交距离"
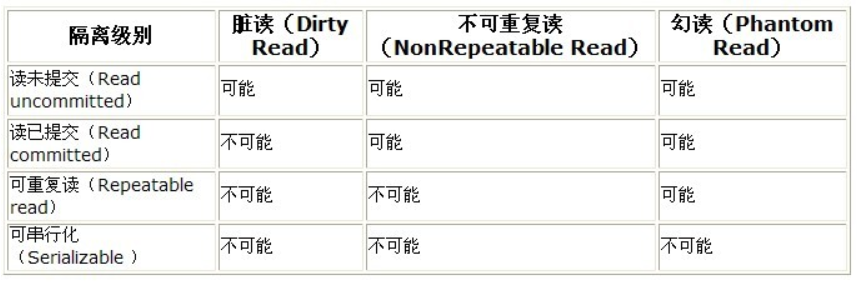
| 隔离级别 | 中文名称 | 防止脏读 | 防止不可重复读 | 防止幻读 | 性能 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | 读未提交 | ❌ | ❌ | ❌ | 最高 |
| READ COMMITTED | 读已提交 | ✅ | ❌ | ❌ | 高 |
| REPEATABLE READ | 可重复读 | ✅ | ✅ | ✅* | 中 |
| SERIALIZABLE | 串行化 | ✅ | ✅ | ✅ | 最低 |
*:MySQL InnoDB通过间隙锁在可重复读级别防止幻读
代码示例:设置和查看隔离级别
-- 查看当前隔离级别
SELECT @@transaction_isolation;-- 设置会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;-- 演示脏读(需在两个窗口执行)
-- 窗口1(事务A)
START TRANSACTION;
UPDATE accounts SET balance = 150 WHERE id = 1; -- 不提交-- 窗口2(事务B,隔离级别设为READ UNCOMMITTED)
START TRANSACTION;
SELECT balance FROM accounts WHERE id = 1; -- 读到150(脏数据)-- 窗口1回滚
ROLLBACK;-- 窗口2再次查询
SELECT balance FROM accounts WHERE id = 1; -- 变回100
4.4 间隙锁:防止"插队"的利器
什么是间隙锁?
当你查询WHERE id BETWEEN 1 AND 10时,InnoDB会锁定(1,10)之间的间隙,防止其他事务插入新记录,就像在图书馆占座,不仅占座位本身,还占旁边的空位。
举例说明:
表中有id=5、10的记录,事务A执行:
SELECT * FROM users WHERE id BETWEEN 5 AND 10 FOR UPDATE;
此时会锁定(5,10)的间隙,事务B尝试插入id=7的记录会被阻塞,直到事务A提交。
五、MySQL 8.0新特性:更强大的"厨房设备"
5.1 降序索引:从大到小排列的目录
以前索引默认升序,要查最新数据需额外排序。现在可以直接创建降序索引:
CREATE INDEX idx_create_time_desc ON orders(create_time DESC);
查询最新订单时,数据库可以直接利用索引,无需额外排序。
5.2 隐藏索引:"备胎"索引
可以暂时隐藏索引而不删除,用于测试性能影响:
-- 隐藏索引
ALTER TABLE users ALTER INDEX idx_username INVISIBLE;-- 恢复索引
ALTER TABLE users ALTER INDEX idx_username VISIBLE;
适合在不影响线上业务的情况下测试索引是否有用。
5.3 函数索引:对"加工后的数据"建索引
以前对索引列使用函数会导致索引失效,现在可以直接对函数结果建索引:
-- 对用户名的大写形式建索引
CREATE INDEX idx_upper_name ON users ((UPPER(username)));-- 查询时可以直接使用
SELECT * FROM users WHERE UPPER(username) = 'ZHANGSAN';
六、实战案例:从慢查询到性能优化
案例:电商商品列表页优化
问题:商品列表页加载慢,执行以下SQL需要2秒:
SELECT * FROM products WHERE category_id = 1 AND price < 100 ORDER BY create_time DESC;
优化步骤:
- 建复合索引:
CREATE INDEX idx_cat_price_time ON products(category_id, price, create_time DESC); - **避免SELECT ***:只查询需要的字段,减少数据传输
- 分页查询:使用
LIMIT限制返回数量
优化后查询时间从2秒降至20毫秒。
附录:索引失效完整场景及解决方案
| 失效场景 | 示例SQL | 优化方案 |
|---|---|---|
| 索引列用函数 | WHERE YEAR(create_time)=2023 | WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31' |
| 隐式类型转换 | WHERE phone=13800138000(phone是字符串) | WHERE phone='13800138000' |
| LIKE以%开头 | WHERE title LIKE '%MySQL' | 使用全文索引MATCH(title) AGAINST('MySQL') |
| OR连接非索引列 | WHERE age=25 OR address='北京' | 拆分为两个SELECT用UNION连接 |
| 复合索引不遵循最左前缀 | WHERE age=25(索引为name,age) | WHERE name='张三' AND age=25 |
| 使用!=或<> | WHERE status!='completed' | WHERE status IN('pending','processing') |
| 索引列参与计算 | WHERE price*0.9=100 | WHERE price=100/0.9 |
| IS NULL/IS NOT NULL | WHERE email IS NULL | 给字段添加NOT NULL约束,用默认值代替NULL |
| 范围查询后列失效 | WHERE age>30 AND salary=5000(索引age,salary) | 调整索引顺序为(salary, age) |
| 数据量太少 | 表只有100行数据 | 小表无需索引,全表扫描更快 |
| 字符集不一致 | 两表JOIN时字符集不同 | 统一字符集为utf8mb4 |
| 参数化查询值分布不均 | WHERE status=?(status大部分为’active’) | 增加条件或使用FORCE INDEX |
看到这里,你已经超越了80%的人,我将MySQL的锁机制与sql优化写在了下一篇MySQL锁机制与sql优化
总结
MySQL高级特性看似复杂,但只要结合生活例子和实际操作,就能轻松理解。关键要记住:
- 索引是"目录",选对索引能让查询飞起来
- 事务是"原子操作",保证数据一致性
- 存储引擎是"工具",不同场景选不同工具
- 隔离级别是"社交距离",平衡一致性和性能
希望本文能帮你彻底搞懂MySQL高级特性,让你的数据库性能提升10倍!