nlp论文:分本分类:《Bag of Tricks for Efficient Text Classification》
文章目录
- 一、论文和代码网址
- 二、代码复现
- 1.Linux系统下拉取代码、编译
- 2.数据集:情感分析
- 3.训练
- 4.评估模型:用训练集评估模型精度
- 5.测试
- 三、代码结构
- 四、模型架构
- 五、fastText模型评价
一、论文和代码网址
论文:https://arxiv.org/pdf/1607.01759v2
代码:https://github.com/facebookresearch/fastText
二、代码复现
1.Linux系统下拉取代码、编译
wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip
unzip v0.9.2.zip
cd fastText-0.9.2
make
2.数据集:情感分析
IMDB 评论25000条:https://ai.stanford.edu/~amaas/data/sentiment/
假设我们要做情感分析任务,任务是根据电影评论判断情感是积极还是消极。那么我们可以准备如下格式的训练数据:
train.txt
__label__positive This movie is fantastic, I loved it!
__label__negative I hated this movie, it was awful.
__label__positive Absolutely amazing, best movie I've seen!
__label__negative Terrible, waste of time.
__label__positive Great movie, will watch again.
__label__negative Didn't enjoy it at all, very boring.
3.训练
修改epoch轮次
vim classification-example.sh
找到-epoch,从5改为20
训练模型命令:
./fasttext supervised -input train_25000.txt -output model./fasttext supervised -input train_25000.txt -output model -lr 0.01 -epoch 300 -dim 300 -neg 10 -loss hs【 loss 0.137】./fasttext supervised -input train_25000.txt -output model -lr 0.05 -epoch 50 -dim 300 -neg 30 -loss ns 【ns:很差】./fasttext supervised -input train_25000.txt -output model -lr 0.1 -epoch 50 -dim 300 -neg 30 -loss hs【 loss 0.111】
最终输出:
Read 5M words
Number of words: 281111
Number of labels: 2
Progress: 100.0% words/sec/thread: 835193 lr: 0.000000 avg.loss: 0.137626 ETA: 0h 0m 0s
4.评估模型:用训练集评估模型精度
./fasttext test model.bin train.txt
./fasttext test model.bin train_25000.txt
./fasttext test model.bin test_label.txt
N 25000
P@1 0.996
R@1 0.996N 107
P@1 0.897
R@1 0.897
5.测试
test.txt
I loved this movie, it was fantastic!
The movie was very boring and predictable.
I didn't enjoy it at all, such a disappointment.
预测命令:
./fasttext predict-prob model.bin train_25000.txt
这将输出每行文本的预测标签。预测结果会以以下格式显示:
__label__positive 0.81732
__label__negative 0.698711
__label__positive 0.999979
__label__positive 0.862
__label__positive 0.999925
__label__positive 0.992208
__label__positive 0.999989
__label__positive 0.910747
__label__positive 0.848151
__label__negative 1.00001__label__positive 1.00001
__label__negative 0.832305
__label__positive 0.999992
__label__negative 0.973684
__label__positive 0.99999
__label__negative 0.965739
三、代码结构
C++辅以Python实现:
1.训练过程:fasttext.cc
(1)train()函数
void FastText::train(const Args& args, const TrainCallback& callback) {
2.模型:model.cc
模型计算与更新:model.cc 中主要处理 隐藏层计算、预测 和 模型参数更新 的过程。每次训练时都会通过 反向传播 来更新模型的 词向量。
3.损失函数:loss.cc
损失函数:loss.cc中实现了多种 损失函数(如负采样、层次化 softmax 和 标准softmax),每个损失函数都有自己的forward方法,负责计算损失并进行反向传播。
四、模型架构
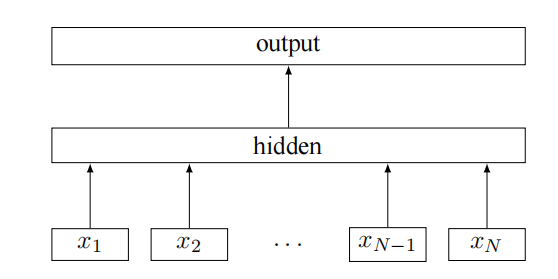
五、fastText模型评价
1.工作原理
(1)词向量
通过词向量(Word Embeddings)的方式来表示每个词。将每个词拆分成了子词(subwords),利用n-gram技术,以更好地处理词形变化(复数形式、时态变化)和生僻词。
(2)线性分类器
fastText 使用一个线性分类器来进行文本分类任务。它会将文本中的所有词的向量表示(或子词的向量)平均起来,得到文本的向量表示,然后通过一个线性分类器(例如 logistic regression)来进行预测。
这种方法非常快速,尤其适合文本分类任务。
2.优势
没有复杂的神经网络,因此对于大规模文本,训练速度很快。
加速训练:
(1)Hierarchical Softmax
(2)负样本(Negative Samples):
负样本是随机从词汇表中选择的 不相关的词汇,这些词不与给定的中心词共同出现在同一上下文中。
例如,在训练 “cat” 的词向量时,负样本可能是从整个词汇表中随机选择的单词 “dog”、“apple”、“car” 等,这些词不与 “cat” 出现在同一上下文中。
3.缺陷
对于双重否定句,无法准确判断。
4.改进:
改用LSTM、GRU、Transformer、BERT等深度学习模型。含有自注意力机制的模型对中长语句的理解能力更强。能更好地处理文本中的长距离依赖和上下文信息,捕捉到更丰富的句法和语义信息。
fastText太轻量级,以至于无法加入早停和Dropout,采用的是负采样和层次化softmax来训练词向量。