kimi-k2模型配置参数
kimi-k2模型配置参数
-
上周kimi推出了万亿级 MoE 大模型 kimi-k2,感觉上一次kimi爆火还是在24年年初200万长上下文的时候,不过着实比较好奇现在都在卷后训练的时代,为什么kimi还是“敢为天下之后”,继续在卷预训练,而且是万亿级别参数的预训练模型?如果你也对此有兴趣,可以看看官方的相关技术博客,目前论文还没出来。
github:
https://moonshotai.github.io/Kimi-K2/
微信公众号:
https://mp.weixin.qq.com/s/2RPmHf_8KqIjXbY5jLdztQ
其设计目标有
高容量 、 激活稀疏、 推理高效、model as agent等等,反正情况就是这么个情况,具体什么情况,那还得看接下来的情况。。。。。。 -
官方的模型概要如下,接下来来看看kimi-k2模型的配置参数 config.json
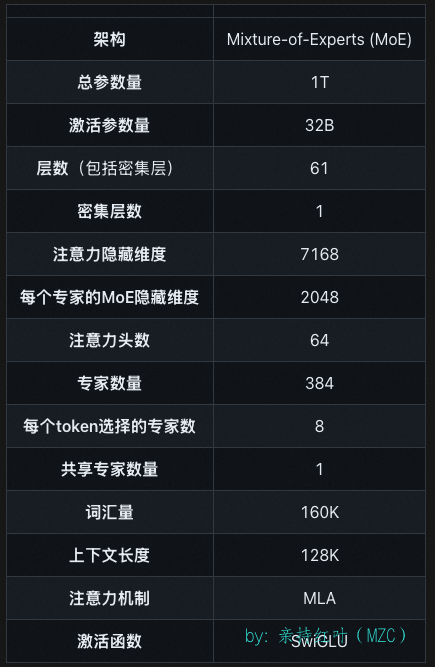
1. 基础信息
| 字段 | 含义 |
|---|---|
"model_type": "kimi_k2" | 固定标识,告诉 transformers 库“这是 Kimi K2 系列”。 |
"architectures": ["DeepseekV3ForCausalLM"] | 代码里复用了 DeepSeek-V3 的建模类,但内部参数已按 K2 需求改动。 |
"vocab_size": 163840 | tokenizer 词表大小(含 163584 个普通词 + 256 个预留控制符)。 |
"bos_token_id": 163584 / "eos_token_id": 163585 | 起始/结束符的 ID。 |
2. 规模与稀疏结构(MoE)
| 字段 | 值 | 备注 |
|---|---|---|
n_routed_experts | 384 | 总共 384 个“路由专家”,每次推理只激活其中 8 个(见下一行)。 |
num_experts_per_tok | 8 | Top-8 专家 参与当前 token 计算。 |
moe_layer_freq | 1 | 每隔 1 层就出现一个 MoE 层(即“层层 MoE”)。 |
n_shared_experts | 1 | 除路由专家外,还有 1 个 始终激活的共享专家。 |
moe_intermediate_size | 2048 | 每个专家的 FFN 中间维度(注意:不是 dense 层的 18432)。 |
3. Dense Transformer
| 字段 | 值 | 解释 |
|---|---|---|
num_hidden_layers | 61 | 共 61 层。 |
hidden_size | 7168 | 模型维度 d_model。 |
intermediate_size | 18432 | 非 MoE 层(即 dense 层)的 FFN 升维后大小。 |
first_k_dense_replace | 1 | 第 0 层是 dense 层(其余层按 moe_layer_freq 决定)。 |
num_attention_heads | 64 | 多头注意力头数。 |
num_key_value_heads | 64 | GQA 未启用(= 头数,等价于 MHA)。 |
4. 注意力机制细节
| 字段 | 值 | 说明 |
|---|---|---|
qk_nope_head_dim | 128 | Q/K 中 无位置编码 部分的维度。 |
qk_rope_head_dim | 64 | RoPE 位置编码附加维度 → 单头总维度 128+64=192。 |
v_head_dim | 128 | V 头维度。 |
attention_dropout | 0.0 | 推理阶段关闭 dropout。 |
attention_bias | false | Q/K/V 投影均 不带 bias(节省显存)。 |
5. 长上下文与 RoPE 缩放
| 字段 | 值 | 说明 |
|---|---|---|
max_position_embeddings | 131072 | 官方支持 128 K 上下文(留一点余量)。 |
rope_theta | 50000 | 基础 RoPE 频率。 |
rope_scaling.type | “yarn” | 使用 YaRN 继续外推到 128 K。 |
rope_scaling.factor | 32 | 外推因子 = 32(4096×32≈131 K)。 |
6. 路由与负载均衡
| 字段 | 值 | 作用 |
|---|---|---|
topk_method | “noaux_tc” | 无辅助 loss 的 top-k 路由,降低实现复杂度。 |
norm_topk_prob | true | 对 top-k 专家的原始 logits 做 softmax 后再加权。 |
aux_loss_alpha | 0.001 | 辅助 loss 权重(极小值,仅作专家负载均衡)。 |
seq_aux | true | 在 序列级别 计算辅助 loss,进一步平滑专家分配。 |
7. 量化与数值精度
| 字段 | 值 | 说明 |
|---|---|---|
quantization_config.quant_method | “fp8” | 官方开源权重使用 FP8量化。 |
weight_block_size | [128,128] | 权重按 128×128 块量化。 |
torch_dtype | “bfloat16” | 推理时可用 bfloat16 反量化运行。 |
8. 其他零碎但常用的字段
| 字段 | 值 | 提示 |
|---|---|---|
hidden_act | “silu” | 激活函数SiLU(即SwiGLUβ=1\beta=1β=1)。 |
rms_norm_eps | 1e-6 | RMS 的 ϵ\epsilonϵ 值。 |
initializer_range | 0.02 | 参数初始化标准差。 |
tie_word_embeddings | false | 词嵌入与 LM Head 不共享权重(总参数量更大)。 |
use_cache | true | 默认启用 KV-Cache 以加速生成。 |