二进制安全-汇编语言-06-包含多个段的程序
六、包含多个段的程序
休息不好,效率不振
这节主要讨论将数据、代码、栈放入不同的段中
6.1 在代码段中使用数据
如果我们考虑将下列8个数据累加,结果存在寄存器ax中:
0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
前面我们都是拿内存中的数据累加,我们也不关注内存中有什么数据。
现在我们要是规定好数据呢?我们应该怎么编写汇编代码呢?
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hmov bx,0mov ax,0mov cx,8
s: add ax,cs:[bx]add bx,2loop smov ax,4c00hint 21hcode ends
end
**dw:**define word 定义字型数据
这里dw定义了8个字型数据(数据之间以逗号隔开),它们所占的内存空间的大小为16个字节
程序中的指令就要对这8个数据进行累加,可这8个数据在哪里呢?
由于它们在代码段中,程序在运行的时候CS中存放代码段的段地址,所以可以从CS中得到它们的段地址。
它们的偏移地址是多少呢?
因为用dw定义的数据处于代码段的最开始,所以偏移地址为0,这8个数据就在代码段的偏移0、2、4、6、8、A、C、E处。
程序运行时,它们的地址就是CS:0、CS:2、CS:4、CS:6、CS:8、CS:A、CS:C、CS:E。
小结:dw一串数据位于代码段的开头,那么CS作为段地址,偏移地址就根据每个数据的大小放在一块连续的地址
由于这些数据的大小相同,且位于一片连续的内存地址,那么我们就可以寻址的方式取数据了。
程序中,用bx存放加2递增的偏移地址,用循环来进行累加。
在循环开始前,设置(bx)=0,cs:bx指向第一个数据所在的字单元。
每次循环中(bx)=(bx)+2,cs:bx指向下一个数据所在的字单元。
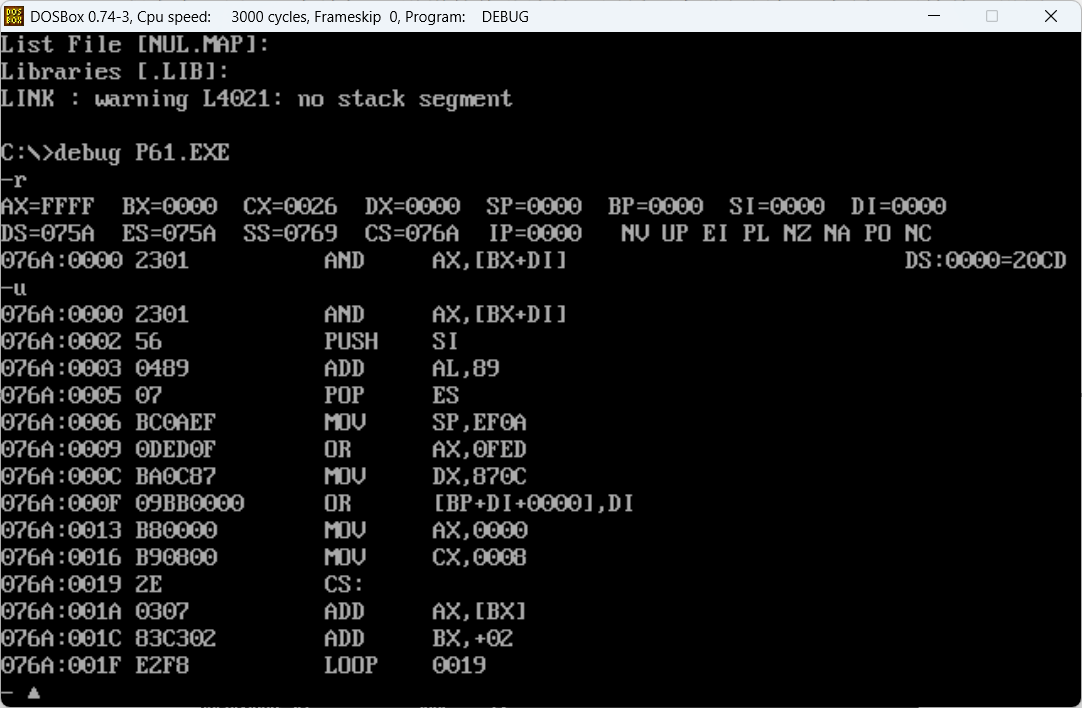
我们先把程序编译、链接为可执行文件p61.exe,先不要运行,用Debug加载查看一下,如上图所示
首先关注一下DS=075A,这是段地址
然后,我们-u查看,发现一些奇奇怪怪的的指令,到后面我们才看到了熟悉的指令
其实,这段奇奇怪怪的指令只是我们前面dw后面的数据的机器码转成了汇编指令的模样
我们可以d 076A:0000查看其机器码,验证是否正确
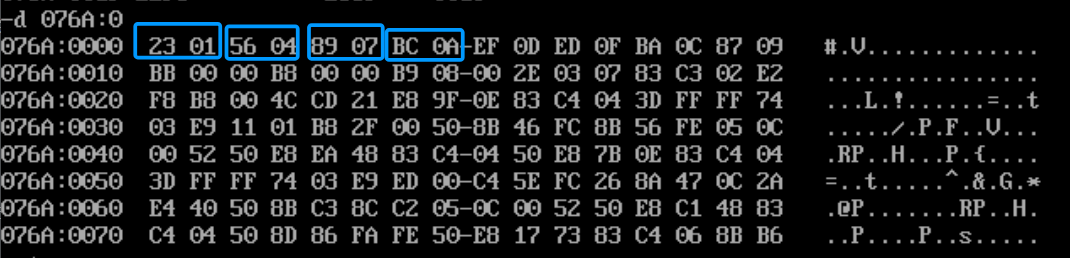
我们在看一下程序的汇编指令,-u 076A:10,这个10h其实就是跳过前面dw定义的8个数据,即16个内存单元,16进制表示10h
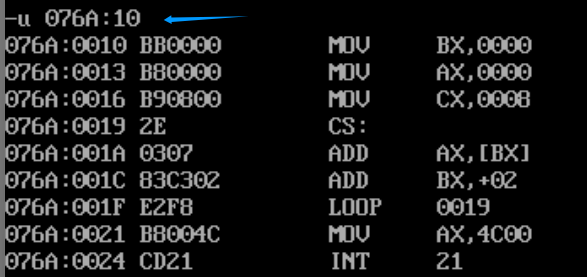
那我们要怎么执行程序中的指令呢?
用Debug加载后,直接把IP设置为10h,从而使CS:IP指向程序中的第一条指令。
然后使用t、p、g命令
可是这样一来,我们就必须用Debug来执行程序。程序6.1编译、连接成可执行文件后,在系统中直接运行可能会出现问题,因为程序的入口处不是我们所希望执行的指令。
如何让这个程序在编译、连接后可以在系统中直接运行呢?
我们可以在源程序中指明程序的入口所在,具体做法如下。
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hstart: mov bx,0mov ax,0mov cx,8s: add ax,cs:[bx]add bx,2loop smov ax,4c00hint 21hcode ends
end start
注意在程序中加入的新内容,在程序的第一条指令的前面加上了一个标号start,而这个标号在伪指令end的后面出现。
这里,我们要再次探讨end的作用。
end除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方。
在程序中我们用end指令指明了程序的入口在标号start处,也就是说,“mov bx,0”是程序的第一条指令。
在前面的课程中(参见4.8节),我们已经知道在单任务系统中,可执行文件中的程序执行过程如下。
(1)由其他的程序(Debug、command或其他程序)将可执行文件中的程序加载入内存;
(2)设置CS:IP指向程序的第一条要执行的指令(即程序的入口),从而使程序得以运行;
(3)程序运行结束后,返回到加载者。现在的问题是,根据什么设置CPU的CS:IP指向程序的第一条要执行的指令?也就是说,如何知道哪一条指令是程序的第一条要执行的指令?这一点,是由可执行文件中的描述信息指明的。我们知道可执行文件由描述信息和程序组成,程序来自于源程序中的汇编指令和定义的数据;描述信息则主要是编译、连接程序对源程序中相关伪指令进行处理所得到的信息。我们在程序6.2中,用伪指令end描述了程序的结束和程序的入口。在编译、连接后,由“end start”指明的程序入口,被转化为一个入口地址,存储在可执行文件的描述信息中。在程序6.2生成的可执行文件中,这个入口地址的偏移地址部分为:10H。当程序被加载入内存之后,加载者从程序的可执行文件的描述信息中读到程序的入口地址,设置CS:IP。这样CPU就从我们希望的地址处开始执行。
归根结底,我们若要CPU从何处开始执行程序,只要在源程序中用“end 标号”指明就可以了。
这里,我按照自己的逻辑理清楚一下:
首先,在单任务系统中,debug会将可执行文件中的程序加载入内存,设置好CS:IP执行程序第一条要执行的指令,程序就可以运行了,程序结束后,就返回给加载者。
现在,不知道根据什么去设置好CS:IP指向程序的第一条指令,这里其实是可执行文件的描述信息指明的。
可执行文件由描述信息和程序组成
- 程序就是汇编指令和定义的数据
- 描述信息是由编译、链接对源程序中的相关伪指令进行处理得到的信息
这里对伪指令的处理很关键,也就是说伪指令的信息会写入到可执行文件的描述信息中
因此,我们要规定程序的入口(CS:IP的指向)也就变得可以实现了
归根结底,我们若要CPU从何处开始执行程序,只要在源程序中用“end 标号”指明就可以了。
记住这个就行了,接下来给一个程序的模板
assume cs:code
code segment.数据.
start:.代码.
end ends
end start
6.2 在代码段中使用栈
利用栈,将程序中定义的数据逆序存放。(利用栈的先进后出的特性)
assume cs:code
codesg segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h?
code ends
end
程序运行时,定义的数据存放在cs:0~cs:F单元中,共8个字单元。
依次将这8个字单元中的数据入栈,然后再依次出栈到这8个字单元中,从而实现数据的逆序存放。
assume cs:code
codesg segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hdw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ;用dw定义16个字型数据,在程序加载后,将取得的16个字的内存空间,;存放这16个数据。在后面的程序中将这段空间当栈来用
start: mov ax,csmov ss,axmov sp,30h ;将设置栈顶ss:sp指向cs:30mov bx,0mov cx,8s: push cs,[bx]add bx,2loop s ;将以上代码段0~15单元中的8个字型数据依次入栈mov bx,0mov cx,8s0: pop cs:[bx]add bx,2loop s0 ;以上依次出栈8个字型数据到代码段0~15单元中mov ax,4c00hint 21h
code ends
end start ;指明程序的入口在start处
这里我们把cs:10~cs:2F的内存空间当作栈来用,初始状态下栈为空,所以ss:sp要指向栈底,则设置ss:sp指向cs:30
cs:30: 栈底最后一个单元的下一个
我们在代码段中定义的这16个字型数据,它们的数值都是0,这个对程序来说没有意义,这里只是作为栈空间使用
检测点6.1
(1)下面的程序实现依次用内存0:0~0:15单元中的内容改写程序中的数据,完成程序:
assume cs:code
codesg segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hstart: mov ax,0mov ds,axmov bx,0mov cx,8s: mov ax,[bx]__________ mov cs:[bx],axadd bx,2loop smov ax,4c00hint 21hcodesg ends
end start
(2)下面的程序实现依次用内存0:0~0:15单元中的内容改写程序中的数据,数据的传送用栈来进行。栈空间设置在程序内。完成程序:
assume cs:code
codesg segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987hdw 0,0,0,0,0,0,0,0,0,0 ;10个字单元用作栈空间
start: mov ax,____ csmov ss,axmov sp,____ 30hmov ax,0mov ds,axmov bx,0mov cx,8s: push [bx]__________ pop cs:[bx]add bx,2loop smov ax,4c00hint 21hcodesg ends
end start
6.3 将数据、代码、栈放入不同的段
上述代码的做法,把数据和栈放到了一个段里面,这显然不够好
要是遇到数据量较大的情况下,就不太方便了
而且也会导致数据和程序比较混乱
assume cs:code,ds:data,ss:stack
data segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data endsstack segmentdw 0,0,0,0,0,0,0,0,0,0
stack endscode segment
start: mov ax,stackmov ss,axmov sp,20h ;将设置栈顶ss:sp指向stack:20mov ax,data mov ds,ax ;ds指向data段mov bx,0 ;ds:bx指向data段中的第一个单元mov cx,8s: push [bx]add bx,2loop s ;将以上data段中的0~15单元中的8个字型数据依次入栈mov bx,0mov cx,8s0: pop [bx]add bx,2loop s0 ;以上依次出栈8个字型数据到data段的0~15单元中mov ax,4c00hint 21hcode ends
end start
(1)定义多个段的方法
assume cs:code,ds:data,ss:stack
data segment.
data ends.
stack segment.
stack ends
code segment. .mov ax,4c00hint 21h
code ends
end start
(2)对段地址的引用
这里我们有数据段、栈段、代码段,那么我们要如何访问段中的数据呢?
当然是要通过地址来访问,地址由段地址和偏移地址组成。那么我们如何指定对应的段地址呢?
这里,我们利用的是标号来指定段地址。数据段地址:data、栈段地址:stack、代码段地址:start
mov ax,data:将名称为’data’的段的段地址送入ax,一个段中的数据可以由段名代表,偏移地址就要看它在段中的位置了。
程序中“data”段中的数据“0abch”的地址就是:data:6,怎么用呢?
mov ax,data
mov ds,ax
mov bx,ds:[6]
这里我们要注意一下,
mov ds,data
mov bx,ds:[6]
mov ds,data是错误的,因为8086CPU不允许将一个数值直接送入段寄存器中。
这里的data其实是一个具体的地址,不是寄存器,因此需要一个寄存器作为中转。
(3)代码段、数据段、栈段完全是我们的安排
首先,我们要理解一件事情就是,我们设置的代码段:code、数据段:data、栈段:data都是逻辑上的设定,为方便我们编写代码而设计的。这在计算机/CPU眼里,并不会知道这些,我们做的标号是为了方便自己编写程序,而编译器会帮我们把标号转为对应的地址,CPU并不知道标号是什么意思,它还是识别机器码。
这里不禁感叹一下编译器的好处,它就像一个工具台,你需要什么它就给你什么,等你构建好你的程序,它就帮你把它翻译成机器码让CPU去执行。
不只是上面的标号对应的段地址,甚至后面的cs:code、ds:data、ss:stack都是CPU不知道的,这些都是有编译器执行的,包括assume这种伪指令,CPU都不知道它们的存在,这些都是由编译器来处理的。
源程序的最后用“end start”说明了程序的入口,这个入口被写入可执行文件的描述信息,可执行文件中的程序被加载入内存后,CPU的CS:IP被指向这个入口,从而开始执行程序中的第一条指令。标号“start”在“code”段中,这样CPU就将code段中的内容当做指令来执行了。
mov ax,stack
mov ss,ax
mov sp,20h
设置ss指向stack,设置cs:ip指向stack:20,CPU执行这些指令后,将把stack段当做栈空间来用。
CPU若要访问data段中的数据,则可用ds指向data段,用其他的寄存器(如bx)来存放data段中数据的偏移地址。
总之,CPU到底如何处理我们定义的段中的内容,是当作指令执行,当作数据访问,还是当作栈空间,完全是靠程序中具体的汇编指令,和汇编指令对CS:IP、SS:SP、DS等寄存器的设置来决定的。
assume cs:b,ds:a,ss:c
a segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
a endsc segmentdw 0,0,0,0,0,0,0,0,0,0
c endsb segmentd: mov ax,cmov ss,axmov sp,20h ;希望用c段当作栈空间,设置ss:sp指向c:20mov ax,amov ds,ax ;希望用ds:bx访问a段中的数据,ds指向a段mov bx,0 ;ds:bx指向a段中的第一个单元mov cx,8
s: push [bx]add bx,2loop s ;以上将a段中的0~15单元中的8个字型数据依次入栈mov bx,0mov cx,0
s0: pop [bx]add bx,2loop s0 ;以上依次出栈8个字型数据到a段的0~15单元中mov ax,4c00hint 21h
b ends
end ;d处是要执行的第一条指令,即程序的入口实验5 编写、调试具有多个段的程序
(1)将下面的程序编译、链接,用Debug加载、跟踪,然后回答问题。
assume cs:code,ds:data,ss:stackdata segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data endsstack segmentdw 0,0,0,0,0,0,0,0
stack endscode segmentstart: mov ax,stackmov ss,axmov sp,16mov ax,datamov ds,axpush ds:[0]push ds:[2]pop ds:[2]pop ds:[0]mov ax,4c00hint 21h
code ends
end start
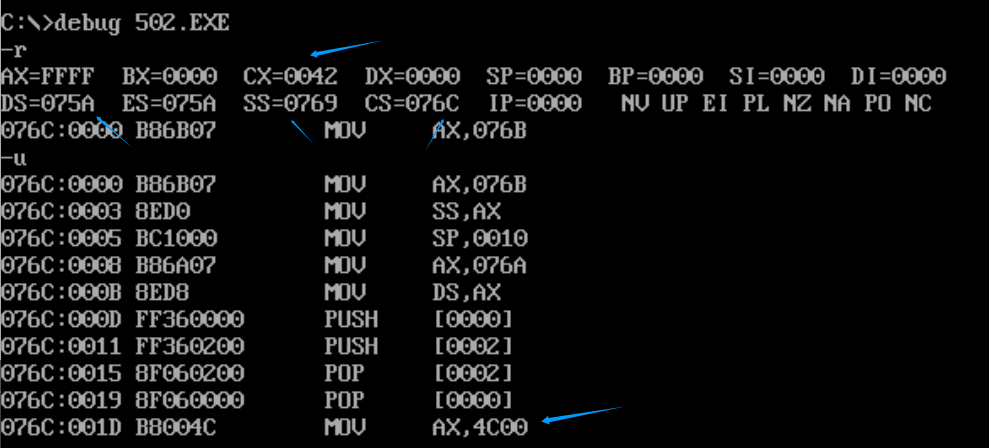
快速编译、链接一下,我这里取名501.exe
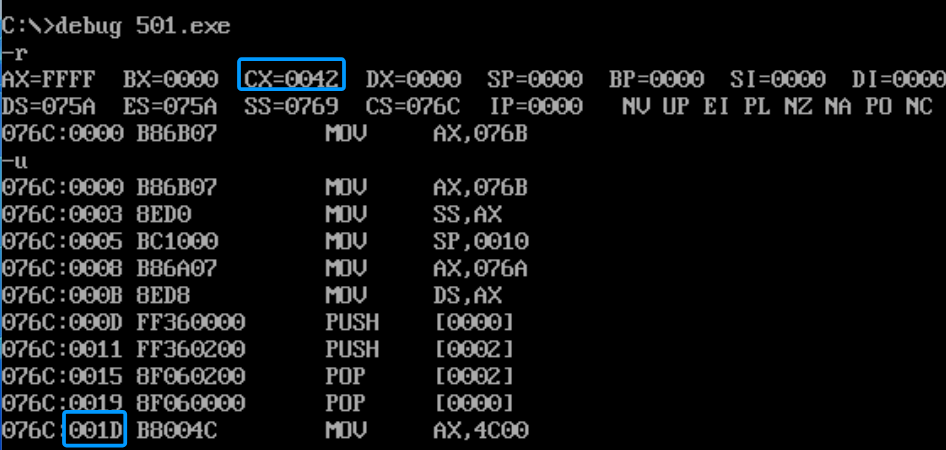
首先,-r查看各个寄存器的值,我们看到CX的值,说明程序的大小为42h,然后我们-u,反汇编查看汇编指令
问题,都问的是程序返回前,那什么是程序返回前呢?mov ax,4c00h就是程序返回指令的开头,所以我们直接追踪过去
g 001D 然后 -d ds:0 查看对应内存单元的内容
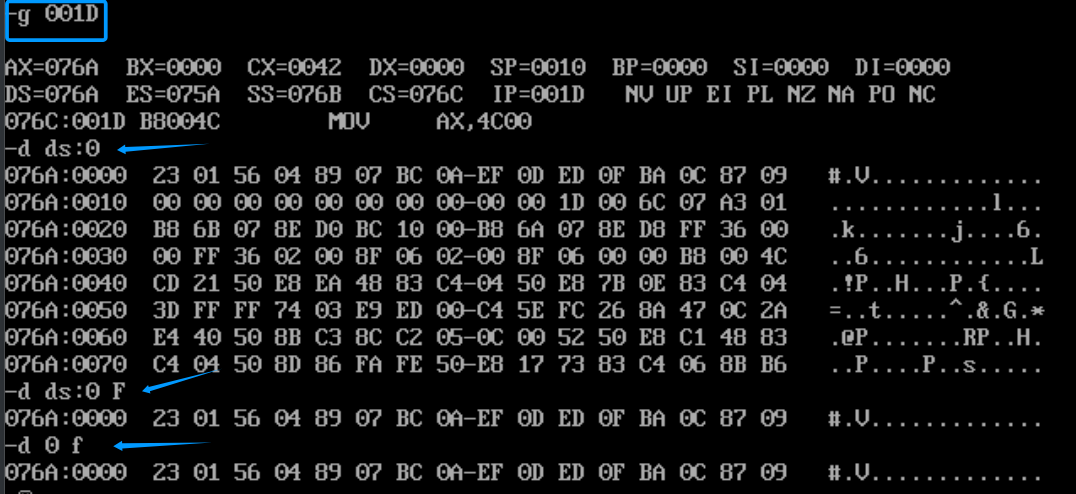
1、CPU执行程序,程序返回前,data段中的数据为多少?
0123h,0456h, 0789h, 0abch, 0defh, 0fedh, 0cbah, 0987h(data段数据不变)
2、CPU执行程序,程序返回前,CS=、SS=、DS=

CS=076C、SS=076B、DS=076A
3、设程序加载后,code段的段地址为X,则data段的段地址为__ stack 段的段地址为__
X-2、X-1
(2)将下面的程序编译、链接,用Debug加载、跟踪,然后回答问题。
assume cs:code,ds:data,ss:stackdata segmentdw 0123h,0456h
data endsstack segmentdw 0,0
stack endscode segment
start: mov ax,stackmov ss,axmov sp,16mov ax,datamov ds,axpush ds:[0]push ds:[2]pop ds:[2]pop ds:[0]mov ax,4c00hint 21hcode ends
end start
1、CPU执行程序,程序返回前,data段中的数据为多少?
0123h,0456h(data段数据不变)
2、CPU执行程序,程序返回前,CS=、SS=、DS=

CS=076C、SS=076B、DS=076A
3、设程序加载后,code段的段地址为X,则data段的段地址为 stack 段的段地址为
X-2、X-1
4、对于如下定义的段:
name segment
.
.
name ends
如果段中的数据占N个字节,则程序加载后,该段实际占有的空间为
(N/16+1)*16 (N/16为取整数部分)
这里不太理解找了篇博客:https://www.cnblogs.com/zsznb/p/10025532.html
感谢大佬的分享!这里引用一下
在8086CPU架构上,段是以paragraph(16-byte)对齐的。程序默认以16字节为边界对齐,所以不足16字节的部分数据也要填够16字节。“对齐”是alignment,这种填充叫做padding。16字节成一小段,称为节。
一、这首先要从8086处理器寻址原理说起。
8086这种处理器有二十根地址线(20个用于寻址的管脚),可以使用的外部存储器空间可达1MB(00000H~FFFFFH)。 但是,8086内部的寄存器都是16位的,用任何一个寄存器(比如BX或SI),都无法直接寻址8086所支持的1M地址空间,因为16位寄存器只能表示640KB的空间范围(0000~FFFFH)。
所以,Intel想了一个方法,设计出了CS/DS/ES/SS这几个段地址寄存器,用段地址寄存器与普通寄存器组合,来寻址1MB的地址范围,即:对于CPU取指来说,用CS:IP组合来寻址下一个要执行的指令(也在存储器中);对于堆栈操作PUSH/POP来说,用SS:SP组合来表示当前栈指针(栈也在存储器中);对于数据操作指令来说,用默认的DS/ES或指定的段地址(段前缀指令)与偏移量寄存器组合寻址。
组合后的实际地址=段寄存器内容×16+偏移量寄存器内容
从这个公式可以看到,每一个段的地址都对齐在16的倍数上。比如DS=1234H,则这个段就从 1234H×16+0000H=12340H开始,最大到1234H×16+0FFFFH=2233FH为止。
二、对同一个内存地址,有不同的段:偏移量组合方法,比如2233FH这个地址,既可以表示为1234H:0FFFFH(在1234H段中),也可以表示为2233H:0000FH(在2233H段中)。
那么,如果汇编程序中有下面两个连续的段定义,汇编编译程序会怎么做呢?
name1 segment
d1 db 0
name1 ends
name2 segment
d2 db 0
name2 ends
编译程序可以将name1和name2编译成一个段,d1和d2在内存中连续存放,这样可以节省内存空间。比如编译程序以name1为基准,将name1作为一个段的起始,程序加载后会被放在xxxx0H的地方,那么d1就放在该段偏移地址为0字节的位置,d2就放在该段偏移为1字节的位置。
这样的处理方式虽然可能会节省一点内存空间,但是对于编译器的智能化要求太高了,它必须将源程序中所有引用到name2和d2的地方,全部调整为以name1段为基准,这实在是太难了,而且也节省不了几个字节的空间,编译器是不会干这种吃力不讨好的事的。编译器实际的处理方式是将name1中的所有内容放在一个段的起始地址处,name2里的所有内容放在后续一个段的起始地址处(这也是汇编指令segment的本义:将不同数据分段)。这样,即使name1中只包含一个字节,也要占一个段(16个字节),所以,一个段实际占用的空间=(段中字节数+15)/ 16。
所以,8086处理器的内部寻址原理和汇编程序编译器共同决定了segment定义的段必须放在按16的倍数对准的段地址边界上,占用的空间也是16的倍数。
从上面的说明可以知道,8086处理器中所定义的段占用的空间一定是16的倍数,即使不满16个字节,也要占一整个段即16个字节,所以题一和题二的cx的值都为0042h。对于公式的疑惑在于如果所需空间正好是16的倍数,那公式所求的占用空间为所需空间多16个字节,为什么不直接分配刚刚好所需的空间而要多一个段空间呢。
这里其实用到的是操作系统中的虚拟内存的思想以及计算机组成原理中数据存储和排列中的边界对齐的思想。
其实不理解也没啥关系,主要就理解内存地址是由段地址和偏移地址组成,而边界对齐就是说,用空间来换效率。
毕竟想要更充分使用内存的空间,就需要更加复杂的设计思维。
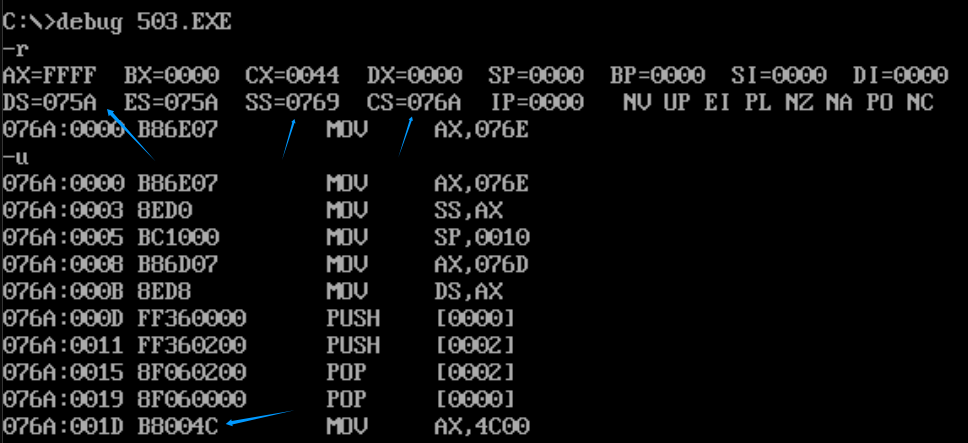
(3)将下面的程序编译、链接,用Debug加载、跟踪,然后回答问题。
assume cs:code,ds:data,ss:stack
code segmentstart: mov ax,stackmov ss,axmov sp,16mov ax,datamov ds,axpush ds:[0]push ds:[2]pop ds:[2]pop ds:[0]mov ax,4c00hint 21h
code ends
data segmentdw 0123h,0456h
data ends
stack segmentdw 0,0
stack ends
end start
1、CPU执行程序,程序返回前,data段中的数据为多少?
0123h,0456h(data段数据不变)
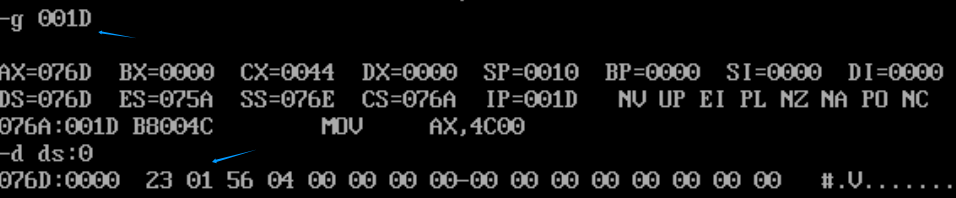
2、CPU执行程序,程序返回前,CS=、SS=、DS=
CS=076C、SS=076B、DS=076A
3、设程序加载后,code段的段地址为X,则data段的段地址为 stack 段的段地址为
X+3,X+4
(4)如果将(1)、(2)、(3)题中的最后一条伪指令“end start”改为“end”(也就是说,不指明程序的入口),则哪个程序仍然可以正确执行?请说明原因。
第三个程序仍可以正常执行,当不指明程序的入口时,cs:code segment的默认ip为0,第三个程序程序刚好执行到代码段。
(5)程序如下,编写code段中的代码,将a段和b段中的数据依次相加,将结果存在c段中。
assume cs:code
a segmentdb 1,2,3,4,5,6,7,8
a ends
b segmentdb 1,2,3,4,5,6,7,8
b ends
c segment db 0,0,0,0,0,0,0,0
c ends
code segment
start:?
code ends
end start
assume cs:code
a segmentdb 1,2,3,4,5,6,7,8
a ends
b segmentdb 1,2,3,4,5,6,7,8
b ends
c segment db 0,0,0,0,0,0,0,0
c ends
code segment
start: mov ax,amov ds,ax ; ds段地址设为a段的开始mov bx,0 ; bx偏移地址设为0,从0开始mov cx,4 ; cx循环计数器,4次,字型数据4个
s: mov dx,ds:[bx] ; 把a段的数值给到dx寄存器add dx,ds:[bx+16] ; 把b段的数值加到dx寄存器,实现a段+b段mov ds:[bx+32],dx ; 把求和的值给到c段add bx,2 ; 字型数据,+2偏移loop smov ax,4c00hint 21h
code ends
end start
这里借用一个bx寄存器,然后通过观察a段、b段、c段的固定偏移即可完成寻址
(6)程序如下,编写code段中的代码,用push指令将a段中的前8个字型数据,逆序存储到b段中。
assume cs:code
a segmentdw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0fh,0ffh
a ends
b segmentdw 0,0,0,0,0,0,0,0
b ends
code segment
start: ?
code ends
end start
assume cs:code
a segmentdw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0fh,0ffh
a ends
b segmentdw 0,0,0,0,0,0,0,0
b ends
code segment
start: mov ax,amov ds,ax ; ds段地址设为a段的开始mov ax,bmov ss,ax ; ss栈段地址设为b段的开始mov sp,10h ; sp栈偏移地址设为10h,8个字型数据10hmov bx,0mov cx,8
s: push ds:[bx] ; 逆序入栈add bx,2loop smov ax,4c00hint 21h
code ends
end start
将数据段寄存器指向a,栈段寄存器指向b,因为栈段分配ss:0到ss:F空间,而在栈空时栈指针sp应该指向栈底的下一个单元即为ss:10h,所以赋值sp为10h。令循环次数cx为8,执行循环s,实现用push指令将a段中的前8个字型数据,逆序存储到b段中。