品牌营销的概念/青岛seo经理
一、实验目的
本次实验旨在通过分析地面采集的光谱信息和LiDAR结构信息,建立并比较多种预测模型,以估计病虫害引起的植被失叶率。通过这一过程学习如何处理和分析植被的光谱与结构数据,理解数据预处理、模型构建及其相关的步骤,掌握利用不同软件构建多元线性回归模型和随机森林模型的方法。同时,通过解读模型结果、进行参数估计和显著性测试,进一步提高自身的数据分析和结果研判的能力,培养在实际问题中综合应用这些技能的能力。
二、实验内容
(1)基于光谱信息建立模型
(2)基于结构信息建立模型
(3)结合光谱与结构信息建立模型
(4)基于随机森林方法建立模型
三、实验步骤
(1)基于光谱信息建立模型
我们首先利用MATLAB软件,构建得到植被的光谱信息(NONPHO_fraction_15,GV_fraction_15,Shade_fraction_15,Fra_under_15,NONPHO_fraction_16,GV_fraction_16,dNONPHO_fraction,dFra_UDS)与植被冠层失叶值(Average.Defol..Status.x)间的多元线性关系模型,基本代码如下所示:
train_data = readtable('C:\Users\付嘉琪\Desktop\农业大数据\实验四\实验四\实验数据\Simplified_Canopy_defoliation_analysis_training-simp.csv');
test_data = readtable('C:\Users\付嘉琪\Desktop\农业大数据\实验四\实验四\实验数据\Simplified_Canopy_defoliation_analysis_vald-simp.csv');% 提取自变量和因变量
X_train = table2array(train_data(:, 2:9)); % B到I列
y_train = table2array(train_data(:, 10)); % J列X_test = table2array(test_data(:, 2:9)); % B到I列
y_test = table2array(test_data(:, 10)); % J列% 构建多元线性回归模型
model = fitlm(X_train, y_train);% 使用交叉验证获取R²值
r2_scores = crossval(@(X_train, y_train, X_test, y_test) ...1 - (sum((y_test - predict(fitlm(X_train, y_train), X_test)).^2) / sum((y_test - mean(y_test)).^2)), ...X_train, y_train, 'kfold', 10);% 绘制R²值的箱线图
figure;
boxplot(r2_scores);
title('R² Scores Boxplot');
ylabel('R² Score');% 打印平均R²值
fprintf('Average R² Score: %.4f\n', mean(r2_scores));
模型结果分析:
线性回归模型:Y=X1+X2+X3+X4+X5+X6+X7+X8+1![]()
观测值数目为64,误差自由度为55,均方根误差为18.3,R 方为0.754,调整后的R 方为0.718,R方较高,说明模型能够解释目标变量约75.4%的变异性。F 统计量(常量模型)为21.1,p 值 = 3.39e-14,小于0.05因此我们认为该模型是显著的,该模型的具体常量参数与变量系数结果如下表所示:
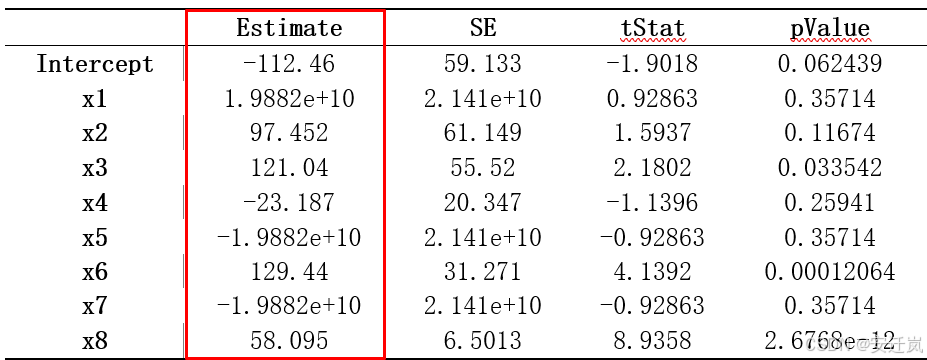
根据系数的p值,我们会发现x3 和 x6 对因变量的影响是最为显著的,而其他自变量的影响可能不够显著(p值略大),但虽然某些自变量的p值较大,不代表其对于因变量的影响就较小,我们需要充分结合相应的领域知识进行分析,同时在进行多元线性回归拟合之前,可以充分开展相关性分析、共线性诊断等步骤进一步提高我们的模型精度。
(2)基于结构信息建立模型
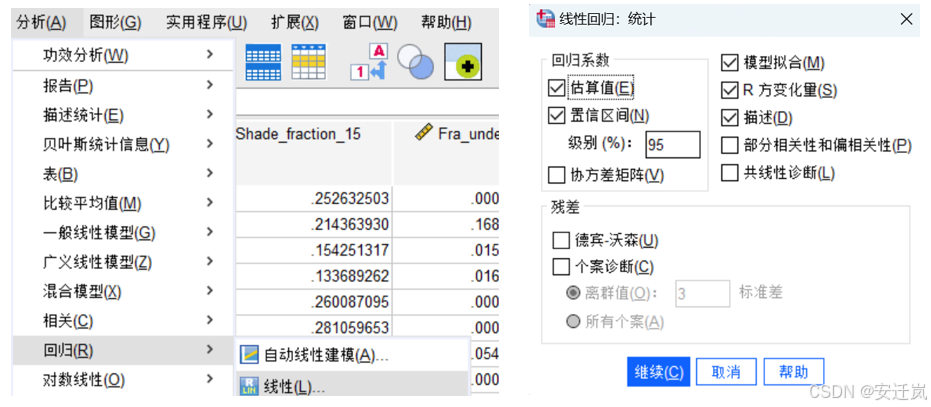
实验第二步我们利用SPSS软件中【分析】—>【回归】—>【线性】功能,帮助我们构建得到植被的结构信息(b70_16、dske、dkur、dint_p25)与植被冠层失叶值(Average.Defol..Status.x)间的多元线性关系模型,具体操作如下左图所示,并将相关参数设置为如下右图所示:
模型结果分析:
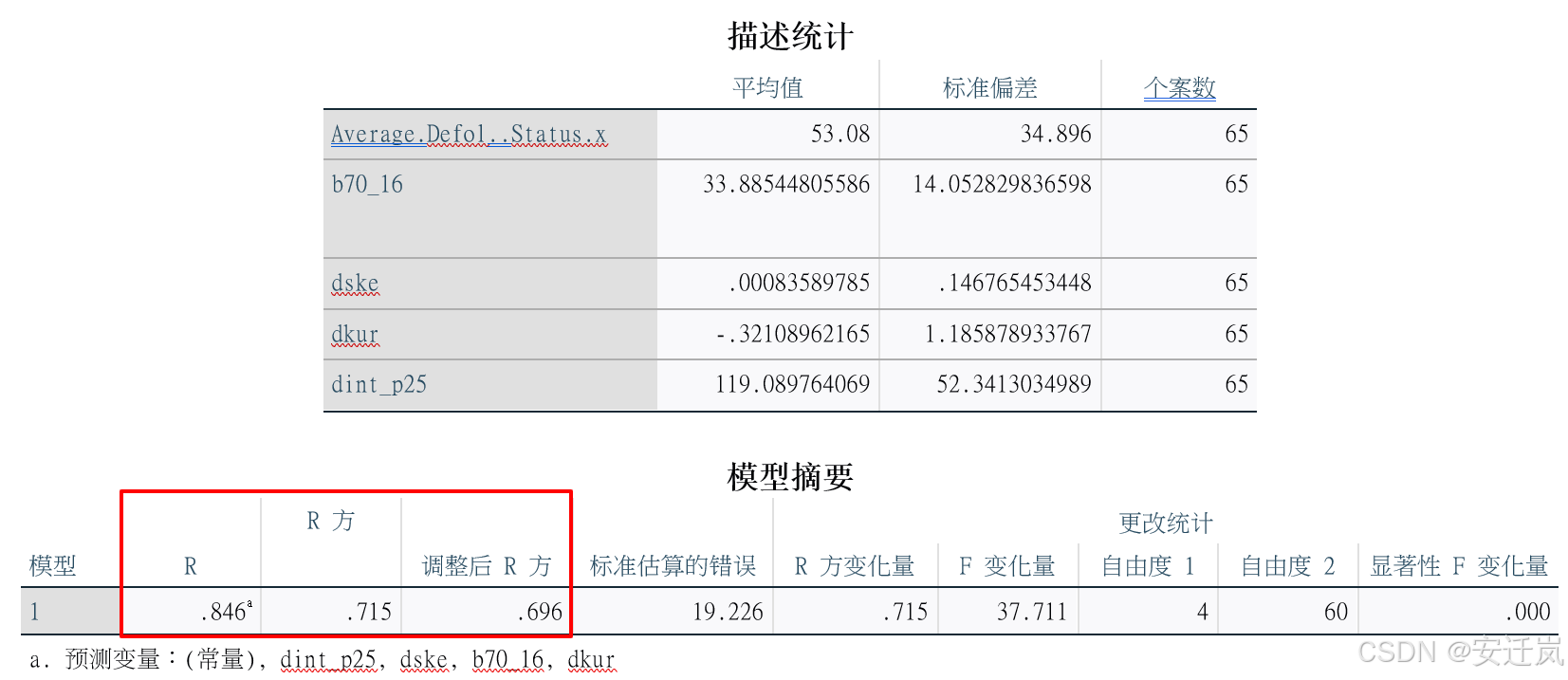
观测值数目为65,误差自由度为60,均方根误差为19.226,R方为0.715,调整后的R方为0.696。R方较高,说明模型能够解释目标变量约71.5%的变异性。F统计量(常量模型)为37.711,该模型的具体常量参数与变量系数结果如下表所示:
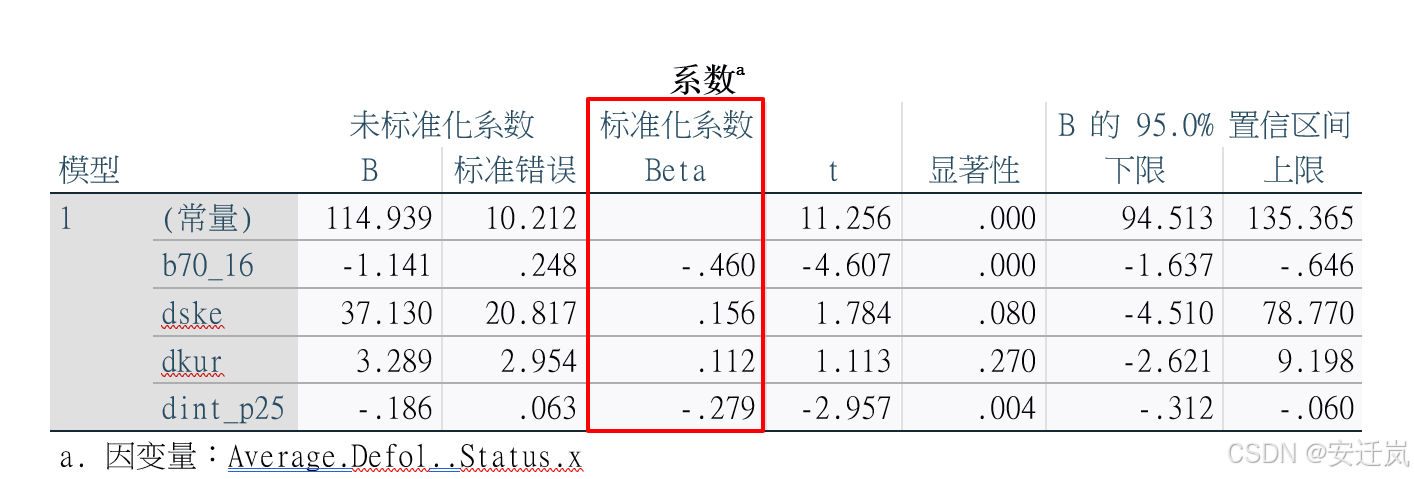
常量的标准化系数为11.256,p值小于0.001;b70_16的标准化系数为-0.460,p值小于0.001;dske的标准化系数为0.156,p值为0.080;dkur的标准化系数为0.112,p值为0.270;dint_p25的标准化系数为-0.279,p值为0.004,p值小于0.05,由此我们可以看出,不同变量对目标变量Average.Defol..Status.x的影响程度各不相同,常量和b70_16的系数具有统计显著性,而dske和dkur的系数则较不明显 。
(3)结合光谱与结构信息建立模型
实验第三步我们利用Python中的相关库(statsmodels库),构建得到植被的光谱信息、结构信息与植被冠层失叶值(Average.Defol..Status.x)间的多元线性关系模型。statsmodels是一个用于拟合统计模型、进行统计测试以及探索数据的Python 库。它提供了广泛的统计模型,包括线性模型、广义线性模型、时间序列模型和非参数模型等,以及许多统计测试和统计数据探索工具。具体代码如下图所示:
模型结果分析:
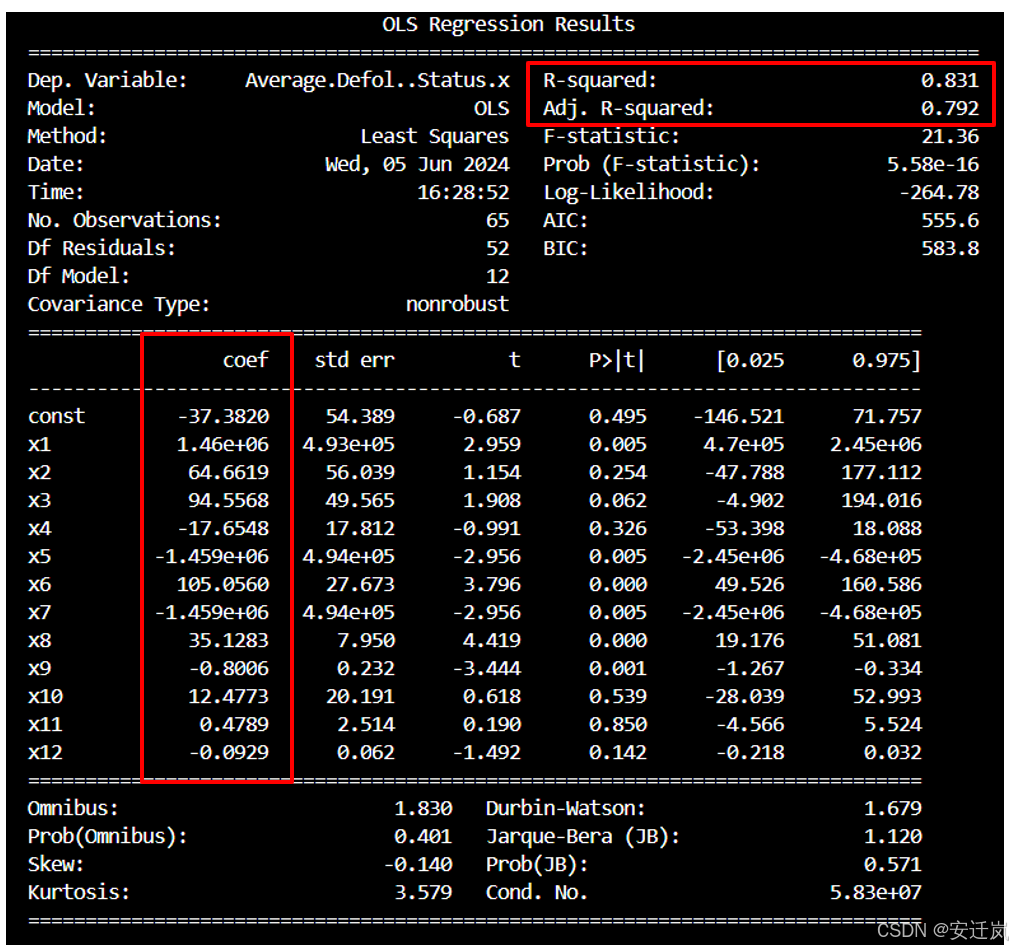
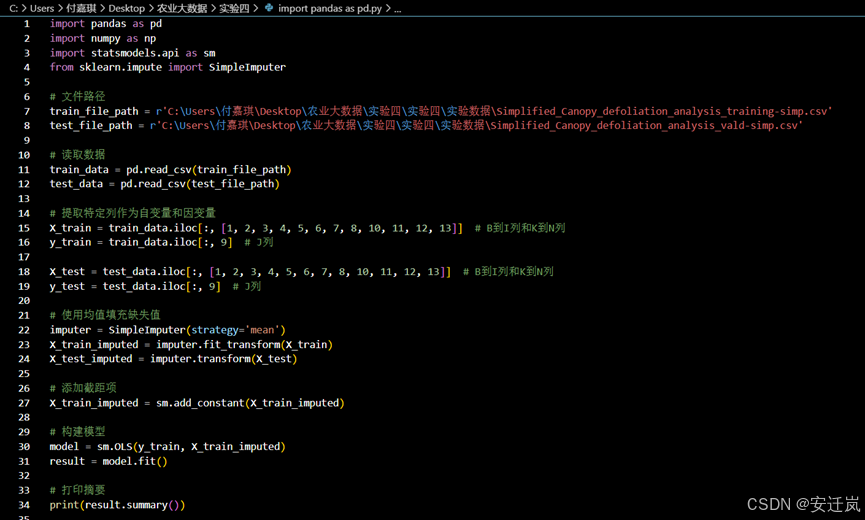
根据OLS回归结果分析,我们可以看到模型的整体拟合效果良好,R方值为0.831,说明模型可以解释约83.1%的因变量的方差,F统计量的显著性检验结果显示,模型整体是显著的(F统计量=21.36,P<0.05)。
该模型的具体常量参数与变量系数结果方面,我们可以看到每个自变量的系数估计值、标准误差、t值以及与之对应的p值。其中,自变量x1、x5、x7、x8和x9的系数估计值的p值小于0.05,表明它们对因变量的影响是显著的。具体来说,自变量x1和x5的系数分别为1.46e+06和-1.459e+06,说明它们对因变量有着较大的影响。而其他自变量的系数的p值大于0.05,表明它们的影响并不显著。
(4)基于随机森林方法建立模型
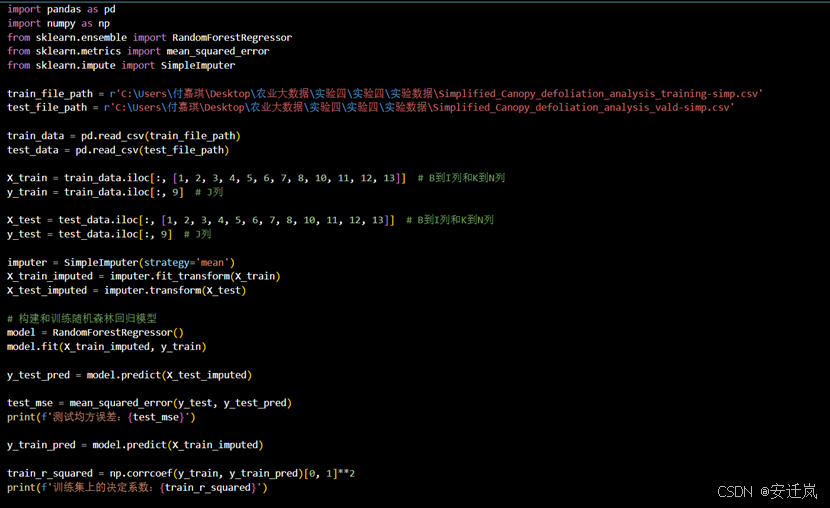
实验第四步,我们依然利用Python编写代码,基于随机森林方法,构建得到植被的光谱信息、结构信息与植被冠层失叶值(Average.Defol..Status.x)间的关系模型。随机森林模型通过构建多个决策来进行预测或分类,并通过投票或取平均的方式来提高整体预测性能,它结合了决策树的简单和直观性以及集成学习的优势,具有较高的准确性、鲁棒性和适应性。具体代码如下图所示:
模型结果分析:
随机森林模型不像线性回归那样提供简单的公式来计算R方等指标,但我们可以通过其它方法计算模型在训练集上的决定系数来评估模型的拟合程度,由于每个决策树的预测结果是离散的,由此我们可以通过计算模型在训练集上的预测值之间的相关系数来作为一个近似值来评估拟合程度。
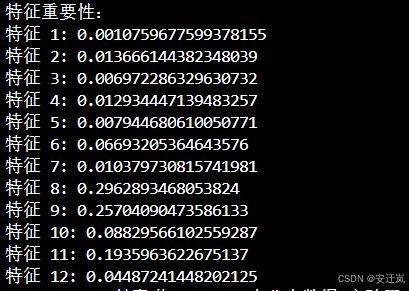
最终我们计算得到测试均方误差为440.7552083,训练集上的决定系数为0.9784051649961465,并且我们可以得到各个特征的重要性,重要性表示特征对模型预测结果的贡献程度。根据结果,特征8的重要性最高,为0.296,其次是特征9,重要性为0.257,这意味着这两个特征对模型的预测影响最大。其他特征的重要性相对较低,但仍然对模型预测有一定的贡献。
四、结果对比
在上述的实验内容中我们共尝试构建了四个由于病虫害引起的失叶率估计模型,模型一:基于植被光谱信息构建多元线性回归模型;模型二:基于植被结构信息构建多元线性回归模型;模型三:结合光谱信息与结构信息构建多元线性回归模型;模型四:基于随机森林方法构建模型。
在此次实验中由于时间有限,我们将重点分析对比前三个模型的结果精度,首先我们利用MATLAB中的绘图工具,绘制得到了三个模型测试集结果的预测值与实际值的散点图、R方与RMSE,可以明显看到,从模型一到模型三,R方逐渐增加,RMSE逐渐减小,说明模型的精度在不断提高。也进一步说明植被的结构信息比植被的光谱信息更能反映由于病虫害引起的失叶率,但此结果明显与我们在实验步骤中得到的结果不相符合,由此我们需要进一步对数据与模型进行分析。
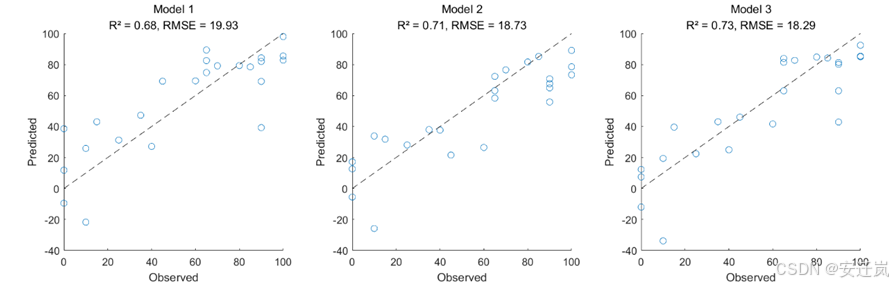
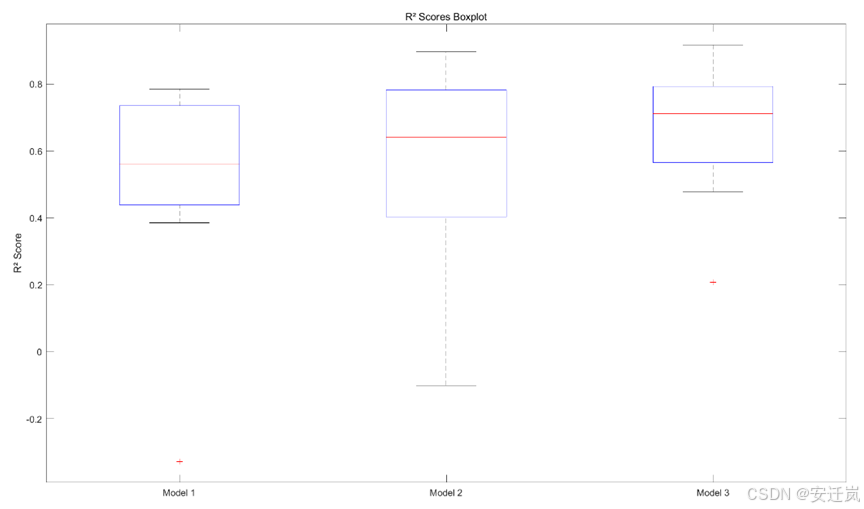
接下来我们同样利用MATLAB编写代码绘制得到了三个模型基于交叉验证方法获得的R方与RMSE的箱线图,箱形图又称为盒须图、盒式图,是一种用作显示一组数据分散情况资料的统计图。箱内部的中间线表示数据的中位数,箱子的上下边缘分别表示数据的第25百分位数和第75百分位数,而箱线图的“须则延伸到数据的最大值和最小值。
首先是R方的箱线图,我们可以看到Model 1中位数较低,IQR较小,异常值较少,表示Model 1在交叉验证中的虽然性能相较其它模型较低但结果一致;Model 2中位数略高,IQR较大,表示Model 2的性能较好但结果并不不稳定;Model 3的中位数最高,IQR中等,有少量异常值,表示Model 3的稳定性介于Model 1和Model 2之间,但是模型精度最高。
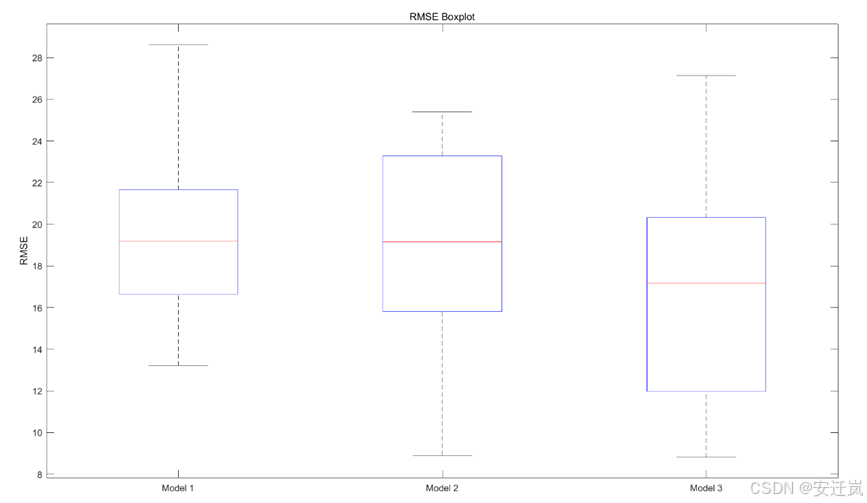
然后是RMSE的箱线图,我们可以看到Model 1中位数较高,IQR最大,异常值较少,说明Model 1在交叉验证中的均方根误差相较其它模型较高且结果并不稳定;Model 2中位数与Model 1接近,IQR较大,表示Model 2的性能较好但同样结果并不不稳定;Model 3的中位数明显低于前两个模型,IQR中等,有表示Model 3的虽然稳定性同样较低,但是模型精度最高,均方根误差最小。
五、实验心得
1. 模型构建与结果分析:通过本次实验,我们学习了如何基于光谱信息、结构信息以及两者结合的情况下,构建多元线性回归模型和随机森林模型,并通过这些模型估计病虫害引起的植被失叶率。并通过交叉验证和结果对比分析,我们进一步理解了模型评价的关键指标(R方和均方根误差RMSE)。实验结果表明,结合光谱与结构信息的多元线性回归模型和随机森林模型在预测精度上优于单一信息来源的模型,说明综合利用多种数据可以有效提高我们模型的预测能力;
2.各个数据统计分析工具对比:在本次实验中,我们深入理解了多元线性回归模型和随机森林方法在植被冠层失叶率估计中的应用,掌握了MATLAB、SPSS和Python等工具在数据处理和模型构建中的使用。通过对比使用我们可以明显感受到,不同的软件处理方法有着不同的特点与使用范围。MATLAB:以其强大的数值计算和数据可视化功能著称,在使用过程中我们可以明显感受到,与其它两个工具相比,其可视化功能清晰简洁更符合我们学术研究的要求;SPSS:该软件专为统计分析设计,具有简洁的用户界面和强大的数据管理功能,该软件的主要优点在于操作非常简单无需编写代码,并且特别适合处理结构化数据和进行标准统计分析;Python:作为通用编程语言,Python在数据科学和机器学习领域有着广泛的应用,我们可以通过使用丰富的库(如statsmodels、scikit-learn等)并且在开源社区中进行学习,灵活地进行数据处理、模型构建和评估。