大数据Hadoop之——Flume安装与使用(详细)
目录
一、Flume架构
1、Agent
2、Source
3、Channel
4、Sink
5、Event
二、前期准备
1、查看网卡
2、配置静态IP
编辑 3、设置主机名
4、配置IP与主机名映射
5、关闭防火墙
6、配置免密登录
三、JDK的安装
四、Flume的安装
1、Flume的下载安装
2、Flume的使用
2.1. 创建 Flume Agent配置文件
2.2. 编写内容
2.3. 创建脚本
2.4. 启动HDFS
2.5. 启动Flume
2.6. 执行脚本
2.7. 结束进程
五、实时监控目录下多个新文件
1、创建监控目录
2、创建 Flume Agent 配置文件
3、创建脚本
4、启动HDFS
5、启动Flume
6、执行脚本
7、结束进程
六、实时监控目录下多个新文件
1、创建监控目录
2、创建 Flume Agent 配置文件
3、创建脚本
4、启动HDFS
5、启动Flume
6、执行脚本
7、结束进程
(1)文档查看地址:Flume 1.11.0 User Guide — Apache Flume
(2)下载地址:http://archive.apache.org/dist/flume/
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
一、Flume架构

1、Agent
Agent 是一个运行在 Java 虚拟机(JVM)上的程序 ,它就像是一个小快递员。
它的任务是:把数据从一个地方搬运到另一个地方 。
数据在 Flume 中是以“事件(Event)”的形式存在的。
2、Source
Source 是 Agent 的入口 ,相当于快递员的起点站。
它负责接收各种来源的数据,比如:
- 网络日志(netcat)
- 文件内容(taildir、spooling directory)
- 消息队列(如 Kafka、JMS)
- 或者模拟数据(sequence generator)
3、Channel
Channel 就像是快递员的背包 ,用来临时存放 Source 接收到的数据。
它起到一个中转站的作用 ,让 Source 和 Sink 可以各自按照自己的节奏工作。
Flume 提供了两种常用的 Channel【Memory Channel(内存通道)、File Channel(文件通道)】:
-
Memory Channel(内存通道) :
- 数据存在内存里,速度快。
- 但如果程序崩溃或服务器断电,数据可能会丢。
-
File Channel(文件通道) :
- 数据写入磁盘,更安全。
- 即使程序关闭或机器重启,数据也不会丢失。
4、Sink
Sink 是 Agent 的出口 ,相当于快递员的目的地。
它不断地从 Channel 中取数据,并把这些数据发送出去或者保存起来。
常见的目的地有:
- HDFS(存储大数据)
- HBase、Solr(数据库/搜索引擎)
- 日志记录器(Logger)
- 或者发给下一个 Agent 继续处理
5、Event
Event 是 Flume 中传输数据的基本单位 ,就像快递员运送的小包裹。
每个 Event 包含两部分:
- Header(头信息) :像标签一样,包含一些描述信息(比如数据类型、时间等),是键值对(Key-Value)形式。
- Body(主体) :真正要传输的数据,是一串字节(byte[]),可以是文本、JSON、图片等。
二、前期准备
1、查看网卡
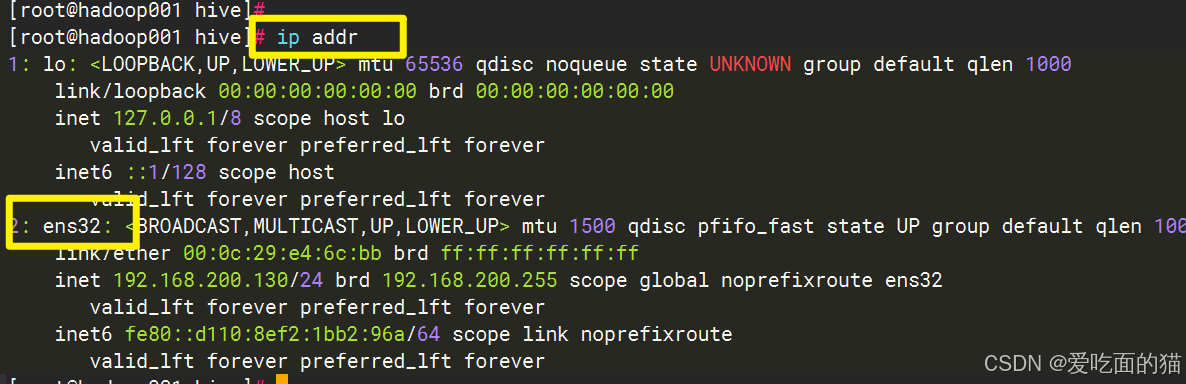
2、配置静态IP
vi /etc/sysconfig/network-scripts/ifcfg-ens32 ---- 根据自己网卡设置。
 3、设置主机名
3、设置主机名
hostnamectl --static set-hostname 主机名
例如:
hostnamectl --static set-hostname hadoop001
4、配置IP与主机名映射
vi /etc/hosts

5、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
6、配置免密登录
传送门
三、JDK的安装
传送门
四、Flume的安装
1、Flume的下载安装
1.1. 下载
https://archive.apache.org/dist/zookeeper/zookeeper-3.7.1/
下载 apache-flume-1.9.0-bin.tar.gz 安装包
1.2 上传
使用xshell上传到指定安装路径此处是安装路径是 /opt/module
1.3 解压重命名
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
mv apache-flume-1.9.0-bin flume
1.4 配置环境变量
vi /etc/profile
export JAVA_HOME=/opt/module/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export FLUME_HOME=/opt/module/flume
export PATH=$PATH:$JAVA_HOME/bin:$FLUME_HOME/bin
1.5 加载环境变量
source /etc/profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
1.6 删除guava
将lib文件夹下的guava-11.0.2.jar删除,以兼容Hadoop
rm -rf /opt/module/flume/lib/guava-11.0.2.jar



2、Flume的使用
2.1. 创建 Flume Agent配置文件
Agent = Source + Channel + Sink
Flume可以定义多个Agent,如a1,a2,a3,....
1、创建job文件夹
在flume目录下创建job文件夹并进入job文件夹。
mkdir /opt/module/flume/job
cd /opt/module/flume/job
2、创建 Flume Agent配置文件
在job文件夹下创建Flume Agent配置文件 log-flume-hdfs.conf
配置六大步骤:
01、定义一个名为 a1 的 Flume Agent
02、给 Agent a1 指定使用的组件
03、配置source
04、配置sink
05、配置chanel
06、连接通道
2.2. 编写内容
cd /opt/module/flume/job
vi log-flume-hdfs.conf
#01、02 给 Agent a1 指定使用的组件
#使用的 Source 是 r1
#使用的 Sink 是 k1
#使用的 Channel 是 c1a1.sources = r1
a1.sinks = k1
a1.channels = c1
#03 配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/test.log
# 04配置sink:类型为hdfs、路径指定hdfs
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/%Y%m%d/%H#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#下面3行表示每小时创建一个文件夹
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳,如果使用%Y%m%d/格式必须设为true否则报错
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#生成新文件的条件:时间60秒,大小约128M、生成环境一般是3600s
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
# 05 配置通道:方式、最多缓存Event个数、每次事务最多处理的Event个数
# 作为 Source 和 Sink 之间的“中转站”,缓解两者速度不一致的问题
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 06 连接通道:a1源的组件r1使用通道 c1,a源的组件k1使用通道 c1,
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.3. 创建脚本
touch /opt/module/genarete_log.sh
chmod 777 /opt/module/genarete_log.sh
vi /opt/module/genarete_log.sh#!/bin/bash
for i in {1..100}; do
echo "$i linux生成1-100的数字的for循环" >> /opt/module/test.log
donetail -10 /opt/module/test.log
2.4. 启动HDFS
/opt/module/hadoop/bin/start-dfs.sh
/opt/module/hadoop/sbin/start-yarn.sh
如果hadoop未安装请走这个门:Hadoop安装传送门
2.5. 启动Flume
启动flume,使用 cnc,即--conf 目录 --name agent 名称 --conf-file 配置文件 顺序不固定
cd /opt/module/flume
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/log-flume-hdfs.conf
2.6. 执行脚本
执行脚本,在hdfs上查看结果
/opt/module/genarete_log.sh
hdfs dfs -ls /flume

2.7. 结束进程
ps -ef | grep flume | grep -v grep | awk '{print $2}' | xargs kill -9
五、实时监控目录下多个新文件
在上面的基础上进行增加需求,让 flume 监控 /opt/module/flume/upload 录下的多个文件,并上传至HDFS。
1、创建监控目录
mkdir /opt/module/flume/upload
2、创建 Flume Agent 配置文件
在job文件夹下创建Flume Agent 配置文件 flume-dir-hdfs.conf
cd /opt/module/flume/job
vi flume-dir-hdfs.conf
#01、02 给 Agent a2 指定使用的组件
#使用的 Source 是 r2
#使用的 Sink 是 k2
#使用的 Channel 是 c2a2.sources = r2
a2.sinks = k2
a2.channels = c2#03 配置source
a2.sources.r2.type = spooldir
a2.sources.r2.spoolDir = /opt/module/flume/upload
a2.sources.r2.fileSuffix = .COMPLETED
a2.sources.r2.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a2.sources.r2.ignorePattern = ([^ ]*\.tmp)# 04配置sink:类型为hdfs、路径指定hdfs
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop001:9820/flume/upload/%Y%m%d/%H#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = upload-
#下面3行表示每小时创建一个文件夹
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream#生成新文件的条件:时间60秒,大小约128M、生成环境一般是3600s
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0# 05 配置通道:方式、最多缓存Event个数、每次事务最多处理的Event个数
# 作为 Source 和 Sink 之间的“中转站”,缓解两者速度不一致的问题
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100# 06 连接通道:a2源的组件r2使用通道 c2,a2源的组件k2使用通道 c2,
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
3、创建脚本
vi /opt/module/genarete_log.sh
#!/bin/bash
for i in {1..100}; do
echo "$i linux生成1-100的数字的for循环" >> /opt/module/flume/upload/test01.log
echo "$i linux生成1-100的数字的for循环" >> /opt/module/flume/upload/test02.log
echo "$i linux生成1-100的数字的for循环" >> /opt/module/flume/upload/test03.log
donetail -3 /opt/module/flume/upload/test01.log
tail -3 /opt/module/flume/upload/test02.log
tail -3 /opt/module/flume/upload/test03.log
4、启动HDFS
如果已经启动,则忽略
/opt/module/hadoop/bin/start-dfs.sh
/opt/module/hadoop/sbin/start-yarn.sh
如果hadoop未安装请走这个门:Hadoop安装传送门
5、启动Flume
启动flume,使用 cnc,即--conf 目录 --name agent 名称 --conf-file 配置文件 顺序不固定
cd /opt/module/flume
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-dir-hdfs.conf
6、执行脚本
执行脚本,在hdfs上查看结果
/opt/module/genarete_log.sh
hdfs dfs -ls /flume
7、结束进程
ps -ef | grep flume | grep -v grep | awk '{print $2}' | xargs kill -9
六、实时监控目录下多个新文件
Exec source适用于监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;而Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
在上面的基础上进行增加需求,让 flume 监控 /opt/module/flume/files 整个目录的实时追加文件,并上传至HDFS。
1、创建监控目录
mkdir /opt/module/flume/files
2、创建 Flume Agent 配置文件
在job文件夹下创建Flume Agent 配置文件 flume-dir-hdfs.conf
cd /opt/module/flume/job
vi flume-dir-hdfs.conf
#01、02 给 Agent a2 指定使用的组件
#使用的 Source 是 r2
#使用的 Sink 是 k2
#使用的 Channel 是 c2a3.sources = r3
a3.sinks = k3
a3.channels = c3#03 配置source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.*
# 04配置sink:类型为hdfs、路径指定hdfs
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:9820/flume/upload/%Y%m%d/%H#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#下面3行表示每小时创建一个文件夹
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream#生成新文件的条件:时间60秒,大小约128M、生成环境一般是3600s
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0# 05 配置通道:方式、最多缓存Event个数、每次事务最多处理的Event个数
# 作为 Source 和 Sink 之间的“中转站”,缓解两者速度不一致的问题
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100# 06 连接通道:a2源的组件r2使用通道 c2,a2源的组件k2使用通道 c2,
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
3、创建脚本
vi /opt/module/genarete_log.sh
#!/bin/bash
for i in {1..100}; do
echo "$i linux生成1-100的数字的for循环" >> /opt/module/flume/upload/test01.log
echo "$i linux生成1-100的数字的for循环" >> /opt/module/flume/upload/test02.log
echo "$i linux生成1-100的数字的for循环" >> /opt/module/flume/upload/test03.log
donetail -3 /opt/module/flume/upload/test01.log
tail -3 /opt/module/flume/upload/test02.log
tail -3 /opt/module/flume/upload/test03.log
4、启动HDFS
如果已经启动,则忽略
/opt/module/hadoop/bin/start-dfs.sh
/opt/module/hadoop/sbin/start-yarn.sh
如果hadoop未安装请走这个门:Hadoop安装传送门
5、启动Flume
启动flume,使用 cnc,即--conf 目录 --name agent 名称 --conf-file 配置文件 顺序不固定
cd /opt/module/flume
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-dir-hdfs.conf
6、执行脚本
执行脚本,在hdfs上查看结果
/opt/module/genarete_log.sh
hdfs dfs -ls /flume
7、结束进程
ps -ef | grep flume | grep -v grep | awk '{print $2}' | xargs kill -9