大数据Hadoop之——安装部署hadoop
目录
前期准备
一、JDK的安装
1、安装jdk
2、配置Java环境变量
3、加载环境变量
4、进行校验
二、hadoop的环境搭建
1、hadoop的下载安装
2、配置文件设置
2.1. 配置 hadoop-env.sh
2.2. 配置 core-site.xml
2.3. 配置 hdfs-site.xml
2.4. 配置 yarn-site.xml
2.5. 配置 mapred-site.xml
3、Hdfs格式化
4、启动hdfs
5、访问HDFS系统
6、启动yarn
7、访问Yarn平台页面
8、Hadoop的集群模式(伪分布式省略)
8.1.集群规划
8.2.设置免密登陆
8.3.修改hdfs-site.xml
8.4.修改workers
8.5.修改mapred-site.xml
8.6.修改yarn-site.xml
8.7.分发文件
8.8.停止服务删除目录
8.9.重启服务
三、msyql安装
1、卸载旧MySQL文件
2、Mysql下载安装
3、配置环境变量
4、删除用户组
5、创建用户和组
6、创建文件夹
7、更改权限
8、安装依赖包
9、初始化
10、记住初始密码
11、将mysql加入到服务中
12、配置文件
(1)Mysql5.X版本配置
(2)Mysql8.X版本配置
13、设置开机启动
14、并查看进程
15、创建软连接
16、登录 Mysql
17、修改密码
(1)Mysql5.X版本修改密码
(2)Mysql8.X版本修改密码
18、授权
(1)Mysql5.X版本授权
(2)Mysql8.X版本授权
四、HIve安装
1、下载安装
2、配置环境变量
3、配置文件
4、拷贝jar包
5、初始化
6、启动hive
五、问题与说明:
前期准备
查看网卡:
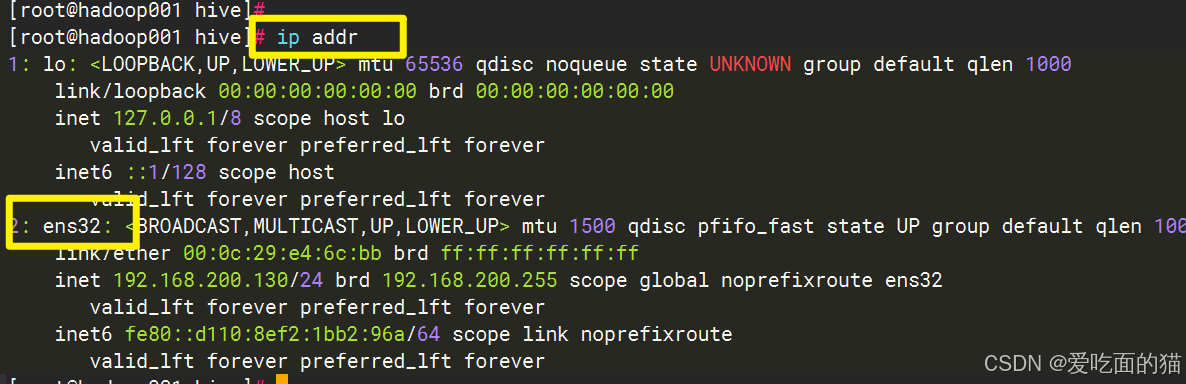
配置静态IP
vi /etc/sysconfig/network-scripts/ifcfg-ens32 ---- 根据自己网卡设置。

设置主机名
hostnamectl --static set-hostname 主机名
例如:
hostnamectl --static set-hostname hadoop001
配置IP与主机名映射
vi /etc/hosts

关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
配置免密登录
传送门
一、JDK的安装
1、安装jdk
在/opt/model中上传jdk包并解压
tar -zxvf jdk-8u151-linux-x64.tar.gz
重命名,方便配置环境变量,避免更换jdk版本修改配置文件
2、配置Java环境变量
| 系统级(全局) |
| 对所有用户生效 |
| 用户级(个人) |
| 只对当前用户生效 |
|
| ✅ 几乎所有 Linux/Unix 系统都有 | Ubuntu、CentOS、macOS 等 |
|
| ✅ CentOS/RHEL 系统使用 | CentOS、RHEL、Fedora |
|
| ✅ Ubuntu 使用 | Ubuntu、Debian |
|
| ✅ 用户可创建 | 所有支持 Bash 的系统 |
|
| ✅ Ubuntu 默认生成 | Ubuntu、Debian |
|
| ✅ 用户级 shell 配置 | 所有支持 Bash 的系统 |
vi /etc/profile
export JAVA_HOME=/opt/module/java #此处是自己实际的Java安装路径
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3、加载环境变量
source /etc/profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
4、进行校验

二、hadoop的环境搭建
1、hadoop的下载安装
1.1. 下载
https://archive.apache.org/dist/hadoop/common/hadoop-3.2.2/
下载 hadoop-3.2.2.tar.gz 安装包1.2 上传
使用xshell上传到指定安装路径此处是安装路径是 /opt/module
1.3 解压重命名
tar -xzvf hadoop-3.2.2.tar.gz
mv hadoop-3.2.2 hadoop
1.4 配置环境变量
vi /etc/profile
export JAVA_HOME=/opt/module/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1.5 加载环境变量
source /etc/profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
1.6检验安装
hadoop version
出现下图说明安装成功
2、配置文件设置
2.1. 配置 hadoop-env.sh
hadoop伪分布式配置
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/opt/module/java
2.2. 配置 core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 默认 9000端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
<description>配置NameNode的URL</description>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>配置hive内容(下面要安装hive,因此需要增加下面内容,否则不添加)
<!-- 配置允许哪些主机上的程序可以以root身份发起代理请求 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property><!-- 配置允许哪些组的用户可以以root身份发起代理请求 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property><!-- 配置允许哪些具体用户可以以root身份发起代理请求-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
2.3. 配置 hdfs-site.xml
<configuration>
<!-- 数据的副本数量 如果是完全分布式的集群模式,则改为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/data/datanode</value>
</property>
<!--设置权限为false-->
<property>
<name>dfs.permissions.enabled </name>
<value>false</value>
</property>
<!-- hdfs的web管理页面的端口 -->
<property>
<name>dfs.http.address</name>
<value>hadoop001:9870</value>
</property>
<!-- 设置secondname的端口,如果是完全分布式的集群模式,则改为hadoop003 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop001:6002</value>
</property>
</configuration>
2.4. 配置 yarn-site.xml
<configuration>
<!-- 指定MR走shuffle -->
<!-- NodeManager 上运行的辅助服务(auxiliary services),用于支持 MapReduce 的 shuffle 阶段 -->
<!-- 必须启用才能让 YARN 支持 MapReduce 的 shuffle 功能 -->
<!-- 如果你使用的是 Spark 或其他框架,可能不需要这个配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<!-- NodeManager 和 ApplicationMaster 会通过该主机名连接到 ResourceManager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
<!-- 环境变量的继承 -->
<!-- 允许传递给容器的环境变量白名单 -->
<!-- 设置哪些环境变量可以从 NodeManager 传递给启动的应用程序容器(Container) -->
<!-- 默认情况下,YARN 容器不会继承所有的系统环境变量 -->
<!-- 为了保证任务能正常运行,需要将必要的环境变量加入白名单 -->
<!-- 常见如 JAVA_HOME、Hadoop 相关路径等,都是应用程序运行所必需的 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn单个容器允许分配的最大最小内存 -->
<!--如果应用请求的内存小于这个值,YARN 会自动将其提升为这个最小值 -->
<!--示例:如果某个任务只申请 100 MB,但设置了最小为 512,则实际分配 512 MB -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!--如果应用请求的内存超过这个值,YARN 会拒绝该请求 -->
<!--这个值不能超过 NodeManager 的总内存容量-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<!-- 指定当前 NodeManager 节点可提供给容器使用的最大物理内存总量(单位:MB)-->
<!-- 这个值决定了该节点最多能运行多少个容器,取决于每个容器的内存需求。-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<!-- 是否启用对容器使用的物理内存 进行检查 -->
<!-- 设为 true,YARN 会在容器超出其申请的物理内存时终止它 -->
<!-- 防止某些任务占用过多内存导致整个节点崩溃。 -->
<!-- 推荐生产环境中保持为 true。 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>true</value>
</property>
<!-- 是否开启虚拟内存检查 -->
<!-- 若设为 true,YARN 会检查虚拟内存使用情况并可能杀掉超限任务 -->
<!-- 有时虚拟内存使用较高是正常的(例如 JVM),所以部分场景下建议关闭此功能 设为Flase -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
2.5. 配置 mapred-site.xml
<configuration>
<!-- mr程序默认运行方式。yarn集群模式 local本地模式--><!-- 设置 MapReduce 应用程序的执行框架为 YARN 即 MR运行的资源调度模式--->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property><!-- 以下可以不用配置,作为了解内容
当 YARN 启动 MapReduce (ApplicationMaster、MapTask、ReduceTask)进程提供一致的环境变量,确保找到 MapReduce 的依赖库和资源路径。-->
<!-- MR App Master环境变量。用于告诉 ApplicationMaster 去哪里找 MapReduce 相关的 JAR 包或脚本-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 为每个 MR 的 MapTask 设置环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- 为每个 MR 的 ReduceTask 设置环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
3、Hdfs格式化
cd /opt/module/hadoop/
bin/hdfs namenode -format
下图表示初始化成功
4、启动hdfs
启动hdfs分布式文件系统
cd /opt/module//hadoop/sbin
>> start-dfs.sh
使用 jps 查看启动进程
5、访问HDFS系统
访问HDFS分布式文件系统的web页面,如:http://192.168.200.130:9870/
6、启动yarn
启动Yarn进程。
cd /opt/module/hadoop/sbin
>> start-yarn.sh
使用 jps 查看启动进程
7、访问Yarn平台页面
访问hadoop分布式yarn页面,如:http://192.168.200.130:8088/
8、Hadoop的集群模式(伪分布式省略)
如果是伪分布式模式,此过程可以省略。
8.1.集群规划
| 模块 | hadoop001 | hadoop002 | hadoop003 |
| HDFS子进程 | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN子进程 | NodeManager | ResourceManager NodeManager | NodeManager |
8.2.设置免密登陆
配置集群免密登录
传送门
8.3.修改hdfs-site.xml
修改数据的副本数量
secondname的主机设置(可选)
<!-- 数据的副本数量 改为3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property><!--可选 对于学习来说,可以不改。但实际生产过时会将其规划到 hadoop003 -->
<!-- 设置secondname的端口,完全分布式的集群模式,改为hadoop003 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:6002</value>
</property>
8.4.修改workers
将原来的localhost改为节点主机名
hadoop001
hadoop002
hadoop003
8.5.修改mapred-site.xml
配置历史服务器(可选)
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
8.6.修改yarn-site.xml
指定ResourceManager的地址:对于目前学习来说不改也可以,但在实际生产过程中 resourcemanager 和 namenode是在不同主机上,避免生产过程中资源不足导致内存溢出情况。
指定ResourceManager的地址(可选)
配置日志的聚集(可选)
<!-- 可选 指定ResourceManager的地址-->
<!-- NodeManager 和 ApplicationMaster 会通过该主机名连接到 ResourceManager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property><!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
8.7.分发文件
注意:在分发文件前要做好三台机器的IP与主机名映射 /etc/hosts
进行分发文件
scp -r /opt/module/hadoop root@hadoop002:/opt/module/hadoop
scp -r /opt/module/hadoop root@hadoop003:/opt/module/hadoop
scp -r /opt/module/java root@hadoop002:/opt/module/java
scp -r /opt/module/java root@hadoop003:/opt/module/java
scp -r /etc/profile root@hadoop002:/etc/profile
scp -r /etc/profile root@hadoop003:/etc/profile
让三台机器文件生效
ssh hadoop001 "source /etcprofile"
ssh hadoop002 "source /etcprofile"
ssh hadoop003 "source /etcprofile"
8.8.停止服务删除目录
停止服务
cd /opt/module/hadoop/sbin
>> stop-all.sh
删除格式化后的目录重新格式化
rm -rf /opt/module/hadoop/data
rm -rf /opt/module/hadoop/logs/*
/opt/module/hadoop/bin/hdfs namenode -format
8.9.重启服务
在hadoop001 上启动HDFS
cd /opt/module/hadoop/sbin
>> start-dfs.sh
在hadoop002 上启动YARN
cd /opt/module/hadoop/sbin
>> start-yarn.sh
群起脚本:
touch /usr/bin/hdall.sh
chmod 777 /usr/bin/hdall.sh
vi /usr/bin/hdall.sh
#!/bin/bash if [ $# -lt 1 ] thenecho "No Args Input..."exit ; fi case $1 in "start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop001 "/opt/module/hadoop/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop002 "/opt/module/hadoop/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop001 "/opt/module/hadoop/bin/mapred --daemon start historyserver" ;; "stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop001 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop002 "/opt/module/hadoop/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop001 "/opt/module/hadoop/sbin/stop-dfs.sh" ;; *)echo "Input Args Error..." ;; esac群起:/usr/bin/hdall.sh start
群停:/usr/bin/hdall.sh stop
如果:ResourceManager的地址和secondname的地址都是hadoop001,则在hadoop001 上启动HDFS和YARN
cd /opt/module/hadoop/sbin
>> start-all.sh