DAY 40 训练和测试的规范写法
目录
- DAY 40 训练和测试的规范写法
- 1.彩色和灰度图片测试和训练的规范写法:封装在函数中
- 2.展平操作:除第一个维度batchsize外全部展平
- 3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
- 作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
DAY 40 训练和测试的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore')
torch.manual_seed(42)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'使用设备: {device}')使用设备: cpu
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))
])train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten()self.layer1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.layer2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x)x = self.layer1(x)x = self.relu(x)x = self.layer2(x)return xmodel = MLP()
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 404: Not FoundDownloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz to ./data\MNIST\raw\train-images-idx3-ubyte.gz100%|██████████| 9912422/9912422 [00:03<00:00, 2855834.01it/s]Extracting ./data\MNIST\raw\train-images-idx3-ubyte.gz to ./data\MNIST\rawDownloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 404: Not FoundDownloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz to ./data\MNIST\raw\train-labels-idx1-ubyte.gz100%|██████████| 28881/28881 [00:00<00:00, 198481.26it/s]Extracting ./data\MNIST\raw\train-labels-idx1-ubyte.gz to ./data\MNIST\rawDownloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 404: Not FoundDownloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz to ./data\MNIST\raw\t10k-images-idx3-ubyte.gz100%|██████████| 1648877/1648877 [00:00<00:00, 2210153.70it/s]Extracting ./data\MNIST\raw\t10k-images-idx3-ubyte.gz to ./data\MNIST\rawDownloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 404: Not FoundDownloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz to ./data\MNIST\raw\t10k-labels-idx1-ubyte.gz100%|██████████| 4542/4542 [00:00<00:00, 3317173.74it/s]Extracting ./data\MNIST\raw\t10k-labels-idx1-ubyte.gz to ./data\MNIST\raw
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train()all_iter_losses = []iter_indices = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_accdef test(model, test_loader, criterion, device):model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()epochs = 2
print('开始训练模型')
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f'训练完成!最终测试准确率: {final_accuracy:.2f}%')开始训练模型
Epoch: 1/2 | Batch: 100/938 | 单Batch损失: 0.3583 | 累计平均损失: 0.6321
Epoch: 1/2 | Batch: 200/938 | 单Batch损失: 0.2035 | 累计平均损失: 0.4776
Epoch: 1/2 | Batch: 300/938 | 单Batch损失: 0.3044 | 累计平均损失: 0.4053
Epoch: 1/2 | Batch: 400/938 | 单Batch损失: 0.1427 | 累计平均损失: 0.3669
Epoch: 1/2 | Batch: 500/938 | 单Batch损失: 0.1742 | 累计平均损失: 0.3321
Epoch: 1/2 | Batch: 600/938 | 单Batch损失: 0.3089 | 累计平均损失: 0.3104
Epoch: 1/2 | Batch: 700/938 | 单Batch损失: 0.0456 | 累计平均损失: 0.2921
Epoch: 1/2 | Batch: 800/938 | 单Batch损失: 0.1008 | 累计平均损失: 0.2763
Epoch: 1/2 | Batch: 900/938 | 单Batch损失: 0.3017 | 累计平均损失: 0.2629
Epoch 1/2 完成 | 训练准确率: 92.43% | 测试准确率: 95.90%
Epoch: 2/2 | Batch: 100/938 | 单Batch损失: 0.1727 | 累计平均损失: 0.1358
Epoch: 2/2 | Batch: 200/938 | 单Batch损失: 0.1767 | 累计平均损失: 0.1291
Epoch: 2/2 | Batch: 300/938 | 单Batch损失: 0.1239 | 累计平均损失: 0.1283
Epoch: 2/2 | Batch: 400/938 | 单Batch损失: 0.2098 | 累计平均损失: 0.1233
Epoch: 2/2 | Batch: 500/938 | 单Batch损失: 0.0214 | 累计平均损失: 0.1206
Epoch: 2/2 | Batch: 600/938 | 单Batch损失: 0.0557 | 累计平均损失: 0.1190
Epoch: 2/2 | Batch: 700/938 | 单Batch损失: 0.0964 | 累计平均损失: 0.1169
Epoch: 2/2 | Batch: 800/938 | 单Batch损失: 0.1627 | 累计平均损失: 0.1152
Epoch: 2/2 | Batch: 900/938 | 单Batch损失: 0.0743 | 累计平均损失: 0.1138
Epoch 2/2 完成 | 训练准确率: 96.64% | 测试准确率: 96.88%

训练完成!最终测试准确率: 96.88%
1.彩色和灰度图片测试和训练的规范写法:封装在函数中
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsetransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten()self.layer1 = nn.Linear(3072, 512)self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2)self.layer2 = nn.Linear(512, 256)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10)def forward(self, x):x = self.flatten(x)x = self.layer1(x)x = self.relu1(x)x = self.dropout1(x)x = self.layer2(x)x = self.relu2(x)x = self.dropout2(x)x = self.layer3(x)return xdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MLP()
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train()all_iter_losses = []iter_indices = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalmodel.eval()test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_accdef plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()epochs = 20
print('开始训练模型')
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f'训练完成!最终测试准确率: {final_accuracy:.2f}%')Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data\cifar-10-python.tar.gz100%|██████████| 170498071/170498071 [00:35<00:00, 4780112.62it/s]Extracting ./data\cifar-10-python.tar.gz to ./data
开始训练模型
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.7732 | 累计平均损失: 1.8981
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.6471 | 累计平均损失: 1.8393
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.7511 | 累计平均损失: 1.7947
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.5363 | 累计平均损失: 1.7685
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.5352 | 累计平均损失: 1.7442
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5442 | 累计平均损失: 1.7289
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.8925 | 累计平均损失: 1.7173
Epoch 1/20 完成 | 训练准确率: 39.22% | 测试准确率: 45.28%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.4810 | 累计平均损失: 1.4966
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.2716 | 累计平均损失: 1.4743
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.6746 | 累计平均损失: 1.4692
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.5636 | 累计平均损失: 1.4705
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.4655 | 累计平均损失: 1.4657
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.5598 | 累计平均损失: 1.4637
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.2325 | 累计平均损失: 1.4583
Epoch 2/20 完成 | 训练准确率: 48.45% | 测试准确率: 49.27%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.4159 | 累计平均损失: 1.3323
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.4548 | 累计平均损失: 1.3254
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.3436 | 累计平均损失: 1.3367
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.6763 | 累计平均损失: 1.3415
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.4215 | 累计平均损失: 1.3389
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.2557 | 累计平均损失: 1.3402
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.3083 | 累计平均损失: 1.3402
Epoch 3/20 完成 | 训练准确率: 52.51% | 测试准确率: 50.57%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 1.5810 | 累计平均损失: 1.2409
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 1.3196 | 累计平均损失: 1.2310
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 1.2563 | 累计平均损失: 1.2342
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 1.2675 | 累计平均损失: 1.2394
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 1.1705 | 累计平均损失: 1.2454
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 1.2095 | 累计平均损失: 1.2483
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 1.3069 | 累计平均损失: 1.2480
Epoch 4/20 完成 | 训练准确率: 55.97% | 测试准确率: 51.87%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.9455 | 累计平均损失: 1.1147
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 1.1351 | 累计平均损失: 1.1304
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 1.3300 | 累计平均损失: 1.1419
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 1.3341 | 累计平均损失: 1.1519
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 1.0595 | 累计平均损失: 1.1535
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 1.0165 | 累计平均损失: 1.1601
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 1.1673 | 累计平均损失: 1.1608
Epoch 5/20 完成 | 训练准确率: 58.90% | 测试准确率: 52.45%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 1.0966 | 累计平均损失: 1.0343
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.9085 | 累计平均损失: 1.0400
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 1.1897 | 累计平均损失: 1.0479
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 1.4776 | 累计平均损失: 1.0613
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 1.1597 | 累计平均损失: 1.0652
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.8775 | 累计平均损失: 1.0684
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 1.1629 | 累计平均损失: 1.0747
Epoch 6/20 完成 | 训练准确率: 61.49% | 测试准确率: 52.80%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 1.0544 | 累计平均损失: 0.9590
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 1.2092 | 累计平均损失: 0.9715
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 1.2537 | 累计平均损失: 0.9753
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.9531 | 累计平均损失: 0.9850
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 1.1590 | 累计平均损失: 0.9891
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 1.3759 | 累计平均损失: 0.9978
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 1.0341 | 累计平均损失: 1.0022
Epoch 7/20 完成 | 训练准确率: 64.19% | 测试准确率: 52.63%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.6753 | 累计平均损失: 0.8942
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.8325 | 累计平均损失: 0.8979
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 1.1172 | 累计平均损失: 0.8938
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 1.3463 | 累计平均损失: 0.9077
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.8854 | 累计平均损失: 0.9107
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 1.1968 | 累计平均损失: 0.9170
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 1.2687 | 累计平均损失: 0.9239
Epoch 8/20 完成 | 训练准确率: 66.89% | 测试准确率: 53.46%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.7985 | 累计平均损失: 0.8394
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.6087 | 累计平均损失: 0.8401
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.7421 | 累计平均损失: 0.8361
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 1.4031 | 累计平均损失: 0.8425
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 1.0196 | 累计平均损失: 0.8442
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 1.1629 | 累计平均损失: 0.8505
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.9443 | 累计平均损失: 0.8568
Epoch 9/20 完成 | 训练准确率: 68.96% | 测试准确率: 54.29%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.6086 | 累计平均损失: 0.7374
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.9004 | 累计平均损失: 0.7504
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.9660 | 累计平均损失: 0.7589
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.9107 | 累计平均损失: 0.7718
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.9115 | 累计平均损失: 0.7792
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.7202 | 累计平均损失: 0.7810
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.8665 | 累计平均损失: 0.7839
Epoch 10/20 完成 | 训练准确率: 71.82% | 测试准确率: 53.79%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.6894 | 累计平均损失: 0.6863
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.8927 | 累计平均损失: 0.6863
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.6811 | 累计平均损失: 0.6941
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.7599 | 累计平均损失: 0.7046
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.8333 | 累计平均损失: 0.7105
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.8249 | 累计平均损失: 0.7176
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.6940 | 累计平均损失: 0.7246
Epoch 11/20 完成 | 训练准确率: 74.19% | 测试准确率: 53.56%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.5904 | 累计平均损失: 0.6165
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.5994 | 累计平均损失: 0.6221
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.6336 | 累计平均损失: 0.6270
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.6264 | 累计平均损失: 0.6372
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.6624 | 累计平均损失: 0.6494
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.5770 | 累计平均损失: 0.6578
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.6652 | 累计平均损失: 0.6634
Epoch 12/20 完成 | 训练准确率: 76.09% | 测试准确率: 53.38%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.6848 | 累计平均损失: 0.5914
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.5379 | 累计平均损失: 0.5759
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.3208 | 累计平均损失: 0.5873
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.7905 | 累计平均损失: 0.5923
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.5012 | 累计平均损失: 0.6018
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.6495 | 累计平均损失: 0.6097
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.6623 | 累计平均损失: 0.6164
Epoch 13/20 完成 | 训练准确率: 77.78% | 测试准确率: 53.31%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.5565 | 累计平均损失: 0.5345
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.7153 | 累计平均损失: 0.5319
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.5568 | 累计平均损失: 0.5416
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.6638 | 累计平均损失: 0.5467
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.5136 | 累计平均损失: 0.5536
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.3919 | 累计平均损失: 0.5615
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.5899 | 累计平均损失: 0.5664
Epoch 14/20 完成 | 训练准确率: 79.89% | 测试准确率: 53.60%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.4651 | 累计平均损失: 0.4772
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.4554 | 累计平均损失: 0.4780
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.3977 | 累计平均损失: 0.4857
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.6845 | 累计平均损失: 0.4994
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.3758 | 累计平均损失: 0.5076
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.4383 | 累计平均损失: 0.5151
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.7366 | 累计平均损失: 0.5244
Epoch 15/20 完成 | 训练准确率: 81.36% | 测试准确率: 52.56%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.4499 | 累计平均损失: 0.4447
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.3819 | 累计平均损失: 0.4489
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.6538 | 累计平均损失: 0.4546
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.4083 | 累计平均损失: 0.4648
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.3803 | 累计平均损失: 0.4701
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.6383 | 累计平均损失: 0.4812
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.7126 | 累计平均损失: 0.4893
Epoch 16/20 完成 | 训练准确率: 82.34% | 测试准确率: 52.91%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.2843 | 累计平均损失: 0.4107
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.5243 | 累计平均损失: 0.4138
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.3653 | 累计平均损失: 0.4217
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.4550 | 累计平均损失: 0.4289
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.4960 | 累计平均损失: 0.4365
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.3528 | 累计平均损失: 0.4431
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.3836 | 累计平均损失: 0.4504
Epoch 17/20 完成 | 训练准确率: 83.72% | 测试准确率: 52.43%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.3644 | 累计平均损失: 0.3817
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.1973 | 累计平均损失: 0.3866
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.6580 | 累计平均损失: 0.3881
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.4780 | 累计平均损失: 0.3949
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.4676 | 累计平均损失: 0.4110
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.3384 | 累计平均损失: 0.4249
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.5635 | 累计平均损失: 0.4333
Epoch 18/20 完成 | 训练准确率: 84.44% | 测试准确率: 53.54%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.4225 | 累计平均损失: 0.3470
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.4426 | 累计平均损失: 0.3524
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.4427 | 累计平均损失: 0.3603
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.3880 | 累计平均损失: 0.3691
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.2474 | 累计平均损失: 0.3761
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.3487 | 累计平均损失: 0.3859
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.3082 | 累计平均损失: 0.3889
Epoch 19/20 完成 | 训练准确率: 85.88% | 测试准确率: 52.34%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.3529 | 累计平均损失: 0.3475
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.3874 | 累计平均损失: 0.3507
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.3167 | 累计平均损失: 0.3514
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.3228 | 累计平均损失: 0.3541
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.2819 | 累计平均损失: 0.3651
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.3354 | 累计平均损失: 0.3697
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.3575 | 累计平均损失: 0.3769
Epoch 20/20 完成 | 训练准确率: 86.56% | 测试准确率: 53.39%
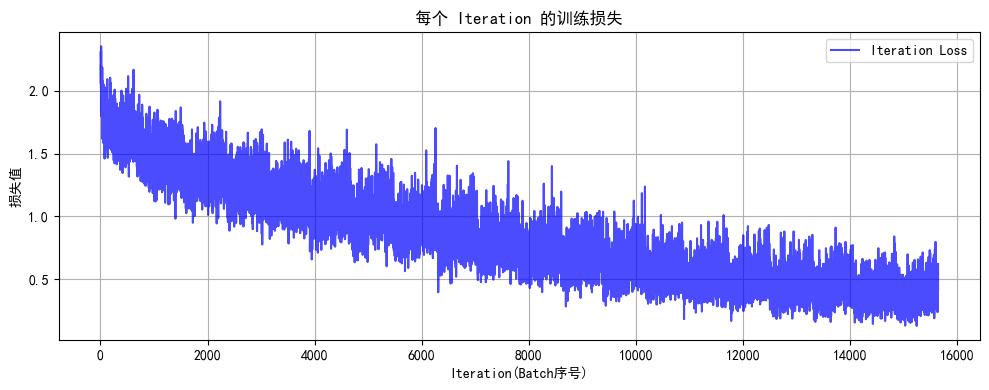
训练完成!最终测试准确率: 53.39%
2.展平操作:除第一个维度batchsize外全部展平
# import torch
# import torch.nn as nn
# import torch.optim as optim
# from torchvision import datasets, transforms
# from torch.utils.data import DataLoader
# import matplotlib.pyplot as plt
# import numpy as np# plt.rcParams['font.family'] = ['SimHei']
# plt.rcParams['axes.unicode_minus'] = False# transform = transforms.Compose([
# transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
# ])# train_dataset = datasets.MNIST(
# root='./data',
# train=True,
# download=True,
# transform=transform
# )# test_dataset = datasets.MNIST(
# root='./data',
# train=False,
# transform=transform
# )# batch_size = 64
# train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# class MLP(nn.Module):
# def __init__(self):
# super(MLP, self).__init__()
# self.flatten = nn.Flatten()
# self.layer1 = nn.Linear(784, 128)
# self.relu = nn.ReLU()
# self.layer2 = nn.Linear(128, 10)# def forward(self, x):
# x = self.flatten(x)
# x = self.layer1(x)
# x = self.relu(x)
# x = self.layer2(x)
# return x# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# model = MLP()
# model = model.to(device)
# criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model.parameters(), lr=0.001)# def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):
# model.train()
# all_iter_losses = []
# iter_indices = []# for epoch in range(epochs):
# running_loss = 0.0
# correct = 0
# total = 0# for batch_idx, (data, target) in enumerate(train_loader):
# data, target = data.to(device), target.to(device)
# optimizer.zero_grad()
# output = model(data)
# loss = criterion(output, target)
# loss.backward()
# optimizer.step()
# iter_loss = loss.item()
# all_iter_losses.append(iter_loss)
# iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# running_loss += iter_loss
# _, predicted = output.max(1)
# total += target.size(0)
# correct += predicted.eq(target).sum().item()# if (batch_idx + 1) % 100 == 0:
# print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
# f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# epoch_train_loss = running_loss / len(train_loader)
# epoch_train_acc = 100. * correct / total
# epoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)# print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# plot_iter_losses(all_iter_losses, iter_indices)
# return epoch_test_acc# def test(model, test_loader, criterion, device):
# model.eval()
# test_loss = 0
# correct = 0
# total = 0# with torch.no_grad():
# for data, target in test_loader:
# data, target = data.to(device), target.to(device)
# output = model(data)
# test_loss += criterion(output, target).item()
# _, predicted = output.max(1)
# total += target.size(0)
# correct += predicted.eq(target).sum().item()# avg_loss = test_loss / len(test_loader)
# accuracy = 100. * correct / total
# return avg_loss, accuracy# def plot_iter_losses(losses, indices):
# plt.figure(figsize=(10, 4))
# plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
# plt.xlabel('Iteration(Batch序号)')
# plt.ylabel('损失值')
# plt.title('每个 Iteration 的训练损失')
# plt.legend()
# plt.grid(True)
# plt.tight_layout()
# plt.show()# epochs = 2
# print('开始训练模型')
# final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
# print(f'训练完成!最终测试准确率: {final_accuracy:.2f}%')3.dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
epochs = 20
print('开始训练模型')
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f'训练完成!最终测试准确率: {final_accuracy:.2f}%')开始训练模型
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.0421 | 累计平均损失: 1.3274
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.1441 | 累计平均损失: 1.2546
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.1194 | 累计平均损失: 1.1966
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.1273 | 累计平均损失: 1.1570
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 0.8041 | 累计平均损失: 1.1449
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.2706 | 累计平均损失: 1.1277
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.1725 | 累计平均损失: 1.1108
Epoch 1/20 完成 | 训练准确率: 63.36% | 测试准确率: 52.21%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 0.4745 | 累计平均损失: 0.4680
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 0.2843 | 累计平均损失: 0.4122
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 0.4399 | 累计平均损失: 0.3907
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 0.3331 | 累计平均损失: 0.3760
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 0.3666 | 累计平均损失: 0.3657
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 0.3130 | 累计平均损失: 0.3620
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 0.4271 | 累计平均损失: 0.3608
Epoch 2/20 完成 | 训练准确率: 87.47% | 测试准确率: 53.55%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 0.3675 | 累计平均损失: 0.2823
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 0.2487 | 累计平均损失: 0.2693
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 0.2173 | 累计平均损失: 0.2759
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 0.3093 | 累计平均损失: 0.2839
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 0.3487 | 累计平均损失: 0.2960
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 0.3246 | 累计平均损失: 0.3030
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 0.1797 | 累计平均损失: 0.3087
Epoch 3/20 完成 | 训练准确率: 88.97% | 测试准确率: 53.19%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 0.2298 | 累计平均损失: 0.3038
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 0.3283 | 累计平均损失: 0.3002
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 0.2966 | 累计平均损失: 0.3012
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 0.3005 | 累计平均损失: 0.3085
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.1612 | 累计平均损失: 0.3123
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.4447 | 累计平均损失: 0.3194
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.2845 | 累计平均损失: 0.3280
Epoch 4/20 完成 | 训练准确率: 88.34% | 测试准确率: 52.88%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.2228 | 累计平均损失: 0.2820
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.2261 | 累计平均损失: 0.2765
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 0.3605 | 累计平均损失: 0.2760
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.1412 | 累计平均损失: 0.2804
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.4173 | 累计平均损失: 0.2919
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.3003 | 累计平均损失: 0.3020
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.3662 | 累计平均损失: 0.3096
Epoch 5/20 完成 | 训练准确率: 88.86% | 测试准确率: 53.05%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.2729 | 累计平均损失: 0.2598
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.4152 | 累计平均损失: 0.2746
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.2788 | 累计平均损失: 0.2787
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.4672 | 累计平均损失: 0.2939
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.3952 | 累计平均损失: 0.2988
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.5510 | 累计平均损失: 0.2970
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.4184 | 累计平均损失: 0.3002
Epoch 6/20 完成 | 训练准确率: 89.26% | 测试准确率: 52.48%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.3532 | 累计平均损失: 0.2708
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.3211 | 累计平均损失: 0.2749
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.2098 | 累计平均损失: 0.2771
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.2623 | 累计平均损失: 0.2816
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 0.4176 | 累计平均损失: 0.2904
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.3794 | 累计平均损失: 0.2981
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.3561 | 累计平均损失: 0.3011
Epoch 7/20 完成 | 训练准确率: 89.36% | 测试准确率: 51.78%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.2675 | 累计平均损失: 0.2859
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.3253 | 累计平均损失: 0.2799
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.4065 | 累计平均损失: 0.2759
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.2322 | 累计平均损失: 0.2751
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.3637 | 累计平均损失: 0.2725
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.1005 | 累计平均损失: 0.2770
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.3827 | 累计平均损失: 0.2798
Epoch 8/20 完成 | 训练准确率: 90.00% | 测试准确率: 52.14%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.1178 | 累计平均损失: 0.2397
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.4516 | 累计平均损失: 0.2386
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.3171 | 累计平均损失: 0.2384
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.1925 | 累计平均损失: 0.2437
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.1050 | 累计平均损失: 0.2457
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.3387 | 累计平均损失: 0.2555
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.4157 | 累计平均损失: 0.2621
Epoch 9/20 完成 | 训练准确率: 90.80% | 测试准确率: 52.48%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.1909 | 累计平均损失: 0.2598
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.1108 | 累计平均损失: 0.2497
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.1184 | 累计平均损失: 0.2504
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.2568 | 累计平均损失: 0.2501
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.3827 | 累计平均损失: 0.2530
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.3076 | 累计平均损失: 0.2600
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.2713 | 累计平均损失: 0.2682
Epoch 10/20 完成 | 训练准确率: 90.47% | 测试准确率: 52.18%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.2202 | 累计平均损失: 0.2567
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.3026 | 累计平均损失: 0.2745
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.1447 | 累计平均损失: 0.2678
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.1086 | 累计平均损失: 0.2626
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.1610 | 累计平均损失: 0.2599
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.2931 | 累计平均损失: 0.2596
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.4790 | 累计平均损失: 0.2576
Epoch 11/20 完成 | 训练准确率: 90.95% | 测试准确率: 52.55%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.1185 | 累计平均损失: 0.2072
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.1361 | 累计平均损失: 0.2060
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.1809 | 累计平均损失: 0.2077
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.2206 | 累计平均损失: 0.2147
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.1989 | 累计平均损失: 0.2246
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.3107 | 累计平均损失: 0.2372
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.1335 | 累计平均损失: 0.2431
Epoch 12/20 完成 | 训练准确率: 91.37% | 测试准确率: 52.01%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.5039 | 累计平均损失: 0.2393
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.3081 | 累计平均损失: 0.2366
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.2684 | 累计平均损失: 0.2398
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.2077 | 累计平均损失: 0.2435
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.1100 | 累计平均损失: 0.2441
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.0980 | 累计平均损失: 0.2441
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.2300 | 累计平均损失: 0.2484
Epoch 13/20 完成 | 训练准确率: 91.57% | 测试准确率: 51.74%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.2316 | 累计平均损失: 0.1822
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.2541 | 累计平均损失: 0.1873
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.2892 | 累计平均损失: 0.1937
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.2165 | 累计平均损失: 0.2013
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.3958 | 累计平均损失: 0.2091
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.5955 | 累计平均损失: 0.2225
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.2286 | 累计平均损失: 0.2325
Epoch 14/20 完成 | 训练准确率: 92.01% | 测试准确率: 53.11%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.2731 | 累计平均损失: 0.2031
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.1307 | 累计平均损失: 0.1951
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.1685 | 累计平均损失: 0.2001
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.2293 | 累计平均损失: 0.2135
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.3525 | 累计平均损失: 0.2113
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.3731 | 累计平均损失: 0.2108
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.3422 | 累计平均损失: 0.2121
Epoch 15/20 完成 | 训练准确率: 92.65% | 测试准确率: 52.82%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.1625 | 累计平均损失: 0.2306
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.1789 | 累计平均损失: 0.2235
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.1637 | 累计平均损失: 0.2197
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.1923 | 累计平均损失: 0.2254
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.2144 | 累计平均损失: 0.2286
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.1268 | 累计平均损失: 0.2320
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.1401 | 累计平均损失: 0.2321
Epoch 16/20 完成 | 训练准确率: 91.99% | 测试准确率: 52.97%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.2060 | 累计平均损失: 0.2027
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.1544 | 累计平均损失: 0.2115
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.3345 | 累计平均损失: 0.2158
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.3147 | 累计平均损失: 0.2182
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.1324 | 累计平均损失: 0.2196
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.2261 | 累计平均损失: 0.2253
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.0723 | 累计平均损失: 0.2303
Epoch 17/20 完成 | 训练准确率: 92.01% | 测试准确率: 52.18%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.2696 | 累计平均损失: 0.1800
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.0923 | 累计平均损失: 0.1835
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.2638 | 累计平均损失: 0.1876
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.3181 | 累计平均损失: 0.1992
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.0980 | 累计平均损失: 0.2054
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.1975 | 累计平均损失: 0.2115
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.1551 | 累计平均损失: 0.2133
Epoch 18/20 完成 | 训练准确率: 92.76% | 测试准确率: 52.71%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.1224 | 累计平均损失: 0.1828
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.1391 | 累计平均损失: 0.1785
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.1803 | 累计平均损失: 0.1722
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.0396 | 累计平均损失: 0.1768
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.2459 | 累计平均损失: 0.1875
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.2526 | 累计平均损失: 0.1962
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.3213 | 累计平均损失: 0.2012
Epoch 19/20 完成 | 训练准确率: 93.01% | 测试准确率: 52.98%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.1330 | 累计平均损失: 0.1884
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.1394 | 累计平均损失: 0.1952
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.1693 | 累计平均损失: 0.1943
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.1354 | 累计平均损失: 0.2035
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.3302 | 累计平均损失: 0.2067
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.2726 | 累计平均损失: 0.2072
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.1539 | 累计平均损失: 0.2088
Epoch 20/20 完成 | 训练准确率: 92.76% | 测试准确率: 51.91%
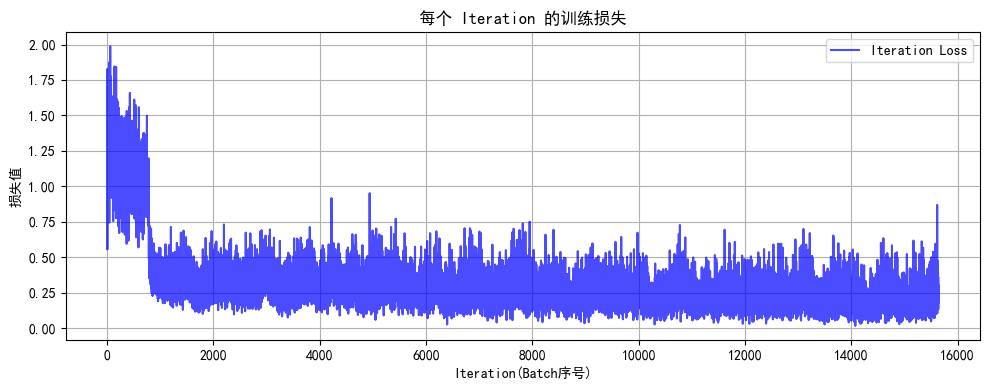
训练完成!最终测试准确率: 51.91%
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
@浙大疏锦行