C/Fortran多核并行计算
文章目录
- OpenMP基础
- 1、OpenMP(Open Multi-Processing)
- 2、 MPl (Message Passing Interface)
- 3、CUDA (Compute Unified Device Architecture) /OpenACC
- C/Fortran中OMP标记的说明
- OpenMP构造并行域
- OMP代码执行模式
- 文本范围(lexical extent)和动态范围(dynamic extent)
- 设置线程数
- 常用函数
- OMP线程数说明
- 嵌套并行域
- 子句
- OMP的数据属性
- if(b)
- numthreads (nT)
- default(private | firstprivate 丨 shared l(none)
- private(a,b, c... )
- firstprivate (a,b,c...)
- reduction(operator:list)
- copyin
- proc_bind
- allocate
- 指令
- sections
- 子句
- workshare
- single/master
- atomic/critical
- flush
- barrier
- for/do
- schedule子句
- collapse子句
- linear子句
- 参考
OpenMP基础
新的0penMP标准(目前是5.2)支持GPU设备(显卡或专业计算卡)加速,但现有的OMP库对该功能支持有限(intel oneAPl套件支持intel的显卡),因此Devices相关的指令不做介绍。
此外,锁操作、SIMD指令等也不作介绍,读者可参阅最新的官方文档:
- 《OpenMP Application Programming Interface》
- 网址
并行计算是一种同时执行多任务或处理多数据的技术:
1、多任务:将任务划分为多个片段(或块),然后使用多个
计算设备(或核心)分别、同时执行这些任务片段,以此达到减少计算耗时的目的。例如:OMP,MPI;
2、多数据:同时对多个数据执行相同操作,例如:CUDA,SIMD.
前提:
1、设备条件:拥有多个计算设备或核心
2、任务条件:任务或数据可划分为多个独立片段
注意:
1、并非所有的任务都适合并行;
2、并行计算代码中包含了额外的管理开销(任务分配与调度、数据同步等),总计算量多于串行代码;
3、并行可以减少计算耗时,但并行代码的耗时也可能多于串行代码(任务并行度太低或代码糟糕);
4、结合实际选择合适的并行方式。
数值计算领域,主要的并行计算方式有三种:
- 1、单机多核并行:OpenMP
- 2、多节点并行:MPI
- 3、GPU设备加速:CUDA/OpenACC
并行方案很多,此处所列条目并不完整,三种方案可混合使用。MPI也可用于单机,OMP也支持设备加速。
为了方便并行、减少错误,建议Fortran用户尽量使用纯函数或逐元函数。
1、OpenMP(Open Multi-Processing)
现今的处理器一般均包含多个计算核心(例如4核),单台机器(节点)更是可能安装有多个处理器(例如2颗)。串行程序仅能够使用一个处理核心进行计算,最多可使用12.5%的CPU资源。0penMP通过启用多个线程,利用该计算机上的多个核心进行并行,已达到加速计算的目的。
编译器自带OMP库,无需额外安装。
注意:
1、核心数量指CPU的物理核心数(4核8线程的CPU具有4个物理核
心),超线性技术对计算密集型代码没有帮助;
2、OMP线程数一般不大于CPU核数,否则计算速度可能降低;
3、区分CPU线程(客观存在—完全不用关心)与OMP线程(程序设定)。
OpenMP是一种用于共享内存系统(单机)的多线程并行方案,支持C/C++和Fortran语言。它通过在串行程序的适当位置添加指令(或指令对),采用Fork-Join模式,启用多个线程并行执行特定部分的代码。

优点
1、简单易学,代码改动小(针对规范的代码);
2、可自由切换并行/串行模式;
3、1可在线程间共享内存(变量)节省内存开销,便于线程间数据传递,减少数据同步耗时。
缺点
1、代码不规范容易造成数据竞争,可能需要大幅度修改原有代码;
2、不适合具有复杂的线程间同步和互斥操作的情形(影响效率);
3、不能用在非共享内存系统(如计算机集群),但支持使用主机以外的计算设备;
OMP/MPI适用于粗粒度任务并行(任务并行),CUDA适用于细粒度任务(数据并行)
参考文献
- 《多核并行高性能计算OpenMP》雷洪,胡许冰
- 《多核异构并行计算OpenMP4.5 C/C++篇》雷洪
- 《Parallel Programming in Fortran 95 using OpenMP》----很经典
Migue丨Hermanns著,李兴旺译(资料较老,内容不多,入门读物)
中文译本下载地址:
https: //download.csdn.net/download/lixingwang0913/86545163
http: //fcode.cn/resource_ebook-24-1.html - 官网文档: www. openmp.org/specifications
启用OMP并行
命令行编译。根据编译器不同,添加相应的编译参数:
- gcc/gfortran-fopenmp(Windows/Linux)
- ifort /Qopenmp(Windows系统)
- ifort -fopenmp(Linux系统)

2、 MPl (Message Passing Interface)
OpenMP只能在单机上使用,假设你有3台这样的机器(或集群),此时可用MPI实现跨节点并行。MPI在每个节点(机器)启用一个或多个进程来并行执行任务。同样,各节点上进程数一般不
大于该节点的CPU核数。一个进程可以含有多个线程,有时也将MPI和OMP结合使用。
常用MPI库:MS MPI,intel MPI,Open MPI,MPICH等。
MPI函数详情: https://www.open-mpi.org/doc/
3、CUDA (Compute Unified Device Architecture) /OpenACC
CUDA是NVIDIA开发的一个并行计算平台和编程模型,而OpenACC则由多个组织(包括NVIDIA)共同维护,二者均是旨在利用GPU实现并行计算。
CUDA适用于NVIDIA卡,目前仅有NVIDIA HPC SDK(包含C和Fortran编译器)支持cuda fortran;
OpenACC同时适用于NVIDIA卡和AMD卡,NVIDIA HPC SDK和GCC(开源免费)均支持。
C/Fortran中OMP标记的说明
为了在并行和串行代码间相互切换(修改编译命令,不修改代码),OMP引入特殊的标记:

注:标记和语句(或指令)之间必须有空格;Fortran也可使用预处理(大小写敏感)。
C语言
- OMP库中包含众多函数,无论是否开启OMP,仅需在代码中#incIude “omp. h",即可使用OMP库函数;
- 2、当关闭OMP选项,#pragma omp所在行被忽略,没有任何作用,生成的程序为串行。
Fortran语言
- 1、如要使用OMP库函数,须开启OMP并在代码中use omp_lib;
- 2、当关闭OMP选项,!$和!$omp将被识别为注释,没有任何作用,也不能使用OMP库函数;
3、选择生成串行代码时,!$和!$omp将被识别为注释,但可以使用OMP库中的部分函数
(需在代码中use omp_lib)

OpenMP构造并行域
OMP以Fork-Join模式并行执行特定部分的代码,这些特定代码所组成的动态范围(dynamic extent)称并行域。
以下指令对用于构造一个并行域,包含于其中的代码或任务可被并行执行:

注:
- 1、C大小写敏感,Fortran不区分大小写(预处理区分);
- 2、并行域中的代码不一定并行执行。
OMP代码执行模式
1、启动程序,主线程(线程0)执行代码块1;
2、遇到!$omp parallel后,主线程分裂(fork)为多个线程(此处
线程数为2),每个线程均尝试执行代码块2;
3、各线程遇到!$omp end parallel后,合并(join)为一个线程(主线程),并由主线程执行代码块3;
4、主线程结束程序。

文本范围(lexical extent)和动态范围(dynamic extent)
文本范围(lexical extent)
- parallel指令对之间的语句。
动态范围(dynamic extent)
- 并行域中所有被执行的语句。

一个完整的OMP程序,其中可以包含若干个串行区域和若干个并行区域,各个并行域内的线程数可以不同。线程数可由环境变量(或内部控制变量ICV,可认为是默认值)、OMP函数(子程序),并行域的子句等确定。

设置线程数
-
1、环境变量OMP_NUM_THREADS
缺省(默认)线程数一般等于CPU核数 -
2、子程序omp_set_num_threads
影响后续所有并行域的线程数
3、子句num_threads
- 设置当前并行域的线程数
优先级:子句>子程序>环境变量

常用函数
omp_set_max_active_levels:最大嵌套并行层数;
omp_get_num_procs:获取CPU核心数;
omp_set_num_threads:设置后续所有并行域的线程数;
omp_get_num_threads: 获取函数调用处线程数;
omp_get_thread_num:获取当前线程的线程号。
注:需要 #include"omp.h"或use omp_lib。一般 set 为子程序(无返回值),get 为函数。

OMP线程数说明
OMP的线程数可为任意正整数(实际受限,可由omp_get_thread_limit函数查询),但线程数不宜超过CPU物理核心数(CPU的超线程对计算密集型任务无益),
主要原因:
- 开辟、释放线程比较耗时;
- 单个核心处理多个线程时会降低效率(线程切换);
- 线程数过多造成内存和堆栈负担。

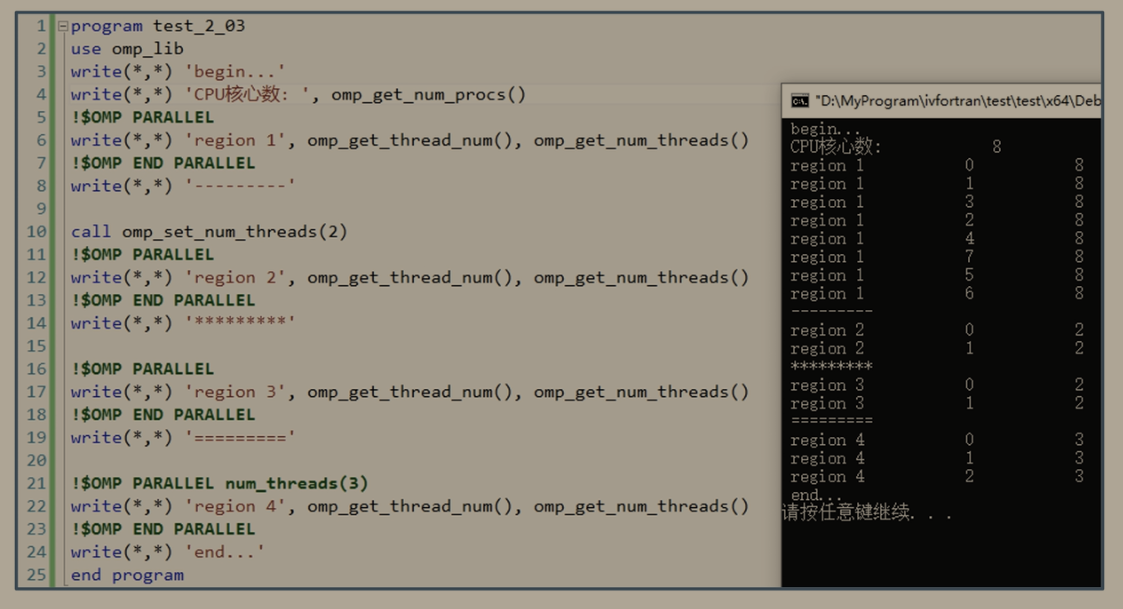
嵌套并行域
在并行域中再次开辟新的并行域,称嵌套并行域。子程序omp_set_max_active_Ievels用于设置执行时的最大嵌套并行层数n(默认n=1)。当设置n=0时,并行域失效,代码串行执行;n>1
时,可进行嵌套并行。
如果代码中并行域的嵌套层数为m,则实际嵌套并行层数为min (m, n)
注:老版本用omp_set_nested函数开启/关闭嵌套并行;
vs2019/GCC 9.4.0 不支持 omp set max active levels.
不同嵌套层数的执行结果
- n=1只有最外层的并行域起作用
- n=2或者3的结果都是一样的,因为嵌套并行域都是2个,所以’regin 3’和‘regin 2’都执行了3*2=6次

子句
OMP指令之后常常可以添加一个或多个子句(clause),用以进行补充说明。子句用于控制具体行为、数据属性、或二者兼之。
并行域处的子句有:
- 并行域开头(#pragma omp parallel/!$omp parallel)可用
子句有:if, num_threads, default,private, firstprivate, shared, reduction, copyin, proc_bind,
allocate.
并行域结尾处(!$omp endparallel)无可用子句,隐含线程同步。
OMP的数据属性
OMP的数据属性可归结为三类:shared、private、threadprivate。
进入并行域时,如果变量具有私有属性(private, firstprivate, lastprivate, reduction, linear),
则会额外开辟nT份(线程数)临时空间来存储数据,并在退出该结构时销毁临时数据。

if(b)
根据参数b的值判断并行域是否有效,进而决定构建并行或串行代码。

numthreads (nT)
参数nT为整型变量或表达式(正整数),设置并行域内的线程数。
default(private | firstprivate 丨 shared l(none)
设置并行域内的变量的默认属性,即如果没有显式给定变量的属性,则其属性为默认属性。
参数为上述四种(私有、承前私有、共享、无)中的其中一种(C语言只可选shared | none)。
注意:C语言中,并行域内变量也可有private丨firstprivate属性,只是default子句中仅有两种可选。C可在并行域定义局部变量(私有)。
private(a,b, c… )
变量a,b,c等为私有变量,每个线程都生成变量的私有备份,同一变量在各个线程中可以有不同值。
初始值未知。
firstprivate (a,b,c…)
变量a,b,c等为私有变量,每个线程都生成变量的私有备份,同一变量在各个线程中可以有不同值。
初始值为主线程的值。
6、 shared(a,b, c… )
变量a,b,c等为共享变量,所有线程共享同一片内存(一荣俱荣)。
初始值为主线程的值。
不同数据属性的效果

reduction(operator:list)
规约:退出并行域时,按照约定的操作将同名变量的多个值处理为一个值。
列表中的变量自动含有private属性。
可用的操作符或函数:
C语言
- 操作符:+, -, *,&, l,^,&&, ll
Fortran
- 操作符:++, *, -, .AND., .OR., .EQV., .NEQV.
- 内置函数:N MAX, Min,IAND,,IOR,IEOR

操作符对应的初始值
| 操作符 | + | - | * | & | | | ^ | && | || |
|--------|----|----|----|----|-----|----|-----|-----|
| 初始值 | 0 | 0 | 1 | 所有位均为1 | 所有位均为0 | 所有位均为0 | 1 | 所有位均为0 |
| 函数 | | | | .and. | .or. | .eqv. | .true. | .false. |
| 操作符 | + | - | * | .and. | .or. | .eqv. | .neqv. |
|---|---|---|---|---|---|---|---|
| 初始值 | 0 | 0 | 1 | .true. | .false. | .true. | .false. |
| 函数 | max | min | iand | ior | ieor | ||
| 初始值 | 该数据类型能够表示的最小值 | 该数据类型能够表示的最大值 | 所有位均为1 | 所有位均为0 | 所有位均为0 |
copyin
仅用于线程私有(threadprivate)变量,进入并行域时将主线程的值赋值给其他线程。
proc_bind
设置线程与CPU核心之间的绑定关系,极少用。
allocate
指针或动态数组可在并行域分配,将增加代码的复杂度,不
建议使用,可用子过程规避。
指令
指令


前期的所有例子,并行域(parallel结构)中的语句会被该并行域中所有线程执行,即相同的代码被多次执行(各线程的执行结果可以不同),未达到并行计算的目的。
为使不同线程执行不同的任务(或同一任务的不同部分),需要在并行域中使用其他OMP指令(结构)将任务分派给各个线程。根据实际情况,任务分派可采用sections、workshare、do、task、taskloop等指令,其中sections结构是最简单、最直接的一种分配方式。
sections
sections结构将代码分割成多个独立代码块(section),每块代码仅被一个线程执行一次。

特点
- 1、该结构适用于处理多个完全不同的任务(一边….一边…);
- 2、section的数量是恒定的(写代码时就确定了),程序运行过程中不会增减(局限性);
- 3、每个代码块(section)组成一个单独的任务,仅被一个线程执行;
- 4、一个线程可能执行0,1,n个代码块(由线程和代码块数量决定);
- 5、紧挨着sections的section可以省略;
- 6、结构末尾处隐含有线程同步(可用nowait取消同步);
子句
private, firstprivate, lastprivate, reduction, allocate,nowait
- lastprivate(a,b,c...):变量a,b,c等为私有变量,初始值未知,退出结构时,源变量的值为最后一次更新的结果(可以修改源变量的值)。
- nowait:置于结构开头©或结尾(Fortran)处,用于取消隐式线程同步,即线程到达该结构的结尾处后无需等待“集合”,继续执行后续任务。


workshare
该结构仅适用于fortran语言,将数组相关的整体操作划分为多个工作单元,分派给各个线程并行执行。
!$omp workshare
·..代码块
!$omp end workshare [nowait]
其内操作包括:数值整体赋值、forall和where语句,内置函数MATMUL,DOT_PRODUCT, SUM, PRODUCT, MAXVAL, MINVAL,COUNT, ANY, ALL,SPREAD, PACK, NPACK, RESHAPE,TRANSPOSE,EOSHIFT, CSHIFT,minloc,MAXLOC。
Fortran语言自身具备数组向量化操作能力,编译器会对此类代码进行优化,对于元素较少的数组,或者单元素计算并不十分复杂的情况,没必要使用workshare结构。

| 语句 | 操作描述 | 多线程执行方式 |
|---|---|---|
b = [1, 0, -2, 5, 3] | 初始化小数组 | 可能按元素分配给线程执行 |
forall(i=1:size(a)) | 并行填充 a(i) = i | 每线程处理若干个 i |
sum(a) + maxval(b) | 并行归约(求和+最大值) | 多线程局部计算 + 汇总 |
Thread 0: b(1), a(1), a(6), sum=7
Thread 1: b(2), a(2), a(7), sum=9
Thread 2: b(3), a(3), a(8), sum=11
Thread 3: b(4), a(4), a(9), sum=13
Thread 4: b(5), a(5), a(10), sum=15maxval(b) = 5total s = 55 + 5 = 60
在 !$omp workshare 块中,OpenMP 会自动分析数组操作,并将这些工作平均分配给所有线程。以下是每条语句的线程划分策略。
b = [1, 0, -2, 5, 3]实际行为:
OpenMP 实现可能按元素划分给线程,比如:线程编号 操作
Thread 0 b(1) = 1
Thread 1 b(2) = 0
Thread 2 b(3) = -2
Thread 3 b(4) = 5
Thread 4 b(5) = 3
但是由于开销太小,有些实现会由主线程直接执行全部赋值。
forall(i=1:size(a)) a(i) = i每个线程处理2个元素的赋值
| 线程编号 | 处理 `i` 范围 |
| -------- | --------- |
| Thread 0 | i = 1, 6 |
| Thread 1 | i = 2, 7 |
| Thread 2 | i = 3, 8 |
| Thread 3 | i = 4, 9 |
| Thread 4 | i = 5, 10 |
s = sum(a) + maxval(b)
sum(a) 和 maxval(b) 都是数组归约操作(reduction)
OpenMP 会用多线程并行归约:sum(a):
线程先对它们负责的 a(i) 部分求和,再归并出总和。
| 线程编号 | 求部分和 |
| -------- | -------------------------- |
| Thread 0 | a(1) + a(6) = 1 + 6 = 7 |
| Thread 1 | a(2) + a(7) = 2 + 7 = 9 |
| Thread 2 | a(3) + a(8) = 3 + 8 = 11 |
| Thread 3 | a(4) + a(9) = 4 + 9 = 13 |
| Thread 4 | a(5) + a(10) = 5 + 10 = 15 |最终汇总:7+9+11+13+15 = 55
maxval(b):
线程分别查看自己负责的 b(i) 值,最后归约出最大值 5
总结:5 个线程如何操作
| 语句 | 操作描述 | 多线程执行方式 |
|---|---|---|
b = [1, 0, -2, 5, 3] | 初始化小数组 | 可能按元素分配给线程执行 |
forall(i=1:size(a)) | 并行填充 a(i) = i | 每线程处理若干个 i |
sum(a) + maxval(b) | 并行归约(求和+最大值) | 多线程局部计算 + 汇总 |
single/master
如果并行域中某部分代码仅需执行一次,例如输出进度提示信息、读取模型参数等,有以下几种方案:
- 构建“并行–串行–并行”模式的代码。并行域的构建和销毁较为耗时,此方案的效率较低;
- 并行域中构建只有一个代码块的sections结构。不能广播数据(难以将变量在某一线程中的值传递给其他线程);
- 并行域中使用判断语句,仅让一个线程(一般是主线程)参与运算。不能广播数据;
- 使用single或master结构。一般,single多用于读取并广播数据,master多用于输出提示。
single结构仅被并行域中的一个线程(任意)执行,末尾处含有隐式线程同步。

clause: private, firstprivate, allocate
end_clause:copyprivate或者nowait
copyprivate子句写在结构开头(C)或结尾(Fortran)处,作用是将一个私有变量的值传递给其他进程(广播)。

master结构仅被并行域中的主线程执行,末尾处没有线程同步,无任何子句。主线程执行代码块的同时,其余线程执行后续任务。一般用于输出提示。

atomic/critical
如果并行域中某部分代码需要被所有线程执行,但不能被多个线程同时执行,例如更新共享变量、读取数据等,可使用
atomic 或critical结构。atomic确保同时只有一个线程修改变量(一般为共享变量),应用于简单的赋值语句:

atomic-clause: read、 write、 update、 capture
read:仅读取变量x的值v=x;
write:覆盖原有值,x=v;
update:对原有值进行更新, x+=1
capture:更新原有值,并传递给其他变量,v=x++
注意:
v为私有变量,x为共享变量
atomic-clause可以不写,默认update
老版本支持单!$omp atomic指令(Fortran),新版不支持

atomic主要用于控制共享变量的更新,应用场景较为简单。
对于更加复杂的代码或场景,可使用critical结构。临界区里面可以是任意合法代码。

临界区特点
- 1、所有同名的多个临界区被看做同一个临界区;
- 2、所有未命名的临界区看作同一个临界区;
- 3、同一时刻,临界区A、B、C...(A、B、C...是多个不同名字的临界区,其中一个可以是无名临界区)里面分别最多只有一个线程;
- 4、当某个线程到达临界区A入口时,它会在此等待,检索所有同名临界区里是否有其他线程执行;等待前一个线程执行完毕后再进入临界区。末尾处没有线程同步。


flush
flush用于强制刷新变量,使缓存与内存一致,

例如:线程A对一个共享数组进行操作时,可能需要使用到受线程B所影响那一部分的信息。线程B对相关信息进行操作时使用了缓存,即操作结果在缓存中,并未更新内存中的信息。这种情况下,必须保证要在A读取数组之前执行完内存更新,可采用flush指令。如果指令后不跟变量列表,则刷新所有变量。
barrier
barrier指令在指定位置插入一个阻塞(同步点),所有线程到达此处后,再继续执行后续语句。

下列结构的结尾处隐含有同步:parallel、 sections、 single、workshare
同步点处隐含有flush。
限制条件:
1、不能用于 sections、single、master、atomic、critical等结构中;
2、其他可引起死锁的情形,如
if(omp_get_thread_num==0)!$OMP BARRIER
end if
for/do
前面介绍的sections结构仅能处理固定的任务片段数(写代码时就给定),workshare主要应对数组整体操作(Fortran)。如果可并行执行的任务数必须在运行时才能确定,且多个任务可通过循环处理,则可采用for/do结构来并行。
指令和循环之间不能有其他语句,尾部隐含同步,可用 nowait 取消。

该指令的作用是将最近的for/do循环(计数循环)中的有限次迭代按照一定方式分派给并行域中的所有线程,各个线程同时执行分配到的迭代任务。适用于每次迭代计算量差异不大的情形。
可用子句:
private, firstprivate, lastprivate, reduction, schedule,collapse, linear, ordered, allocate, order(concurrent)
注意:任务之间无依赖;只能用于计数循环;执行过程中不能跳出循环。
schedule子句
schedule(kind [, chunk])子句
该子句用于设置循环迭代的分配方式(kind),可选值有:static,dynamic,guided,auto,runtime。chunk为整数,对于不同kind的意义不同。
1、
C: #pragma omp for schedule(static, chunk )
Fortran: !$omp do schedule(static, chunk )
首先将循环迭代划分为多个块,按照线程号顺序,依次将各个块分派给每个线程。分派完成后,再开始执行。
适用于每次迭代的任务量相当的情况。
如未指定可选参数chunk,默认把循环迭代平均分配(不能整除怎么办?),块数等于线程数;如指定了可选参数chunk,则每个块均包含chunk次迭代(其中一个可以小于chunk)。静态方案可能存在分配不均的问题,例如将600次迭代分给3线程:

2、 schedule(dynamic, chunk
动态分配每个工作块:按照chunk值(缺省值为1)将循环划分为若干个块,并为每个线程分配一个块。当线程完成一个工作块后,为其分配新的工作块,直至所有块分派完毕。此方案适合各块计算耗时差异较大的情形。
动态方法提高了执行能力和效率,但在处理和分配工作块的时候产生了更多的计算冗余。每个工作块越大,冗余越少,但也会扩大各线程的工作量的差异。
3、 schedule(guided, chunk )
动态分配每个工作块:随着计算进行,逐步减少每个块的工作量(通常是将剩余工作量的一半进行分配),但每个块最少包含chunk次迭代(最后一个块除外)。如果未指定chunk,默认为1。

4、 schedule(auto)
程序自行决定分派方式。
5、 schedule(runtime)
前面的几种方案在编译源代码时就固定了,如果需要在运行时修改分配方式,则可指定为RUNTIME方式,并由环境变量OMP_SCHEDULE决定。
大多数情况(尤其是每次迭代任务相当时)无需使用schedule子句,默认就行。
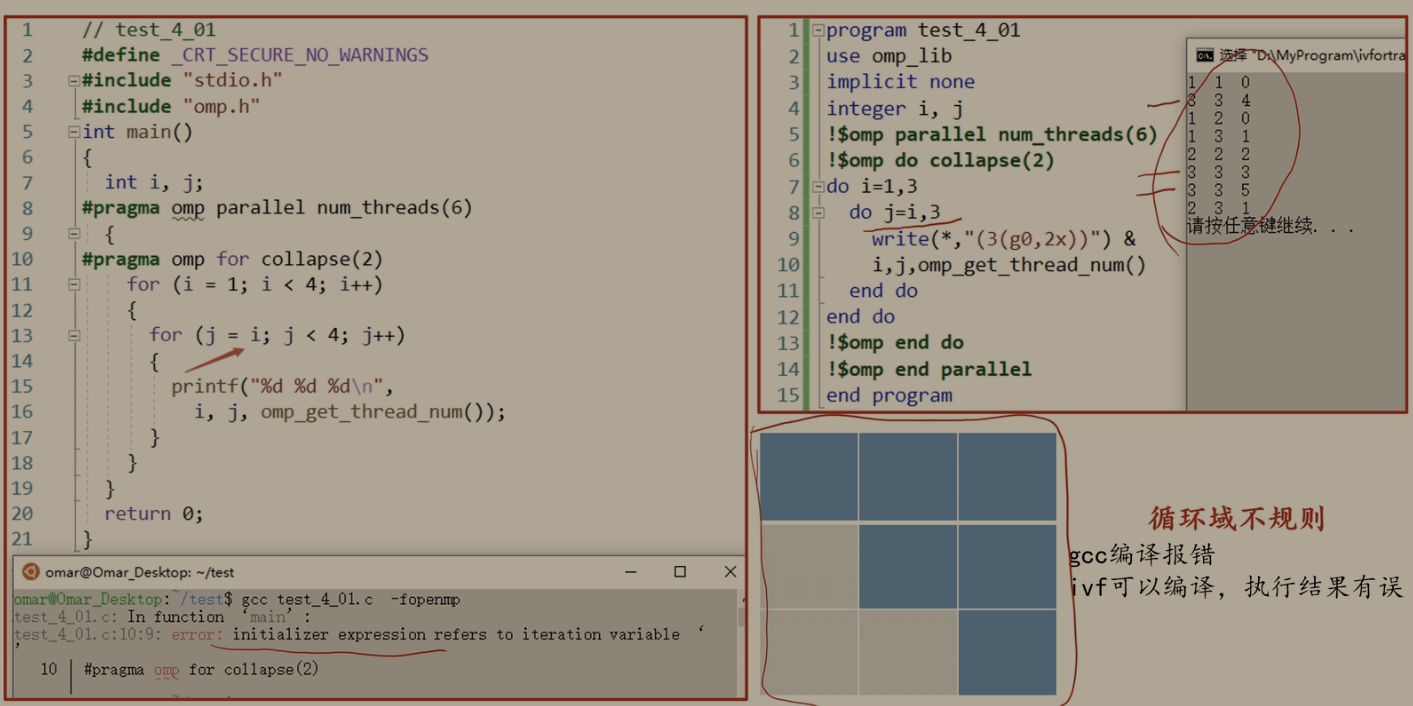
collapse子句
默认情况下,omp for/do仅将最近的循环并行化,collapse可将n层循环合并为一个大循环进行并行。遵守以下限制条件:
- 1、n层循环之间不能有其他语句;
- 2、循环域规则。


linear子句
表明变量为firstprivate属性,且其值与关联的循环的迭代次序线性相关。
参考
- C/Fortran多核并行计算