DeepSeek 大型 MoE 模型大规模部署压测学习
https://lmsys.org/blog/2025-05-05-large-scale-ep/
以上是对文章《Deploying DeepSeek with PD Disaggregation and Large-Scale Expert Parallelism on 96 H100 GPUs》的中文总结,以及对您提到的几个术语(MLA、MoE、SGLang、VLLM、EP 和 DP)的说明。
📄 文章中文总结
这篇由 SGLang 团队于 2025年5月5日发布的技术博客,展示了如何采用 SGLang 框架,在 12 个节点(共 96 张 NVIDIA H100 GPU,Atlas Cloud)上,使用预填充-解码拆分(Prefill‑Decode Disaggregation)与大规模专家并行(Expert Parallelism,EP),成功复现 DeepSeek 的推理效率 ([lmsys.org][1])。
- 性能表现:每节点处理输入 2000 token 时,达到 52.3k 输入 token/s 和 22.3k 输出 token/s,几乎与官方 DeepSeek 相当,且每输出百万 token 的成本仅约 $0.20,仅为官方 Chat API 费用的五分之一 ([lmsys.org][1])。
- 优化手段:文章深入讲解了并行策略(MLA attention、MoE expert、dense FFN、LM head),并重点介绍了 PD 拆分、DeepEP、DeepGEMM、Two‑Batch Overlap(TBO)、以及专家负载均衡(EPLB)。这些方法有效提升了 GPU 利用率及吞吐量 ([lmsys.org][1])。
- 开源贡献:所有代码与实验方案均已开源,可复现,自由扩展使用 。
🧠 专业术语解析
MLA(Multi-Head Latent Attention 多头潜在注意力)
一种 attention 机制,用于捕捉复杂输入依赖关系。文章指出在此机制上,采用 DP Attention 进行数据并行以减少 KV 缓存冗余,提高内存效率 ([lmsys.org][1])。
MoE(Mixture of Experts 专家混合模型)
模型中含有多个专家子网络,输入由路由模块分配给部分专家处理,形成“稀疏 FFN”(Sparse FFN)。优势在于计算高效但内存消耗大。文章提出用 Expert Parallelism(EP)将专家参数分散存储在多 GPU 上,并结合 DeepEP 和 EPLB 技术来优化通信与负载均衡 ([lmsys.org][1])。
SGLang
一个高效的 LLM/VLM 推理框架,强调后端与前端协同设计。此次文章展示 SGLang:
- 支持 PD Disaggregation;
- 内建 EP、DeepEP、DeepGEMM、TBO、EPLB 等模块;
- 提供 DisposableTensor、专家负载分析工具等辅助功能 ([lmsys.org][1])。
SGLang 已成为业内标准部署方案 。
VLLM
虽文章未直接涉及 VLLM,但它是在同类型 LLM 推理框架中常被提及的对标系统。SGLang 团队曾于 2024 年对比并优化深度 remark,显示其性能优于 VLLM 。
EP(Expert Parallelism 专家并行)
一种并行策略,用于将 MoE 中的多个专家分布到不同 GPU 上管理内存压力。配合 DeepEP 通信库,支持两种调度模式:prefill 的高吞吐模式(normal dispatch)和 decode 的低延迟模式(low‑latency dispatch)。PD 拆分机制让这两种模式可并存 ([lmsys.org][1])。
DP(Data Parallelism 数据并行)
不同于 tensor parallelism,DP 复制整模型到多个设备,再并行处理 batch。文章使用它对 attention、FFN、LM Head 进行优化:
- 在 attention 中避免 KV 缓存复制;
- 在 dense FFN 中减少通讯与对齐碎片,加速训练与推理 ([lmsys.org][1])。
✅ 总结
| 技术 | 功能 |
|---|---|
| MLA | 模型核心注意力机制,配合 DP 优化 KV 内存 |
| MoE | 稀疏专家网络,允许高效扩展但需加载专家参数 |
| EP | 专家参数跨设备分布并管理通信模式 |
| DP | 跨设备复制模型,实现高效 batch 推理 |
| PD 拆分 | 分离 prefill 与 decode 阶段,优化资源利用 |
| DeepEP / DeepGEMM / TBO / EPLB | 分别负责通信、矩阵计算、批次重叠与专家负载均衡 |
文章展示了通过这些协同优化,SGLang 在庞大 MoE 模型上达成高效、大规模部署,且成果开源,推动社区共建发展。
bu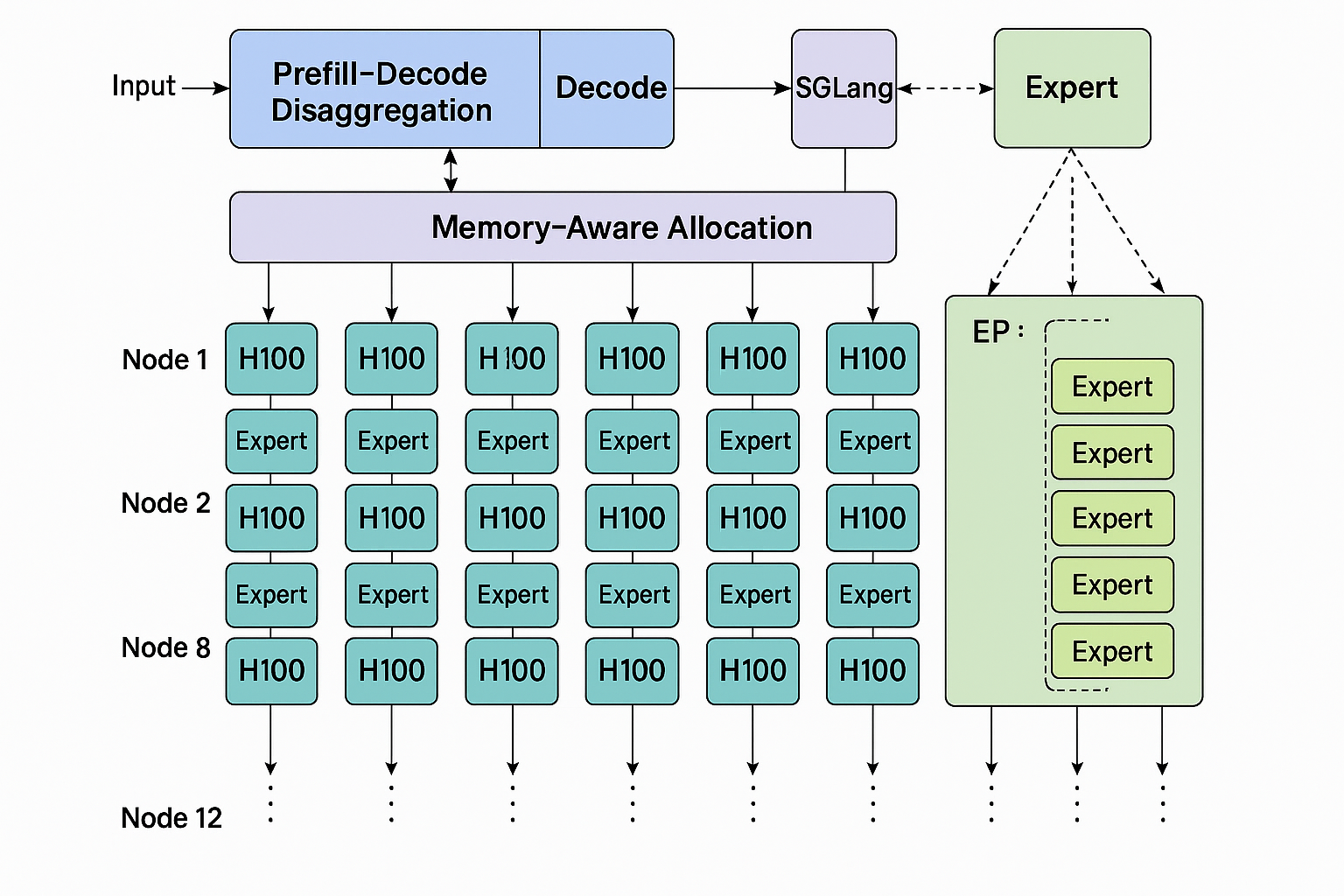
基于 LMSYS 在文章《Deploying DeepSeek with PD Disaggregation and Large-Scale Expert Parallelism on 96 H100 GPUs》中展示的内容和实践经验,我们可以设计一套用于评估 大规模 MoE 模型部署性能 的完整测评工具与方案,覆盖:
🔧 一、测评工具(建议组合使用)
| 工具/库名称 | 功能 | 说明 |
|---|---|---|
| SGLang | 推理框架 | 本文核心框架,支持 EP/DP/PD 拆分等 |
| DeepEP | 高性能专家通信 | 用于优化专家参数的分布式通信 |
| DeepGEMM | 高效矩阵乘法库 | 替代 PyTorch 默认 GEMM,加速 FFN/MoE |
| vllm-benchmark | 推理性能基准工具 | 可用于横向对比 vLLM/SGLang 等 |
| nvprof / Nsight / Nsight Systems | NVIDIA GPU 分析工具 | 分析 GPU 利用率、内存瓶颈等 |
| Prometheus + Grafana | 系统监控 | 收集节点资源(CPU/GPU/内存/网络)利用率 |
| torch.distributed + NCCL Debug | 通信调试工具 | 调试 DP/EP 分布式通信问题 |
| 日志分析工具(如 ELK) | 专家分布/调度可视化 | 对 EPLB / 路由行为做统计分析 |
📋 二、性能测试指标设计
1. Token Throughput(吞吐量)
- Input Token/s:每秒处理的 prompt token 数;
- Output Token/s:每秒生成的 token 数;
- Peak vs Steady-state:观察 warm-up 后是否稳定;
- 用于判断 PD 拆分 + DeepEP 优化效果。
2. Token Latency(时延)
- Prefill 时延:测每个 token 编码耗时;
- Decode 时延:生成阶段每 token 平均耗时;
- 支持 1-B/4-B/8-B 并发下对比。
3. 资源利用率
- GPU 利用率(SM/Memory/PCIe/NVLink);
- Network 带宽(EP 通信);
- 内存占用(KV 缓存/专家缓存是否爆炸);
- 是否存在 Load Imbalance(EPLB 调度是否平衡)。
4. 专家调度效率
- 路由策略命中率(top-k);
- 有效专家调用比例;
- 负载均衡偏差(EPLB前后对比);
- expert collapse(专家频繁未命中)现象。
5. 系统稳定性
- 并发处理能力(不同并发下是否死锁);
- 长时间推理稳定性(内存泄漏/通信超时);
- 多轮推理中错误率(异常 token、重复输出);
- 异常节点容错测试(例如某 GPU 故障恢复);
✅ 三、测试方案设计(按步骤)
✅ 基础功能验证阶段(1-8 卡小规模)
-
部署 SGLang + DeepEP,加载 MoE 模型(如 DeepSeek-MoE);
-
验证 PD 拆分是否成功;
-
检查每个阶段(prefill/decode)是否绑定正确 GPU 核心;
-
分别测试:
- Dense 模式;
- MoE 模式;
- EP+DP 模式对比。
✅ 性能扩展阶段(96 卡大规模)
-
固定 batch size,逐步增加 expert 数;
-
验证是否触发 DeepEP 的 dispatch 模式切换;
-
多组并发设置:
- 单路(低延迟);
- 多路并发(高吞吐);
- 混合(PD 拆分)。
-
使用工具收集:
- Token 吞吐;
- 时延;
- GPU utilization;
- expert 活跃度与分布。
✅ 优化测试阶段
-
启用/关闭:
- EPLB;
- DeepGEMM;
- Two‑Batch Overlap(TBO);
- Memory-Aware Allocation(MAA);
-
比较:
- vLLM baseline vs SGLang;
- dense vs sparse(同模型)。
📌 附加建议
-
日志指标建议添加:
- 每轮推理专家调度表;
- 通信延迟(EP);
- token queue size(PD Decode);
- TBO 命中率(prefill-decode 重叠成功率);
-
推荐数据集:使用 AlpacaEval / MMLU / GSM8K 的部分样本模拟实际对话负载。
-
自动化评估脚本:编写
eval_runner.py实现多种并发配置自动跑测,并输出 markdown 表格或 CSV。