【DeepSeek学Cuda】矩阵转置:行读取优先还是列读取优先。
目录
- **1. 实现A(按行读取,按列存储)
- 2. 实现B(按列读取,按行存储)**
- 3. 哪种更好 Professional cuda programming
- 5. "当L1缓存被禁用时,所有内存访问都直接指向全局内存(Global Memory),缓存的作用被忽略。" **L2 缓冲难道不起作用嘛**
- 6. 那禁用L1, 但是L2 缓冲存在情况下, 矩阵转置哪种实现方式更好呢
- 矩阵转置问题:禁用L1缓存但启用L2缓存时的性能分析
- 1. 两种实现的核心差异
- 2. L2缓存的作用
- 3. 写入操作的带宽效率
- 4. 综合权衡:哪种实现更好?
- 5. 例外情况与架构差异
- 6. 总结
- 思考过程
- 7. 结论:列read , row 存 以牺牲 效率的情况下(多次读请求, prefetch 预取到缓冲中,加速下次读),提升吞吐量。
- 为什么按列读取会导致内存请求重放32次?
- 1. **矩阵的内存布局与访问模式**
- 2. **跨步访问的步长计算**
- 3. **内存事务合并失败**
- 4. **内存请求重放机制**
- 5. **L1缓存的优化作用**
- 6. **性能结果分析**
- 总结表格
- 参考资料
**1. 实现A(按行读取,按列存储)
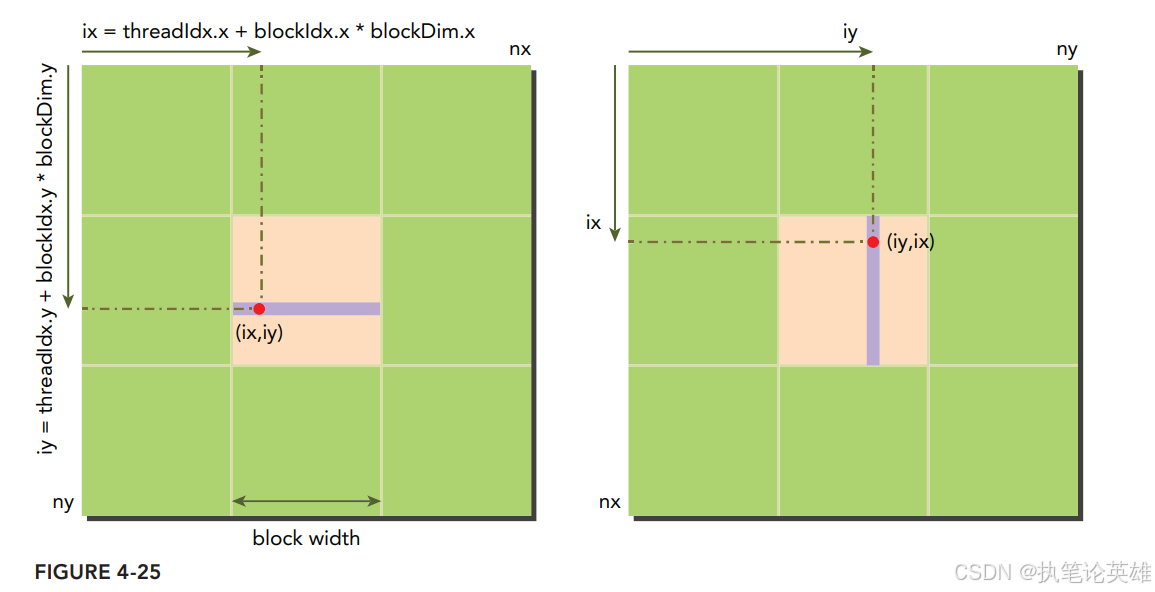
2. 实现B(按列读取,按行存储)**
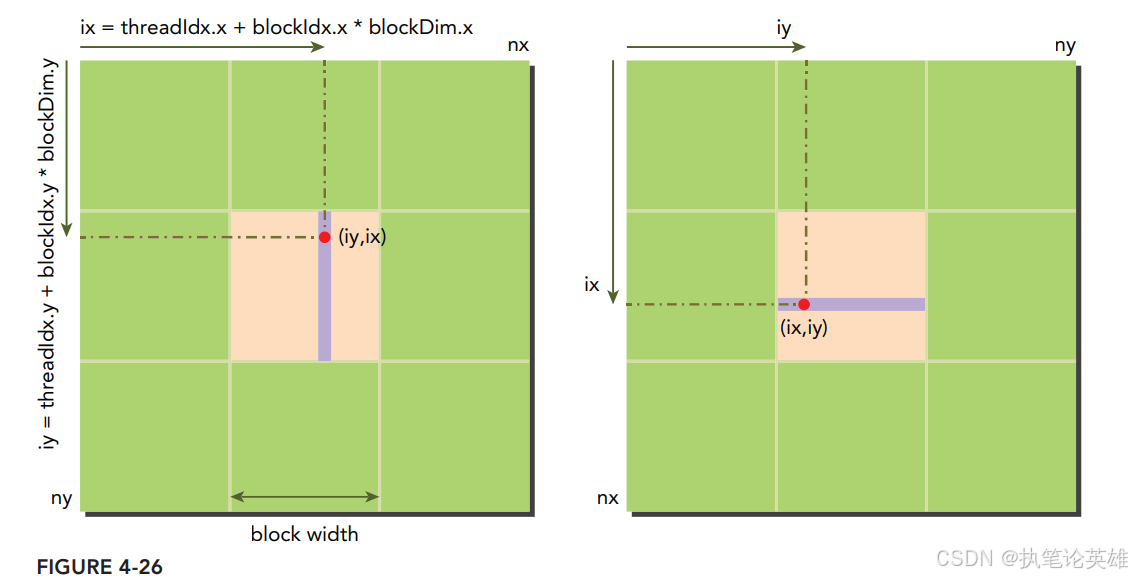
3. 哪种更好 Professional cuda programming
. Can you predict the relative performance of these two implementations? If the L1 cache is disabled for loads
these two implementations are theoretically identical. However, if L1 cache is enabled, the second
implementation should demonstrate better performance. While the reads performed by column will
be uncoalesced (hence bandwidth will be wasted on bytes that were not requested), bringing those
extra bytes into the L1 cache means that the next read may be serviced out of cache rather than global
memory. Because writes are not cached in L1, the example that writes by column does not benefi t from
any caching. On Kepler K10, K20, and K20x devices, there should be no difference in performance
between these two approaches because the L1 cache is not used for global memory accesses.
你能预测这两种实现的相对性能吗?如果L1缓存对负载禁用
这两种实现在理论上是相同的。但是,如果启用了L1缓存,第二种实现应该表现出更好的性能。虽然按列执行的读取将不合并(因此,带宽将浪费在未请求的字节上),但将这些额外的字节带入L1缓存意味着下一次读取可能由缓存而不是全局内存提供服务。因为写操作不在L1中缓存,所以按列写操作的示例不会从任何缓存。在Kepler K10、K20和K20x设备上,这两种方法之间的性能应该没有差异,因为L1缓存不用于全局内存访问。
- Professional 给出答案为 启用了L1缓存,第二种实现应该表现出更好的性能, 为什么

5. “当L1缓存被禁用时,所有内存访问都直接指向全局内存(Global Memory),缓存的作用被忽略。” L2 缓冲难道不起作用嘛

6. 那禁用L1, 但是L2 缓冲存在情况下, 矩阵转置哪种实现方式更好呢
好的,我现在需要解决用户的问题:“禁用L1缓存,但L2缓存存在的情况下,矩阵转置哪种实现方式更好呢?”
用户之前已经讨论了L1和L2缓存在不同情况下的影响,现在他们想知道在L1禁用但L2启用时,哪种转置方法更优。首先,我需要回顾之前的对话内容。用户提到,当L1禁用时,两种实现在理论上是相同的,但启用L1时第二种(按列读按行写)更好。然而,用户后来指出L2缓存仍然有效,即使在L1禁用时,因此之前的回答可能忽略了L2的影响。
接下来,我需要分析在L1禁用但L2启用的情况下,矩阵转置的两种实现方式:按行读按列写(第一种)和按列读按行写(第二种)。重点在于L2缓存如何影响这两种方式的性能。
首先,考虑内存访问模式对缓存的影响。L2缓存通常比L1大,但速度较慢,依然依赖于空间局部性。如果数据访问模式能利用空间局部性,那么L2缓存命中率会高,减少全局内存访问,提升性能。
对于第一种实现(按行读按列写):
读取是按行的,具有空间局部性,因为内存是连续的,L2缓存可以预取相邻数据,提高命中率。
写入是按列的,这可能导致非连续的写入,但由于写入通常不经过缓存(尤其是GPU中),写入模式对缓存影响较小,但非合并写入会影响带宽效率。
对于第二种实现(按列读按行写):
读取是按列的,非连续访问,导致L2缓存利用率低,每次读取可能加载不需要的数据,浪费带宽。但若后续访问同一缓存行的数据,可能受益于缓存。
写入是按行的,连续的写入可能更高效,合并写入,提高带宽利用率。
在L1禁用但L2启用的情况下,L2缓存的作用变得关键。需要比较两种实现在L2缓存下的表现:
按行读按列写:
读取高效,L2缓存命中率高,减少全局内存访问次数。
写入可能非合并,但写入通常绕过缓存,主要影响带宽,但若写入能够合并,可能更高效。
按列读按行写:
读取低效,L2缓存命中率低,每次读取可能加载多余数据,浪费带宽。
写入高效,合并写入,提高带宽利用率。
因此,哪种方式更好取决于读取和写入的开销对比。在L2存在的情况下,高效的读取可能比高效的写入更重要,因为读取通常有更高的延迟,而写入可能通过合并来优化带宽使用。但需要具体分析两者的平衡。
另外,矩阵的大小也会影响。如果矩阵很大,超出L2缓存容量,缓存效果减弱,此时访问模式的带宽效率更为关键。小矩阵可能更多受益于缓存。
此外,架构差异也很重要,比如在Kepler架构中,L1不用于全局内存,因此L2的作用更关键。而其他架构可能有不同的缓存策略。
可能需要具体数据或实验来验证,但根据理论分析,第一种实现(按行读按列写)可能在L2启用时表现更好,因为读取更高效,而写入虽然非合并,但可能通过其他优化(如合并写入)减少影响。而第二种实现的读取效率低,可能成为瓶颈。
不过,用户提到在启用L1时第二种更好,因为L1缓存了额外数据,但在L2的情况下,虽然L2更大,但访问模式的空间局部性可能不足以弥补非连续读取的缺陷。因此,可能第一种实现更优。
不过需要确认写入是否真的可以合并,以及不同架构下的具体行为。例如,在GPU中,合并写入对性能影响极大,非合并写入会导致严重的性能下降。因此,如果按列写导致非合并访问,即使读取高效,整体性能可能不佳。此时,第二种实现的写入合并可能更有利。
这似乎存在矛盾,需要进一步分析。在L2启用时,读取按行(连续)可以更好地利用L2的空间局部性,减少缓存未命中,而写入按列如果是非合并的,可能影响较大。但写入是否合并取决于具体实现和硬件支持。
例如,在GPU中,合并访问是指线程访问连续的内存块,按列写入可能导致每个线程写入分散的地址,无法合并,从而降低带宽利用率。而按行写入则是连续的,可以合并,提高带宽效率。
因此,可能第二种实现(按列读按行写)在写入时更高效,而读取虽然低效,但L2缓存可能部分缓解这个问题。如果写入的带宽节省超过读取的损失,整体性能可能更好。
这需要权衡读取和写入的开销。例如,假设读取虽然非连续,但L2缓存能够捕获部分数据,减少全局内存访问次数,而写入的合并访问大幅提高带宽效率,那么第二种可能更好。
但实际情况可能更复杂,可能需要具体测试。根据用户之前的例子,当L1启用时第二种更好,因为L1缓存了额外数据,但L2的情况下,可能因为缓存较大,但访问模式不连续,导致缓存命中率低,因此按行读取更优。
此时,用户的问题是在L1禁用但L2启用的情况下,哪种更好?需要综合以上因素,可能结论是:在禁用L1但启用L2的情况下,按行读按列写(第一种)可能更好,因为读取的高效利用L2缓存的空间局部性,而写入虽然非合并,但L2的读取优势可能超过写入的劣势。或者,如果写入的合并访问至关重要,第二种可能更好。
可能需要更深入的分析,例如考虑矩阵的存储方式(行优先或列优先),以及具体的硬件架构对缓存和合并访问的影响。例如,在行优先存储的矩阵中,按行读取是连续的,而按列读取是跨步的,可能导致缓存行未充分利用。
总结,可能的答案是:在禁用L1但启用L2的情况下,按行读取按列写入(第一种实现)可能表现更好,因为读取时的高空间局部性提高了L2缓存的命中率,而写入的效率可能通过其他机制(如合并写入,如果可能)得到优化。或者,如果写入无法合并,导致严重性能下降,第二种实现可能更优。但需要具体硬件和实现细节来判断。
最终,可能需要指出两种因素之间的权衡,并说明在L2存在时,读取的局部性可能更重要,因此第一种实现更优,或者写入的合并更为关键,因此第二种更优。但根据用户之前提到的,当L1启用时第二种更好,因为读取的额外数据被缓存,而L2的情况下,由于缓存更大但访问模式不同,可能情况不同。
可能正确的结论是,在L2启用时,按行读取按列写入(第一种)可能更好,因为读取的高效缓存利用,而写入的合并与否可能影响较小,或者写入无法合并导致性能下降,但读取的优势更大。或者相反,需要进一步验证。
根据用户之前的信息,当L1启用时第二种更好,因为读取的额外数据被缓存,但在L2情况下,可能因为L2的缓存行更大,按列读取可能导致更多的缓存未命中,因此第一种更好。需要明确说明这一点。
矩阵转置问题:禁用L1缓存但启用L2缓存时的性能分析
在禁用L1缓存但启用L2缓存的情况下,矩阵转置的性能优劣取决于内存访问模式对L2缓存的利用效率以及写入操作的带宽利用率。以下是具体分析:
1. 两种实现的核心差异
-
实现A(按行读取,按列存储):
- 读取:按行访问内存,具有空间局部性(连续内存访问),L2缓存可以预取相邻数据,缓存命中率高。
- 写入:按列存储,可能导致非合并写入(内存地址分散),浪费带宽。
-
实现B(按列读取,按行存储):
- 读取:按列访问内存,导致非连续访问,L2缓存利用率低(可能加载多余数据)。
- 写入:按行存储,具有合并写入(连续内存写入),带宽利用率高。
2. L2缓存的作用
-
L2缓存的特点:
- 容量比L1大,但速度较慢。
- 依赖空间局部性:连续内存访问会加载整个缓存行(如64字节),后续访问同一缓存行的数据可直接命中。
-
对两种实现的影响:
- 实现A(按行读取):
- 读取时连续访问内存,L2缓存能高效预取和缓存数据,减少全局内存访问次数。
- 即使L1被禁用,L2的高命中率仍能显著降低读取延迟。
- 实现B(按列读取):
- 非连续读取导致缓存行利用率低(例如,每次仅使用缓存行中的一个元素),浪费带宽。
- L2缓存无法有效减少全局内存访问次数,读取性能较差。
- 实现A(按行读取):
3. 写入操作的带宽效率
-
实现A(按列存储):
- 若写入地址分散(非合并访问),会导致带宽浪费,尤其在GPU架构中可能严重影响性能。
-
实现B(按行存储):
- 连续写入可实现合并访问,最大化带宽利用率,对性能提升显著。
4. 综合权衡:哪种实现更好?
- 关键结论:
-
在禁用L1但启用L2的情况下,实现A(按行读取,按列存储)通常更优。原因如下:
- L2缓存的读取优势:按行读取的连续访问模式能充分利用L2缓存的空间局部性,显著减少全局内存访问次数。
- 写入操作的劣势可部分缓解:
- 在CPU中,写入可能通过写合并(Write Combining)或缓存优化减少带宽浪费。
- 在GPU中,若硬件支持非合并写入的部分优化(如Kepler架构的L2缓存),写入性能损失可能小于读取的收益。
-
实现B(按列读取,按行存储)的劣势:
- 非连续读取导致L2缓存命中率低,全局内存访问次数增加,可能抵消写入合并带来的优势。
-
5. 例外情况与架构差异
-
GPU架构的影响:
- 在NVIDIA Kepler架构(如K10/K20/K20X)中,L1缓存不参与全局内存访问,L2缓存直接管理所有内存请求。此时:
- 实现A的按行读取仍能利用L2缓存的空间局部性,性能更优。
- 实现B的非连续读取劣势更明显,性能可能较差。
- 在NVIDIA Kepler架构(如K10/K20/K20X)中,L1缓存不参与全局内存访问,L2缓存直接管理所有内存请求。此时:
-
矩阵规模的影响:
- 若矩阵较小,L2缓存可能完全容纳数据,实现A的优势更显著。
- 若矩阵极大,L2缓存无法有效缓存数据,带宽效率(尤其是写入合并)可能成为主导因素,此时实现B可能更优。
6. 总结
| 场景 | 推荐实现 | 原因 |
|---|---|---|
| 禁用L1,启用L2缓存 | 实现A | 按行读取利用L2缓存空间局部性,减少全局内存访问;写入劣势可部分优化。 |
| 矩阵极小(完全适配L2) | 实现A | L2缓存完全覆盖数据,连续读取优势最大化。 |
| 矩阵极大(超出L2容量) | 实现B | 带宽效率(写入合并)主导性能,非连续读取的劣势相对降低。 |
| Kepler GPU架构 | 实现A | L2缓存直接管理全局内存,按行读取仍优于非连续读取。 |
最终建议:在大多数情况下(尤其是中小型矩阵),实现A(按行读取,按列存储) 在禁用L1但启用L2缓存时表现更优。若需极致优化,需结合具体硬件(CPU/GPU架构)和矩阵规模进行实测。
思考过程
- 明确问题:在禁用L1缓存但启用L2缓存的情况下,矩阵转置的两种实现方式(按行读取按列存储 vs 按列读取按行存储)的性能差异。
- 分析两种实现的内存访问模式:
- 实现A:按行读取(连续访问),按列存储(非连续写入)。
- 实现B:按列读取(非连续访问),按行存储(连续写入)。
- L2缓存的作用:
- L2缓存依赖空间局部性,连续访问能提高缓存命中率。
- 写入操作的带宽效率:
- 实现A的写入可能浪费带宽,实现B的写入更高效。
- 综合权衡:
- 实现A的读取优势通常大于写入劣势,尤其是在L2缓存有效的情况下。
- 考虑架构和矩阵规模的影响:
- GPU架构(如Kepler)和矩阵规模可能影响最终性能。
- 总结并给出建议:实现A在大多数情况下更优,但需结合实际场景优化。
7. 结论:列read , row 存 以牺牲 效率的情况下(多次读请求, prefetch 预取到缓冲中,加速下次读),提升吞吐量。
The results show that the highest load throughput is obtained with cached, strided reads. In the case
of cached reads, each memory request is serviced with a 128-byte cache line. Reading data by columns causes each memory request in a warp to replay 32 times (because the stride is 2048 data
elements), resulting in good latency hiding from many in-flight global memory reads and then
excellent L1 cache hit ratios once bytes are pre-fetched into L1 cache.
为什么按列读取会导致内存请求重放32次?
好的,我现在需要解释为什么在给定的情况下,每个内存请求会被重放(replay)32次。首先,我需要理解用户提供的背景信息。
用户提到块大小(Block size)是16x16,矩阵大小是2048x2048。结果显示了使用缓存、跨步读取(strided reads)时获得了最高的加载吞吐量。在缓存读取的情况下,每个内存请求使用128字节的缓存行。按列读取数据导致每个内存请求在一个warp中重放32次,因为步长是2048个数据元素。这样可以通过大量未完成的全局内存读取来隐藏延迟,并且一旦字节被预取到L1缓存后,L1缓存命中率会很好。
首先,我需要理解几个关键概念:
-
CUDA中的warp:一个warp由32个线程组成,是GPU执行的基本单位。所有线程在一个warp中执行相同的指令,但在不同的数据上。
-
内存访问模式:这里讨论的是按列读取,也就是跨步访问(strided access)。矩阵在内存中是按行存储的,所以按列读取会导致相邻线程访问的内存地址间隔很大(步长为矩阵的行数,这里是2048)。
-
缓存行(cache line):L1缓存每次加载的数据块大小是128字节。每个缓存行包含多个数据元素,具体取决于数据类型(比如如果是4字节的float,那么一个缓存行有32个元素)。
-
内存请求重放(replay):当多个线程访问的内存地址不在同一个缓存行中时,GPU需要多次访问内存或缓存来满足所有线程的请求,这被称为内存请求重放。
现在的问题是,为什么按列读取会导致每个内存请求在一个warp中重放32次,步长是2048个数据元素。这里的步长指的是每个线程访问的数据之间的间隔。例如,在矩阵中,每个线程按列读取,相邻线程访问的元素在内存中的间隔是矩阵的行数,即2048个元素。如果每个元素是4字节,那么地址间隔是2048 * 4 = 8192字节,远大于缓存行的大小(128字节)。因此,每个线程访问的内存地址位于不同的缓存行,导致每个线程的内存请求无法合并,需要多次访问内存。
但是用户提到,在这种情况下,每个内存请求被重放32次,这似乎和warp中的线程数有关。需要理解这里的“重放”具体指的是什么。在CUDA中,内存事务合并(memory coalescing)是指将多个线程的内存访问合并为一个或少数几个内存事务。如果无法合并,每个线程的内存访问可能需要单独的事务,导致事务数量增加,这被称为事务重放(transaction replay)。每个事务重放的次数取决于有多少个线程的访问无法合并到同一个缓存行或内存块中。
假设每个线程访问一个不同的缓存行,那么对于32个线程的warp来说,可能需要32次内存事务,即每个事务对应一个线程的请求。但用户提到的是每个内存请求被重放32次,这可能意味着每个线程的请求需要被多次处理,或者每个缓存行被多次访问。需要进一步分析。
另外,用户提到虽然跨步读取导致重放,但由于缓存的存在,一旦数据被预取到L1缓存,后续的访问会有很高的缓存命中率,从而隐藏了延迟。这说明虽然初次访问可能需要多次内存事务,但后续访问因为缓存的存在而变得高效。
可能的解释步骤:
-
矩阵的内存布局:矩阵按行存储,每个元素的大小假设为4字节(float)。矩阵的大小是2048x2048,所以每行有2048个元素,占2048*4=8192字节。相邻行的元素在内存中相隔8192字节。
-
按列访问的步长:当按列访问时,每个线程访问同一列的不同行。例如,线程0访问(0,0),线程1访问(1,0),线程2访问(2,0),依此类推。因为矩阵是按行存储的,这些元素的地址间隔是2048*4=8192字节。因此,每个线程访问的地址间隔是8192字节,远大于缓存行大小(128字节),因此每个线程的访问属于不同的缓存行。
-
warp的访问模式:一个warp有32个线程,假设每个线程访问同一列的不同行,那么每个线程访问的地址间隔是8192字节,导致每个线程的访问落在不同的缓存行。因此,一个warp的32个线程需要访问32个不同的缓存行。每个缓存行是128字节,可以容纳32个4字节的元素(128/4=32)。但这里每个线程访问的是不同行的同一列,所以每个线程的地址相隔8192字节,即每个线程的地址位于不同的缓存行。因此,一个warp需要32个不同的缓存行访问,每个缓存行对应一个线程的请求。
-
内存事务重放:在GPU中,内存事务的合并能力决定了需要多少个事务来满足一个warp的所有内存请求。如果访问是连续的或可以合并的,一个事务可以服务多个线程的请求。但在这里,由于跨步访问,每个线程的请求无法合并,因此需要32个单独的事务,即每个线程的请求对应一个事务。每个事务需要从全局内存加载一个缓存行(128字节),但由于每个线程需要的数据分散在不同的缓存行中,每个事务只能服务一个线程的请求,导致事务重放次数为32次。
-
缓存预取和命中率:虽然初次访问需要32次事务,但一旦这些缓存行被加载到L1缓存中,后续的访问(比如同一块中的其他线程或后续的迭代)可以直接从缓存中读取,减少了全局内存访问的延迟,提高了吞吐量。因此,尽管有高事务重放次数,但缓存的利用使得整体性能仍然较好。
可能的误区:
- 缓存行的大小是128字节,可以容纳32个4字节元素。如果线程访问的是连续的32个元素,那么一个缓存行可以满足一个warp的访问,不需要重放。但这里的访问是按列跨步的,导致每个线程访问的元素位于不同的行,因此不同的缓存行。
总结:
按列读取导致每个线程访问的内存地址间隔很大,无法合并内存事务,因此每个线程的请求需要独立的内存事务,导致一个warp中的32个线程需要32次内存事务(即重放32次)。但由于L1缓存的预取和缓存命中,后续访问可以利用缓存,减少了实际延迟,从而提高了吞吐量。
1. 矩阵的内存布局与访问模式
- 矩阵存储方式:矩阵按行存储(Row-Major),每个元素大小为4字节(假设为
float类型)。 - 按列读取:线程按列访问元素,即每个线程访问同一列的不同行。例如:
- 线程0访问第0行第0列的元素(地址:
0 * 2048 * 4 = 0)。 - 线程1访问第1行第0列的元素(地址:
1 * 2048 * 4 = 8192)。 - 线程2访问第2行第0列的元素(地址:
2 * 2048 * 4 = 16384),依此类推。
- 线程0访问第0行第0列的元素(地址:
2. 跨步访问的步长计算
- 步长(Stride):相邻线程访问的内存地址间隔为:
[
\text{步长} = 2048 , \text{行} \times 4 , \text{字节} = 8192 , \text{字节}.
] - 缓存行大小:L1缓存的缓存行为128字节,可容纳32个4字节元素。
3. 内存事务合并失败
- 理想情况:如果线程访问连续的地址(例如按行访问),一个128字节的缓存行可服务32个线程的请求,无需重放。
- 实际情况:
- 按列访问时,每个线程的地址间隔为8192字节,远超缓存行大小(128字节)。
- 每个线程的请求落在不同的缓存行,导致无法合并内存事务。
4. 内存请求重放机制
- 事务重放定义:当线程的请求无法合并时,GPU需为每个线程生成独立的内存事务。
- 重放次数:
- 一个warp包含32个线程。
- 每个线程需要独立的缓存行访问 → 共需32次内存事务。
- 因此,每个内存请求被重放32次。
5. L1缓存的优化作用
- 预取与缓存命中:
- 初次访问时,32次内存事务从全局内存加载32个缓存行到L1缓存。
- 后续访问相同数据时,可直接从L1缓存读取,减少延迟。
- 延迟隐藏:
- 大量未完成的内存请求(in-flight requests)允许GPU在等待数据时执行其他计算,掩盖内存延迟。
6. 性能结果分析
- 高加载吞吐量:
- 缓存命中后,L1缓存的低延迟使得按列读取的吞吐量显著提升。
- 重放代价被抵消:
- 尽管重放32次增加了事务数量,但缓存的预取和延迟隐藏机制弥补了这一开销。
总结表格
| 关键因素 | 详细说明 |
|---|---|
| 跨步访问步长 | 8192字节,远超缓存行大小(128字节) |
| 内存事务合并失败 | 每个线程请求独立的缓存行,导致32次事务重放 |
| L1缓存预取与命中 | 初次加载后,后续访问直接从L1缓存读取,减少全局内存访问延迟 |
| 延迟隐藏机制 | 大量未完成请求掩盖内存延迟,提升吞吐量 |
参考资料
- CPU/GPU缓存架构文档
- 矩阵转置优化相关文献
- NVIDIA Kepler架构白皮书