【WB 深度学习实验管理】利用 Hugging Face 实现高效的自然语言处理实验跟踪与可视化
本文使用到的 Jupyter Notebook 可在GitHub仓库002文件夹找到,别忘了给仓库点个小心心~~~
https://github.com/LFF8888/FF-Studio-Resources

在自然语言处理领域,使用Hugging Face的Transformers库进行模型训练已经成为主流。然而,随着模型复杂度的增加和实验次数的增多,如何高效地跟踪和管理每一次实验的结果变得尤为重要。传统的日志记录方法往往繁琐且不够直观,难以满足快速迭代的需求。幸运的是,Weights & Biases(W&B)提供了一种轻量级的解决方案,能够无缝集成到Hugging Face的工作流程中,帮助开发者自动跟踪实验数据、可视化模型性能,并轻松比较不同架构和超参数设置的效果。本文将详细介绍如何利用这一强大组合,让每一次实验都清晰可溯,每一次优化都有据可依。
Hugging Face + W&B
通过无缝的 W&B 集成,快速可视化你的 Hugging Face 模型性能。
比较超参数、输出指标以及系统统计数据,如 GPU 利用率。

🤔 为什么我应该使用 W&B?

- 统一仪表盘:所有模型指标和预测的中央存储库
- 轻量级:无需代码更改即可与 Hugging Face 集成
- 可访问:个人和学术团队免费使用
- 安全:所有项目默认私有
- 可信:被 OpenAI、Toyota、Lyft 等机器学习团队使用
将 W&B 视为机器学习模型的 GitHub——将机器学习实验保存到你的私有托管仪表盘。快速实验,确保所有模型版本都已保存,无论你在哪里运行脚本。
W&B 的轻量级集成适用于任何 Python 脚本,你只需注册一个免费的 W&B 账户即可开始跟踪和可视化你的模型。
在 Hugging Face Transformers 仓库中,我们已将 Trainer 配置为在每个日志步骤自动将训练和评估指标记录到 W&B。
以下是集成工作原理的深入分析:Hugging Face + W&B 报告。
🚀 安装、导入和登录
安装 Hugging Face 和 Weights & Biases 库,以及本教程的 GLUE 数据集和训练脚本。
- Hugging Face Transformers:自然语言模型和数据集
- Weights & Biases:实验跟踪和可视化
- GLUE 数据集:语言理解基准数据集
- GLUE 脚本:用于序列分类的模型训练脚本
!pip install datasets wandb evaluate accelerate -qU
!wget https://raw.githubusercontent.com/huggingface/transformers/master/examples/pytorch/text-classification/run_glue.py
# run_glue.py 脚本需要 transformers dev 版本
!pip install -q git+https://github.com/huggingface/transformers
🖊️ 注册免费账户 →
🔑 输入你的 API 密钥
注册后,运行下一个单元格并点击链接获取你的 API 密钥以验证此笔记本。
import wandb
wandb.login()
可选地,我们可以设置环境变量以自定义 W&B 日志记录。查看 文档。
# 可选:记录梯度和参数
%env WANDB_WATCH=all
👟 训练模型
接下来,调用下载的训练脚本 run_glue.py,并查看训练自动跟踪到 Weights & Biases 仪表盘。该脚本在 Microsoft Research Paraphrase Corpus 上微调 BERT——包含人类标注的句子对,指示它们是否语义等价。
%env WANDB_PROJECT=huggingface-demo
%env TASK_NAME=MRPC!python run_glue.py \--model_name_or_path bert-base-uncased \--task_name $TASK_NAME \--do_train \--do_eval \--max_seq_length 256 \--per_device_train_batch_size 32 \--learning_rate 2e-4 \--num_train_epochs 3 \--output_dir /tmp/$TASK_NAME/ \--overwrite_output_dir \--logging_steps 50
👀 在仪表盘中可视化结果
点击上面打印的链接,或访问 wandb.ai 查看你的结果实时流入。浏览器中查看你的运行的链接将在所有依赖项加载后出现——查找以下输出:“wandb: 🚀 View run at [URL to your unique run]”
可视化模型性能 轻松查看数十个实验,放大有趣的发现,并可视化高维数据。

比较架构 这是一个比较 BERT vs DistilBERT 的示例——通过自动折线图可视化,可以轻松查看不同架构如何影响训练期间的评估准确性。
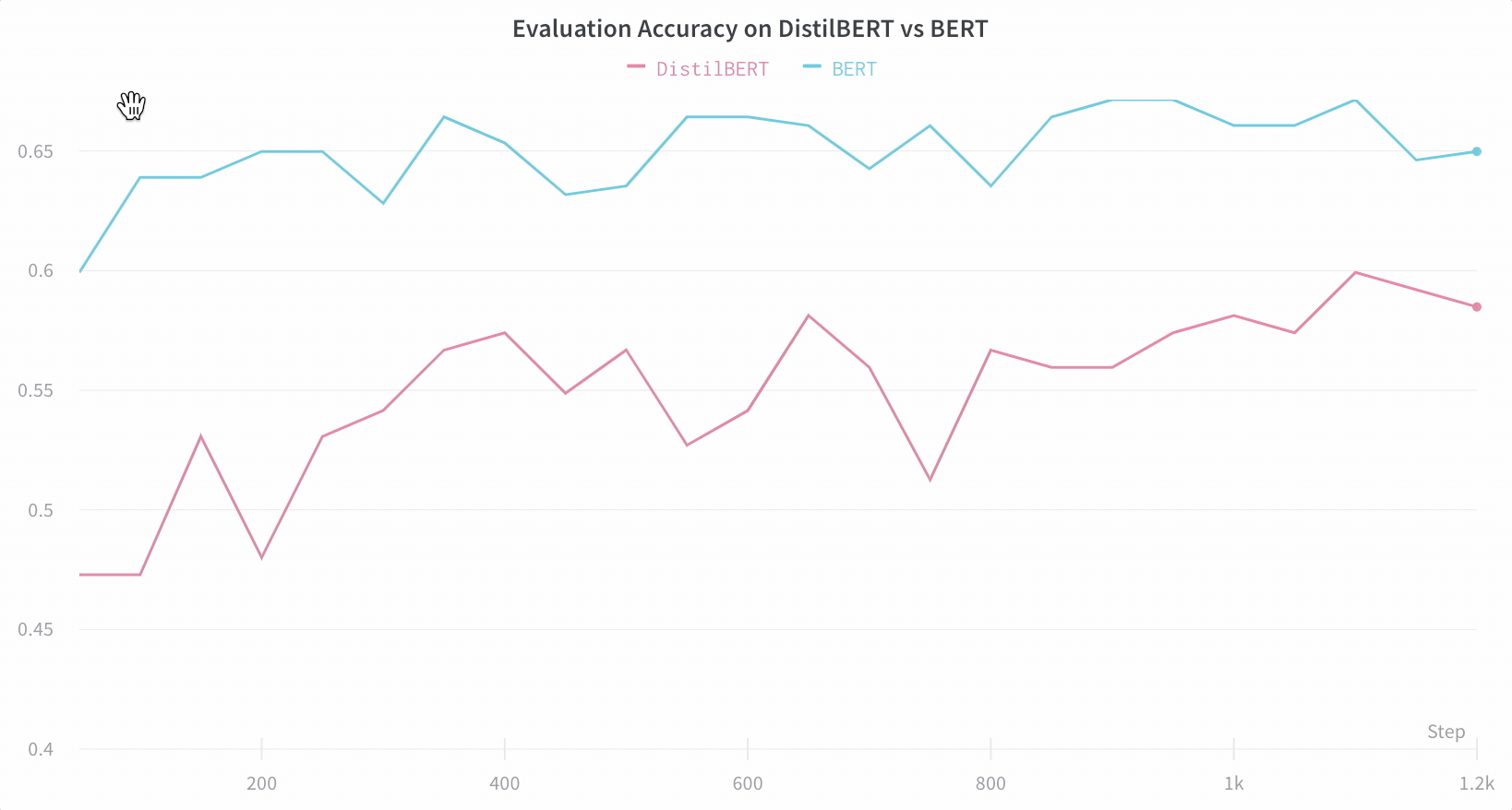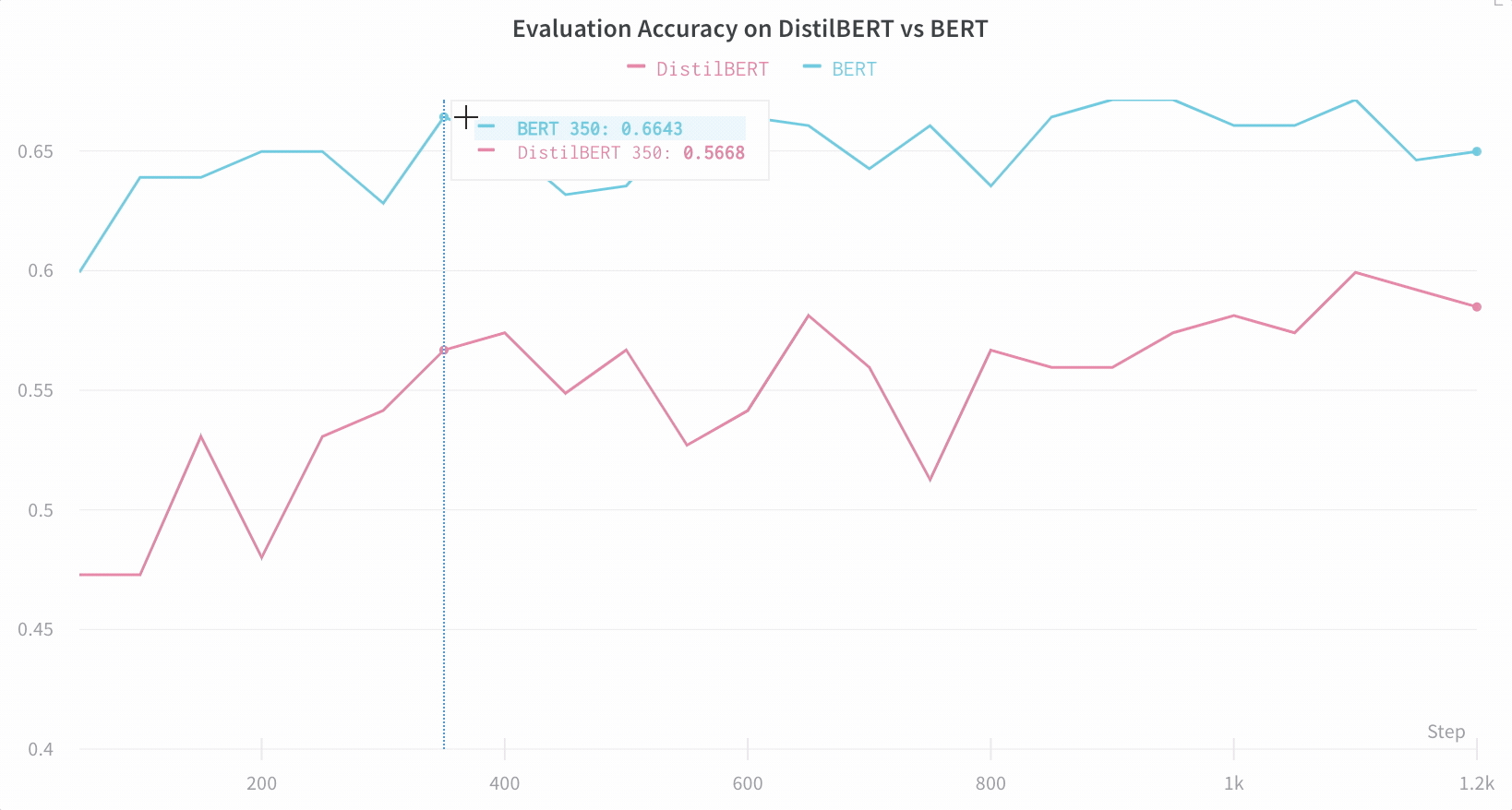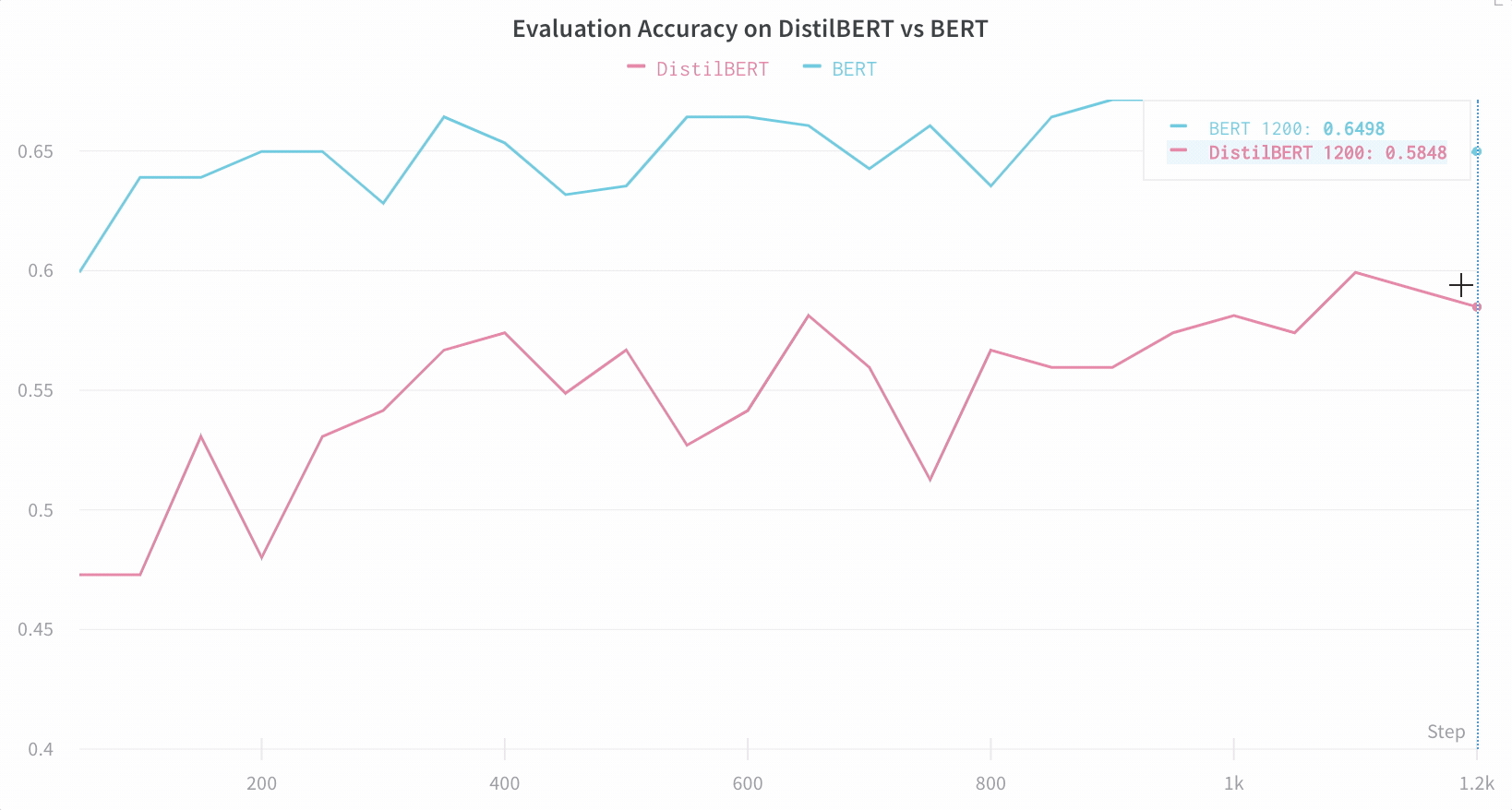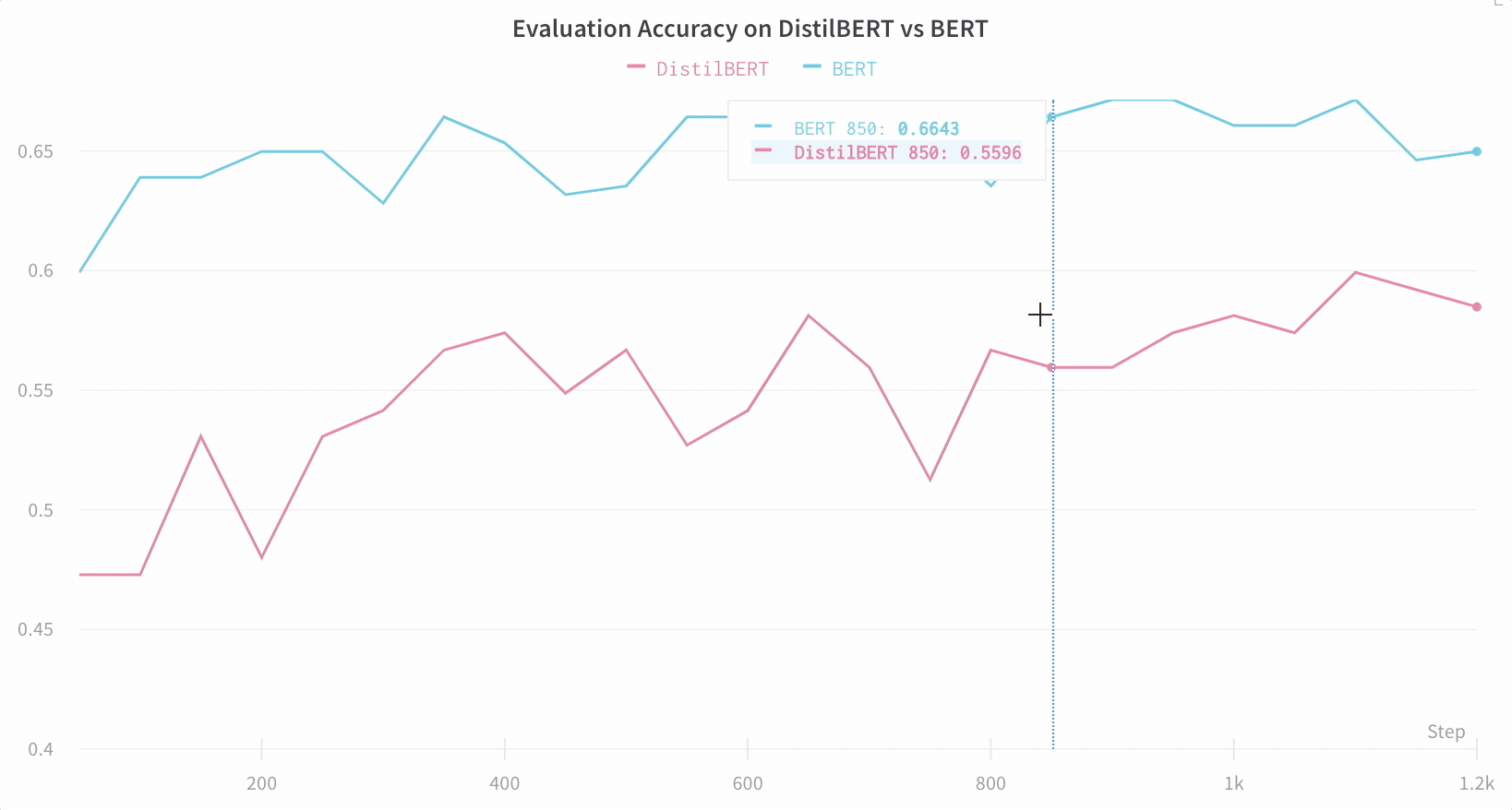
📈 默认情况下轻松跟踪关键信息
Weights & Biases 为每个实验保存一个新的运行。以下是默认保存的信息:
- 超参数:模型设置保存在 Config 中
- 模型指标:流式传输的指标时间序列数据保存在 Log 中
- 终端日志:命令行输出保存在选项卡中
- 系统指标:GPU 和 CPU 利用率、内存、温度等
🤓 了解更多!
- 文档:Weights & Biases 和 Hugging Face 集成的文档
- 视频:教程、与从业者的访谈等,请访问我们的 YouTube 频道
- 联系我们:如有问题,请发送邮件至 contact@wandb.com