XML解析
一,XML概述
1.什么是XML
- XML即为可扩展的标记语言(eXtensible Markup Language)
- XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识
2.XML和HTML不同之处
- XML主要用于说明文档的主题,而HTML侧重描述文本的显示格式。
- XML文档数据和格式分离,文档=文档数据+文档结构+文档样式
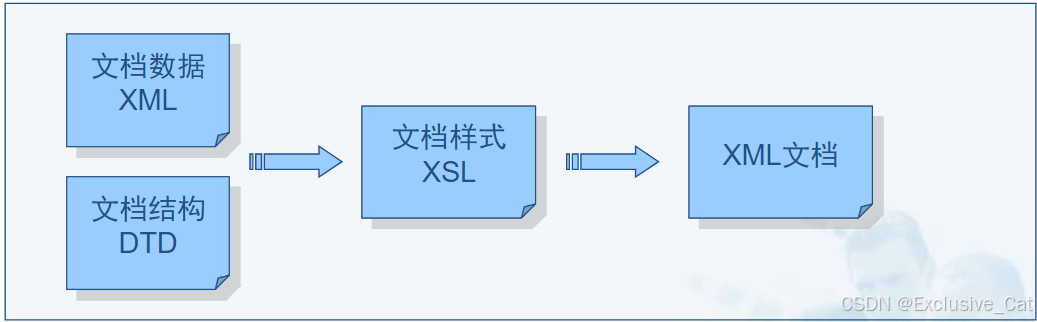
- XML是一种元标记语言,用户可以自己定义标记集,从而使数据具有自我描述性,而HTML的标记是不能自己定制的。
- XML支持Unicode字符集
3.Unicode
- Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。
- 常用 Unicode
- UTF-8:以字节为单位对Unicode进行编码 。
- UTF-16 :以16位无符号整数为单位 。
- GB2312:gb2312 出现较早 ,一些汉字和繁体不支持。
- GBK: 95年重新修订了编码,命名GBK1.0,共收录了21886个符号。
- 之后又推出了GBK18030编码,共收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字,现在WINDOWS平台必需要支持
- GBK18030编码。
按照GBK18030、GBK、GB2312的顺序,3种编码是向下兼容,同一个汉字在三个编码方案中是相同的编码。
二,XML文档结构
1.XML元素
(1)规范的XML文档中关于元素的几条原则
- 文档要包含一个或多个元素
- 根元素(文档元素)唯一,且其无任何部分出现在其他元素中
- 元素必须被正确关闭
- 元素不得交叉
- 属性值必须加引号(单引、双引均可)
(2)树形组织结构
- 父元素
- 子元素
2.XML与HTML标签对比
1. xml标签区分大小写(开始标签和结束标签大小必须一致)<tr></tr>
html标签不区分大小写<tr></TR>
2. xml中空元素标签必须被关闭<br/>
html中空元素标签可以不被关闭<br>
3. xml所有标签必须严格嵌套 <b><i></i></b>
html不一定严格嵌套 <b><i></b></i>
4. xml所有标签中的属性值字符必须加(“ ”)或(‘ ’),包括属性
值为数字时<student tel=‘0108888888’/>(内容有双引号使用
(‘’),内容有单引号使用(“”))
html属性值不一定用引号括起来 <hr color=blue>
5. xml只能有一个根元素
html可以有多个根元素
3.逻辑结构——XML文档结构
1. XML文档的构成一个格式良好的XML文档要包含三个部分:
- XML声明
- 处理指令(可选)
- XML元素
三,XML解析
1.XML解析
1. 将 XML 数据从其序列化字符串格式转换为分层格式,获取对应信息的过程
2. 语言无关性
3. 常用的四种解析方式
- DOM
- SAX
- JDOM
- DOM4J
2.DOM解析
1. 优点
- 允许应用程序对数据和结构做出更改
- 访问是双向的,可以在任何时候在树中上下导航,获取和操作任意部分的数据
2. 缺点
- 通常需要加载整个XML文档来构造层次结构,消耗资源大。
3.SAX解析
1. SAX处理的优点非常类似于流媒体的优点,事件驱动
2. 优点
- 不需要等待所有数据都被处理,分析就能立即开始
- 只在读取数据时检查数据,不需要保存在内存中
- 可以在某个条件得到满足时停止解析,不必解析整个文档
- 效率和性能较高,能解析大于系统内存的文档
3. 缺点
- 需要应用程序自己负责TAG的处理逻辑(例如维护父/子关系等),文档越复杂程序就越复杂
- 单向导航,无法定位文档层次,很难同时访问同一文档的不同部分数据
- 无状态性,事件过后查询内容不会自动保存
4.JDOM解析
1. 优点
- 使用具体类而不是接口,简化了DOM的API
- 大量使用了Java集合类,方便了Java开发人员
2. 缺点
- 没有较好的灵活性
- 性能较差
5.DOM4J解析
1. 优点
- 大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法
- 支持XPath
- 有很好的性能
2. 缺点
- 大量使用了接口,API较为复杂
3.常用类
- Document - 表示整个XML文档。文档Document对象是通常被称为DOM树。
- Element - 表示一个XML元素。 Element对象有方法来操作其子元素,它的文本,属性和名称空间。
- Attribute - 表示元素的属性。属性有方法来获取和设置属性的值。它有父节点和属性类型。
- Node - 代表元素,属性或处理指令
4.常用方法
- SAXReader.read(xmlSource)() - 构建XML源的DOM4J文档。
- Document.getRootElement() - 得到的XML的根元素。
- Element.node(index) - 获得在元素特定索引XML节点。
- Element.attributes() - 获取一个元素的所有属性。
- Node.valueOf(@Name) - 得到元件的给定名称的属性的值。
5. 文档读取
- SAXReader reader = new SAXReader();
- Document document = reader.read(new File(fileName));
6. 获取根节点
- root = document.getRootElement();
7. 遍历节点
- for ( Iterator i = root.elementIterator(); i.hasNext(); )
- Element element = (Element) i.next();
8. 创建xml文档
- Document document = DocumentHelper.createDocument();
- Element root = document.addElement("root");
9. 添加元素
- Element author2 = root.addElement(“student”)
- .addAttribute("name", “yaoMing")
- .addAttribute(“age", “20")
- .addText(“He is a boy");
10. I/O流生成xml文档
- FileWriter fileWiter = new FileWriter(“XXX.xml"))
- XMLWriter writer = new XMLWriter(fileWriter);
- writer.write( document );