操作系统动态分区分配算法-首次适应算法c语言实现
目录
一、算法原理
二、算法特点
1.优先利用低址空闲分区:
2.查找开销:
3.内存碎片:
三、内存回收四种情况
1.回收区上面(或后面)的分区是空闲分区:
2.回收区下面(或前面)的分区是空闲分区:
3.回收区上面和下面的分区都是空闲分区:
4.回收区上面和下面的分区都不是空闲分区:
四、实现要求
1.实验数据
2.要求
五、代码实现
六、实现效果
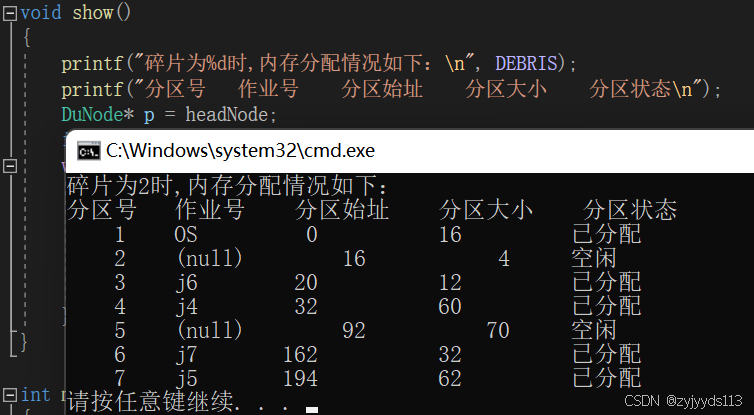
1.碎片为2
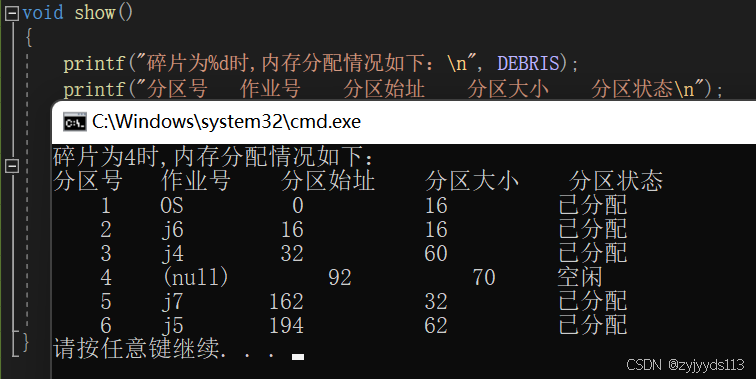
2.碎片为4
一、算法原理
首次适应算法要求空闲分区链按地址递增的次序链接。在分配内存时,从链首开始顺序查找,直到找到一个大小能满足要求的空闲分区,在根据作业大小把余下的空间与碎片大小进行比较,如果小于等于碎片大小,就全部分配给作业,否则将余下的空间仍留在空闲链中。若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。
二、算法特点
1.优先利用低址空闲分区:
首次适应算法倾向于优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区。这为以后到达的大作业分配大的内存空间创造了条件。
2.查找开销:
由于每次查找都是从低址部分开始的,这会增加查找可用空闲分区的开销。然而,由于算法简单且易于实现,这种开销在大多数情况下是可以接受的。
3.内存碎片:
首次适应算法容易产生内存碎片。当一个较大的分区被分配给较小的作业后,该分区的剩余部分可能无法再分配给其他较大的作业,导致内存碎片的产生。这些碎片无法被有效利用,从而降低了内存的利用率。
三、内存回收四种情况
1.回收区上面(或后面)的分区是空闲分区:
在这种情况下,操作系统会将回收区与上面的空闲分区合并,形成一个新的、更大的空闲分区。这样,就可以减少内存中的碎片数量,提高内存的利用率。
2.回收区下面(或前面)的分区是空闲分区:
与第一种情况类似,操作系统会将回收区与下面的空闲分区合并,形成一个新的空闲分区。这种合并操作同样有助于减少内存碎片,提高内存的连续性。
3.回收区上面和下面的分区都是空闲分区:
在这种情况下,操作系统会将回收区与上、下两个空闲分区都合并起来,形成一个更大的、连续的空闲分区。这种合并操作对于减少内存碎片、提高内存利用率具有显著的效果。
4.回收区上面和下面的分区都不是空闲分区:
在这种情况下,操作系统无法将回收区与其他空闲分区合并。此时,回收区将作为一个独立的空闲分区被加入到空闲分区表中。虽然这种情况下无法减少内存碎片,但操作系统仍然可以通过其他方式(如紧凑技术)来优化内存的使用。
需要注意的是,内存回收的过程不仅涉及到空闲分区的合并和更新,还需要考虑到操作系统的内存管理策略、进程调度策略等多个方面。此外,在不同的操作系统和内存管理算法中,内存回收的具体实现方式可能会有所不同。
四、实现要求
1.实验数据

2.要求
要求计算碎片分别是2K和4K时内存的分配情况。(要求分配时从高地址开始)。
五、代码实现
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>#define OSSIZE 16
#define MAXSIZE 256
#define DEBRIS 2 //碎片
//#define DEBRIS 4 //碎片
char* osname = "OS";
typedef struct areadata//空闲区
{ char* ID;//作业号 int address;//分区始址int size;//分区大小int state;//分区状态,0为空闲,1为已分配
} areadata;typedef struct DuNode//双向链表
{areadata data;struct DuNode* prior;struct DuNode* next;
} DuNode, * DuNodeList;DuNodeList headNode;
DuNodeList lastNode;
void initList()//双向链表初始化
{headNode = (DuNodeList)malloc(sizeof(DuNode));lastNode = (DuNodeList)malloc(sizeof(DuNode));if (headNode == NULL || lastNode == NULL){printf("动态内存开辟错误\n");exit(-1);}headNode->prior = NULL;headNode->next = lastNode;lastNode->prior = headNode;lastNode->next = NULL;headNode->data.ID = osname;headNode->data.address = 0;headNode->data.size = OSSIZE;headNode->data.state = 1;lastNode->data.address = OSSIZE;lastNode->data.size = MAXSIZE- OSSIZE;lastNode->data.ID = NULL;lastNode->data.state = 0;}
//首次适应算法
int firstFitAlloc(char* ID, int size)
{DuNode* p = headNode->next;while (p){if (p->data.size < size || p->data.state == 1){p = p->next;continue;}if (p->data.size - size <= DEBRIS){p->data.state = 1;p->data.ID = ID;return 1;}else{DuNodeList temp = (DuNodeList)malloc(sizeof(DuNode));if (temp == NULL) {printf("动态内存开辟错误\n");exit(-1);}temp->data.ID = ID;temp->data.size = size;temp->data.state = 1;temp->data.address = (p->data.address + p->data.size) - size;temp->next = p->next;temp->prior = p;if (temp->next){temp->next->prior = temp;}p->next = temp;p->data.size -= size;return 1;}p = p->next;}return 0;
}
//内存回收四种情况
void freeNode(char* ID)
{DuNode* p = headNode->next;while (p){if (p->data.ID == ID){p->data.ID = NULL;p->data.state = 0;//回收区前面的分区是空闲分区if (!(p->prior->data.state) && (p->next == NULL || p->next->data.state)){p->prior->data.size += p->data.size;p->prior->next = p->next;if (p->next != NULL)p->next->prior = p->prior;free(p);break;}//回收区后面的分区是空闲分区if (p->next != NULL && (!(p->next->data.state) && p->prior->data.state)){DuNode* tmp;tmp = p->next;p->data.size += p->next->data.size;if (p->next->next){p->next->next->prior = p;}p->next = p->next->next;free(tmp);break;}//回收区上面和下面的分区都是空闲分区if (p->next != NULL && (!(p->prior->data.state) && !(p->next->data.state))){p->prior->data.size += p->data.size + p->next->data.size;p->prior->next = p->next->next;if (p->next->next != NULL){p->next->next->prior = p->prior;}free(p->next);free(p);break;}break;}p = p->next;}
}
//输出打印信息
void show()
{printf("碎片为%d时,内存分配情况如下:\n", DEBRIS);printf("分区号 作业号 分区始址 分区大小 分区状态\n");DuNode* p = headNode;int a = 1;while (p != NULL) {printf("%5d ", a++);printf(" %s", p->data.ID);printf("%10d%12d", p->data.address, p->data.size);printf("\t %s\n", p->data.state == 0 ? "空闲" : "已分配"); p = p->next;}
}int main()
{initList();firstFitAlloc("j1", 134);firstFitAlloc("j2", 30);firstFitAlloc("j3", 64);freeNode("j1");freeNode("j3");firstFitAlloc("j4", 60);firstFitAlloc("j5", 62);freeNode("j2");firstFitAlloc("j6", 12);firstFitAlloc("j7", 32);show();return 1;
}六、实现效果
1.碎片为2
2.碎片为4