【嵌入式C语言】内存分布
内存分布
- 内存分布图
- 内存的属性:
- 只读空间
- 只读空间的特点
- 编程注意事项
- 栈空间
- 栈的工作原理
- 栈的特点
- 栈溢出
- 与堆的区别
- 堆空间
- 堆的特点
- 内存分配函数
- 内存泄漏
- 总结
内存分布图
内存的属性:
在C语言中,内存的属性主要取决于它是如何分配的以及它在程序中的作用。我们可以将内存分为以下几个主要类别:
-
静态存储区(Static Storage Duration):
- 静态变量和全局变量存储在这里。
- 这些变量在程序启动时初始化,在程序结束时销毁。
- 它们的生命周期是整个程序的执行过程。
- 内存由编译器自动管理,程序员无需手动释放。
-
自动存储区(Automatic Storage Duration):
- 函数内部定义的局部变量通常存储在此区域。
- 这些变量在函数调用开始时创建,在函数结束时销毁。
- 每次调用函数都会为这些变量分配新的空间。
-
动态存储区(Dynamic Storage Duration):
- 通过
malloc、calloc、realloc等函数分配的内存块。 - 这些内存块可以在程序运行期间任何时间点分配或释放。
- 程序员负责管理这部分内存,使用
free函数来释放不再需要的内存以防止内存泄漏。
- 通过
-
线程存储区(Thread Storage Duration, C11引入):
- 使用
_Thread_local关键字声明的变量存储在这里。 - 这些变量为每个线程单独实例化一次,并且存在于线程的整个生命周期中。
- 使用
-
常量存储区:
- 字符串字面量和其他常量数据通常存储在这里。
- 这部分内存中的值不应该被修改(尝试修改可能导致未定义行为)。
-
堆栈(Stack)与堆(Heap):
- 堆栈用于实现自动存储区,具有快速分配和释放的特点,因为它的操作遵循后进先出(LIFO)原则。
- 堆用于实现动态存储区,允许更灵活的内存管理,但分配和释放速度相对较慢。
每种类型的内存都有其特定的用途和管理方式,理解它们的区别对于编写高效且无错误的C程序至关重要。此外,了解这些概念有助于避免常见的编程错误,如内存泄漏、悬空指针和缓冲区溢出等。
最重要的内存属性就是大小和位置
- 大小
- 在哪里
编译-汇编-链接-运行
链接就是把.o文件链接在一起,生成可执行文件,如下图所示,放到section中,就是放到各个段中
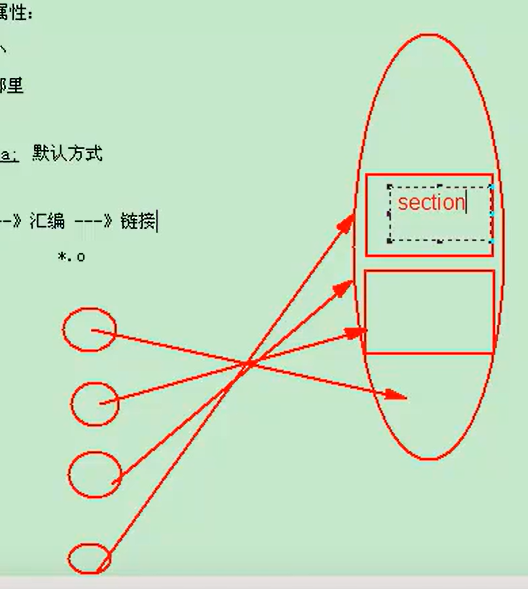
一个变量存放的位置不同,效果是否不同呢?
运行如下代码测试:
#include <stdio.h>
int main(int argc, char **argv[])
{int a = 0x10;printf("the a is %p\n", &a);printf("main is %p\n", main);return 0;
}
输出结果如下,可以看到这两个地址相差很远,猜测应该在不同的段中~
the a is 000000000061FE1C
main is 0000000000401550
修改成全局变量,看一下输出结果如何
#include <stdio.h>
int a = 0x10;
int main(int argc, char **argv[])
{printf("the a is %p\n", &a);printf("main is %p\n", main);return 0;
}
输出结果如下,可以看到两个地址相差很小,猜测在同一个段中~
the a is 0000000000403010
main is 0000000000401550
内存分布图
高地址
---------------------------------
内核空间(应用程序不可访问)
---------------------------------3G
栈空间(局部变量) RW
---------------------------------
运行时的堆空间(malloc分配的内存)
---------------------------------
全局数据空间(初始化的、未初始化的)static RW data bss
只读数据段(字符串常量、"Hello world!") R TEXT
代码段(code) R TEXT
---------------------------------
0x0;低地址
只读空间
只读空间是静态空间,整个程序结束时释放内存,生存周期最长。
代码段:存放程序代码,可读不可写,存放程序执行代码的二进制机器指令
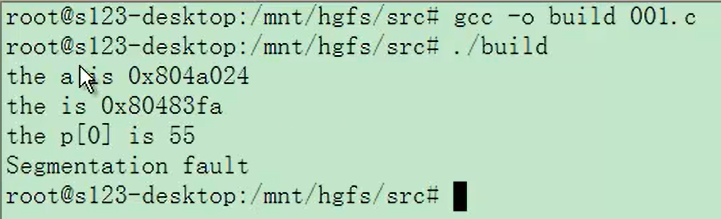
修改代码段的内容,会导致程序崩溃,下面是示例程序
#include <stdio.h>
int a = 0x10;
int main()
{printf("the a is %p\n", &a);printf("main is %p\n", main);unsigned char *p = (unsigned char *)main;printf("p[0] is %x\n", p[0]);p[0] = 0x90;printf("+++++++++p[0] is %x\n", p[0]);return 0;
}
win10的运行结果
the a is 0000000000403010
main is 0000000000401550
p[0] is 55
后面的内容就输出不成功了,程序崩溃了;在linux系统中这里能提示出现了段错误。
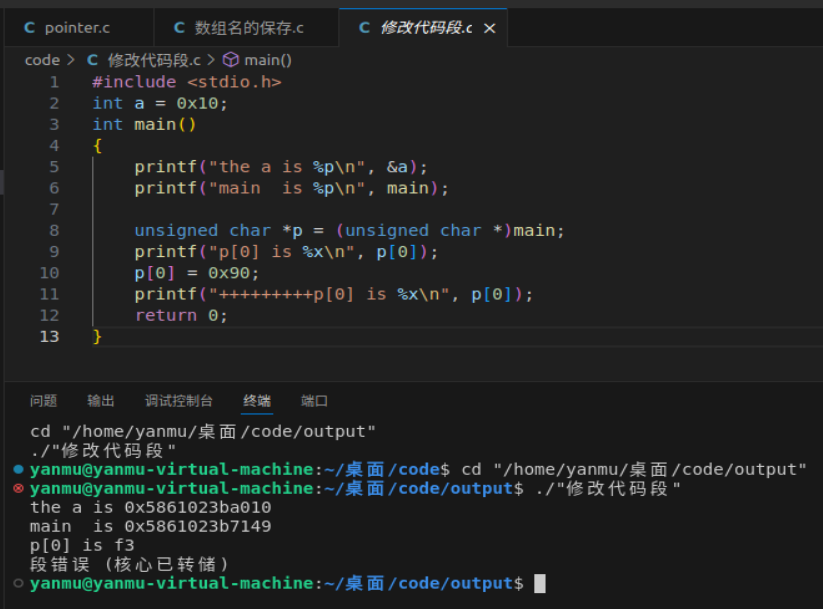
在C语言中,只读空间(Read-Only Memory, ROM)通常用于存储程序运行期间不应该被修改的数据。这类数据包括但不限于:
-
字符串字面量:当你在代码中使用字符串如
"Hello, world!"时,这些字符串常量会被存储在只读区域。 -
全局或静态常量:使用
const关键字声明的全局变量或静态变量如果初始化了,则它们可能会被放置在只读段中。例如:
const int MAX_SIZE = 100;
-
函数代码:编译后的机器指令一般也被存放在只读内存区域,以防止意外或恶意地修改程序的行为。
-
其他不可变数据结构:一些编译器和链接器可能会选择将特定类型的常量数据放入只读段,以优化程序性能和保护数据完整性。
只读空间的特点
-
不可修改性:一旦程序加载,这部分内存中的内容不能被程序修改。任何尝试修改只读内存的行为都会导致未定义行为,这可能包括程序崩溃或安全漏洞。
-
共享性:由于只读数据不会改变,多个进程可以共享同一块只读内存,从而节省内存资源。例如,当多个进程执行同一个程序时,它们可以共享该程序的代码部分。
-
持久性:只读数据通常在程序启动时加载,并且在整个程序运行期间保持不变,直到程序结束。
编程注意事项
当你编写C程序时,应该避免尝试修改任何你认为是只读的数据。如果你需要修改一个看起来像是常量的东西,那么你应该确保它不是存储在只读内存中,或者创建一个可写的副本。此外,在某些嵌入式系统开发环境中,了解如何正确配置和使用只读内存对于优化性能和资源管理非常重要。
栈空间
程序运行时的空间,函数内部使用的变量,函数一旦返回,就释放了,生存周期(在函数内)较短。
- 使用size命令查看可执行文件的大小
- 局部变量,一旦返回之后,就失效了,访问不了了
- 全局变量赋值之前放在bss段,赋值之后放在data段
- static变量(没有初始化的),放在bss段。
- 使用nm命令查看可执行文件中的符号表。
nm .\修改代码段.exe
PS E:\CProject\内存分布图\output> size .\修改代码段.exetext data bss dec hex filename9868 2244 2432 14544 38d0 .\修改代码段.exe
栈空间(Stack)是计算机内存中用于存储程序运行时数据结构的一个区域,具有后进先出(LIFO, Last In First Out)的操作特性。在C语言编程中,栈空间主要用于以下几种用途:
-
函数调用:每当一个函数被调用时,一个新的栈帧(也叫激活记录)会被创建并压入栈顶。这个栈帧包含了该函数的局部变量、参数以及返回地址等信息。
-
局部变量存储:在函数内部定义的自动变量(即没有使用
static修饰符的变量)通常会被分配到栈上。这些变量在函数调用开始时创建,在函数结束时自动销毁。 -
保存寄存器状态:当函数调用发生时,为了保证调用者环境的安全,CPU寄存器的内容也会被保存到栈上,并在函数返回前恢复。
-
临时数据:编译器可能还会使用栈来存储中间计算结果或其他临时性数据。
栈的工作原理
- 栈指针(Stack Pointer, SP):这是一个特殊的寄存器,指向当前栈顶的位置。
- 压栈(Push):将数据项添加到栈顶。这会减少SP的值(在大多数架构中,栈是从高地址向低地址增长的)。
- 弹栈(Pop):从栈顶移除数据项,并将其值赋予另一个位置或寄存器。这会增加SP的值。
- 栈帧(Frame):每个函数调用都会创建一个新的栈帧,它包含该函数所需的所有信息,如局部变量、参数和返回地址。
栈的特点
- 快速访问:由于栈的操作简单且直接(仅涉及栈顶),因此其操作速度非常快。
- 自动管理:栈上的内存由编译器自动管理,程序员无需显式地释放内存。
- 有限大小:栈的空间通常是有限的,如果超出这个限制就会导致栈溢出错误。例如,递归深度过大或者局部变量占用过多空间都可能导致这种情况。
栈溢出
栈溢出是指栈空间耗尽的情况,可能会导致程序崩溃或者其他未定义行为。常见的原因包括无限递归、过大的局部数组等。为了避免栈溢出,应该注意避免不必要的深递归调用,并谨慎处理大尺寸的局部变量。
与堆的区别
栈和堆都是程序用来动态分配内存的区域,但它们有着显著的不同:
- 分配方式:栈是由编译器自动管理的,而堆需要程序员通过诸如
malloc、calloc、realloc和free等函数手动管理。 - 生存期:栈上的对象在其对应的函数调用结束后自动消失;堆上的对象则持续存在直到显式释放。
- 性能:由于栈的操作更简单,所以通常比堆更快。
- 大小:一般而言,栈的大小相对较小,而堆可以扩展到系统可用内存的最大限度。
了解栈的工作机制对于编写高效、安全的C代码非常重要,尤其是在设计复杂的数据结构和算法时。
堆空间
程序运行时,可以自由,自我管理的分配和释放的空间。生命周期由程序员来决定。
分配:malloc,calloc,realloc,new
malloc();一旦分配成功,就返回分配好的地址给我们,只需要接收;对于这个新地址的读法,由程序员灵活把握,输入参数指定分配的大小,单位是B。
char *p;
p = (char *)malloc(10*sizeof(char));
if (p == NULL)
{// error
}
malloc函数的用法
#include <stdio.h>
#include <stdlib.h>
int main()
{int *p = (int *)malloc(10 * sizeof(int));if (p == NULL){printf("malloc failed\n");return -1;}
}
释放:free,delete
- free 和 malloc是配套使用的,malloc分配的内存,一定要用free释放,否则会造成内存泄漏!!!
- free();释放malloc分配的内存,释放之后,这块内存就可以被再次分配了。
堆空间(Heap)是内存中用于动态分配内存的一个区域,它允许程序在运行时请求和释放任意大小的内存块。与栈不同的是,堆的空间管理是由程序员负责的,并且它的内存分配不依赖于函数调用栈。以下是关于C语言中堆空间的一些重要信息:
堆的特点
-
动态内存分配:堆主要用于在程序运行期间动态地分配和释放内存。这意味着可以在程序执行过程中根据需要分配内存,而不是在编译时确定。
-
手动管理:与栈上的自动变量不同,堆上的内存分配和释放必须由程序员显式地进行。这提供了更大的灵活性,但也增加了管理和维护的复杂性。
-
生存期长:堆上分配的对象在其被显式释放之前一直存在。这意味着它们可以跨越多个函数调用或整个程序的生命周期。
-
碎片化问题:由于堆上的内存块可以以任意顺序分配和释放,因此可能会导致内存碎片化,即虽然有足够的总可用内存,但没有足够大的连续内存块来满足新的分配请求。
-
较慢的操作速度:相比栈操作,堆上的分配和释放通常更慢,因为涉及到更复杂的内存管理逻辑。
内存分配函数
C语言提供了几个标准库函数来处理堆上的内存分配和释放:
-
malloc(size_t size):分配指定字节数的内存,并返回指向这块内存的指针。如果分配失败,则返回NULL。 -
calloc(size_t num, size_t size):为num个元素,每个元素占用size字节的内存分配空间,并将所有内容初始化为零。同样,在分配失败时返回NULL。 -
realloc(void *ptr, size_t new_size):调整之前通过malloc、calloc或realloc分配的内存块的大小。它可以增大或缩小内存块。如果无法调整原内存块的大小,它会尝试分配新的内存块并将旧数据复制过去,然后释放旧的内存块。如果调整失败,则返回NULL,而原来的内存块保持不变。 -
free(void *ptr):释放之前分配的内存块。释放后的指针不应再被使用,否则会导致未定义行为。
内存泄漏
当程序分配了堆上的内存但忘记释放时,就会发生内存泄漏。这些未释放的内存块不能再被程序使用,从而浪费了系统资源。长时间运行的应用程序如果不正确管理堆内存,可能会逐渐消耗掉所有可用内存,最终导致性能下降甚至崩溃。
为了避免内存泄漏,应该确保每次调用malloc、calloc或realloc后,都有相应的free调用来释放不再需要的内存。此外,还可以使用一些工具和技术(如Valgrind等内存调试工具)来检测和预防内存泄漏。
总结
堆空间提供了一种灵活的方式来管理程序运行时所需的内存,但同时也要求程序员更加小心谨慎地管理内存的分配和释放,以避免常见的错误如内存泄漏、悬空指针等问题。理解如何有效地利用堆对于编写高效、可靠的C程序至关重要。