【论文复现】分割万物-SAM

📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀ 分割万物-SAM
- 介绍
- 原理
- 分割任务
- 任务
- 预训练
- zero-shot transfer
- 相关任务
- 模型
- Image Encoder
- Prompt Encoder
- Mask Eecoder
- 消除歧义
- 高效
- Loss 和训练细节
- 推理与部署
- 读取图片
- 选择模型
- 加载模型
- prompt
- 推理
- WebUI
介绍
Segment Anything(SAM)是 Meta/FAIR 提出的以 data-centric AI 理念搭建的机器视觉分割模型,堪称图像分割领域的 GPT!SAM 在 1100w 张图片上镜像训练,拥有分割万物的能力。无论是庞然大物、还是精细入微,都可以准确区分。
可以点击此处体验模型demo。
论文地址见此。
原理
分割任务
任务
任务(Task)是由 NLP 领域带来的灵感。在 NLP 中通过预测 next token 作为预训练的任务,在下游任务中使用 prompt engineering 作为应用。出于图像分割的需要,SAM 将prompt 分为以下几种类型:
- point
- box
- mask
- 文本
本文所涉及的所有资源的获取方式:这里
预训练
可提示的分割任务提出一种自然的预训练算法,模拟多种 sequence 的 prompt,并且每一次训练都与 ground truth 进行比较。
zero-shot transfer
预训练任务赋予了模型在推理时对任何提示做出适当反应的能力,因此下游任务可以通过设计合适的提示来解决。例如在实例分割中,可以提供一个检测得到的 box, SAN 就可以利用该 promp 进行实例分割。
相关任务
分割可以细分出很多领域:交互式分割、边缘检测、超像素化、目标提案生成、前景分割、语义分割、实例分割、全景分割等。而SAM时一个具有广泛适用性的模型,通过 prompt 可以适应许多现有的和新的分割任务。
模型
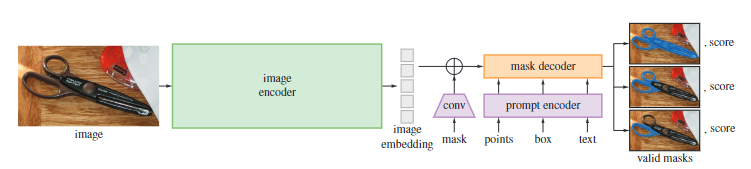
上图展示了 SAM 的结构。SAM 由以下三个部分组成。
Image Encoder
使用 MAE 预训练 ViT 模型处理高解析输入。Image Encoder 对每张图像运行,并用于提示模型。
Prompt Encoder
模型设计了两种 prompt:稀疏(points,boxes,text)、密集(masks)。点和框使用位置编码表示,与每种 prompt 的 learned embedding 相加。而文本使用来自 CLIP 的现成文本 encoder。密集型提示使用卷积进行 embedded, 与图像 embedding 相加。
Mask Eecoder
该部分有效地将 image embedding、 prompt embedding、 和输出 token 映射到一个 mask 上。修改 transformer decoder 块,将 image embedding 和prompt embedding 做双向的 cross-attention。
消除歧义
只有一个输出的情况下,如果给了一个模棱两可的提示,模型会对多个有效的 mask 进行平均处理。为了解决这个问题,模型被修改为对单个提示预测多个输出。而且可以发现,三个输出就可以解决大多数常见情况。
高效
模型设计得非常高效,在 web 浏览器上 CPU 计算只需要约 50 ms。、
Loss 和训练细节
主要使用 focal loss 和 dice loss。对于每个 mask 模型会随机产生 11 种 prompt 进行配对。
推理与部署
大部分可以使用的推理场景在文件中的 notebook 中,打开后可以根据自己的需要运行任何一个部分。
此处介绍模型的推理方法。
首先确保安装对应的依赖
pip install git+https://github.com/facebookresearch/segment-anything.git
pip install opencv-python pycocotools matplotlib onnxruntime onnx gradio
读取图片
需要使用 opencv 读取图片,使用以下代码读取一张图像:
import cv2
image = cv2.imread('imgs/example.jpg')
选择模型
SAM有三种模型可以选择,分别为sam_vit_l_0b3195、sam_vit_b_01ec64、sam_vit_h_4b8939。规模、效果以及需要的算力依次增加。
sam_checkpoint = "checkpoint/sam_vit_h_4b8939.pth"
model_type = "vit_h"device = "cuda"
加载模型
使用sam_model_registry 加载指定的模型并得到预测器。将图片作为预测器的输入即可。
from segment_anything import sam_model_registry, SamPredictor
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)predictor = SamPredictor(sam)predictor.set_image(image)
prompt
SAM 可以接受多种形式的prompt。例如多个点和一个方框。同时也需要提供对应的标签。
import numpy as np
input_point = np.array([[300, 300], [350, 350]])
input_label = np.array([1, 1])
input_box = np.array([150, 100, 320, 500])
推理
推理只需要使用预测器的 predict 函数,该函数接受多个点输入,最多一个方框的输入,与对应的标签。multimask_output 表示是否输出多个预测。masks 即为模型的预测结果。
masks, _, _ = predictor.predict(point_coords=input_point,point_labels=input_label,box=input_box[None, :],multimask_output=False,
)
WebUI
为了方便大家操作,制作了一个可以输入提示的网站。使用python webui.py即可启动网站。
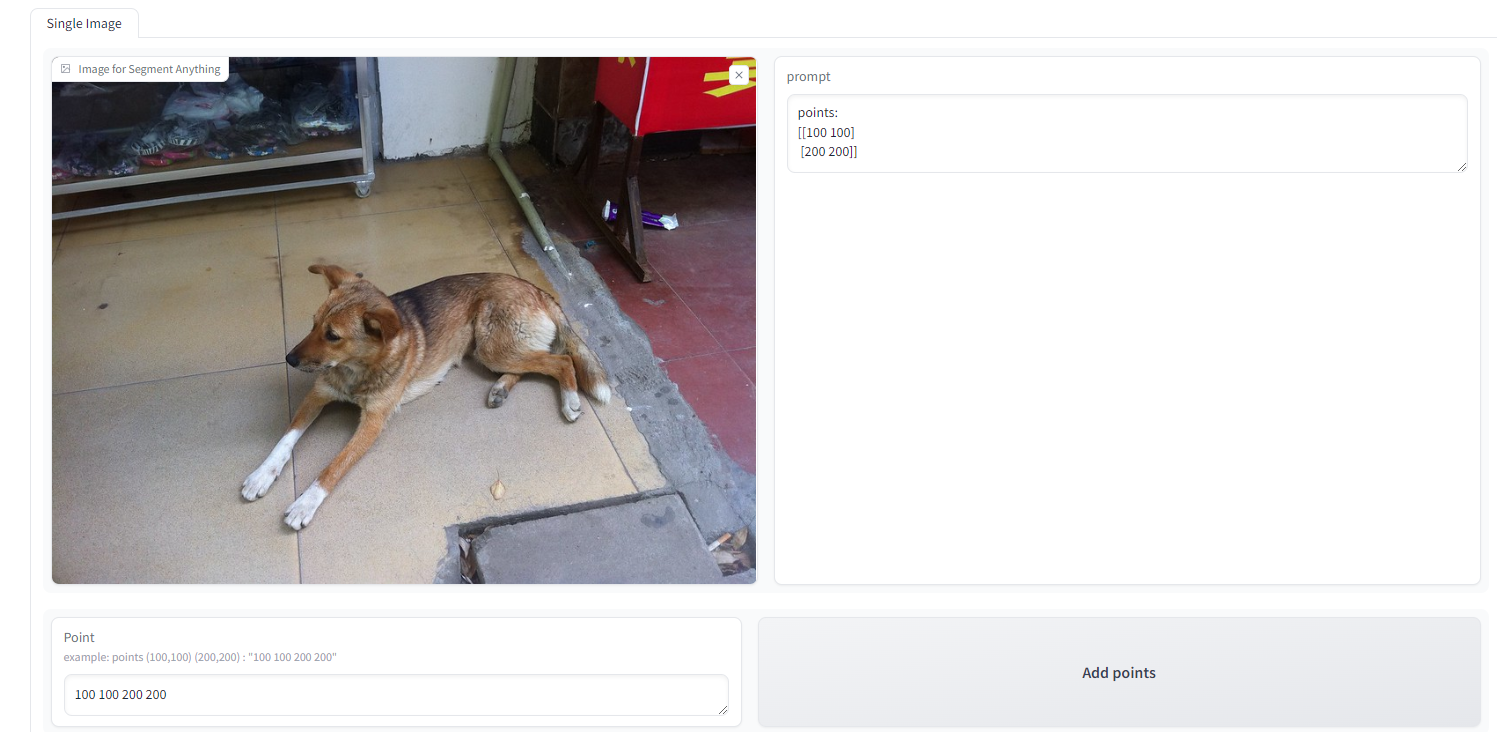
在 Point 一栏输入点的横纵坐标,SAM 就可以去识别点所标记的物体。支持多个点输入,例如(100,150)(250,300)就输入 “100 150 250 300” 即可。点击右侧的 Add 将点添加进 prompt 中。点击 Preview 可以预览点所在的位置。没有任何输入时点击预览可以查看图片的坐标轴。点击底部的 Run 即可根据输入的 prompt 分割图像,分给结果展示在下方。


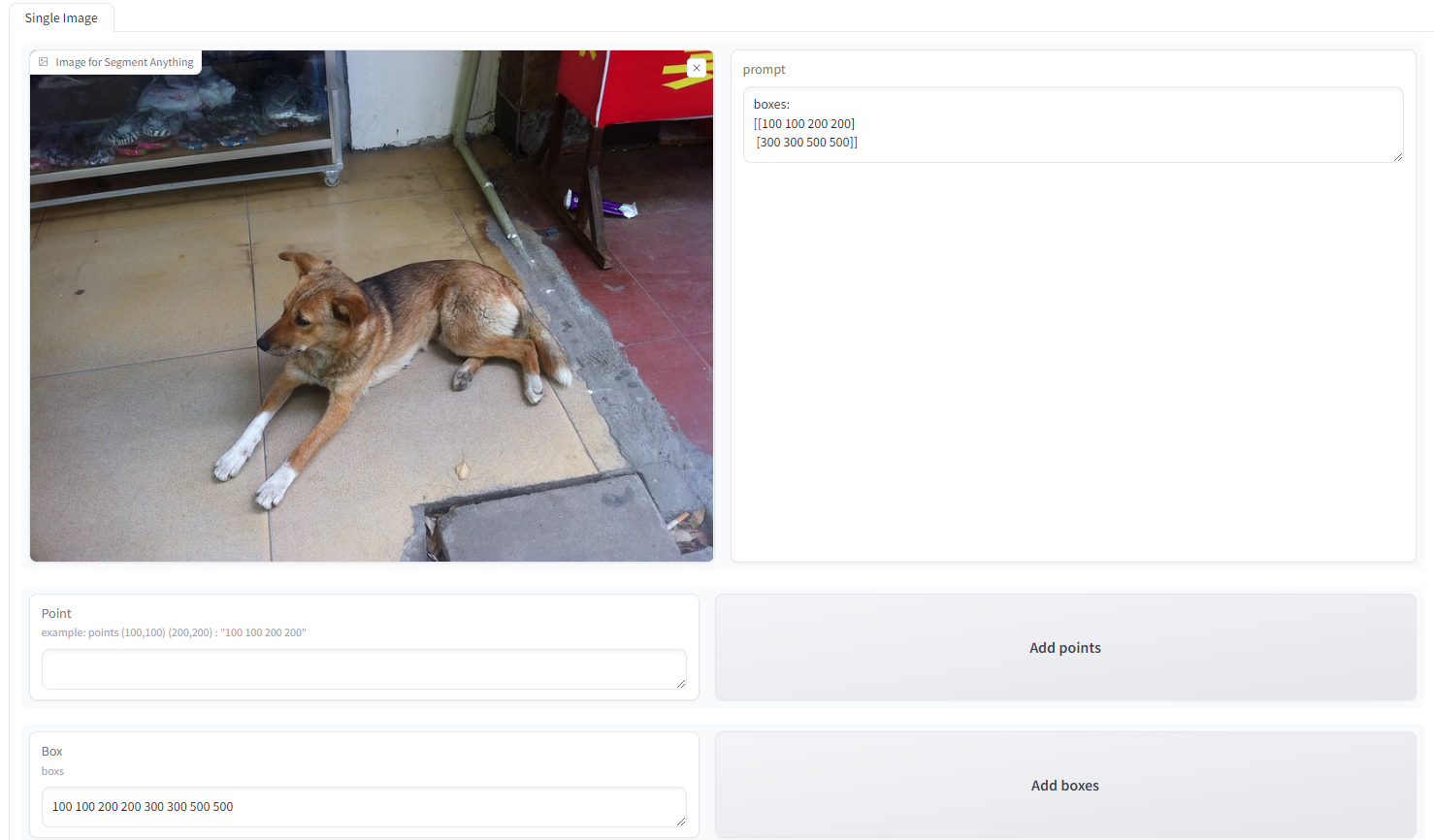
在 Box 一栏输入方框左上角的横纵坐标与右下角的横纵坐标。方框(100,100,200,200)和(300,300,500,500)就输入为"100 100 200 200 300 300 500 500 "点击右侧的 Add 将方框添加进 prompt 中。点击 Run 运行,现在不支持点和方框的混合输出。


编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里