CV22_语义分割基础
1. 常见的分割类型
在计算机视觉领域,根据不同的应用场景和需求,分割任务可以分为几种主要类型。以下是几种常见的分割类型:
语义分割(Semantic Segmentation):
语义分割的目标是将图像中的每个像素分配到一个预定义的类别中。这类分割关注的是类别级别的识别,即所有属于同一类别的对象都被标注为相同的标签。例如,在自动驾驶场景中,将路面、行人、车辆等分别标注出来。
实例分割(Instance Segmentation):
实例分割不仅识别图像中的对象类别,还能区分出同一类别中的不同个体。这意味着对于每一种对象类别,每个具体的实例都会被单独标识。例如,在一张包含多个人的图片中,不仅要识别出所有的人都属于“人”这一类别,还要能够区分每一个人。
全景分割(Panoptic Segmentation):
全景分割结合了语义分割和实例分割的优点,旨在同时处理场景中的所有元素,无论是可数的个体对象还是不可数的背景区域。这种方法能够为每个像素提供一个唯一的标签,确保每个对象实例都得到明确的识别。
交互式分割(Interactive Segmentation):
交互式分割允许用户通过简单的输入(如点击、拖拽等)参与到图像分割的过程中,以指导算法更好地完成任务。这种方式常用于需要高精度分割结果的场合,如医学图像分析。
医学图像分割(Medical Image Segmentation):
医学图像分割专门针对医疗影像数据,目的是准确地识别和分离出组织、器官或病变区域。这种类型的分割对于临床诊断、手术规划以及疾病研究至关重要。
视频分割(Video Segmentation):
视频分割是在视频序列中执行的分割任务,它不仅需要考虑单帧图像的信息,还需要利用时间维度上的连续性来提高分割的准确性。这在运动分析、行为识别等领域有重要应用。
弱监督分割(Weakly Supervised Segmentation):
弱监督分割试图在较少的标注数据或者不完全标注的情况下完成分割任务。例如,可能只有图像级别的标签而没有像素级别的标注,这种情况下算法需要从有限的信息中学习并推断出详细的分割结果。
每种分割类型都有其特定的应用场景和技术挑战,随着计算机视觉技术的进步,这些领域的研究也在不断深入和发展。

2. 分割常见的数据集类型
PASCAL VOC (Visual Object Classes)
PASCAL VOC 是一个经典的计算机视觉数据集,最初用于目标检测和分类任务。后来扩展到了语义分割任务,包含了20个常见的物体类别和一个背景类别。每个图像都有对应的像素级标签。
请注意:PASCAL VOC数据集的png格式的图片实际上是单通道的类型,,不是我们常见的RGB三通道类型。(该数据集用的是“调色板”的模式去存储颜色信息。比如像素0对应的是(0,0,0)黑,,1对应的是(127.0, 0)深红像素,255对应的是(224,224,129)。在背景处的像素值为0,目标边缘处用的像素值为255,目标区域内根据目标的类别索引信息进行填充,例如人对应的目标索引是15,所以目标区域的像素值用15填充。)
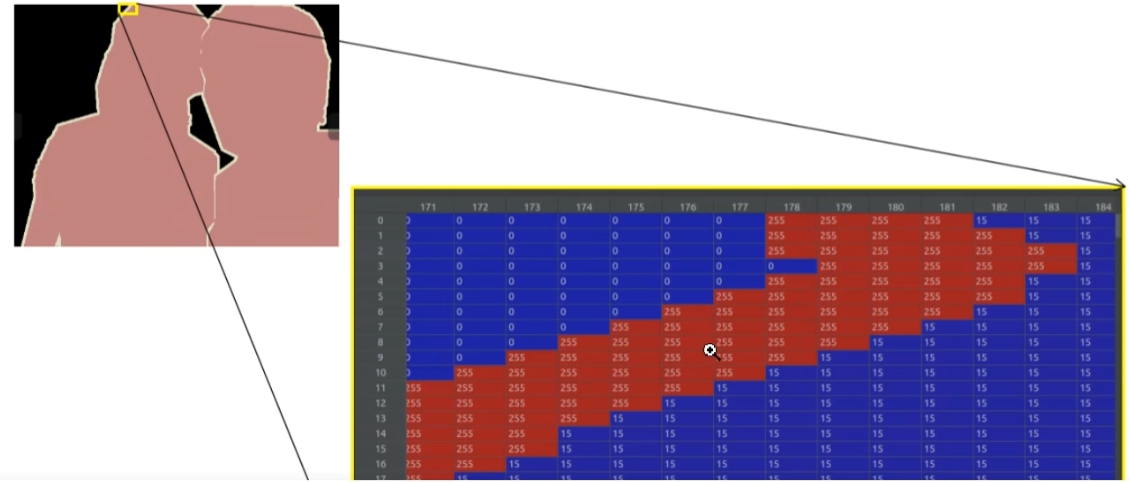
有些分割比较困难的目标,比如下图,左下角只有一个飞机的尾翼,并没有完整的飞机,分割有一定的难度,我们为了减小损失,就用相同颜色的像素遮盖了这个部分。

COCO (Common Objects in Context)
COCO 数据集是一个大规模的数据集,主要用于目标检测、分割和字幕生成任务。它包含了超过20万张图片,标注了80个类别,并提供了丰富的实例分割标注。
MS COCO数据集提供了每个目标的多边形坐标。(X坐标,Y坐标,两两一组)
MS COCO并没有标注边缘信息。除了可以做语义分割还可以做实力分割,因为每个目标的具体坐标都给出来了。

ADE20K (A Diversity of Environments)
ADE20K 是一个大型的场景解析数据集,包含超过2万张图片,涵盖了室内和室外的各种场景。它标注了150多个类别,适合进行复杂的场景解析任务。
Cityscapes
Cityscapes 数据集专注于城市街景图像的语义分割任务,提供了来自50个城市的高质量图片,标注了30个类别,包括道路、行人、汽车等。这个数据集特别适用于自动驾驶和城市监控系统的研究。
CamVid (Cambridge Driving Labeled Video Database)
CamVid 是一个用于评估视觉理解系统的视频数据集,包含了驾驶过程中的街景视频片段。它提供了像素级的标注,涵盖11个类别,适合进行视频分割的研究。
PASCAL Context
PASCAL Context 是基于PASCAL VOC 数据集的一个扩展,增加了更多类别的标注,特别是那些在原始PASCAL VOC 数据集中未被标注的对象和背景元素。它共有463个类别,适合进行细粒度的场景解析。
SUN RGB-D
SUN RGB-D 数据集包含了超过10万个RGB-D图像,这些图像是从室内环境中采集的。它提供了丰富的注释信息,包括深度图、表面法线、物体边界框等,适合进行室内场景的理解和分割。
MIT Scene Parsing Benchmark (Scene Understanding Challenge)
MIT Scene Parsing Benchmark 提供了一个用于评估场景解析算法的数据集,包含超过7171张图片,标注了150个类别。该数据集强调场景理解的多样性。
BDD100K (Berkeley DeepDrive)
BDD100K 是一个大规模的驾驶场景数据集,包含了超过10万段视频片段,标注了10个类别。它还提供了多种其他注释,如目标检测、车道检测等,适合进行自动驾驶相关的研究。
3.语义分割得到的结果
类别标签:
每个像素的标签是一个整数,表示该像素所属的类别。例如,0 可能表示背景,1 表示道路,2 表示行人,等等。标签的具体含义取决于数据集的定义。
颜色编码:
为了可视化和解释方便,通常会将类别标签转换为颜色编码图像。每个类别对应一种颜色,这样可以直接看到分割结果的分布情况。例如,道路可以用灰色表示,行人用红色表示,汽车用蓝色表示等。

4. 语义分割的评价指标
为了评估语义分割模型的性能,通常采用多种指标。以下是常见的语义分割评价指标及其详细说明:
1. 像素准确率(Pixel Accuracy, PA)
定义:像素准确率是指模型预测正确的像素数占总像素数的比例。

优点:计算简单,易于理解。
缺点:当类别不平衡时,像素准确率可能会受到影响,因为背景类通常占大多数。
2. 均值像素准确率(Mean Pixel Accuracy, MPA)
定义:均值像素准确率是指每个类别的像素准确率的平均值。

优点:对于类别不平衡的问题,MPA可以避免背景类对整体指标的影响。
缺点:当某些类别的像素数较少时,可能导致其对指标影响较大。
3. 交并比(Intersection over Union, IoU)
定义:IoU是评估模型分割精度的常用指标,表示预测区域与实际区域的交集与并集之比。

优点:IoU可以精确反映模型的分割性能,尤其是在类别不平衡时具有较好的鲁棒性。
缺点:IoU值较低时,可能导致一些类别的性能评价不够全面。
4. 均值交并比(Mean IoU, mIoU)
定义:均值交并比是各个类别IoU的平均值,反映了整体模型在所有类别上的分割效果。
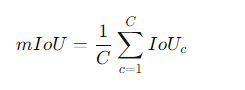
优点:提供了整体分割性能的概述。
缺点:类别不平衡可能影响mIoU,尤其是当某些类别非常少时,mIoU可能会受到很大影响。
5. 频率加权交并比(Frequency Weighted IoU, FWIoU)
定义:频率加权交并比是对每个类别的IoU按其像素数(频率)加权平均。该指标能够在类别不平衡的情况下更好地反映模型的性能。
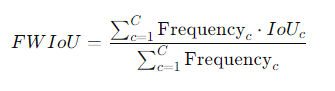
![]()
优点:能更公平地考虑类别频率,避免少数类别对IoU的影响。
缺点:与mIoU类似,依赖于类别分布,可能无法反映小类别的性能。
6. Dice系数(Dice Coefficient, F1 Score)
定义:Dice系数是衡量预测与实际重合程度的一个常用指标,特别适用于不均衡数据集。它是精准率和召回率的调和平均数。
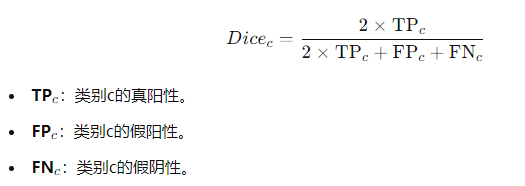
优点:对类别不平衡问题敏感,能够全面评估模型性能。
缺点:与IoU相比,Dice系数对类别间的错分容忍度稍低。

(忽略了边缘,就是没有像素值为255的情况)
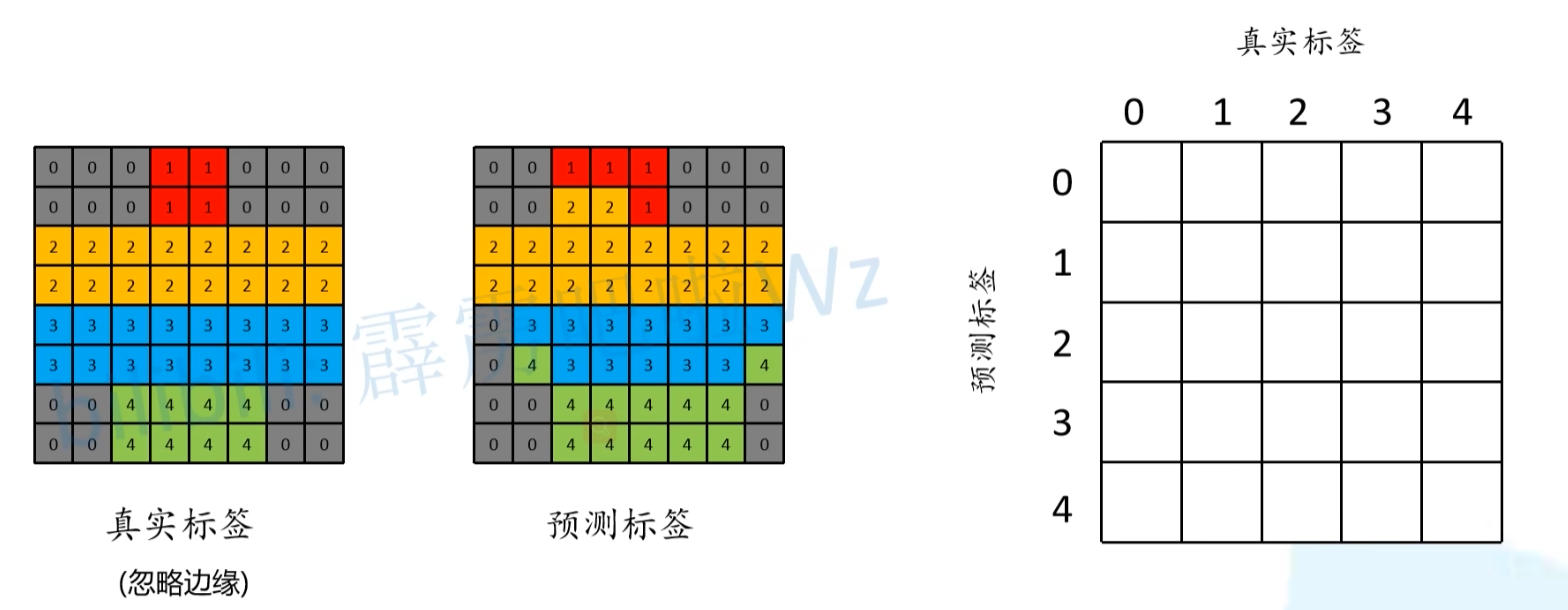
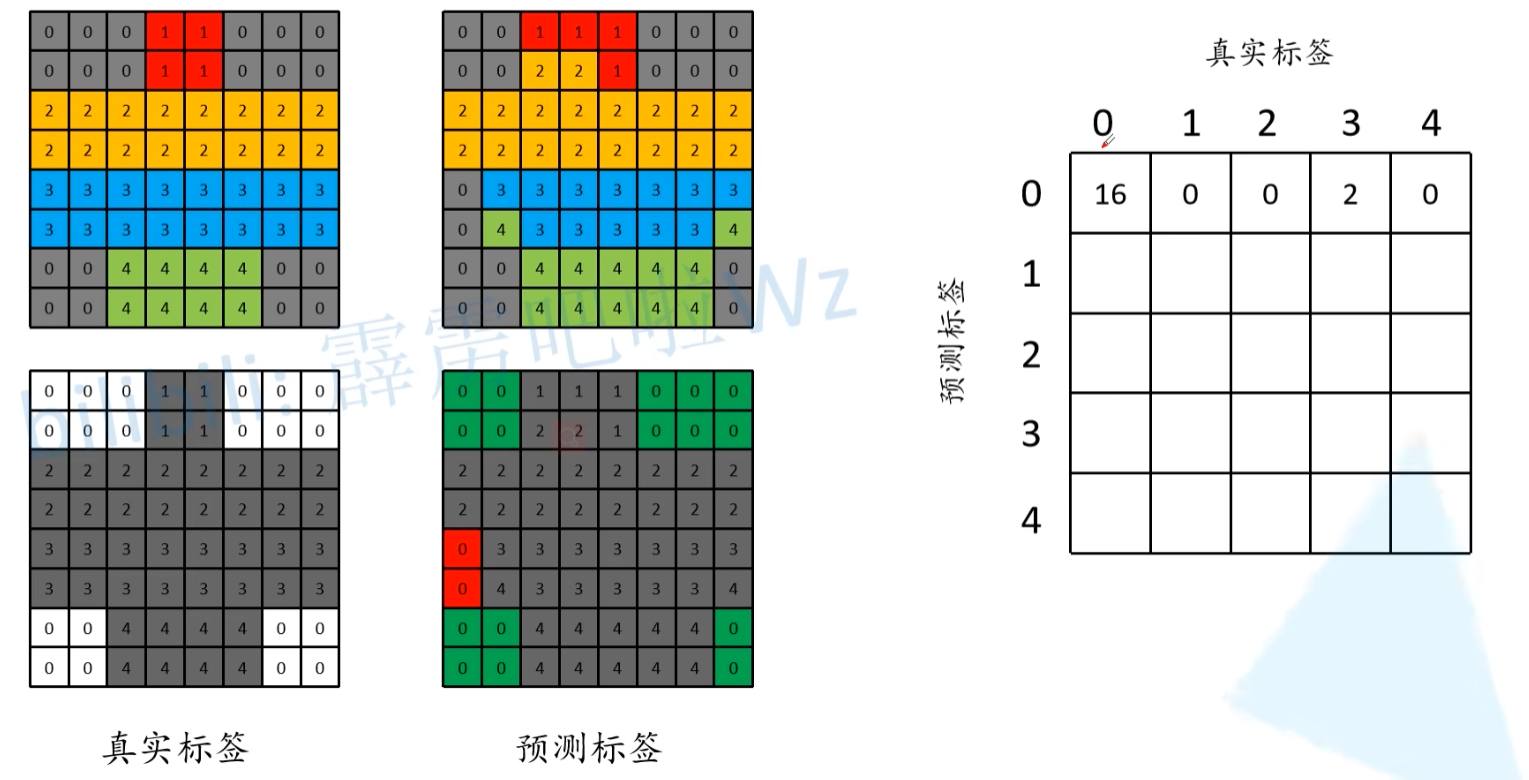

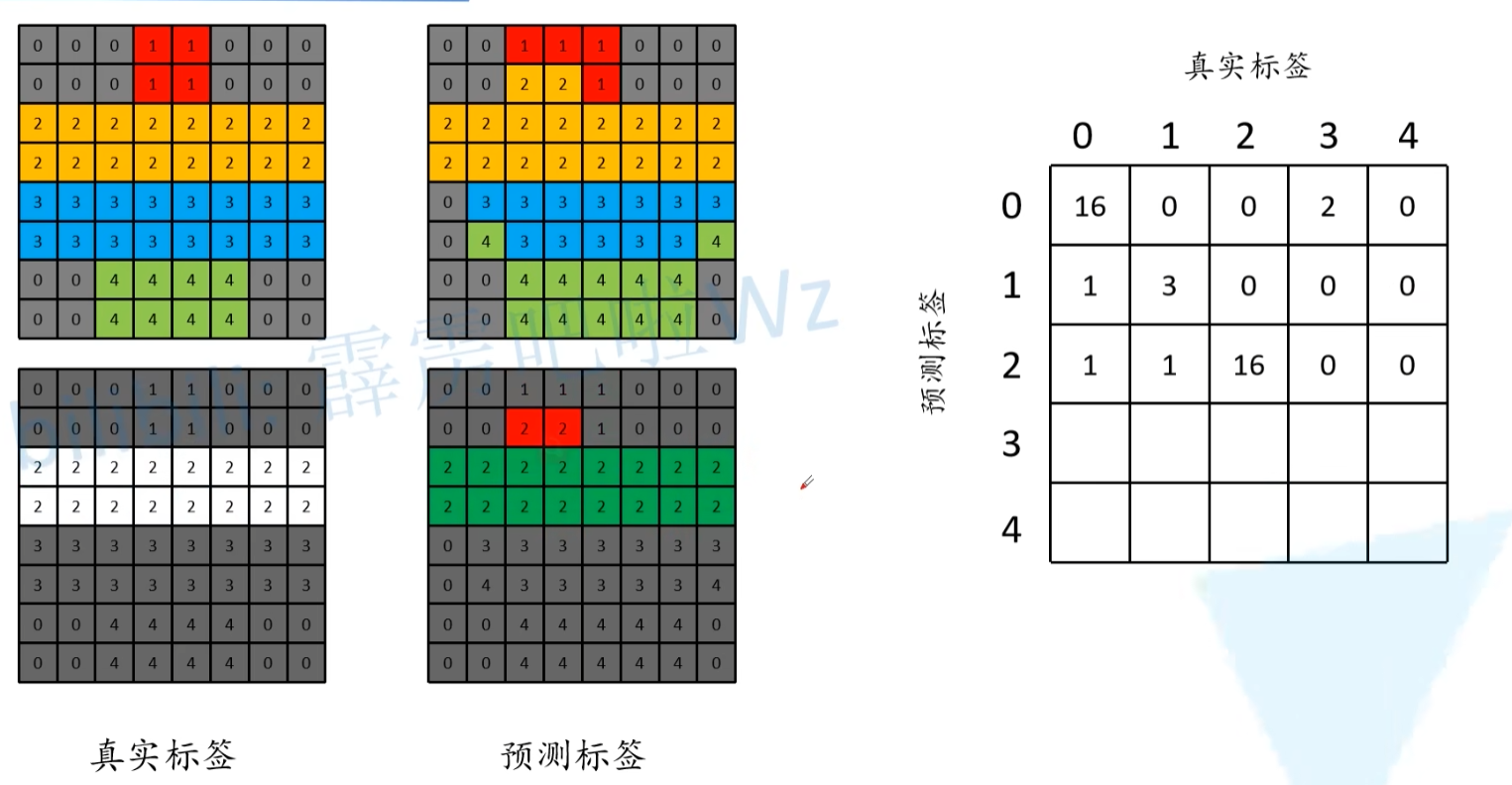
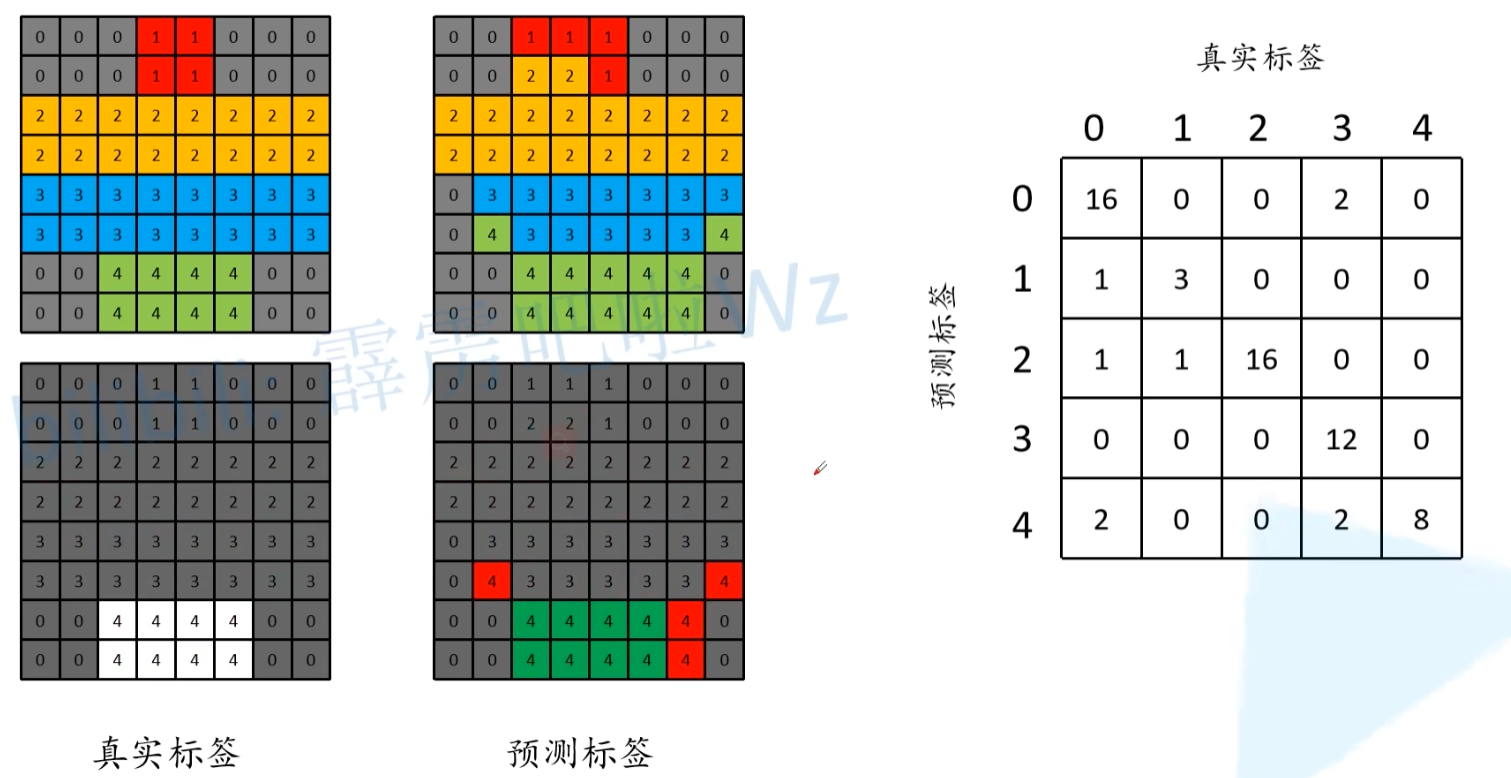
global_accuracy中,分子就是我们对角线上预测正确的像素(包括背景),分母就是全部像素个数。

分类准确率,分母是每一类的像素总个数(真实标签列),分子是每一类预测正确的像素个数(对角线元素)
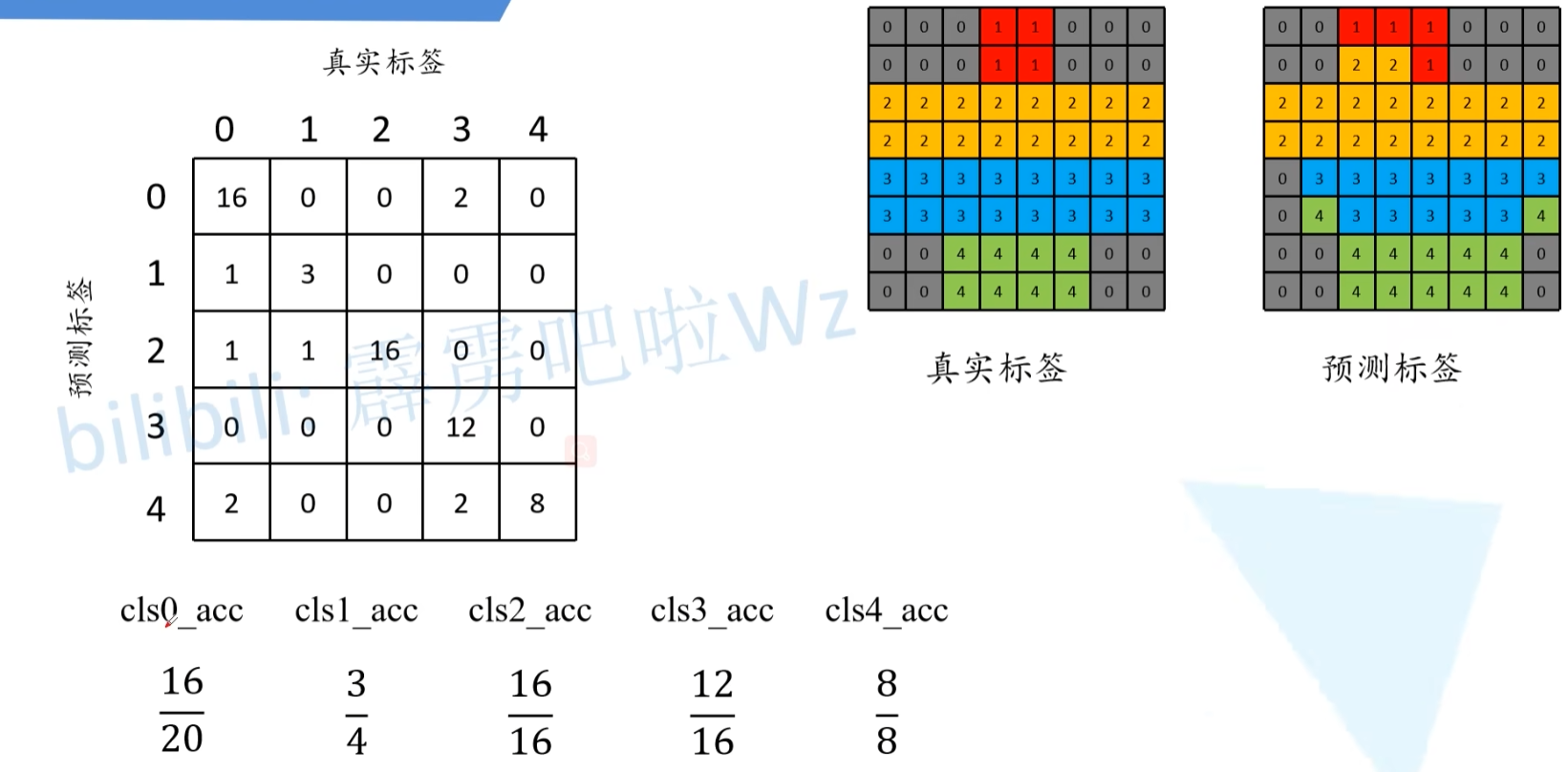
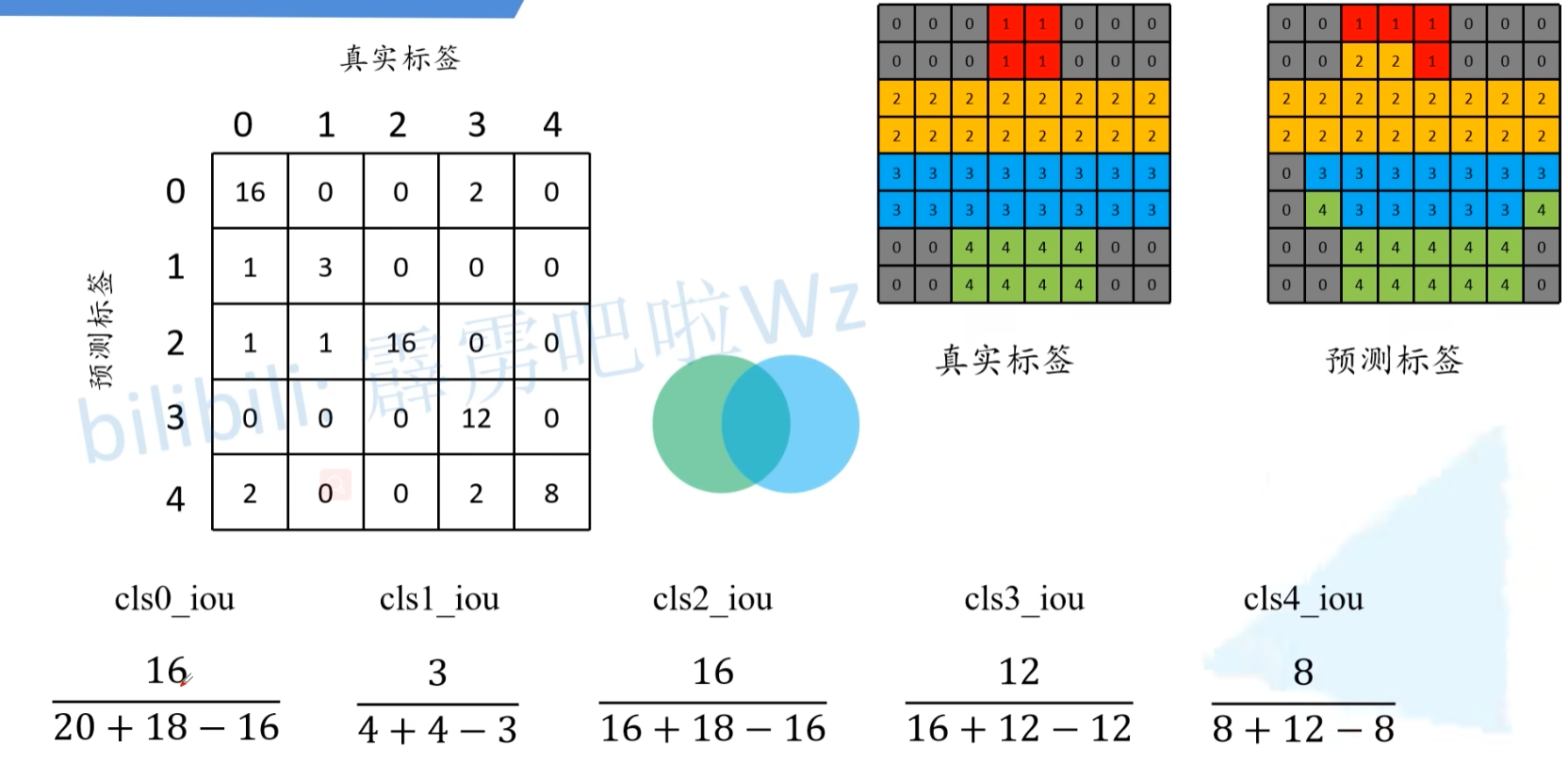
分类IOU,分母是“并”,就是每一类本来的像素的个数+(预测像素个数-预测对的像素个数)。分子是“交”,就是预测对的像素个数。
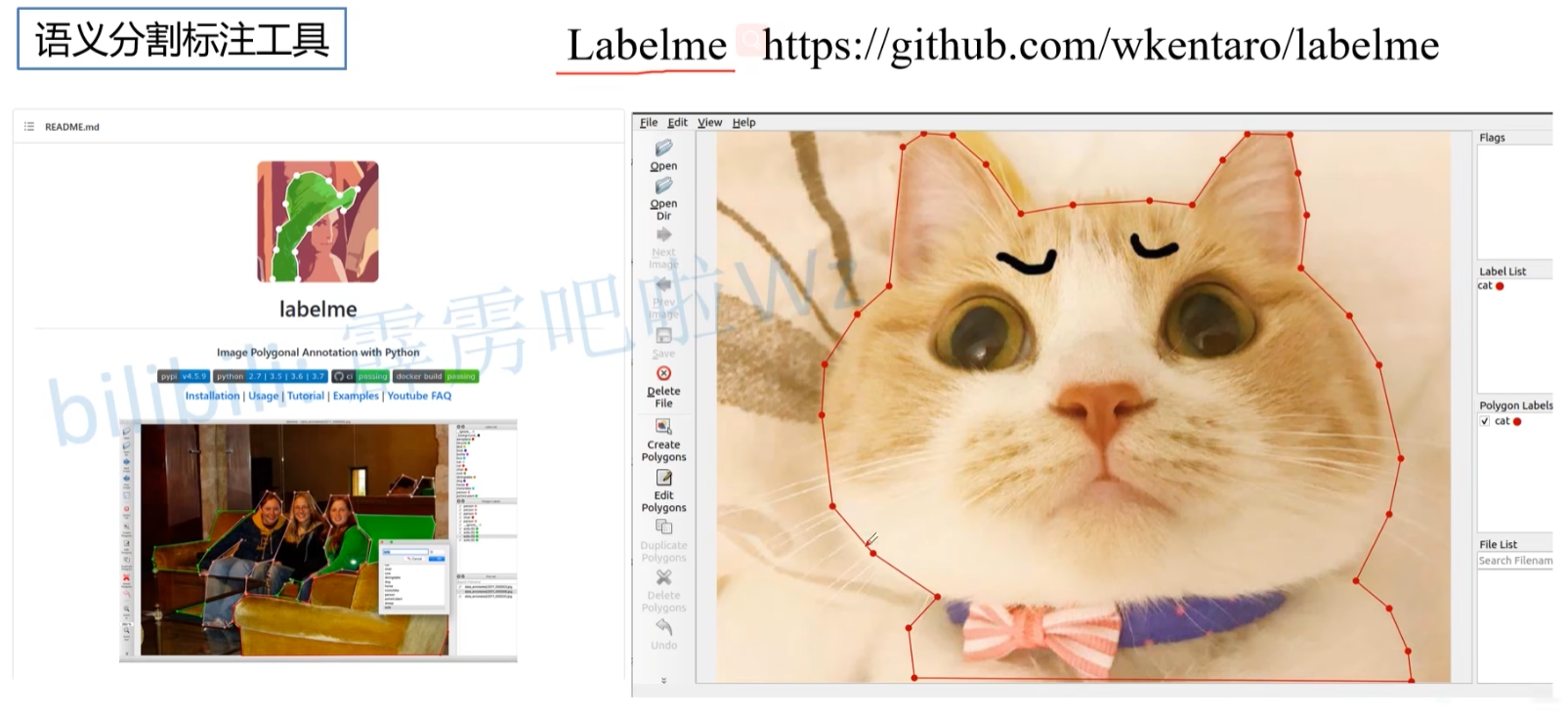
5. 语义分割标签标注工具
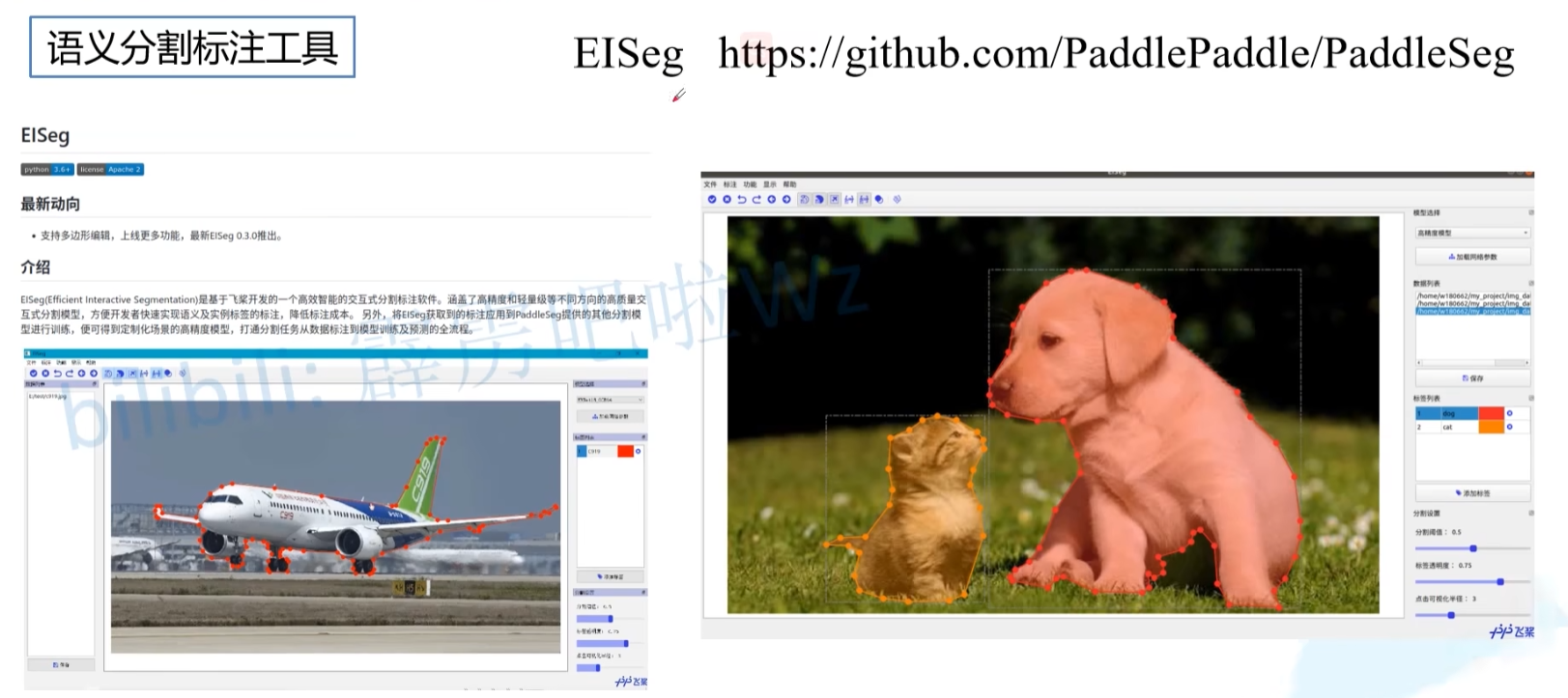
1. Labelme
- 简介:Labelme 是一个开源的图像标注工具,由麻省理工学院(MIT)开发。它支持多种标注格式,包括多边形标注、矩形标注、圆形标注等,适用于语义分割任务。
- 特点:
- 支持多种标注方式,如多边形、多种形状的区域标注。
- 标注数据可导出为JSON格式,易于与其他机器学习工具集成。
- 具有简单的图形界面,用户友好。
- 适用场景:适用于小型数据集的标注工作,也适合学术研究和快速原型开发。
- 官网:Labelme
2. CVAT (Computer Vision Annotation Tool)
- 简介:CVAT 是由英特尔开源的一个专业标注工具,特别适用于计算机视觉任务,包括图像分类、目标检测、语义分割等。
- 特点:
- 支持多种标注任务,包括语义分割、目标检测、图像分类等。
- 可以使用多边形、矩形、点标注等方式进行标注。
- 提供团队协作功能,支持多人共同标注,适合大规模数据集的标注工作。
- 支持多种数据格式(如COCO、Pascal VOC、YOLO等)导入和导出。
- 可通过Web界面进行标注,便于在线操作。
- 适用场景:适合大规模数据集的标注,特别是在团队协作下使用。
- 官网:CVAT
3. LabelBox
- 简介:LabelBox 是一个商业化的图像和视频标注平台,提供了灵活的标注工具,支持语义分割、目标检测等多种任务。
- 特点:
- 提供了强大的标签管理和审核功能,适合企业级项目。
- 支持语义分割、目标检测等多种标注类型。
- 提供协作和项目管理功能,适合大规模团队合作。
- 支持与机器学习平台(如TensorFlow、PyTorch等)无缝集成。
- 适用场景:适用于商业项目和企业级的标注需求,支持大规模数据集。
- 官网:LabelBox
4. VGG Image Annotator (VIA)
- 简介:VGG Image Annotator 是由牛津大学视觉几何组(VGG)开发的开源标注工具,支持图像标注和视频标注。
- 特点:
- 简单易用,适合快速标注。
- 支持多边形、矩形、圆形等标注方式。
- 支持标注数据的导入和导出,支持JSON格式。
- 无需安装,完全基于Web浏览器,可以在任何现代浏览器中运行。
- 适用场景:适合小型项目或个人项目,快速标注小规模数据集。
- 官网:VIA
5. Supervisely
- 简介:Supervisely 是一款功能强大的人工智能数据标注平台,支持图像、视频、3D数据的标注。它提供了专为语义分割设计的标签标注工具。
- 特点:
- 支持多种标注任务,包括语义分割、目标检测、姿态估计等。
- 强大的标注工具,支持多边形、矩形、圆形等多种标注方式。
- 提供实时预览和标签管理功能,支持图像的快速标注。
- 集成了数据集管理、模型训练、模型评估等功能,方便一站式操作。
- 适用场景:适合需要高级功能的团队或公司,尤其是在大规模数据集的标注和训练过程中。
- 官网:Supervisely
6. MakeSense
- 简介:MakeSense 是一个免费的Web应用,旨在提供简单而高效的标注工具,支持语义分割、目标检测等任务。
- 特点:
- 免费使用,易于上手,界面简单直观。
- 支持多种标注格式,包括VOC、COCO、YOLO等。
- 具备团队协作功能,可以多人共同参与标注。
- 支持导入和导出标注数据,支持常见的格式。
- 适用场景:适合个人、小团队或快速项目标注,适合小规模数据集。
- 官网:MakeSense
7. RectLabel
- 简介:RectLabel 是一款Mac平台上的图像标注工具,支持目标检测、语义分割等任务的标注。
- 特点:
- 适用于Mac用户,支持高效的图像标注。
- 支持矩形、多边形、圆形等多种标注工具。
- 提供视频帧标注功能,适合视频数据的标注。
- 支持COCO、Pascal VOC等标注格式。
- 适用场景:适合Mac用户进行小规模项目的标注,支持目标检测、语义分割等任务。
- 官网:RectLabel
8. Sly (Sly.ai)
- 简介:Sly 是一个灵活且协作性强的图像标注平台,适合处理大规模数据集的标注。
- 特点:
- 强大的标注管理和版本控制功能,适合团队协作。
- 提供多种标注工具,支持语义分割、目标检测、实例分割等任务。
- 支持导入和导出多种格式,适应不同的数据格式需求。
- 提供标注质量控制和审核机制。
- 适用场景:适合大规模数据集和团队协作,适用于需要高效标注和质量控制的项目。
- 官网:Sly
9. EISEG