在 AMD GPU 上构建深度学习推荐模型
Deep Learning Recommendation Models on AMD GPUs — ROCm Blogs

2024 年 6 月 28 日 发布者 Phillip Dang
在这篇博客中,我们将演示如何在支持 ROCm 的 AMD GPU 上使用 PyTorch 构建一个简单的深度学习推荐模型 (DLRM)。
简介
DLRM 位于推荐系统和深度学习的交汇处,利用神经网络在庞大的数据集中预测用户与物品的交互。它是一种强大的工具,在各种领域中个性化推荐,从电子商务到内容流媒体平台。
正如 《深度学习推荐模型:个性化和推荐系统》 中讨论的那样,DLRM 具有几个组件:
-
多个嵌入表将稀疏特征(每个特征一个)映射到密集表示。
-
一个底部多层感知器 (MLP),将密集特征转换为与嵌入向量长度相同的密集表示。
-
一个特征交互层,计算所有嵌入向量和处理后的密集特征之间的点积。
-
一个顶部多层感知器 (MLP),输入交互特征与原始处理后的密集特征串联,并输出对数 (logits)。
以下图表总结了 DLRM 的架构,来自 《深度学习推荐模型:深度探究》。
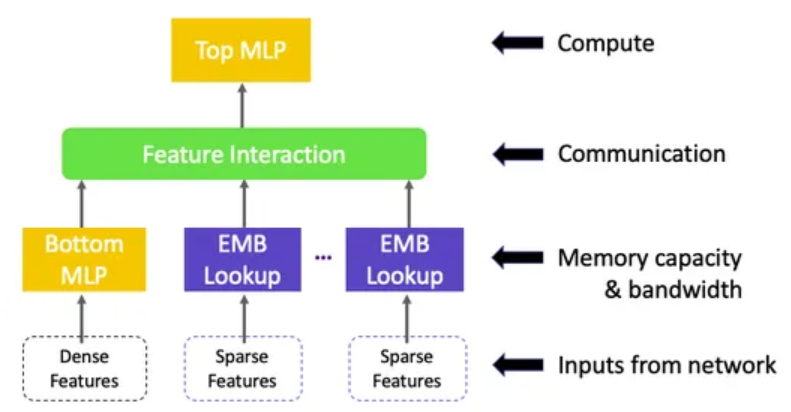
DLRM 与其他深度学习网络的区别之一是它“在结构上以一种模仿因子分解机的方式特定地交互嵌入,通过只考虑最终 MLP 中成对嵌入之间点积产生的交叉项来显著减少模型的维度”[参考文献]。这使 DLRM 相比于其他网络如 Deep 和 Cross 大幅减少了模型的维度。
本博客强调简单性。我们将通过一个简单的数据集来预测展示广告的点击率,构建一个基本的 DLRM 架构,并为理解其内部工作原理提供坚实的基础。鼓励用户调整和扩展模型,探索更多复杂性,以适应他们的具体需求。
前提条件
-
ROCm
-
PyTorch
-
Linux 操作系统
-
An AMD GPU
确保系统识别到你的 GPU:
! rocm-smi --showproductname
================= ROCm System Management Interface ================ ========================= Product Info ============================ GPU[0] : Card series: Instinct MI210 GPU[0] : Card model: 0x0c34 GPU[0] : Card vendor: Advanced Micro Devices, Inc. [AMD/ATI] GPU[0] : Card SKU: D67301 =================================================================== ===================== End of ROCm SMI Log =========================
检查是否安装了正确版本的 ROCm.
! apt show rocm-core -a
Package: rocm-core Version: 5.7.0.50700-63~22.04 Priority: optional Section: devel Maintainer: ROCm Dev Support <rocm-dev.support@amd.com> Installed-Size: 94.2 kB Homepage: https://github.com/RadeonOpenCompute/ROCm Download-Size: 7030 B APT-Manual-Installed: no APT-Sources: http://repo.radeon.com/rocm/apt/5.7 jammy/main amd64 Packages Description: Radeon Open Compute (ROCm) Runtime software stack
确保 PyTorch 也识别到 GPU:
import torch
print(f"number of GPUs: {torch.cuda.device_count()}")
print([torch.cuda.get_device_name(i) for i in range(torch.cuda.device_count())])
number of GPUs: 1 ['AMD Radeon Graphics']
数据集
以下内容是基于原始 DLRM 论文 中介绍的,我们将使用 Criteo 数据集 来预测广告点击率 (CTR)。我们将预测用户在访问页面时点击给定广告的概率。
数据字段包含以下内容:
-
Label - 目标变量,指示广告是否被点击(1)或未被点击(0)。
-
I1-I13 - 一共13列整数特征(主要是计数特征)。
-
C1-C26 - 一共26列分类特征。这些特征的值已被哈希成32位以进行匿名化处理。
这些特征的具体语义未被披露,这在匿名化数据集中是常见的做法,以保护隐私和专有信息。为方便起见,我们已经下载了数据并将其包含在我们的代码库中。让我们安装和导入所需的库,并加载数据集。
! pip install --upgrade pip ! pip install --upgrade pandas ! pip install --upgrade scikit-learn
import torch import torch.nn as nn import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, MinMaxScaler from torch.utils.data import DataLoader, TensorDataset from tqdm import tqdm
columns = ["label", *(f"I{i}" for i in range(1, 14)), *(f"C{i}" for i in range(1, 27))]
df = pd.read_csv("../data/dac_sample.txt", sep="\t", names=columns
).fillna(0)
预处理
我们的预处理步骤包括对稀疏和类别特征进行序数编码,并对密集和数值特征进行最小-最大缩放。
sparse_cols = ["C" + str(i) for i in range(1, 27)] dense_cols = ["I" + str(i) for i in range(1, 14)]data = df[sparse_cols + dense_cols] data = data.astype(str) for feat in sparse_cols:lbe = LabelEncoder()data[feat] = lbe.fit_transform(data[feat]) mms = MinMaxScaler(feature_range=(0, 1)) data[dense_cols] = mms.fit_transform(data[dense_cols]) print(data.sample(5))
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 ... I4 I5 I6 I7 I8 I9 I10 I11 I12 I13 33714 8 289 12798 19697 23 10 2279 86 2 2505 ... 0.000000 0.001729 0.013812 0.000000 0.000000 0.001027 0.000000 0.000000 0.0 0.000000 41376 8 21 6057 20081 23 5 6059 27 2 2505 ... 0.011990 0.002585 0.008840 0.000795 0.001283 0.020220 0.000000 0.028846 0.0 0.000762 21202 8 62 23836 24608 41 5 2305 8 2 2933 ... 0.004796 0.000136 0.002701 0.000568 0.005987 0.003633 0.166667 0.019231 0.0 0.003355 89866 8 113 42768 7421 23 11 827 48 2 2505 ... 0.002398 0.000118 0.000491 0.000114 0.002138 0.002133 0.166667 0.009615 0.0 0.000152 19993 327 78 31306 11660 23 0 6837 27 2 8905 ... 0.007194 0.001740 0.001105 0.002612 0.001497 0.002448 0.000000 0.038462 0.0 0.000457
我们还移除了一些类别数过多的稀疏特征,在这个数据集中大约有10,000个类别。按照Kaggle的社区讨论中的推荐,当稀疏特征的类别数超过了10,000时,模型性能的提升是微乎其微的,而且这只会不必要地增加参数的数量。
# 获取每个分类特征的类别数 num_categories = [len(data[c].unique()) for c in sparse_cols]# 只保留类别数少于10K的分类特征 indices_to_keep = [i for i, num in enumerate(num_categories) if num <= 10000] num_categories_kept = [num_categories[i] for i in indices_to_keep] sparse_cols_kept = [sparse_cols[i] for i in indices_to_keep]
最后,我们将数据拆分为训练集和测试集,然后将它们转换成 torch 张量并创建相应的数据加载器。
device = "cuda" if torch.cuda.is_available() else "cpu" batch_size = 128# 拆分数据集 X_train, X_test, y_train, y_test = train_test_split(data, df["label"], test_size=0.2, random_state=42 )# 转换成张量 # 训练集 X_train_sparse = torch.tensor(X_train[sparse_cols_kept].values, dtype=torch.long).to(device ) X_train_dense = torch.tensor(X_train[dense_cols].values, dtype=torch.float).to(device) y_train = torch.tensor(y_train.values, dtype=torch.float).unsqueeze(1).to(device)# 测试集 X_test_sparse = torch.tensor(X_test[sparse_cols_kept].values, dtype=torch.long).to(device) X_test_dense = torch.tensor(X_test[dense_cols].values, dtype=torch.float).to(device) y_test = torch.tensor(y_test.values, dtype=torch.float).unsqueeze(1).to(device)# 创建训练数据的DataLoader train_dataset = TensorDataset(X_train_sparse, X_train_dense, y_train) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 创建测试数据的DataLoader test_dataset = TensorDataset(X_test_sparse, X_test_dense, y_test) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
建模
让我们为我们的DLRM设置一些超参数:
device = "cuda" if torch.cuda.is_available() else "cpu" num_epochs = 10 lr = 3e-4 batch_size = 128 hidden_size = 32 embd_dim = 16
现在我们准备创建我们的DLRM。为了简化,底部和顶部的MLP将是一个简单的3层(输入、隐藏、输出)神经网络,并使用ReLU激活函数。
class FeatureInteraction(nn.Module):def __init__(self):super(FeatureInteraction, self).__init__()def forward(self, x):feature_dim = x.shape[1]concat_features = x.view(-1, feature_dim, 1)dot_products = torch.matmul(concat_features, concat_features.transpose(1, 2))ones = torch.ones_like(dot_products)mask = torch.triu(ones)out_dim = feature_dim * (feature_dim + 1) // 2flat_result = dot_products[mask.bool()]reshape_result = flat_result.view(-1, out_dim)return reshape_resultclass DLRM(torch.nn.Module):def __init__(self,embd_dim,num_categories,num_dense_feature,hidden_size,):super(DLRM, self).__init__()# 为每个分类特征创建具有相同嵌入维度的嵌入self.embeddings = nn.ModuleList([nn.Embedding(num_cat, embd_dim) for num_cat in num_categories])self.feat_interaction = FeatureInteraction()self.bottom_mlp = nn.Sequential(nn.Linear(in_features=num_dense_feature, out_features=hidden_size),nn.ReLU(),nn.Linear(hidden_size, embd_dim),)num_feat = (len(num_categories) * embd_dim + embd_dim) # 包括分类特征和数值特征num_feat_interact = num_feat * (num_feat + 1) // 2 # interaction featurestop_mlp_in = (num_feat_interact + embd_dim) # 交互特征与数值特征连接self.top_mlp = nn.Sequential(nn.Linear(in_features=top_mlp_in, out_features=hidden_size),nn.ReLU(),nn.Linear(hidden_size, 1),)def forward(self, x_cat, x_num):B = x_cat.shape[0]num_sparse_feat = x_cat.shape[1]# 查找分类特征的嵌入embed_x = torch.concat([self.embeddings[i](x_cat[:, i]).unsqueeze(1)for i in range(num_sparse_feat)]) # B, num_sparse_feat, embedding dimembed_x = embed_x.view(B, -1) # B, num_sparse_feat * embedding dim# 获取底部的数值特征dense_x = self.bottom_mlp(x_num) # B, embedding dim# 与嵌入连接x = torch.concat([embed_x, dense_x], dim=-1) # B, (num_sparse_feat+1) * embedding dim# 获取二阶交互特征x = self.feat_interaction(x) # B, n*(n+1) // 2# 与数值特征结合x = torch.concat([x, dense_x], dim=-1)# 通过顶部MLPx = self.top_mlp(x) # B, 1return x
让我们实例化我们的模型,并定义我们的损失函数和优化器。
# 实例化模型、损失函数和优化器
model = DLRM(embd_dim=embd_dim,num_categories=num_categories_kept,num_dense_feature=len(dense_cols),hidden_size=hidden_size,
)
model.to(device)
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)print(f"running on {device}")
print(sum(p.numel() for p in model.parameters()) / 1e6, "M parameters")
print(model)
输出示例:
running on cuda 2.195553 M parameters DLRM((embeddings): ModuleList((0): Embedding(541, 16)(1): Embedding(497, 16)(2): Embedding(145, 16)(3): Embedding(12, 16)(4): Embedding(7623, 16)(5): Embedding(257, 16)(6): Embedding(3, 16)(7): Embedding(3799, 16)(8): Embedding(2796, 16)(9): Embedding(26, 16)(10): Embedding(5238, 16)(11): Embedding(10, 16)(12): Embedding(2548, 16)(13): Embedding(1303, 16)(14): Embedding(4, 16)(15): Embedding(11, 16)(16): Embedding(14, 16)(17): Embedding(51, 16)(18): Embedding(9527, 16))(feat_interaction): FeatureInteraction()(bottom_mlp): Sequential((0): Linear(in_features=13, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=16, bias=True))(top_mlp): Sequential((0): Linear(in_features=51376, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=1, bias=True)) )
训练
接下来,让我们编写两个工具函数,一个用于模型训练,一个用于在训练集和测试集上的模型评估。
def train_one_epoch():model.train()for i, (x_sparse, x_dense, y) in enumerate(tqdm(train_loader)):x_sparse = x_sparse.to(device)x_dense = x_dense.to(device)y = y.to(device)optimizer.zero_grad()logits = model(x_sparse, x_dense)loss = criterion(logits, y)loss.backward()optimizer.step()
def evaluate(dataloader, dataname):model.eval()total_samples = 0total_loss = 0total_correct = 0with torch.no_grad():for i, (x_sparse, x_dense, y) in enumerate(tqdm(dataloader)):x_sparse = x_sparse.to(device)x_dense = x_dense.to(device)y = y.to(device)logits = model(x_sparse, x_dense)probs = torch.sigmoid(logits)predictions = (probs > 0.5).long()loss = criterion(logits, y)total_loss += loss.item() * y.shape[0]total_correct += (predictions == y).sum().item()total_samples += y.shape[0]avg_loss = total_loss / total_samplesaccuracy = total_correct / total_samples * 100print(f"{dataname} accuracy = {accuracy:0.2f}%, {dataname} avg loss = {avg_loss:.6f}")return accuracy, avg_loss
现在我们准备好训练我们的模型。
for epoch in range(num_epochs):print(f"epoch {epoch+1}")train_one_epoch()evaluate(train_loader, "train")evaluate(test_loader, "test")print()
输出结果: epoch 1 100%|██████████| 625/625 [00:06<00:00, 92.18it/s] 100%|██████████| 625/625 [00:01<00:00, 351.70it/s] train accuracy = 77.37%, train avg loss = 0.535811 100%|██████████| 157/157 [00:00<00:00, 354.67it/s] test accuracy = 77.14%, test avg loss = 0.538407...epoch 10 100%|██████████| 625/625 [00:06<00:00, 98.00it/s] 100%|██████████| 625/625 [00:01<00:00, 351.16it/s] train accuracy = 77.48%, train avg loss = 0.498510 100%|██████████| 157/157 [00:00<00:00, 352.91it/s] test accuracy = 77.14%, test avg loss = 0.501544
推理
现在,我们已经有了一个DLRM模型,可以预测给定用户/广告组合的点击概率。由于Criteo数据集的特征语义未公开,我们无法重建代表真实用户或广告的有意义特征向量。出于说明目的,我们假设特征向量的一部分代表用户,其余的代表广告。特别是,为了简单起见,我们假设所有整数特征代表用户,所有分类特征代表广告。
假设在投放广告时,我们检索到了10个广告候选项。DLRM的任务是选择最佳广告候选项向用户展示。为了解释目的,我们假定检索到的广告候选项来自原始数据集的前10行,而用户是第一行中的用户。首先,我们创建一个数据加载器,将用户和广告特征组合起来,以供模型使用。
# 假设我们使用数据集的前10行作为广告候选项 num_ads = 10 df_c = pd.DataFrame(data.iloc[0:num_ads]) # 获取广告候选项特征 df_ads = df_c[df_c.columns[26:39]] # 获取第一行的用户特征 df_user = df_c[df_c.columns[0:26]].iloc[0:1] # 将用户特征复制到所有广告候选项行 df_user_rep = df_user for i in range(num_ads-1): df_user_rep = pd.concat([df_user_rep, df_user], ignore_index=True, sort=False) df_candidates = pd.concat([df_user_rep, df_ads], axis=1)# 将特征向量转换为张量 X_inf_sparse = torch.tensor(df_candidates[sparse_cols_kept].values, dtype=torch.long).to(device) X_inf_dense = torch.tensor(df_candidates[dense_cols].values, dtype=torch.float).to(device)# 创建用于推理的数据加载器 y_dummy = torch.tensor([0]*num_ads, dtype=torch.float).unsqueeze(1).to(device) inf_dataset = TensorDataset(X_inf_sparse, X_inf_dense, y_dummy) inf_loader = DataLoader(inf_dataset, batch_size=num_ads, shuffle=True)
接下来,我们创建一个函数,该函数返回具有最高点击概率的张量的索引。
def recommend():with torch.no_grad():for i, (x_sparse, x_dense, y) in enumerate(tqdm(inf_loader)):x_sparse = x_sparse.to(device)x_dense = x_dense.to(device)logits = model(x_sparse, x_dense)probs = torch.sigmoid(logits)print(probs)return torch.max(probs, dim=0).indices[0].item()
调用这个函数将得到最佳广告候选项的索引。
print('Best ad candidate is ad', recommend())
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 315.29it/s] tensor([[0.1380],[0.2414],[0.3493],[0.3500],[0.1807],[0.3009],[0.2203],[0.3639],[0.1890],[0.3702]], device='cuda:0') Best ad candidate is ad 9
我们鼓励用户进一步探索优化和超参数调优,以提高模型性能。例如,可以尝试在底部和顶部MLP中添加更多层和隐藏单元,增加嵌入维度,或者包括正则化如dropout以防止过拟合。
讨论
在这篇博客中,我们开发了一个仅用于教育目的的小规模模型。然而,在实际应用中,模型的规模要大得多。因此,高效地并行化这些模型以应对真实世界中的挑战是至关重要的。
对于DLRM模型,大多数模型参数来自embedding表,这使得在实际应用中很难实现数据并行性,因为我们需要在每个设备上复制这些表。因此,我们需要高效地将模型分布到多个设备上以解决内存限制的问题。另一方面,底层和顶层的MLP(多层感知器)参数较少,我们可以应用数据并行性,在不同设备上同时处理多个样本。
关于如何高效地实现DLRM模型的数据并行和模型并行的更多细节,请参阅原始论文《paper》以及Meta发布的这个开源库《repo》。