【人工智能】揭秘可解释性AI(XAI):从原理到实战的终极指南
文章目录
- 开篇:AI的黑箱时代,你准备好揭开真相了吗?🔍
- 什么是可解释性AI(XAI)?
- XAI的定义
- XAI的分类
- 可解释性AI的重要性与价值
- 建立用户信任
- 遵循法规和伦理
- 发现和纠正模型偏见
- 提高模型性能
- 促进跨领域合作
- 可解释性AI的核心挑战
- 1. 模型复杂度
- 2. 精度与可解释性的权衡
- 3. 缺乏统一的评估标准
- 4. 用户理解能力差异
- 5. 计算成本
- 可解释性AI的评估与度量方法
- 1. 人类理解度
- 2. 模型简化度
- 3. 决策一致性
- 4. 可用性和实用性
- 5. 解释的准确性
- 可解释性AI的主要技术与方法
- 1. 本地解释方法
- 2. 全局解释方法
- 3. 本身可解释的模型
- 4. 后置解释方法
- 实战教程:如何实现可解释性AI
- 环境准备
- 1. 数据准备
- 2. 模型训练
- 3. 模型评估
- 4. 使用SHAP进行解释
- 5. 结果分析
- 更多文献
- 结语
开篇:AI的黑箱时代,你准备好揭开真相了吗?🔍
在人工智能(AI)迅猛发展的今天,AI系统已悄然渗透到我们生活的方方面面——从医疗诊断到金融风控,从自动驾驶到智能客服。然而,伴随着AI能力的提升,另一个问题也逐渐浮出水面:AI决策过程的透明度。当一个复杂的深度学习模型给出一个决策结果时,我们往往无法理解其背后的逻辑。这不仅影响了用户对AI的信任,还带来了伦理和法律上的挑战。
这就是可解释性AI(Explainable AI,简称XAI)登场的原因。XAI旨在提高AI系统的透明度和可理解性,使人们能够理解AI的决策过程和原理。本文将深入探讨可解释性AI的定义、挑战、评估方法及其在各个领域的应用,并通过实际案例和教程,帮助你全面掌握这一前沿技术。
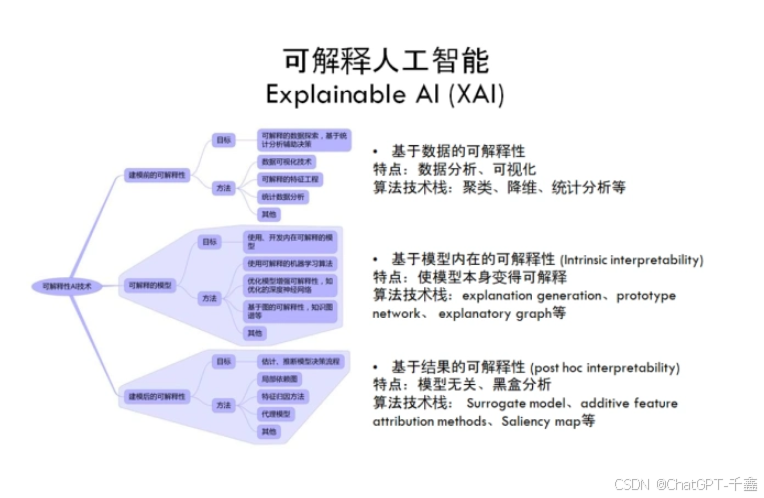
什么是可解释性AI(XAI)?
可解释性AI(XAI),顾名思义,是指通过技术手段使AI模型的决策过程对人类可理解的技术。它不仅关注模型的准确性,更强调模型的透明度和可理解性。
XAI的定义
可解释性AI旨在揭示AI模型如何得出结论,以及这些结论背后的具体原因。例如,在医疗诊断中,XAI不仅提供病症预测,还解释为什么该模型认为某患者患有某种疾病。这种透明度有助于用户建立对AI的信任,并确保AI决策的公平性和可靠性。
XAI的分类
XAI方法大致可以分为以下几类:
- 本地解释(Local Explanations):侧重于解释单个决策或预测结果。例如,LIME(Local Interpretable Model-agnostic Explanations)。
- 全局解释(Global Explanations):旨在理解整个模型的行为和特征重要性。例如,决策树模型本身就是一种全局解释模型。
- 模型内解释(Intrinsically Interpretable Models):设计时就是为了易于解释,如线性回归、决策树等。
- 后置解释(Post-hoc Explanations):在模型训练完毕后,通过附加的解释模型来解释AI决策,如SHAP值。
可解释性AI的重要性与价值
随着AI在各行各业的广泛应用,可解释性AI的重要性也愈发凸显。其主要价值体现在以下几个方面:
建立用户信任
当用户了解AI决策的依据和过程时,他们更愿意信任和接受AI的建议。这在医疗、金融等高风险领域尤为重要。
遵循法规和伦理
许多行业法规要求AI系统具有可解释性,以确保决策过程的透明和公平。例如,欧盟的《通用数据保护条例》(GDPR)就规定了“自动化决策”的解释权。
发现和纠正模型偏见
可解释性AI能够帮助开发者发现模型潜在的偏见和歧视,从而进行调整和优化,提升模型的公正性。
提高模型性能
通过理解模型决策过程中的不足,开发者可以针对性地优化模型结构和算法,进而提升整体性能。
促进跨领域合作
可解释性使不同领域的专业人士能够理解和应用AI技术,推动跨学科的创新和发展。
可解释性AI的核心挑战
尽管可解释性AI具有诸多优势,但在实际应用中仍面临不少挑战:
1. 模型复杂度
现代AI模型,尤其是深度学习模型,以其庞大的参数量和复杂的结构著称。这种复杂性使得解释其决策过程变得极为困难。例如,深度神经网络中的每一层都在不断抽象和提取特征,使得从输入到输出的路径难以追踪和理解。
2. 精度与可解释性的权衡
通常,高精度的模型(如深度神经网络)往往难以解释,而易于解释的模型(如线性回归、决策树)在复杂任务上的表现可能不尽如人意。这种精度与可解释性的权衡在实际应用中是一个需要仔细权衡的问题。
3. 缺乏统一的评估标准
目前,关于可解释性AI的评估方法还不统一。不同的应用场景和需求可能需要不同的评估指标,使得比较和选择合适的XAI方法变得复杂。
4. 用户理解能力差异
不同用户对解释的需求和理解能力不同。一些专家可能需要详细的技术解释,而普通用户可能只需要简单明了的结果。这种多样性增加了设计统一可解释性解决方案的难度。
5. 计算成本
某些XAI方法需要额外的计算资源和时间,这在实时应用中可能不可行。例如,生成全局解释可能需要对大量数据进行分析,导致高昂的计算成本。
可解释性AI的评估与度量方法
评估可解释性AI的效果需要多维度的考量,包括人类理解度、模型简化度和决策一致性等方面。
1. 人类理解度
这是评估XAI效果的最直接方式。通常通过问卷调查、用户测试或专家评估等方法,了解用户是否能够理解模型的决策过程。例如,在医疗诊断中,可以邀请医生评估XAI提供的解释是否有助于理解诊断结果。
2. 模型简化度
通过评估模型的复杂度来衡量其可解释性。常用的指标包括模型的参数数量、层级结构和计算复杂度。例如,一个拥有较少参数和浅层结构的模型通常更易于解释。
3. 决策一致性
可解释性AI应该能够提供一致的决策解释,即对于相同的输入,模型应给出相同的解释。这要求解释方法具有稳定性和可靠性,避免因小的输入变化导致解释结果的大幅波动。
4. 可用性和实用性
评估XAI方法在实际应用中的可用性和实用性。例如,解释结果是否能够被用户轻松理解和应用,是否能够在实际场景中帮助用户做出更好的决策。
5. 解释的准确性
衡量解释是否准确反映了模型的真实决策过程。这可以通过与模型的内部机制进行对比,确保解释结果与实际决策逻辑的一致性。

可解释性AI的主要技术与方法
XAI领域涵盖了丰富的技术和方法,主要可分为本地解释方法、全局解释方法、本身可解释的模型和后置解释方法。
1. 本地解释方法
本地解释方法关注单个预测或决策的解释,常用于理解特定输入下模型的行为。
- LIME(Local Interpretable Model-agnostic Explanations):通过在输入数据的局部区域生成解释模型,来近似原模型的决策边界。
- SHAP(SHapley Additive exPlanations):基于博弈论中的Shapley值,为每个特征分配一个贡献度,解释其对预测结果的影响。
2. 全局解释方法
全局解释方法旨在理解整个模型的行为和特征重要性,提供整体性的解释视角。
- 特征重要性分析:通过评估各特征对模型整体性能的贡献,识别关键特征。
- 可视化方法:如决策树可视化,帮助理解模型的决策逻辑和路径。
3. 本身可解释的模型
一些模型设计时就考虑到了可解释性,天然具有良好的解释性。
- 线性回归:通过线性关系明确各特征的影响方向和程度,易于理解。
- 决策树:通过树的结构展示决策路径,直观明了。
- 规则集模型:基于一组规则进行决策,便于解释和验证。
4. 后置解释方法
后置解释方法是在模型训练完成后,通过附加的解释机制来揭示模型的决策过程。
- 可视化注意力机制:在神经网络中,通过可视化注意力权重,展示模型关注的输入部分。
- 反事实解释:通过生成反事实案例,展示如果输入发生变化,模型的决策将如何改变。
实战教程:如何实现可解释性AI
为了更好地理解可解释性AI的实际应用,下面我们通过一个实战案例,展示如何在Python中使用SHAP库对一个深度学习模型进行解释。
环境准备
首先,确保你的环境中已安装以下库:
pip install shap tensorflow pandas scikit-learn matplotlib
1. 数据准备
我们将使用UCI的鸢尾花(Iris)数据集进行分类任务。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split# 加载数据集
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2. 模型训练
使用TensorFlow构建一个简单的神经网络模型。
import tensorflow as tf
from tensorflow.keras import layers, models# 构建模型
model = models.Sequential([layers.Dense(10, activation='relu', input_shape=(X_train.shape[1],)),layers.Dense(10, activation='relu'),layers.Dense(3, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=16, verbose=0)
3. 模型评估
评估模型的性能。
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f"Test Accuracy: {accuracy:.4f}")
4. 使用SHAP进行解释
通过SHAP库解释模型的预测。
import shap
import matplotlib.pyplot as plt# 创建SHAP解释器
explainer = shap.KernelExplainer(model.predict, X_train.sample(100))# 选择一个测试样本进行解释
test_sample = X_test.iloc[0]
shap_values = explainer.shap_values(test_sample)# 可视化解释
shap.initjs()
shap.force_plot(explainer.expected_value[0], shap_values[0], test_sample)
5. 结果分析
通过SHAP的可视化工具,我们可以直观地看到每个特征对预测结果的贡献。这样的解释有助于理解模型为何会对特定样本作出某种预测,从而提高用户对模型的信任度。
更多文献
【ChatGPT】CodeMoss & ChatGPT中文版-国内专属的大模型聚合AI工具
【VScode】揭秘编程利器:教你如何用“万能@符”提升你的编程效率! 全面解析ChatMoss & ChatGPT中文版
【VScode】VSCode中的智能编程利器,全面揭秘ChatMoss & ChatGPT中文版
结语
**可解释性AI(XAI)**作为人工智能领域的重要研究方向,正在引领AI技术向更加透明、可信和负责任的方向发展。随着AI在各个行业的深入应用,XAI的需求和价值将进一步凸显。然而,XAI的实现仍面临诸多挑战,如模型复杂度、评估标准缺乏统一性等。因此,未来的研究需要在提升可解释性与保持模型性能之间找到更好的平衡,同时开发更加高效和通用的解释方法。
在实际应用中,开发者和研究者应充分考虑XAI的需求,结合具体应用场景选择合适的解释方法,确保AI系统的透明度和可信度。同时,行业监管和标准的制定也将对XAI的发展起到重要推动作用。
总之,可解释性AI不仅是技术发展的需求,更是AI伦理和社会责任的重要体现。只有在确保AI系统透明、可信的基础上,才能充分发挥其巨大的潜力,为社会带来更积极的影响。