大模型面试题:常见的微调方法有哪些说下原理并对比
更多实时面试题总结请关注我的公众号"算法狗" 或移步至 https://pica.zhimg.com/80/v2-7fd6e77f69aa02c34ca8c334870b3bcd_720w.webp?source=d16d100b
这里说的微调主要是指参数微调,参数微调的方法主要有以下几种:
-
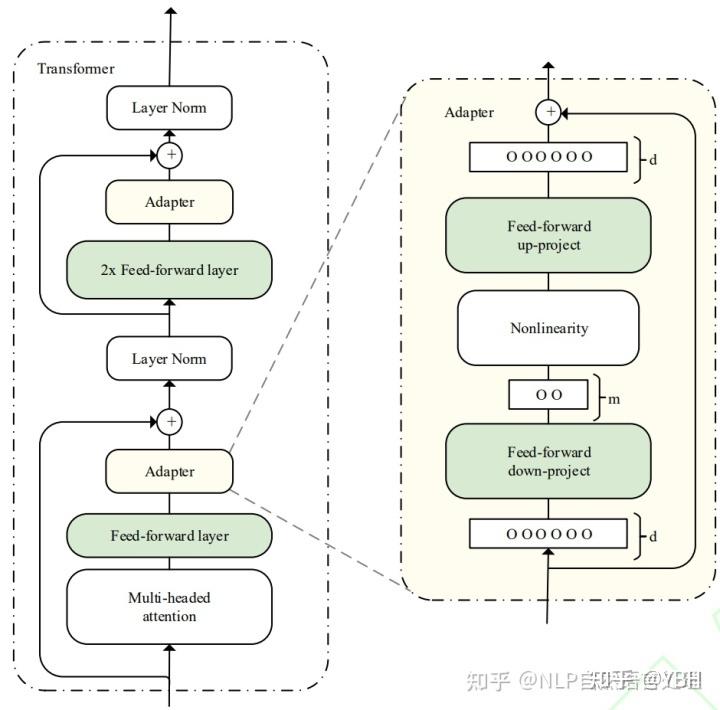
Adapter
在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成。具体使用了Adapter的模型结构如下所示:
 给每个任务定义了自己的Prompt,拼接到输入数据一起作为输入,同时freeze预训练模型进行训练
给每个任务定义了自己的Prompt,拼接到输入数据一起作为输入,同时freeze预训练模型进行训练 -
Prefix-tunning 前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,如下图中的红色块所示。与提示(prompt)不同的是,前缀完全由自由参数组成,与真正的token不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型Transformer和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。 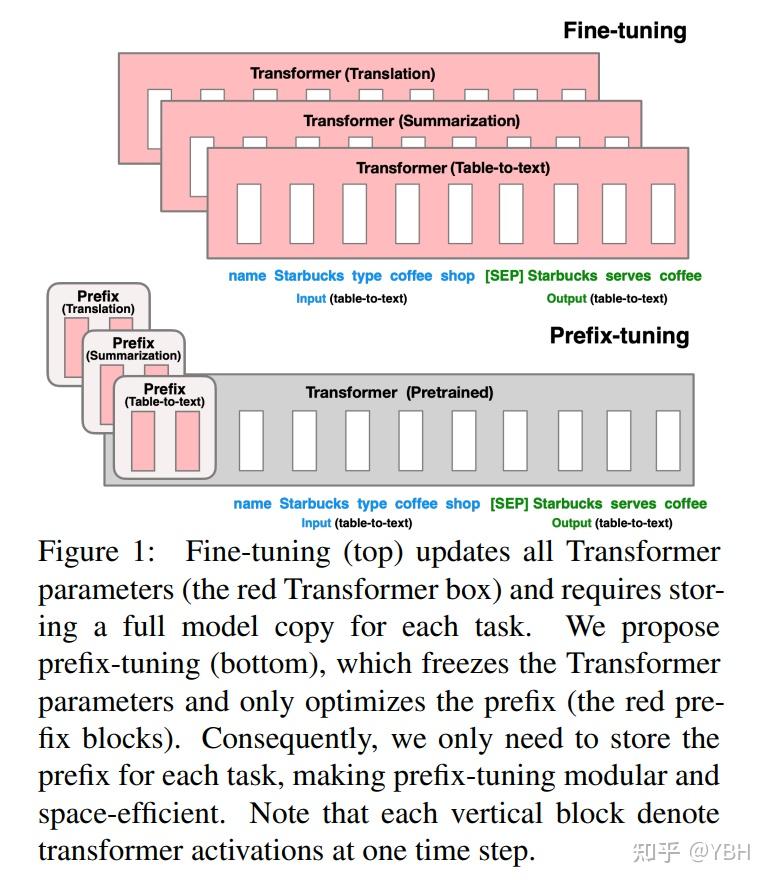
-
P-tuning/P-tuning V2
P-tuning V1直接对embedding层进行优化存在两个挑战:embedding层已经经过预训练,如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优;没法捕捉到prompt embedding之间的相关性。
P-Tuning V2是升级版本,主要解决P-Tuning V1在小参数量模型上表现差的问题。V2在每一层上都加了一个残差连接,每一层都加上prompts,使特征更充分。
P-tuning模型加入embedding位置不固定,可以加在整个输入的前面或者后面,用法比较灵活,且其通过MLP+LSTM的方式对加入的embedding进行了学习,以提高收敛性。整体框架如下图所示: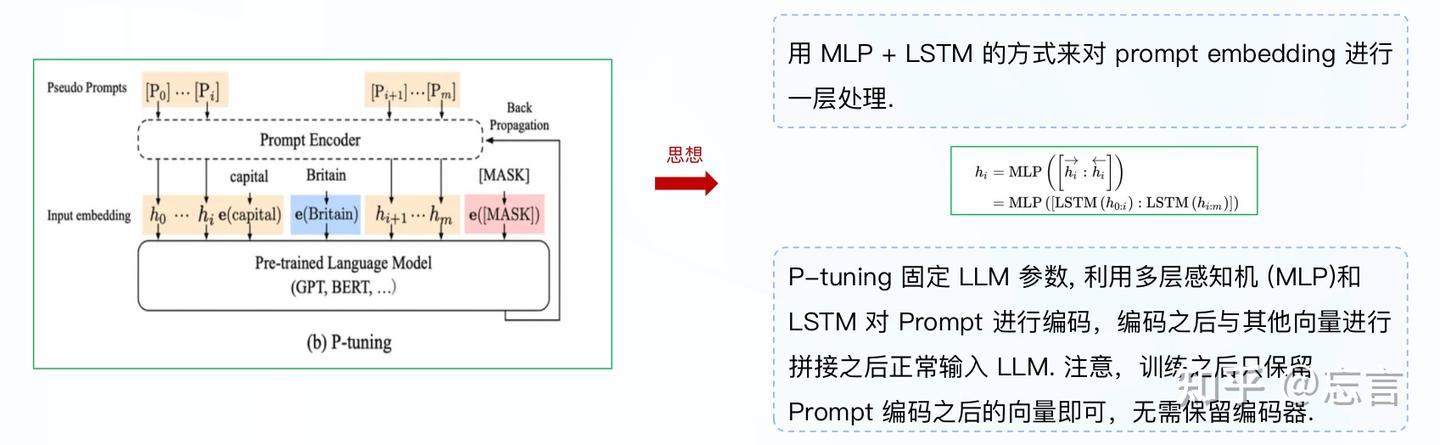
-
LORA
采用低秩矩阵近似的思想,冻结一个预训练模型的矩阵参数,并选择用A和B矩阵来替代,在下游任务时只更新A和B。流程如下: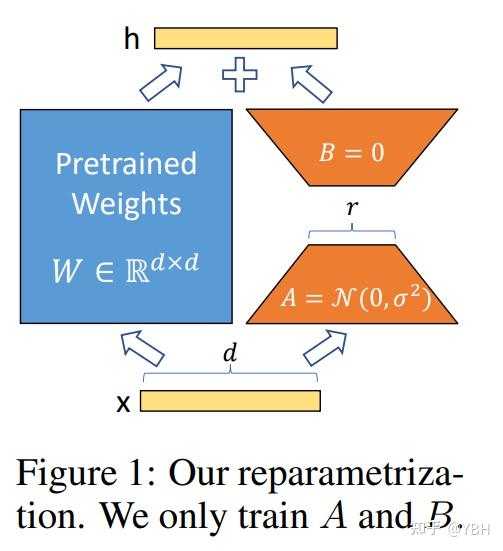
参考:
[1] https://zhuanlan.zhihu.com/p/636481171
[2] https://zhuanlan.zhihu.com/p/709376189
本文由 mdnice 多平台发布