spark读取parquet文件
源码
parquet文件读取的入口是FileSourceScanExec,用parquet文件生成对应的RDD
非bucket文件所以走createNonBucketedReadRDD方法。
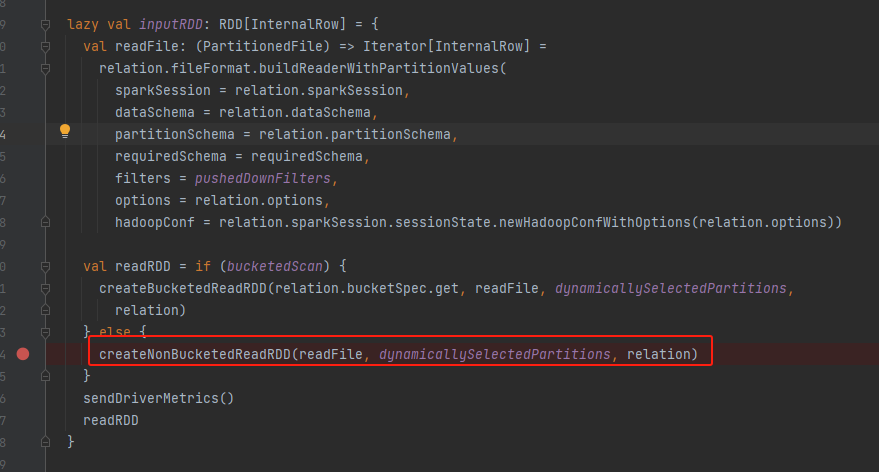
createNonBucketedReadRDD
过程:
- 确定文件分割参数
- openCostInBytes=4M 相关参数spark.sql.files.openCostInBytes=4M
- maxSplitBytes<=128M 相关参数spark.sql.files.maxPartitionBytes=128M,根据maxSplitBytes计算得来
- logInfo打印的日志可以用于排查参数
- 切分文件
- splitFiles进行文件切分,按照maxSplitBytes将大文件切分
- 切分后文件根据大小进行倒排,为了方便后面合并
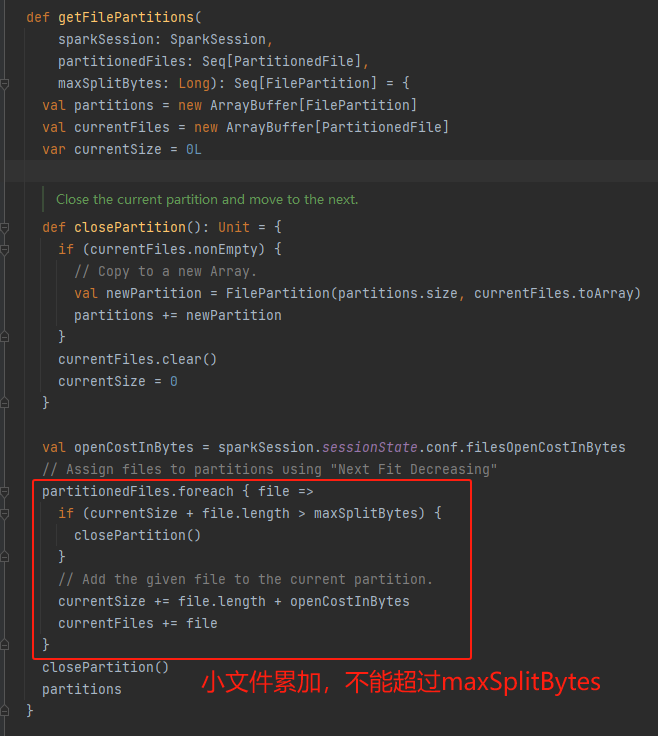
- 合并partition
- getFilePartitions 将小文件合并到一个partition
- 生成RDD
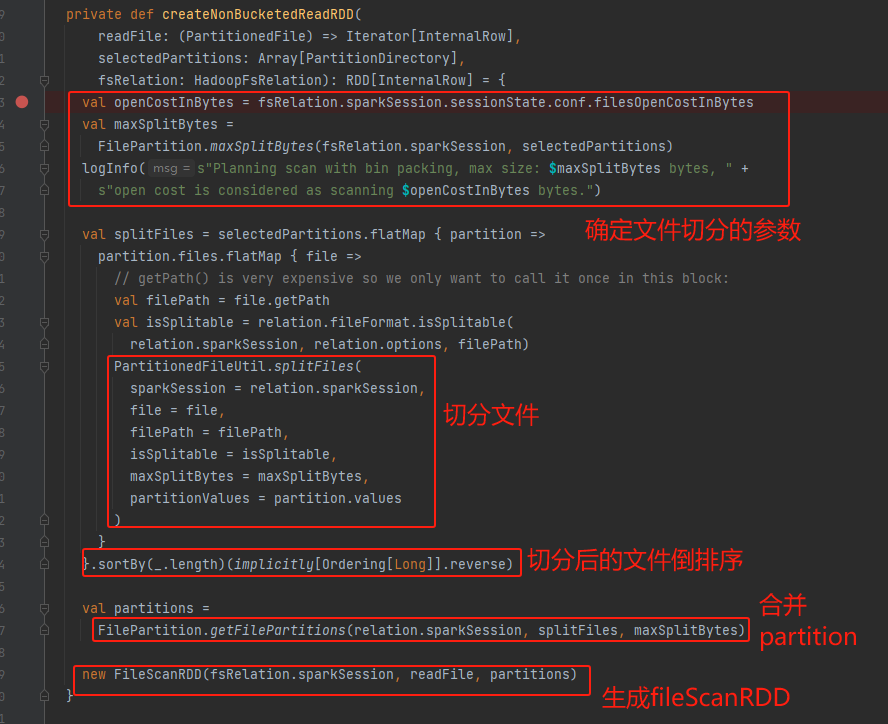
maxSplitBytes
- defaultMaxSplitBytes 最大分区大小=spark.sql.files.maxPartitionBytes=128M
- openCostInBytes 打开文件的代价 默认4M
- defaultParallelism 并行度
conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))默认是core的总和,最小为2 - totalBytes 文件总大小(单个文件大小需要加上openCostInBytes)
- bytesPerCore 单个core分配的文件大小
最后Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
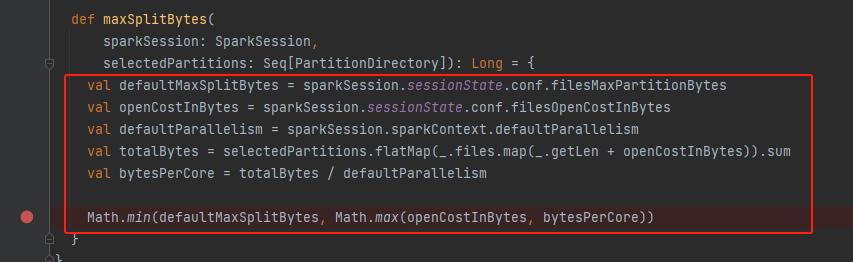
splitFiles
0L until file.getLen by maxSplitBytes按maxSplitBytes进行文件拆分
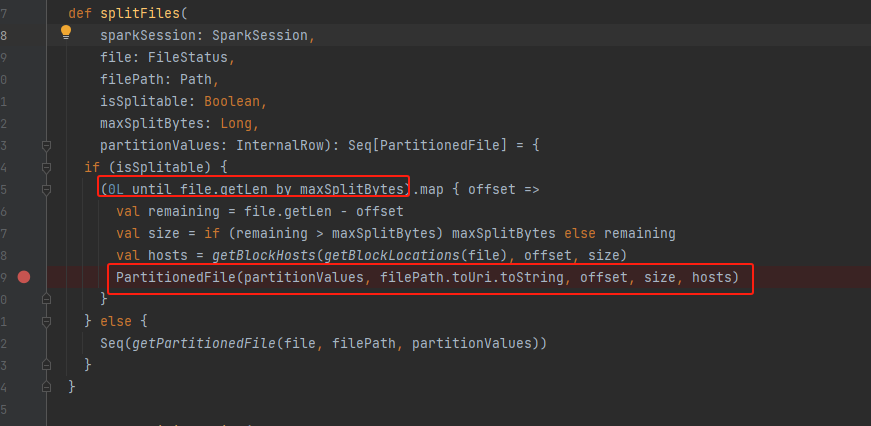
getFilePartitions
currentSize += file.length + openCostInBytes计算文件大小的时候需要加上openCostInBytes
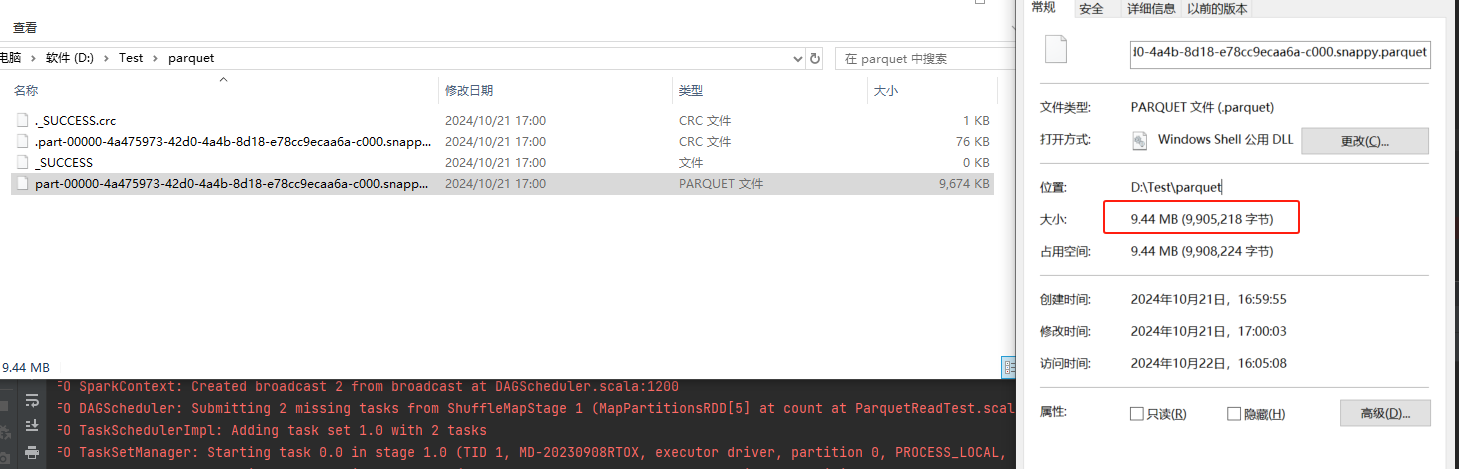
计算示例
parquet文件是9,905,218b,并行度是2
defaultMaxSplitBytes = 128MB
openCostInBytes = 4MB
defaultParallelism = max(2, 2) = 2
totalBytes = 9,905,218b+ 1 * 4MB = 14,099,522B
bytesPerCore = 14,099,522B / 2 = 7,049,761B
maxSplitBytes = 7,049,761B = Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
文件分成0-7049761 和 7049761-9905218两部分
从下面日志可以知道计算正确。


参考https://developer.aliyun.com/article/985412?utm_content=m_1000349867