SpringCloud之断路器聚合监控
一、Hystrix Turbine简介
看单个的Hystrix Dashboard的数据并没有什么多大的价值,要想看这个系统的Hystrix Dashboard数据就需要用到Hystrix Turbine。Hystrix Turbine将每个服务Hystrix Dashboard数据进行了整合。Hystrix Turbine的使用非常简单,只需要引入相应的依赖和加上注解和配置就可以了。
二、准备工作
本文使用的工程为上一篇文章的工程,在此基础上进行改造。因为我们需要多个服务的Dashboard,所以需要再建一个服务,取名为service-lucy,它的基本配置同service-hi,具体见源码,在这里就不详细说明。
三、创建service-turbine
引入相应的依赖:
<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-turbine</artifactId></dependency></dependencies>在其入口类ServiceTurbineApplication加上注解@EnableTurbine,开启turbine,@EnableTurbine注解包含了@EnableDiscoveryClient注解,即开启了注册服务。
@SpringBootApplication@EnableEurekaClient@EnableDiscoveryClient@RestController@EnableHystrix@EnableHystrixDashboard@EnableCircuitBreaker@EnableTurbinepublic class ServiceTurbineApplication {/*** http://localhost:8764/turbine.stream*/public static void main(String[] args) {SpringApplication.run( ServiceTurbineApplication.class, args );}}配置文件application.yml:
spring:application.name: service-turbineserver:port: 8769security.basic.enabled: falseturbine:aggregator:clusterConfig: default # 指定聚合哪些集群,多个使用","分割,默认为default。可使用http://.../turbine.stream?cluster={clusterConfig之一}访问appConfig: service-hi,service-la ### 配置Eureka中的serviceId列表,表明监控哪些服务clusterNameExpression: new String("default")# 1. clusterNameExpression指定集群名称,默认表达式appName;此时:turbine.aggregator.clusterConfig需要配置想要监控的应用名称# 2. 当clusterNameExpression: default时,turbine.aggregator.clusterConfig可以不写,因为默认就是default# 3. 当clusterNameExpression: metadata['cluster']时,假设想要监控的应用配置了eureka.instance.metadata-map.cluster: ABC,则需要配置,同时turbine.aggregator.clusterConfig: ABCeureka:client:serviceUrl:defaultZone: http://localhost:8761/eureka/
配置文件注解写的很清楚。
Turbine演示
依次开启server、service-hi、service-la、service-turbine工程。
打开浏览器输入:http://localhost:8769/turbine.stream,
依次请求:
http://localhost:8762/hi?name=whhttp://localhost:8763/hi?name=wh
打开:http://localhost:8763/hystrix,输入监控流http://localhost:8769/turbine.stream
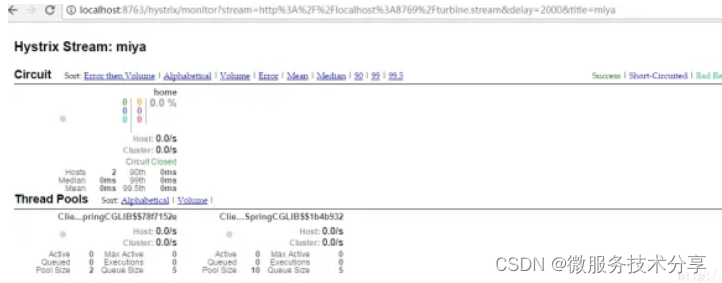
可以看到这个页面聚合了2个service的hystrix dashbord数据。