Spark大数据处理讲课笔记2.4 IDEA开发词频统计项目
文章目录
- 零、本讲学习目标
- 一、词频统计准备工作
- (一)启动集群的HDFS与Spark
- (二)在HDFS上准备单词文件
- 二、本地模式执行Spark程序
- (一)创建Maven项目
- (二)添加Spark相关依赖,打包插件
- (三)编写代码,实现功能
- (四)运行程序,查看结果
- 三、集群模式执行Spark程序
- (一)添加打包插件
- (二)修改代码,打包程序
- (三)执行提交命令
零、本讲学习目标
- 掌握本地模式执行Spark程序
- 掌握集群模式执行Spark程序
一、词频统计准备工作
- 单词计数是学习分布式计算的入门程序,有很多种实现方式,例如MapReduce;使用Spark提供的RDD算子可以更加轻松地实现单词计数。
- 在IntelliJ IDEA中新建Maven管理的Spark项目,并在该项目中使用Scala语言编写Spark的WordCount程序,最后将项目打包提交到Spark集群(Standalone模式)中运行。
(一)启动集群的HDFS与Spark
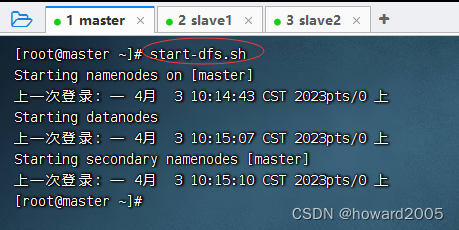
- 启动HDFS服务
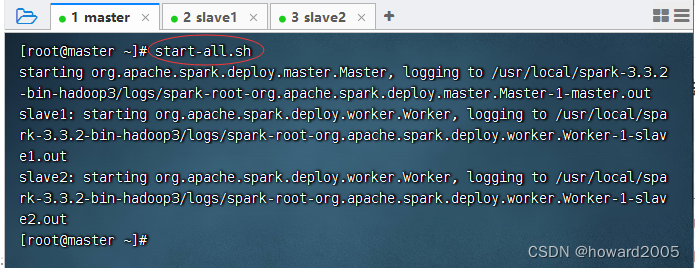
- 启动Spark集群
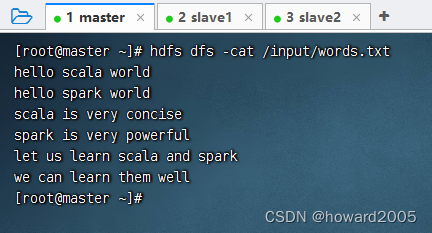
(二)在HDFS上准备单词文件
-
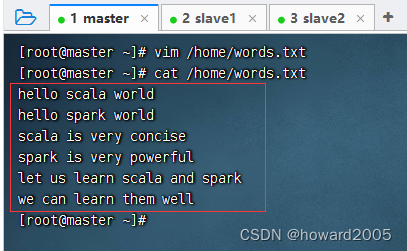
在本地创建单词文件 -
words.txt
-
HDFS上的单词文件 -
words.txt