Hadoop之——WordCount案例与执行本地jar包
目录
一、WordCount代码
(一)WordCount简介
1.wordcount.txt
(二)WordCount的java代码
1.WordCountMapper
2.WordCountReduce
3.WordCountDriver
(三)IDEA运行结果
(四)Hadoop运行wordcount
1.在HDFS上新建一个文件目录
2.新建一个文件,并上传至该目录下
3.执行wordcount命令
4.查看运行结果
5.第二次提交报错原因
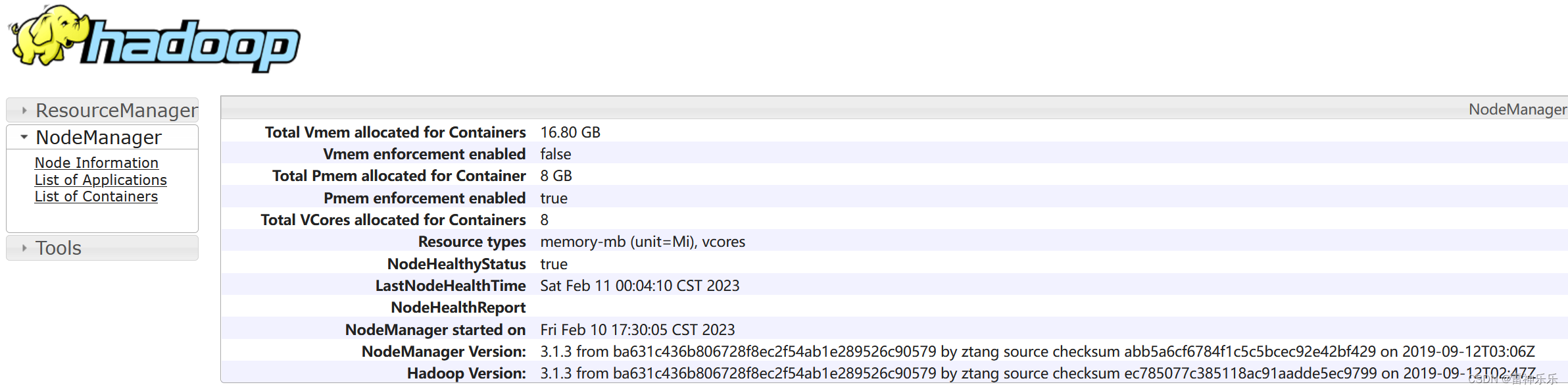
6.进入NodeManager查看
7.启动历史服务器(如果已经启动可以忽略此步骤)
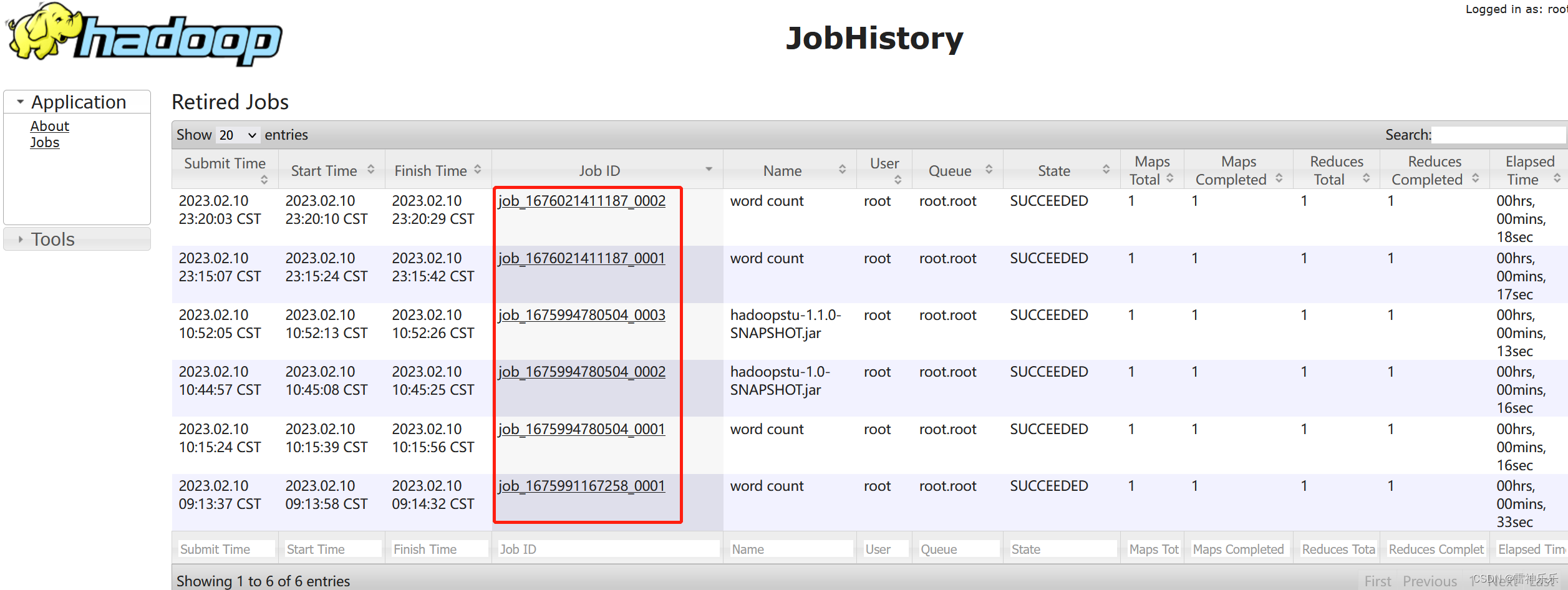
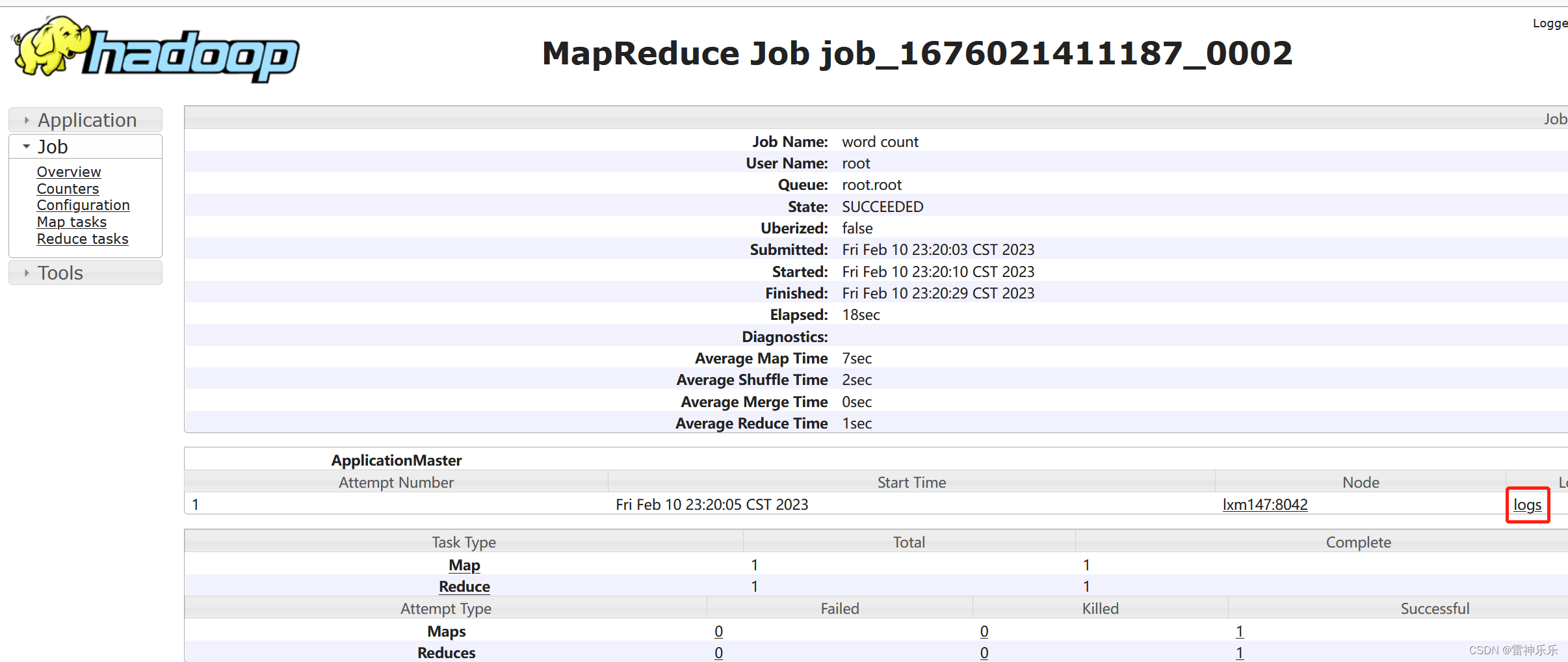
8.查看历史服务信息
三、执行本地代码
(一)项目代码
1.stuscore.csv
2.Student类
2.StudentMapper类
4.StudentReduce类
5.StudentDriver类
(二)java代码中指定路径
1.maven项目编译并打包
2.上传stuscore.csv到hdfs指定目录下
3.xftp上传target目录下的打包好的jar包上传到虚拟机
4.Hadoop运行hadoopstu-1.0-SNAPSHOT.jar
5.Hadoop运行结果
(三)java代码中不指定路径
1.StuudentDriver类
2.重新编译打包上传
3.HDFS命令执行该jar包
4.查看运行结果
一、WordCount代码
(一)WordCount简介
WordCount是大数据经典案例,其逻辑就是有一个文本文件,通过编写java代码与Hadoop核心组件的操作,查询每个单词出现的频率。
1.wordcount.txt
hello java hello hadoop hello java hadoop java hadoop java hadoop hadoop java hello java
(二)WordCount的java代码
1.WordCountMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
// <0,"hello world","hello",1>
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {Text text = new Text();IntWritable intWritable = new IntWritable();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {System.out.println("WordCount stage Key:"+key+" Value:"+value);String[] words = value.toString().split(" ");// "hello world" -->[hello,world]for (String word :words) {text.set(word);intWritable.set(1);context.write(text,intWritable);// 输出键值对 <hello,1><world,1>}}
}2.WordCountReduce
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;// <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
public class WordCountReduce extends Reducer<Text, IntWritable,Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {System.out.println("Reduce stage Key:"+key+" Values:"+values.toString());int count = 0;for (IntWritable intWritable :values) {count += intWritable.get();}
// LongWritable longWritable = new LongWritable();
// longWritable.set(count);LongWritable longWritable = new LongWritable(count);System.out.println("Key:"+key+" ResultValue:"+longWritable.get());context.write(key,longWritable);}
}3.WordCountDriver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(WordCountDriver.class);// 设置mapper类job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 设置reduce类job.setReducerClass(WordCountReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 指定map输入的文件路径FileInputFormat.setInputPaths(job,new Path("D:\\javaseprojects\\hadoopstu\\input\\demo1\\wordcount.txt"));// 指定reduce结果输出的文件路径Path path = new Path("D:\\javaseprojects\\hadoopstu\\output");FileSystem fileSystem = FileSystem.get(path.toUri(),configuration);if(fileSystem.exists(path)){fileSystem.delete(path,true);}FileOutputFormat.setOutputPath(job,path);job.waitForCompletion(true);
// job.setJobName("");}
}
(三)IDEA运行结果
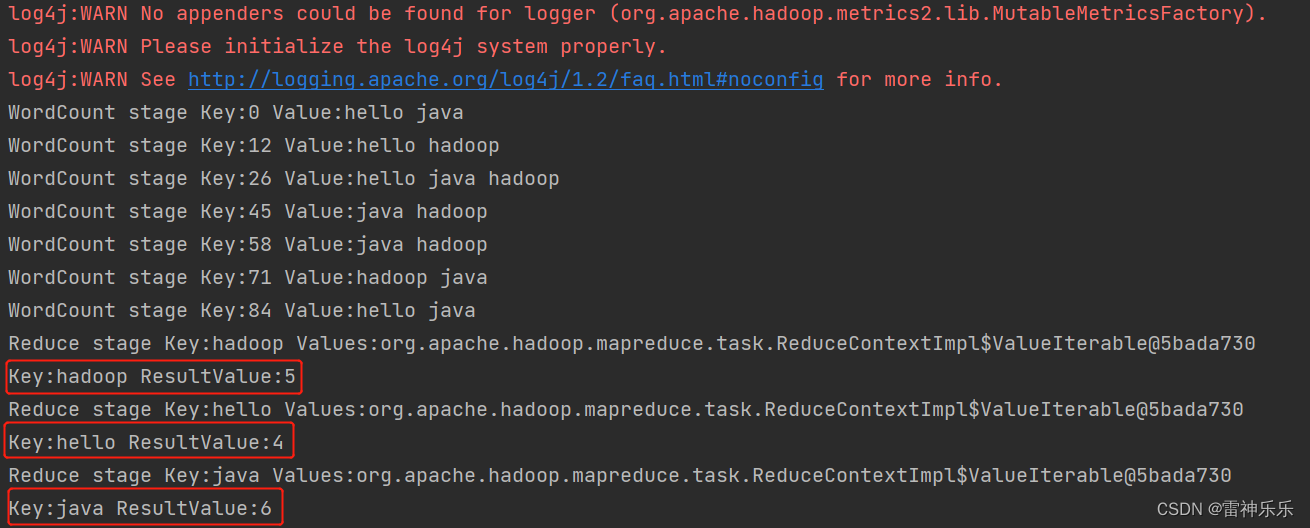
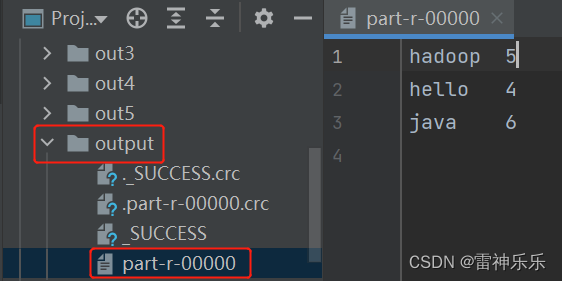
(四)Hadoop运行wordcount
1.在HDFS上新建一个文件目录
[root@lxm147 ~]# hdfs dfs -mkdir /inputpath
2023-02-10 23:05:40,098 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@lxm147 ~]# hdfs dfs -ls /
2023-02-10 23:05:52,217 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
drwxr-xr-x - root supergroup 0 2023-02-08 08:06 /aa
drwxr-xr-x - root supergroup 0 2023-02-10 10:52 /bigdata
drwxr-xr-x - root supergroup 0 2023-02-10 23:05 /inputpath2.新建一个文件,并上传至该目录下
[root@lxm147 mapreduce]# vim ./test.csv
[root@lxm147 mapreduce]# hdfs dfs -put ./test.csv /inputpath
3.执行wordcount命令
[root@lxm147 mapreduce]# hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount /inputpath /outputpath
4.查看运行结果
(1)web端


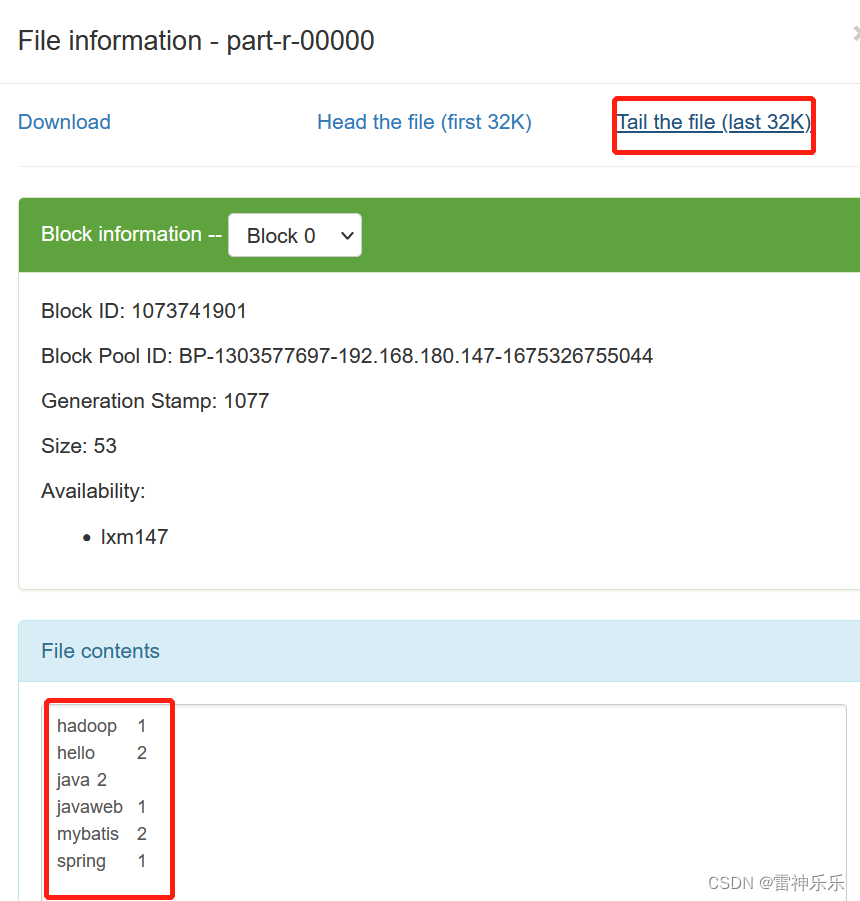
(2)命令行
[root@lxm147 mapreduce]# hdfs dfs -cat /outputpath/part-r-00000
2023-02-10 23:26:06,276 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-02-10 23:26:07,793 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
hadoop 1
hello 2
java 2
javaweb 1
mybatis 2
spring 15.第二次提交报错原因
执行wordcount命令前删除/outpath目录下的文件再执行即可
6.进入NodeManager查看
http://lxm147:8088/cluster
7.启动历史服务器(如果已经启动可以忽略此步骤)
[root@lxm148 ~]# mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[root@lxm148 ~]# jps
4546 SecondaryNameNode
6370 JobHistoryServer
4164 NameNode
4804 ResourceManager
4937 NodeManager
6393 Jps
4302 DataNode
8.查看历史服务信息
http://lxm147:19888/

三、执行本地代码
(一)项目代码
1.stuscore.csv
1,zs,10,语文 2,ls,98,语文 3,ww,80,语文 1,zs,20,数学 2,ls,87,数学 3,ww,58,数学 1,zs,44,英语 2,ls,66,英语 3,ww,40,英语 1,zs,55,政治 2,ls,60,政治 3,ww,80,政治 1,zs,10,化学 2,ls,28,化学 3,ww,78,化学 1,zs,87,生物 2,ls,9,生物 3,ww,10,生物
2.Student类
import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class Student implements WritableComparable<Student> {private long stuid;private String stuname;private int score;private String lession;@Overridepublic int compareTo(Student o) {return this.score > o.score ? 1 : 0;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(stuid);dataOutput.writeUTF(stuname);dataOutput.writeUTF(lession);dataOutput.writeInt(score);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.stuid = dataInput.readLong();this.stuname = dataInput.readUTF();this.lession = dataInput.readUTF();this.score = dataInput.readInt();}@Overridepublic String toString() {return "Student{" +"stuid=" + stuid +", stuname='" + stuname + '\'' +", score=" + score +", lession='" + lession + '\'' +'}';}public long getStuid() {return stuid;}public void setStuid(long stuid) {this.stuid = stuid;}public String getStuname() {return stuname;}public void setStuname(String stuname) {this.stuname = stuname;}public int getScore() {return score;}public void setScore(int score) {this.score = score;}public String getLession() {return lession;}public void setLession(String lession) {this.lession = lession;}public Student(long stuid, String stuname, int score, String lession) {this.stuid = stuid;this.stuname = stuname;this.score = score;this.lession = lession;}public Student() {}
}
2.StudentMapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;// K=id,V=student
// Mapper<进来的K,进来的V,出去的K,出去的V>
public class StudentMapper extends Mapper<LongWritable, Text, LongWritable, Student> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Student>.Context context) throws IOException, InterruptedException {System.out.println(key+" "+value.toString());String[] split = value.toString().split(",");LongWritable stuidKey = new LongWritable(Long.parseLong(split[2]));Student studentValue = new Student(Long.parseLong(split[0]), split[1], Integer.parseInt(split[2]),split[3]);context.write(stuidKey,studentValue);}
}4.StudentReduce类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class StudentReduce extends Reducer<LongWritable, Student, Student, NullWritable> {@Overrideprotected void reduce(LongWritable key, Iterable<Student> values, Reducer<LongWritable, Student, Student, NullWritable>.Context context) throws IOException,InterruptedException {Student stu = new Student();// 相同key相加
// int sum = 0;int max = 0;String name ="";String lession = "";
// for (Student student:
// values) {
// sum += student.getScore();
// name = student.getStuname();
// }// 求每门科目的最高分for (Student student :values) {if(max<=student.getScore()){max = student.getScore();name = student.getStuname();lession = student.getLession();}}stu.setStuid(key.get());stu.setScore(max);stu.setStuname(name);stu.setLession(lession);System.out.println(stu.toString());context.write(stu,NullWritable.get());}
}
5.StudentDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class StudentDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(StudentDriver.class);job.setMapperClass(StudentMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Student.class);job.setReducerClass(StudentReduce.class);job.setOutputKeyClass(Student.class);job.setOutputValueClass(NullWritable.class);// 指定路径FileInputFormat.setInputPaths(job,new Path("hdfs://lxm147:9000/bigdata/in/demo2/stuscore.csv"));Path path = new Path("hdfs://lxm147:9000/bigdata/out2");// 不指定路径/* Path inpath = new Path(args[0]);FileInputFormat.setInputPaths(job, inpath);Path path = new Path(args[1]);*/FileSystem fs = FileSystem.get(path.toUri(), configuration);if (fs.exists(path)) {fs.delete(path, true);}FileOutputFormat.setOutputPath(job, path);job.waitForCompletion(true);}
}(二)java代码中指定路径
1.maven项目编译并打包
分别双击compile和package
2.上传stuscore.csv到hdfs指定目录下
hdfs dfs -put /opt/stuscore.csv /bigdata/in/demo23.xftp上传target目录下的打包好的jar包上传到虚拟机
4.Hadoop运行hadoopstu-1.0-SNAPSHOT.jar
[root@lxm147 opt]# hadoop jar ./hadoopstu-1.1.0-SNAPSHOT.jar nj.zb.kb21.demo2.StudentDriver /bigdata/in/demo2/stuscore.csv /bigdata/out2
5.Hadoop运行结果

(三)java代码中不指定路径
1.StuudentDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class StudentDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(StudentDriver.class);job.setMapperClass(StudentMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Student.class);job.setReducerClass(StudentReduce.class);job.setOutputKeyClass(Student.class);job.setOutputValueClass(NullWritable.class);// 指定路径/*FileInputFormat.setInputPaths(job,new Path("hdfs://lxm147:9000/bigdata/in/demo2/stuscore.csv"));Path path = new Path("hdfs://lxm147:9000/bigdata/out2");*/// 不指定路径Path inpath = new Path(args[0]);FileInputFormat.setInputPaths(job, inpath);Path path = new Path(args[1]);FileSystem fs = FileSystem.get(path.toUri(), configuration);if (fs.exists(path)) {fs.delete(path, true);}FileOutputFormat.setOutputPath(job, path);job.waitForCompletion(true);}
}2.重新编译打包上传
为了方便区分,这里修改版本号再重新编译打包
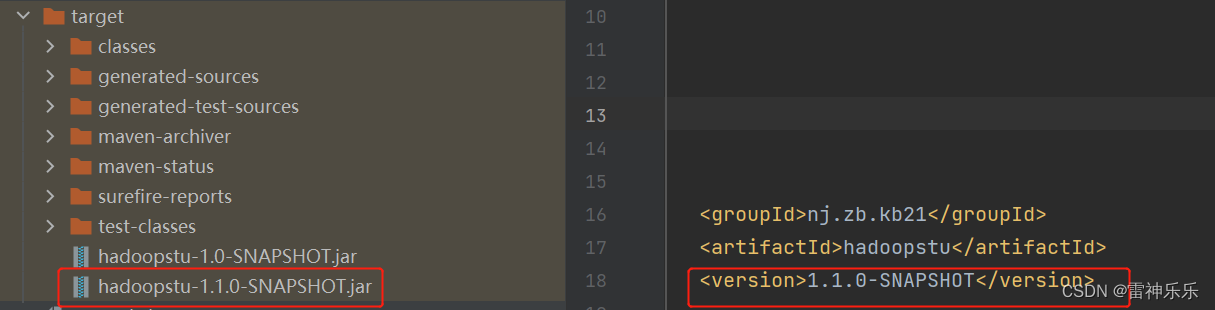
3.HDFS命令执行该jar包
[root@lxm147 opt]# hadoop jar ./hadoopstu-1.1.0-SNAPSHOT.jar nj.zb.kb21.demo2.StudentDriver /bigdata/in/demo2/stuscore.csv /bigdata/out
4.查看运行结果
[root@lxm147 opt]# hdfs dfs -cat /bigdata/out/part-r-00000
Student{stuid=1, stuname='zs', score=226}
Student{stuid=2, stuname='ls', score=348}
Student{stuid=3, stuname='ww', score=346}