关于工作虚拟组的一些思考
这是学习笔记的第 2493篇文章

因为各种工作协作,势必要打破组织边界,可能会存在各种形态的虚拟组。
近期沉淀了一些虚拟组的管理方式,在一定时间范围内也有了一些起色,所以在不断沉淀的过程中,也在不断思考。
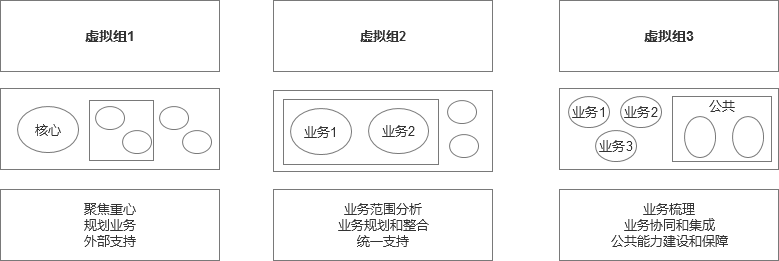
这三个虚拟组是分阶段成立的,虚拟组1和虚拟组2是相近时间段成立的,虚拟组3则是相隔了2个多月之后才从筹划到逐步启动的状态。
虚拟组1的目的主要是解决某个组织内的人少事多的难题,比如有十多个技术栈,但是只有几个人,按照互备的思路,怎么安排都会发现是全员参与,最后也就失去了重心,所以虚拟组的方式就是精选出几个人来,专门琢磨和分析这些事情,主要包括3部分:1)通过梳理分析得到当前的瓶颈点或者中心在哪里,然后聚焦之后重点解决 2)对于一些业务,看起来是碎片化的,但是按照面来盘点,可以做一些规划,这样就把事情规整起来了,3)组织内人少是事实,那么可以有效借助外部力量,协调解决,所以这个虚拟组的整体逻辑就是先解决内部问题,然后把问题的解决思路外延,寻求协同。

虚拟组2在组织形态不明确的情况下是比较难推动的,比如存在一些体量的业务1,业务2,实力相当,要整合起来通盘考虑就是难以推动的事情。所以虚拟组2的目的是把业务做整合,然后统一规划之后,统一支持。
其中虚拟组1和虚拟组2的一个很重要的特点就是选定的成员应该具备一定的管理属性,能够推动和组织去解决一些事情。

虚拟组3则是一种相对全新的模式,比如有几个看起来相对独立和松散的业务,各自为政,都能正常运转。按照通信代价来说,3个业务如果一对一对接,需要3次沟通,而如果是4个业务,则需要差不多6次沟通,以此类推,这种沟通和对接的成本是极高的。所以干脆单开一摊子,提炼它们的公共部分,把通用的部分提炼出来重点建设,然后再把各个业务集成起来。说实话虚拟组3所做的工作难度是最大的,但是成效从长期来看也是最好的。

虚拟组3我们按照运维体系服务建设为切入点来思考,假设有差不多10个子方向,那么我们使用虚拟组的方式管理,就需要把具体建设工作和协作分隔开来。具体点则是给机会、提要求、做辅导、上资源。
好了,基本明确了运维方向,则启动这个虚拟团队,就需要对齐认识,让虚拟团队这个轮子转起来。
经过初步沟通和思考,我整理了如下的思考总结:
基本分工和原则
虚拟组成员专注于业务的梳理和技术分析,重点把业务和相关问题分析清楚,对于落地过程中的协作困难需要考虑完整,(短中期内)对于外部协作、部门内的协调工作由我负责推动;
短期内先不考虑使命、愿景,整体规划的内容,需要聚焦的事项都是基于一线的实际问题
需要明确组内成员的职责和角色
对于业务的熟悉,目的不是投入到某个具体业务的开发中,需要把握好度,了解到什么程度即可;
先不要规划一件很大的事情,比如动辄需要半年甚至一年才可以完成,需要考虑落地性,积聚小胜,小步迭代
不需要写ppt, 重点把方案设计和分析写完整
目标思路
对于运维体系的梳理思路,分为两层:
在大运维体系内,各个业务方向通用的运维操作有哪些,到底是怎么支持业务的,有哪些共通之处,本质上是提取运维操作具有共性的部分。
以运维无法登录堡垒机,没有服务器手工操作权限为一个里程碑,以终为始进行思考,大运维体系内应该具备哪些基本的运维能力和相关的操作支持
工作步调
虚拟组的价值呈现,短期内不要有过高的期望,先摸清业务情况
切实解决实际的问题
对于业务的梳理,能够拆解出可行的具体事项,制定相应的计划并落实
对于技术层面,公共机制的设计和内部普及推广
不着急列出完整的OKR目标,可以按照月度、或者季度第一阶段、第二阶段的方式逐步确认
后面我也会时不时对一些组织管理中的情况进行总结,及时分享出来。
各大平台都可以找到我
微信公众号:杨建荣的学习笔记
Github:@jeanron100
CSDN:@jeanron100
知乎:@jeanron100
头条号:@杨建荣的学习笔记
网易号:@杨建荣的数据库笔记
腾讯云+社区:@杨建荣的学习笔记
热文:
呼伦贝尔游记第二篇
山西大同云冈石窟一日游
新数据库时代,DBA 发展之路该如何选择
我们为什么在MySQL中几乎不使用分区表
《大江大河2》最触动我的一段经典对话
如何优化MySQL千万级大表,我写了6000字的解读
一道经典的MySQL面试题,答案出现三次反转
换个角度看人生
QQ群号:763628645
QQ群二维码如下, 添加请注明:姓名+地区+职位,否则不予通过
点在看,让更多人看到