聚簇索引与非聚簇索引
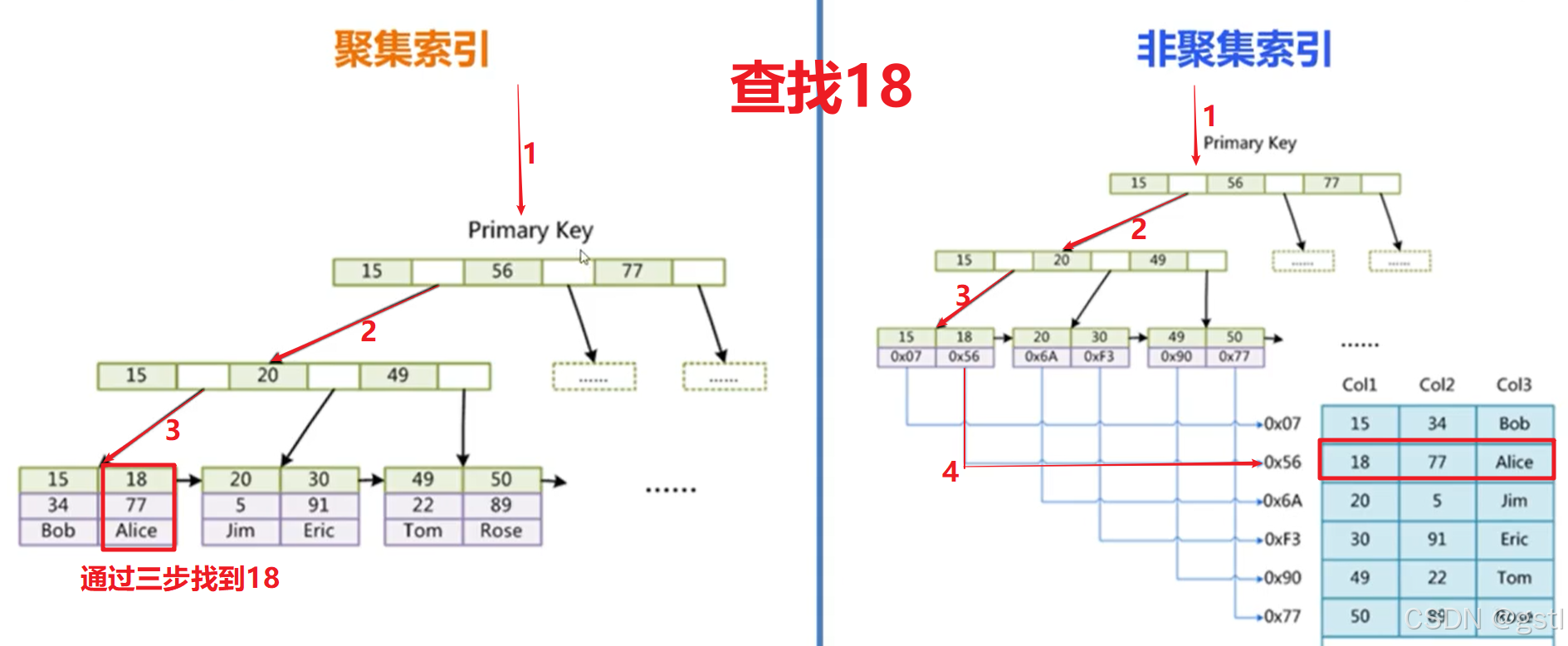
物理存储方式不同:
1. InnoDb默认数据结构是聚簇索引;MyISAM 是非聚簇索引
2. 聚簇索引 中表索引与数据是在一个文件中 .ibd;非聚簇索引中表索引(.MYI)与数据(.MYD)是在两个文件中
3. 聚簇索引中表数据行都存放在索引树的叶子节点中;非聚簇索引中表数据行则存放在数据块中,叶子节点存储的是数据块的指针
4. 聚簇索引中索引和数据存在同一个B-Tree中,非聚簇索引需要先查询索引文件,得到索引,然后根据索引获取数据;所以从聚簇索引中获取数据通常比在非聚簇索引中查找要快