MySQL更新数据流程
1.mysql三种重要日志
redo log(重做日志):存在于引擎层,物理存储,通过设置innodb_flush_log_at_trx_xommit=1 让其持久化到磁盘,保证引擎的crash-safe能力,遵从WAL技术(Write-Ahead Logging),存放方式为指定大小循环存储,存储时通过写指针(write pos)和擦拭指针(check point)来控制,存放内容为“在某个数据页做了什么操作”,简单来说就是为了保证数据准确,场景:系统崩溃了,可以找回
bin log(归档日志):存在server层,物理存储,通过设置sync_binlog=1让其持久化到磁盘,与引擎无关,存放方式为叠加,不会覆盖,存储内容包括两部分:存储sql,存储数据前后变动,在数据备份以及回复中,用得多,简单来说是为了备份数据,场景:数据还原,先备份到指定时间点的数据,再根据binlog恢复
undo log(回滚日志):该日志主要是用于事务执行失败时进行回滚操作,同时也是用于MVCC中对数据的历史版本进行查看

2.先贴图
sql:
update test set c = c + 1 where id = 2;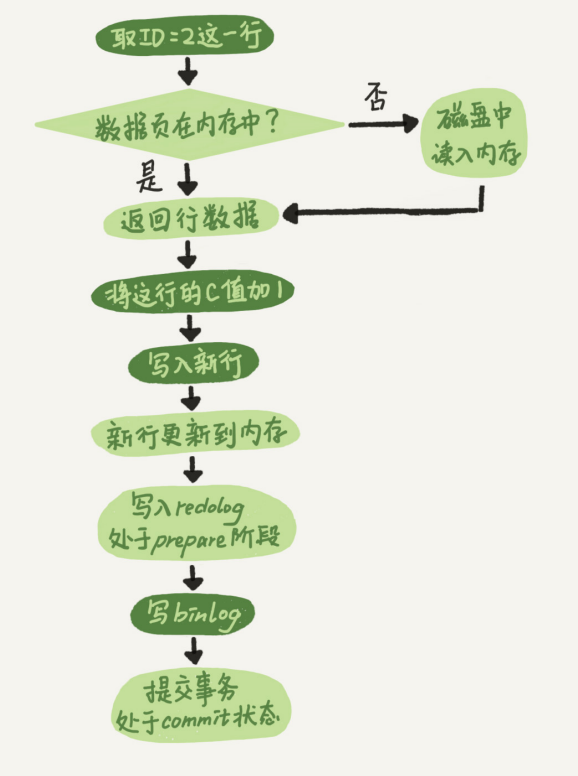
3.执行流程
- 执行器从引擎层查询id=2的数据
- 引擎层先从内存中查询是否存在,如果不存在则从磁盘中加载返回
- 执行器对c字段进行+1后,调用引擎层进行写入
- 引擎层更新内存数据,同时写入redo log,并且设置redo log状态为prepare
- 通知执行器写入bin log ,写入后通知引擎层
- 引擎层提交事务,修改redo log状态为commit
4.疑问
-> 为什么redo log需要两种状态(两段提交)?
防止数据存储时,其中写入redo log或者bin log时系统崩溃,导致两端数据不一致,双重确认有利于保存数据一致性。
举个例子:在写入redo log后,还没写入bin log,这个时候系统崩溃重启了,这个时候bin log就会缺少该操作的日志,从而导致数据不一致,两者调换也一样.