ConvMixer:Patches Are All You Need
Patches Are All You Need
发表时间:[Submitted on 24 Jan 2022];
发表期刊/会议:Computer Vision and Pattern Recognition;
论文地址:https://arxiv.org/abs/2201.09792;
代码地址:https://github.com/locuslab/convmixer;
0 摘要
尽管CNN多年以来一直是计算机视觉任务的主要架构,但最近的一些工作表明,基于Transformer的模型,尤其是ViT,在某些情况下会超越CNN的性能(尤其是后来的swin transformer,完全超越CNN, 里程碑);
然而,因为Transformer的self-attention运行时间为二次的/平方的(O(n2)O(n^2)O(n2)),ViT使用patch embedding,将图像的小区域组合成单个输入特征,以便应用于更大的图像尺寸。
这就引出一个问题: ViT的性能是由于Transformer本身就足够强大,还是因为输入是patch?
本文为后者提供了一些证据;
本文提出一种非常简单的模型:ConvMixer,思想类似于MLP-Mixer;
-
MLP-Mixer直接在作为输入的patch上操作,分离空间和通道维度的混合信息,并在整个网络中保持相同的大小和分辨率。
-
ConvMixer只使用标准卷积来实现混合步骤。
尽管它很简单,但本文表明ConvMixer在类似的参数计数和数据集大小方面优于ViT、MLP-Mixer和它们的一些变体,此外还优于经典视觉模型(如ResNet)。
1 简介
本文探索一个问题:ViT的性能强大是因为Transformer结构本身,还是更多的来源于这种patch的表征形式?
本文提出一个非常简单的卷积架构,我们称之为“ConvMixer”,因为它与最近提出的MLP-Mixer相似(Tolstikhin et al, 2021)。
ConvMixer的许多方面都和ViT或MLP-Mixer类似:
- 直接对patch进行操作;
- 在所有层中保持相同的分辨率和大小表示(feature map不降维、没有下采样);
- 不会对连续层的表示进行下采样;
- 将信息的“通道混合”与“空间混合”分开(depthwise 和 pointwise conv);
不同之处:
- ConvMixer只通过标准卷积来完成所有这些操作;
结论:patch的表征形式很重要;
2 ConvMixer模型
2.0 模型概述
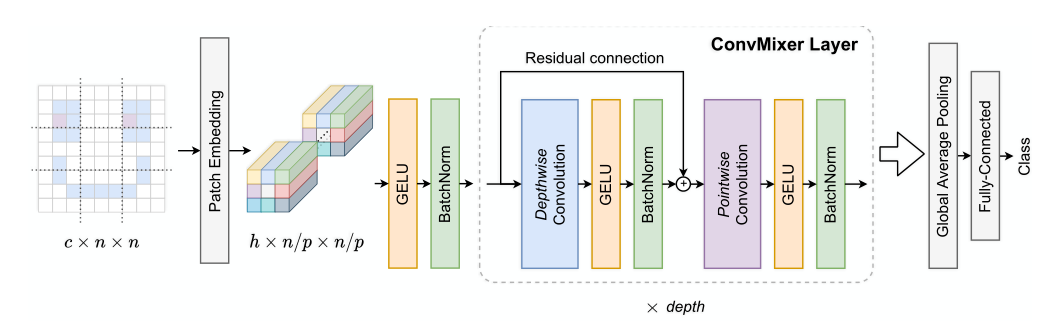
如图2所示:
- 输入图像大小为c×n×nc×n×nc×n×n,c-通道,n-宽度/高度;
- patch大小为ppp,进行patch embedding后,个数为n/p×n/pn/p × n/pn/p×n/p,一个嵌入成h维的向量,得到向量块(也可以叫feature map) h×(n/p)×(n/p)h×(n/p)×(n/p)h×(n/p)×(n/p);
- 这个patch embedding不同于Transformer的patch embedding;
- 这一步相当于用一个输入通道为ccc,输出通道为hhh,卷积核大小=patch_size, stride = patch_size的卷积核去卷出的feature map;
- 将这个feature map进行GeLU激活和BN,输入进ConvMixer Layer中;
- ConvMixer层由深度卷积depthwise conv和逐点卷积pointwise conv和残差连接组成,每一个卷积之后都会有GeLU激活和BN;
- depthwise conv: 将hhh个通道各自进行卷积=>空间混合;
- pointwise conv:1×1的卷积,对通道之间混合;
- ConvMixer层会循环depth次;
- 最后接入分类头;

Pytorch实现:
class ConvMixerLayer(nn.Module):def __init__(self,dim,kernel_size = 9):super().__init__()#残差结构self.Resnet = nn.Sequential(nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding='same'),nn.GELU(),nn.BatchNorm2d(dim))#逐点卷积self.Conv_1x1 = nn.Sequential(nn.Conv2d(dim,dim,kernel_size=1),nn.GELU(),nn.BatchNorm2d(dim))def forward(self,x):x = x +self.Resnet(x)x = self.Conv_1x1(x)return xclass ConvMixer(nn.Module):def __init__(self,dim,depth,kernel_size=9, patch_size=7, n_classes=1000):super().__init__()self.conv2d1 = nn.Sequential(nn.Conv2d(3,dim,kernel_size=patch_size,stride=patch_size),nn.GELU(),nn.BatchNorm2d(dim))self.ConvMixer_blocks =nn.ModuleList([])for _ in range(depth):self.ConvMixer_blocks.append(ConvMixerLayer(dim=dim,kernel_size=kernel_size))self.head = nn.Sequential(nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(),nn.Linear(dim,n_classes))def forward(self,x):#编码时的卷积x = self.conv2d1(x)#多层ConvMixer_block 的计算for ConvMixer_block in self.ConvMixer_blocks:x = ConvMixer_block(x)#分类输出x = self.head(x)return xmodel = ConvMixer(dim=128,depth=2)
print(model)
ConvMixer((conv2d1): Sequential((0): Conv2d(3, 128, kernel_size=(7, 7), stride=(7, 7))(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(ConvMixer_blocks): ModuleList((0): ConvMixerLayer((Resnet): Sequential((0): Conv2d(128, 128, kernel_size=(9, 9), stride=(1, 1), padding=same, groups=128)(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(Conv_1x1): Sequential((0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): ConvMixerLayer((Resnet): Sequential((0): Conv2d(128, 128, kernel_size=(9, 9), stride=(1, 1), padding=same, groups=128)(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))(Conv_1x1): Sequential((0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))(1): GELU()(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))))(head): Sequential((0): AdaptiveAvgPool2d(output_size=(1, 1))(1): Flatten(start_dim=1, end_dim=-1)(2): Linear(in_features=128, out_features=1000, bias=True))
)
2.1 参数设计
ConvMixer的实例化依赖于四个参数:
- the “width” or hidden dimension: hhh (patch embedding的维度);
- ConvMixer层的循环次数:depthdepthdepth;
- 控制模型内部分辨率的patch size: ppp;
- 深度卷积层的核大小:kkk;
其他ConvMixer模型的命名规则:ConvMixer-h/d;
2.2 动机
本文的架构是基于混合的想法;特别地,我们选择了深度卷积dw来混合空间位置和点卷积来pw混合通道位置。
以前工作的一个关键观点是,MLP和自我注意可以混合远的空间位置,也就是说,它们可以有任意大的接受域。因此,我们使用大核卷积来混合遥远的空间位置。
虽然自我注意和MLP理论上更灵活,允许大的接受域和内容感知行为,但卷积的归纳偏差非常适合视觉任务。通过使用这样的标准操作,我们也可以看到与传统的金字塔形、逐步下采样的卷积网络设计相比,patch表示本身的效果。
3 实验
3.1 训练设置
主要在ImageNet-1k分类上评估ConvMixers,没有任何预训练或其他数据;
将ConvMixer添加到timm框架,并使用接近标准的设置对其进行训练: 除了默认的timm增强外,我们还使用RandAugment、mixup、CutMix、随机擦除和梯度范数裁剪。使用AdamW优化器;
由于计算量有限,我们绝对没有在ImageNet上进行超参数调优,并且训练的epoch比竞争对手少。
因此,我们的模型可能过度正则化或不正则化,我们报告的准确性可能低估了我们模型的能力。
3.2 实验结果
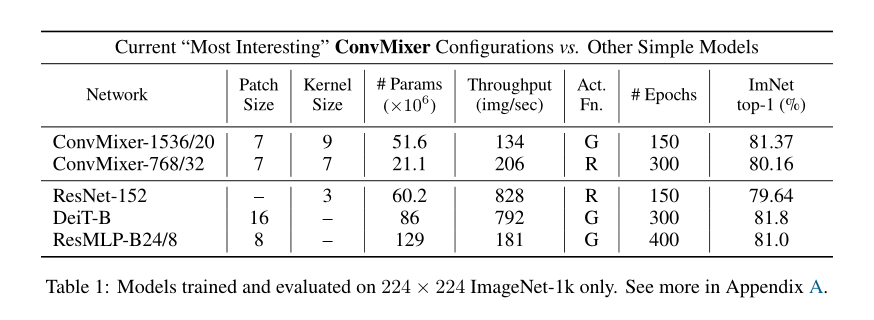
- 精度:在ImageNet上,参数为52M的ConvMixer-1536/20可以达到81.4%的top-1精度,参数为21M的ConvMixer-768/32可以达到80.2%的top-1精度;
- 宽度:更宽的ConvMixer似乎收敛更快,但需要大量内存和计算;
- 内核大小:当将内核大小从k = 9减小到k = 3时,ConvMixer-1536/20的精度下降了≈1%;
- patch大小:较小patch的ConvMixers基本上更好,更大的patch可能需要更深的ConvMixers;除了将patch大小从7增加到14,其他都保持不变,ConvMixer-1536/20达到了78.9%的top-1精度,但速度快了大约4倍;
- 激活函数:用ReLU训练了一个模型,证明在最近的各向同性模型中流行的GELU是不必要的。
3.3 比较
将ConvMixer模型与ResNet/DeiT/ResMLP比较,结果如表1、图1所示;
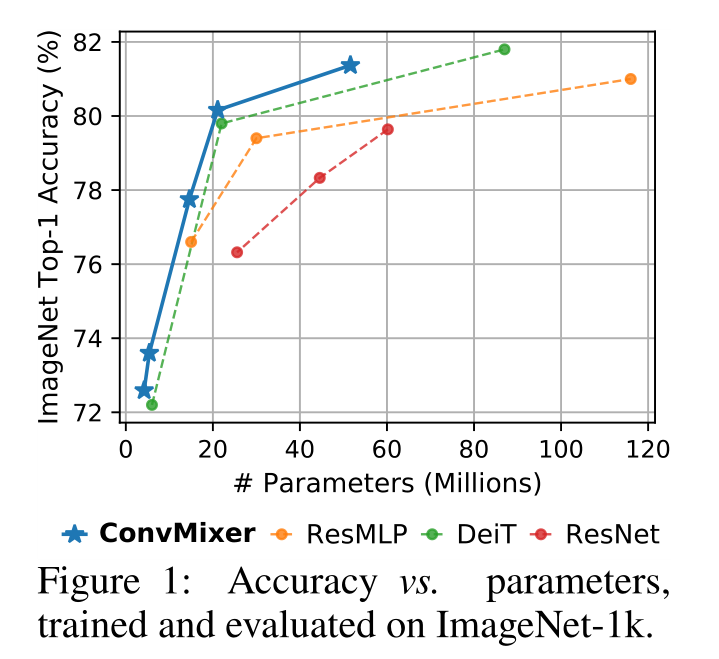
- 同等参数量,ConvMixer-1536/20的性能优于ResNet-152和ResMLP-B24;
- ConvMixers在推理方面比竞争对手慢得多,可能是由于它们的patch尺寸更小; 超参数调优和优化可以缩小这一差距。有关更多讨论和比较,请参见表2和附录A。