【LINUX】小工具降耦合,全内核函数插入宏摸索测试中。。
这阵子把这个小工具对外的耦合度降了下,
include/linux/printk_self.h · r77683962/linux-6.9.0 - Gitee.com![]() https://gitee.com/r77683962/linux-6.9.0/blob/master/include/linux/printk_self.h
https://gitee.com/r77683962/linux-6.9.0/blob/master/include/linux/printk_self.h
这个用于初始化打印日志的级别和打印次数:
void ParametersInit(int State, int Times); //Initial parameters
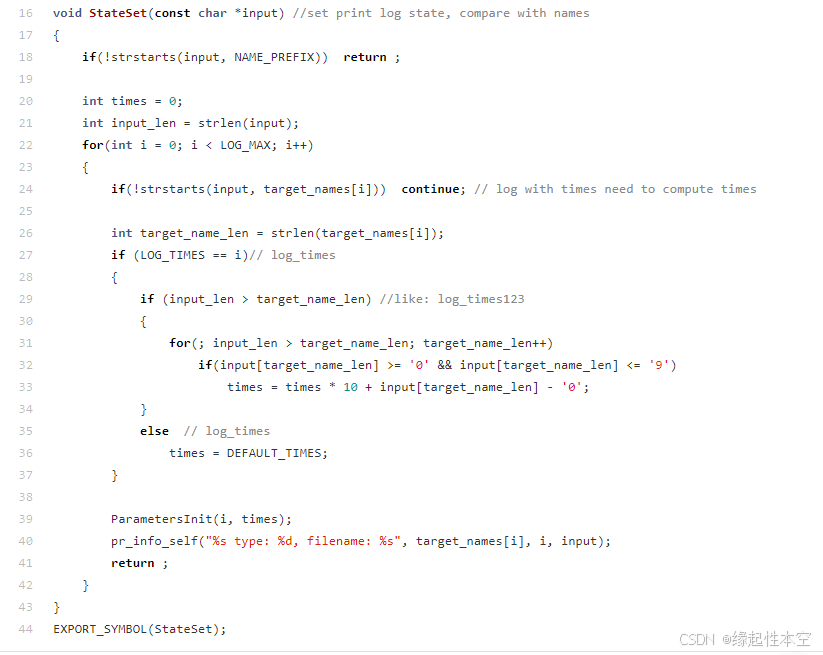
这个用于通过名称来设置打印的级别和打印次数,原来是放在do_sys_openat2函数内的:
现在把跟文件比较的代码全放在这个函数里了:
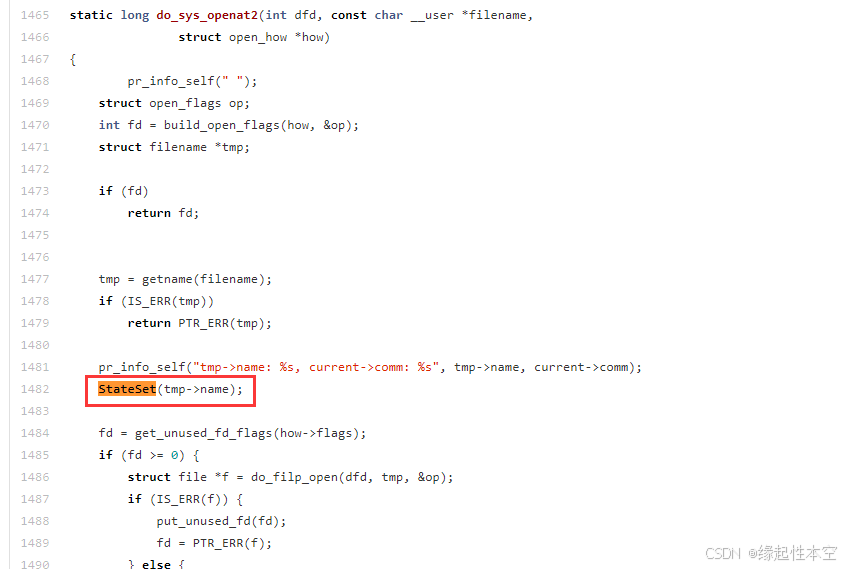
 原来在创建文件时会走到这个流程,由于操作系统内核运行时,时时刻刻都可能会走到这个流程,所以会浪费系统CPU资源。
原来在创建文件时会走到这个流程,由于操作系统内核运行时,时时刻刻都可能会走到这个流程,所以会浪费系统CPU资源。
void StateSet(const char *name); //set print log state
封装后调用的话,看起来简单不少,只需要你的代码传入名称就可以了,那这样可以根据自己的实际情况选择这个函数的插入位置:
这是把原来这个工具代码优化了下。
另外一件事情本来是设想把内核所有C文件函数里都加下这个打印,想看看效果怎么样,先给结论:电脑会卡死,具体原因还没有找到,修改的文件太多了,不太容易找。
先说下是怎么操作这一个流程的:
1、把内核编译一遍,编译完成后所有C文件都会有目标文件.O,操作命令就是在根目录make -j16这样;
2、用NM命令把所有C代码生成的目标文件里边的符号找出来,在这步操作的时候需要排除一些目录,比如:tools,samples这类,下边这个命令行写的不太行,当时为了实现功能,没想那么多:
find . -mindepth 2 -name "*.o" | grep '\./tools' -v | grep '\./samples' -v | grep '\./security' -v | grep '\./crypto' -v | grep '\./arch' -v | grep '\./lib' -v | grep -v "\.mod\.o" >all_o_files.txt
然后于nm命令的参数找到目标文件里定义的局部函数和全局函数:
nm $ofile -l | grep " [Tt] " | grep -v "__pfx" | grep "${no_postfix}\.c" | awk -F":" '{ print $2 }' | sort -n |uniq >all_lines.txt
在实际操作的过程里,还需要去重等等,这里边就会找到每个C文件里边在实现的时候函数名所在的行。
函数所在的行是没法直接插入我们的打印宏的,需要找到函数体开始标志:{
3、用的这个手段,好像大概意思是找到函数所在的行,向后10行中找第一个{,函数实现的时候会有实参列表啥的,实际上是把所有写入到 leftCurlyBracket.txt,所以这里用到>>
cat -n $file | tail -n +${line} | head -10 | grep "{" | head -1 | awk '{ print $1 }' >> leftCurlyBracket.txt
然后在找到的{下一行插入,实际这样会有问题,因为有的函数只有{}在同一行,会报错
在前面nm -Tt的时候会把静态结构体定义找到,就会导致插入宏后会变成这样:
struct xxxx = {
pr_info_self().....
xxx
xxx
}
这是一类,还有同类型的static char *......这类,还有enum这类等等
第2步那个sort -n很重要,在插入宏的时候,只能是从行数大的先插入,然后行数小的后插入宏,因为插入代码后,行数会变;
4、最后插入头文件包含,开始本来是在原来C文件里边#include最后一个后边插入,实际上不行,因为有的C文件最后百分之15左右也会有#include包含,到后边直接简单粗暴直接在第2行后插入,这能解决98%左右的问题,还有些使用的/**/多行注释的,插入了因为被注释掉了没有用,也不行;
5、前面工作完了就要编译验证,这才是最难的,因为很多大佬写的代码也不太规范,会有各种编译问题。
其实最好的还是使用编译器来搞这种操作比较好。